NVIDIA TAO Toolkit 提供了一个低代码人工智能框架,用于加速视觉人工智能模型开发,适用于从新手到专家数据科学家的所有技能水平。借助 NVIDIA TAO (训练、适应、优化)工具包,开发人员可以利用迁移学习的力量和效率,通过适应和优化,在创纪录的时间内实现最先进的精度和生产级吞吐量。
在 NVIDIA GTC 2023 上, NVIDIA 发布了 NVIDIA TAO Toolkit5.0 ,带来了突破性的功能来增强任何人工智能模型的开发。新功能包括开源架构、基于 transformer 的预训练模型、人工智能辅助的数据注释,以及在任何平台上部署模型的能力。
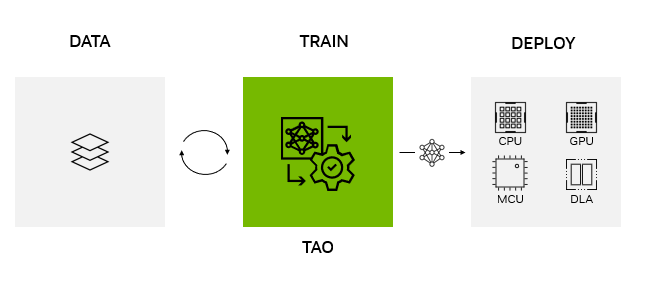
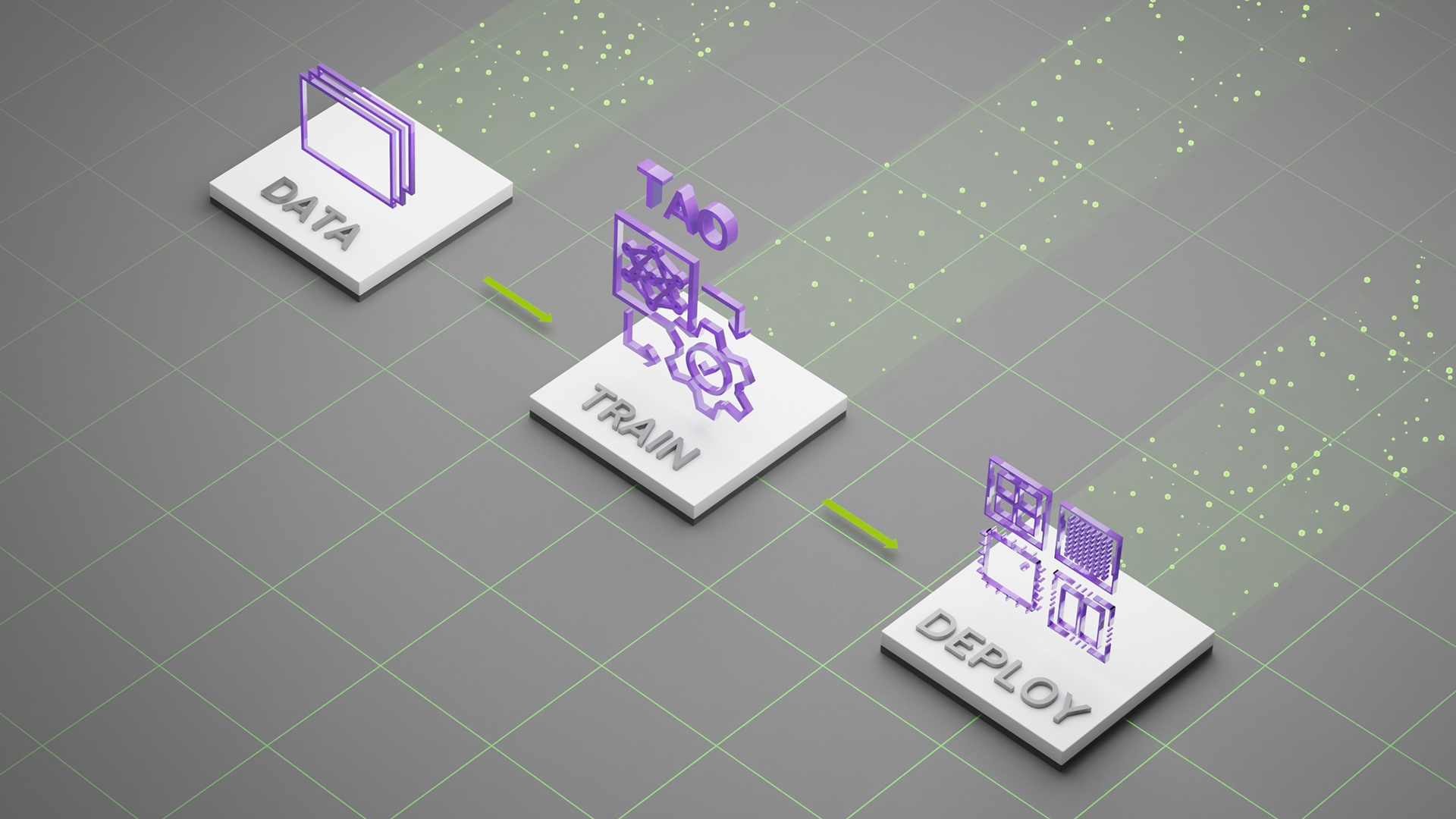
在任何平台、任何位置部署 NVIDIA TAO 型号
NVIDIA TAO Toolkit 5.0 支持 ONNX 中的模型导出。这使得在边缘或云中的任何计算平台 GPU 、 CPU 、 MCU 、 DLA 、 FPGA 上部署使用 NVIDIA TAO Toolkit 训练的模型成为可能。 NVIDIA TAO 工具包简化了模型训练过程,优化了模型的推理吞吐量,为数千亿台设备的人工智能提供了动力。
嵌入式微控制器的全球领导者 STMicroelectronics 将 NVIDIA TAO 工具包集成到其 STM32Cube AI 开发人员工作流程中。这使 STMicroelectronics 的数百万开发人员掌握了最新的人工智能功能。它首次提供了将复杂的人工智能集成到 STM32Cube 提供的广泛物联网和边缘用例中的能力。
现在有了 NVIDIA TAO 工具包,即使是最新手的人工智能开发人员也可以在微控制器的计算和内存预算内优化和量化人工智能模型,使其在 STM32 MCU 上运行。开发人员还可以带来自己的模型,并使用 TAO Toolkit 进行微调。 STMicroelectronics 在下面的演示中捕捉到了有关这项工作的更多信息。
视频 1 。了解如何在 STM 微控制器上部署使用 TAO Toolkit 优化的模型
虽然 TAO Toolkit 模型可以在任何平台上运行,但这些模型在使用 TensorRT 进行推理的 NVIDIA GPU 上实现了最高吞吐量。在 CPU 上,这些模型使用 ONNX-RT 进行推理。一旦软件可用,将提供复制这些数字的脚本和配方。
| NVIDIA Jetson Orin Nano 8 GB | NVIDIA Jetson AGX Orin 64 GB | T4 | A2 | A100 | L4 | H100 | |
| PeopleNet | 112 | 679 | 429 | 242 | 3,264 | 797 | 7,062 |
| DINO – FAN-S | 3 | 11.4 | 29.9 | 16.5 | 174 | 52.7 | 292 |
| SegFormer – MiT | 1.3 | 4.7 | 6.2 | 4 | 40.6 | 10.4 | 70 |
| OCRNet | 981 | 3,921 | 3,903 | 2,089 | 27,885 | 7,241 | 53,809 |
| EfficientDet | 61 | 227 | 303 | 184 | 1,521 | 522 | 2,428 |
| 2D Body Pose | 136 | 557 | 593 | 295 | 4,140 | 1,010 | 7,812 |
| 3D Action Recognition | 52 | 212 | 269 | 148 | 1,658 | 529 | 2,708 |
人工智能辅助的数据注释和管理
对于所有人工智能项目来说,数据注释仍然是一个昂贵且耗时的过程。对于像分割这样需要在对象周围的像素级生成分割遮罩的 CV 任务来说尤其如此。通常,分割掩模的成本是对象检测或分类的 10 倍。
使用 TAO Toolkit 5.0 ,使用新的人工智能辅助注释功能对分割掩码进行注释,速度更快,成本更低。现在,您可以使用弱监督分割架构 Mask Auto Labeler ( MAL )来帮助进行分割注释,以及固定和收紧用于对象检测的边界框。地面实况数据中对象周围的松散边界框可能会导致次优检测结果,但通过人工智能辅助注释,您可以将边界框收紧到对象上,从而获得更准确的模型。
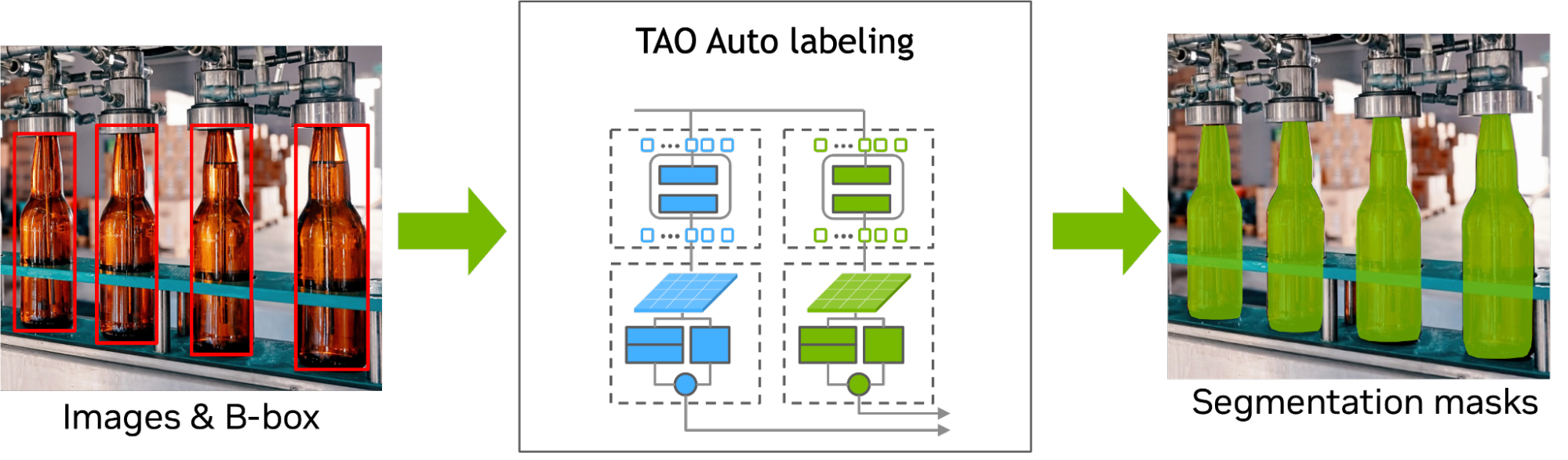
MAL 是一个基于 transformer 的掩码自动标记框架,用于仅使用方框注释的实例分割。 MAL 将方框裁剪图像作为输入,并有条件地生成掩码伪标签。它对输入和输出标签都使用了 COCO 注释格式。
MAL 显著减少了自动标注和人工标注之间的差距,以获得遮罩质量。使用 MAL 生成的掩码训练的实例分割模型可以几乎匹配完全监督的对应模型的性能,保留了高达 97.4% 的完全监督模型的性能。
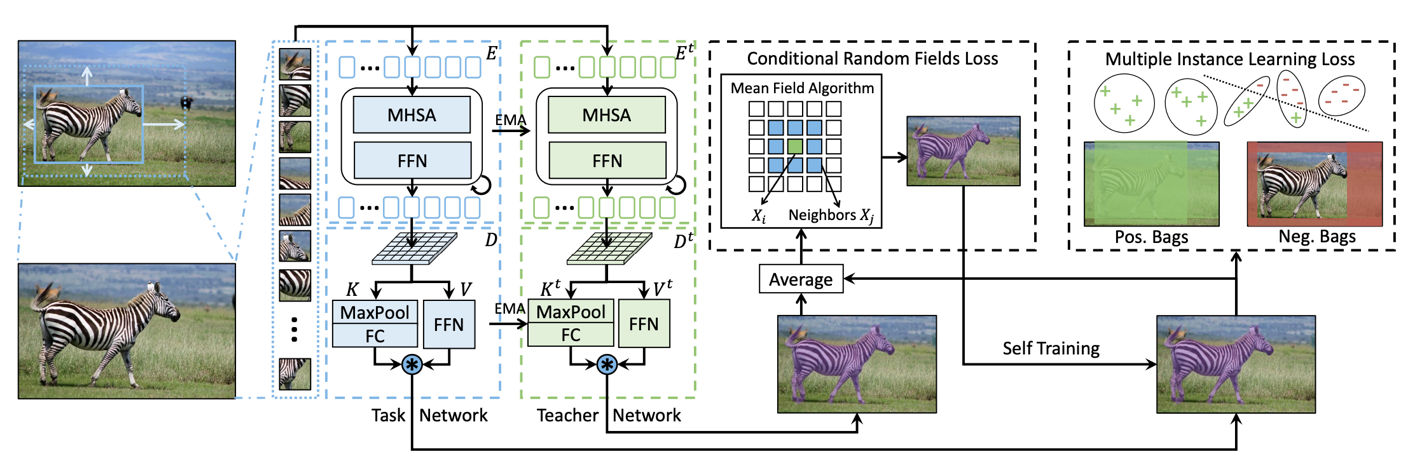
在训练 MAL 网络时,任务网络和教师网络(共享相同的 transformer 结构)一起工作,以实现类不可知的自我训练。这使得能够细化具有条件随机场( CRF )损失和多实例学习( MIL )损失的预测掩码。
TAO Toolkit 在自动标记管道和数据扩充管道中都使用了 MAL 。具体而言,用户可以在空间增强的图像上生成伪掩模(例如,剪切或旋转),并使用生成的掩模细化和收紧相应的边界框。
最先进的愿景 transformer
transformer 已经成为 NLP 中的标准架构,这主要是因为自我关注。它们还因一系列视觉人工智能任务而广受欢迎。一般来说,基于 transformer 的模型可以优于传统的基于 CNN 的模型,因为它们具有鲁棒性、可推广性和对大规模输入执行并行处理的能力。所有这些都提高了训练效率,对图像损坏和噪声提供了更好的鲁棒性,并在看不见的对象上更好地泛化。
TAO Toolkit 5.0 为流行的 CV 任务提供了几种最先进的( SOTA )愿景 transformer ,具体如下。
全注意力网络
全注意力网络( FAN )是 NVIDIA Research 的一个基于 transformer 的主干家族,它在抵御各种破坏方面实现了 SOTA 的鲁棒性。这类主干可以很容易地推广到新的领域,并且对噪声、模糊等更具鲁棒性。
FAN 块背后的一个关键设计是注意力通道处理模块,它可以实现稳健的表征学习。 FAN 可以用于图像分类任务以及诸如对象检测和分割之类的下游任务。

FAN 系列支持四个主干,如表 2 所示。
| Model | # of parameters/FLOPs | Accuracy |
| FAN-Tiny | 7 M/3.5 G | 71.7 |
| FAN-Small | 26 M/6.7 | 77.5 |
| FAN-Base | 50 M/11.3 G | 79.1 |
| FAN-Large | 77 M/16.9 G | 81.0 |
全球环境愿景 transformer
全局上下文视觉 transformer ( GC ViT )是 NVIDIA Research 的一种新架构,可实现非常高的准确性和计算效率。 GC ViT 解决了视觉中缺乏诱导性偏倚的问题 transformer 。通过使用局部自注意,它在 ImageNet 上使用较少的参数获得了更好的结果。
局部自我注意与全局上下文自我注意相结合,可以有效地模拟长距离和短距离的空间交互。图 6 显示了 GC ViT 模型体系结构。有关更多详细信息,请参见 Global Context Vision Transformers 。

如表 3 所示, GC ViT 家族包含六个主干,从 GC ViT xxTiny (计算效率高)到 GC ViT Large (非常准确)。 GC ViT 大型模型在 ImageNet-1K 数据集上可以实现 85.6 的 Top-1 精度,用于图像分类任务。该体系结构还可以用作其他 CV 任务的主干,如对象检测、语义和实例分割。
| Model | # of parameters/FLOPs | Accuracy |
| GC-ViT-xxTiny | 12 M/2.1 G | 79.6 |
| GC-ViT-xTiny | 20 M/2.6 G | 81.9 |
| GC-ViT-Tiny | 28 M/4.7 G | 83.2 |
| GC-ViT-Small | 51 M/8.5 G | 83.9 |
| GC-ViT-Base | 90 M/14.8 G | 84.4 |
| GC-ViT-Large | 201 M/32.6 G | 85.6 |
DINO
DINO ( d 检测 transformer ,带有 i 改进的 n oising anch o r )是最新一代 de 检测 tr 编码器( DETR )。它实现了比前代更快的训练收敛时间。可变形 DETR ( D-DETR )至少需要 50 个历元才能收敛,而 DINO 可以在 COCO dataset 上收敛 12 个历元。与 D-DETR 相比,它还实现了更高的精度。
DINO 通过在训练过程中使用去噪来实现更快的收敛,这有助于在提案生成阶段进行二分匹配过程。由于二分匹配的不稳定性,类 DETR 模型的训练收敛较慢。二部分匹配消除了手工制作和计算量大的 NMS 操作的需要。然而,它通常需要更多的训练,因为在二分匹配过程中,不正确的基本事实与预测相匹配。
为了解决这个问题, DINO 引入了有噪声的正地面实况盒和负地面实况盒来处理“无对象”场景。因此, DINO 的训练收敛得非常快。有关更多信息,请参阅 DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection 。
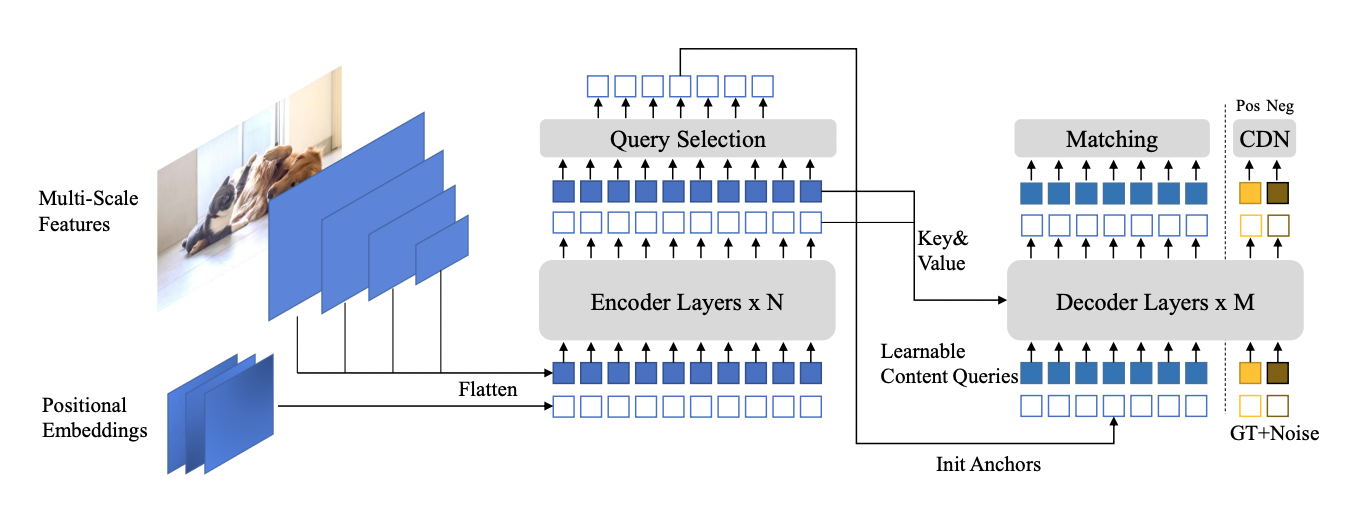
TAO Toolkit 中的 DINO 是灵活的,可以与传统细胞神经网络的各种骨干(如 ResNets )和基于 transformer 的骨干(如 FAN 和 GC ViT )相结合。表 4 显示了流行 YOLOv7 的各种版本的 DINO 上的 COCO 数据集的准确性。有关更多详细信息,请参见 YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors 。
| Model | Backbone | AP | AP50 | AP75 | APS | APM | APL | Param |
| YOLOv7 | N/A | 51.2 | 69.7 | 55.5 | 35.2 | 56.0 | 66.7 | 36.9M |
| DINO | ResNet50 | 48.8 | 66.9 | 53.4 | 31.8 | 51.8 | 63.4 | 46.7M |
| FAN-Small | 53.1 | 71.6 | 57.8 | 35.2 | 56.4 | 68.9 | 48.3M | |
| GCViT-Tiny | 50.7 | 68.9 | 55.3 | 33.2 | 54.1 | 65.8 | 46.9M |
分段窗体
SegFormer 是一种基于 transformer 的轻量级语义分割。解码器由轻量级 MLP 层制成。它避免了使用位置编码(主要由 transformer s 使用),这使得推理在不同分辨率下高效。
将 FAN 骨干网添加到 SegFormer MLP 解码器中会产生一个高度鲁棒和高效的语义分割模型。 FAN-based hybrid + SegFormer 是 Robust Vision Challenge 2022 语义分割的获胜架构。

| Model | Dataset | Mean IOU (%) | Retention rate (robustness) (%) |
| PSPNet | Cityscapes Validation | 78.8 | 43.8 |
| SegFormer – FAN-S-Hybrid | Cityscapes validation | 81.5 | 81.5 |
目标检测和分割之外的 CV 任务
NVIDIA TAO 工具包加速了传统对象检测和分割之外的各种 CV 任务。 TAO Toolkit 5.0 中新的字符检测和识别模型使开发人员能够从图像和文档中提取文本。这自动化了文档转换,并加速了保险和金融等行业的用例。
当被分类的对象变化很大时,检测图像中的异常是有用的,这样就不可能用所有的变化进行训练。例如,在工业检测中,缺陷可以是任何形式的。如果训练数据之前没有发现缺陷,那么使用简单的分类器可能会导致许多遗漏的缺陷。
对于这样的用例,将测试对象直接与黄金参考进行比较将获得更好的准确性。 TAO Toolkit 5.0 的特点是暹罗神经网络,在该网络中,模型计算被测对象和黄金参考之间的差异,以便在对象有缺陷时进行分类。
使用 AutoML 实现超参数优化的自动化培训
自动机器学习( autoML )自动化了在给定数据集上为所需 KPI 寻找最佳模型和超参数的手动任务。它可以通过算法推导出最佳模型,并抽象掉人工智能模型创建和优化的大部分复杂性。
TAO Toolkit 中的 AutoML 可完全配置,用于自动优化模型的超参数。它既适合人工智能专家,也适合非专家。对于非专家来说,引导 Jupyter notebook 提供了一种简单有效的方法来创建准确的人工智能模型。
对于专家来说, TAO Toolkit 可以让您完全控制要调整的超参数和要用于扫描的算法。 TAO Toolkit 目前支持两种优化算法:贝叶斯优化和双曲线优化。这些算法可以扫描一系列超参数,以找到给定数据集的最佳组合。
AutoML 支持多种 CV 任务,包括一些新的视觉 transformer ,如 DINO 、 D-DETR 、 SegFormer 等。表 6 显示了受支持网络的完整列表(粗体项目是 TAO Toolkit 5.0 的新增项目)。
| Image classification | Object detection | Segmentation | Other |
| FAN | DINO | SegFormer | LPRNet |
| GC-ViT | D-DETR | UNET | |
| ResNet | YoloV3/V4/V4-Tiny | MaskRCNN | |
| EfficientNet | EfficientDet | ||
| DarkNet | RetinaNet | ||
| MobileNet | FasterRCNN | ||
| DetectNet_v2 | |||
| SSD/DSSD |
用于工作流集成的 REST API
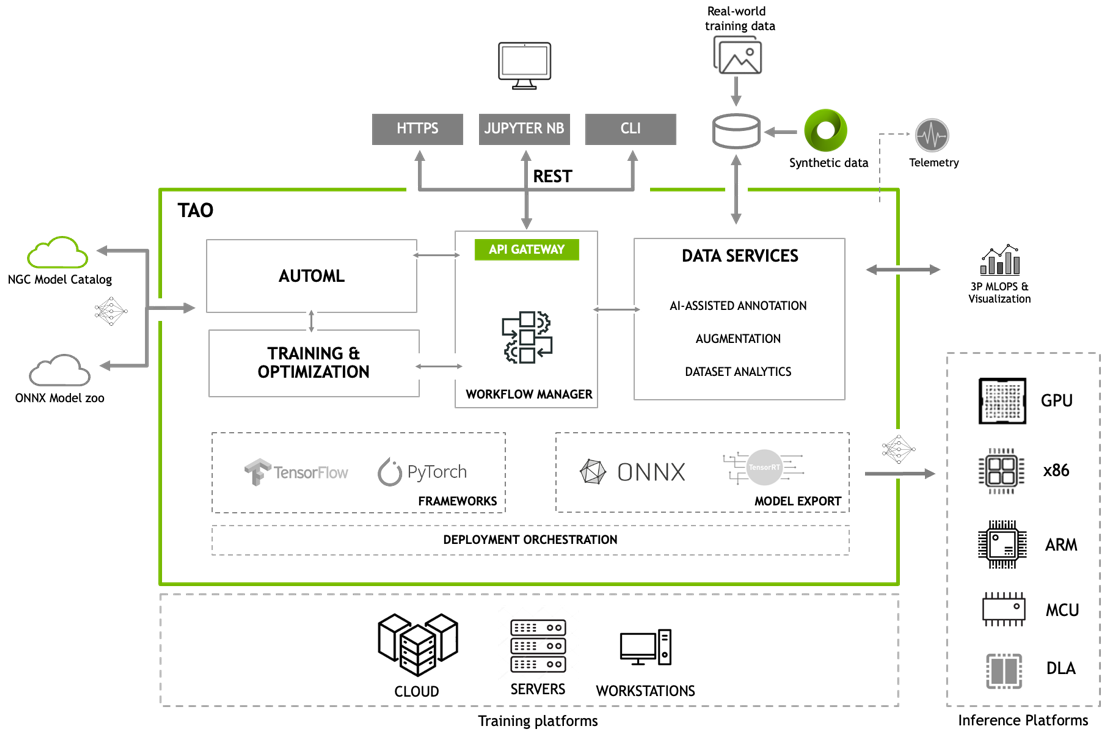
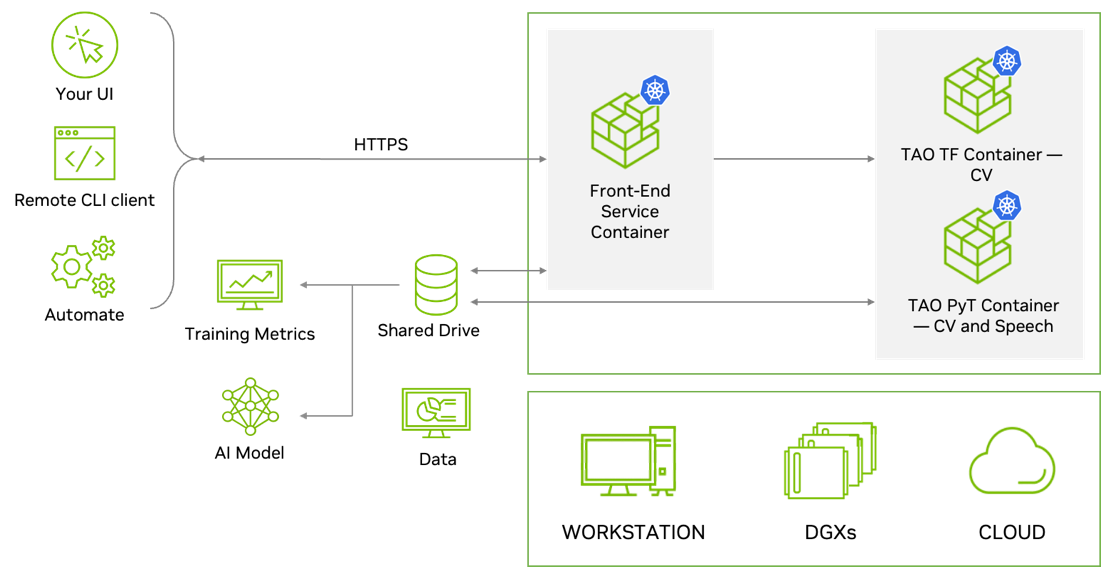
TAO Toolkit 是模块化的、云原生的,这意味着它可以作为容器使用,并且可以使用 Kubernetes 进行部署和管理。 TAO Toolkit 可以作为自管理服务部署在任何公共或私有云、 DGX 或工作站上。 TAO Toolkit 提供了定义良好的 RESTAPI ,使其易于集成到您的开发工作流程中。开发人员可以为所有的训练和优化任务调用 API 端点。这些 API 端点可以从任何应用程序或用户界面调用,这可以远程触发培训作业。
Better inference optimization
为了简化产品化并提高推理吞吐量, TAO Toolkit 提供了几种交钥匙性能优化技术。其中包括模型修剪、较低精度量化和 TensorRT 优化,与公共模型动物园的可比模型相比,这些技术可以将性能提高 4 到 8 倍。
开放灵活,具有更好的支撑
人工智能模型基于复杂的算法预测输出。这可能会使人们很难理解系统是如何做出决定的,并且很难调试、诊断和修复错误。可解释人工智能( XAI )旨在通过深入了解人工智能模型如何做出决策来应对这些挑战。这有助于人类理解人工智能输出背后的推理,并使诊断和修复错误变得更容易。这种透明度有助于建立对人工智能系统的信任。
为了提高透明度和可解释性, TAO Toolkit 现在将以开源形式提供。开发人员将能够从内部层查看特征图,并绘制激活热图,以更好地理解人工智能预测背后的推理。此外,访问源代码将使开发人员能够灵活地创建定制的人工智能,提高调试能力,并增加对其模型的信任。
NVIDIA TAO 工具包已准备就绪,可通过 NVIDIA AI Enterprise ( NVAIE )获得。 NVAIE 为公司提供关键业务支持、访问 NVIDIA 人工智能专家以及优先级安全修复。 Join NVAIE 获得人工智能专家的支持。
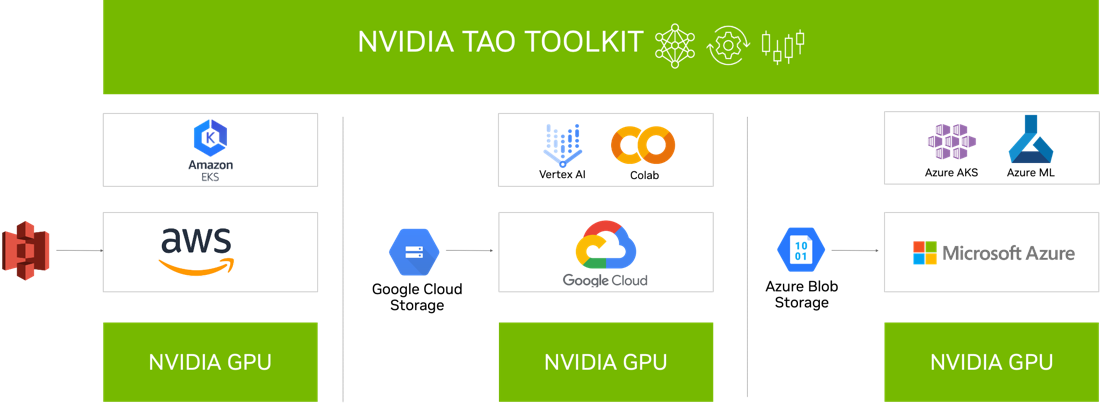
与云服务集成
NVIDIA TAO Toolkit 5.0 集成到您可能已经使用的各种 AI 服务中,如 Google Vertex AI 、 AzureML 、 Azure Kubernetes 服务和 Amazon EKS 。
总结
TAO Toolkit 为任何开发人员、任何服务和任何设备提供了一个平台,可以轻松地转移学习他们的自定义模型,执行量化和修剪,管理复杂的训练工作流程,并执行人工智能辅助注释,而无需编码。在 GTC 2023 上, NVIDIA 宣布了 TAO Toolkit 5.0 . Sign up to be notified 关于 TAO Toolkit 的最新更新。
Download NVIDIA TAO Toolkit 并开始创建自定义人工智能模型。您也可以在 LaunchPad 上体验 NVIDIA TAO 工具包。