创造新的候选药物是一项英勇的努力,通常需要 10 多年的时间才能将一种药物推向市场。理解生物学和化学文本的新的超级计算规模的大型语言模型( LLM )正在帮助科学家理解蛋白质、小分子、 DNA 和生物医学文本。
这些最先进的人工智能模型有助于生成 de novo 蛋白质和分子,并预测蛋白质的 3D 结构。他们可以预测小分子与蛋白质的结合结构,并为科学家提供更容易的方法来设计新的候选药物,最终为患者带来希望。
2021 Exscientia brought an AI-designed drug candidate 进行临床试验后,其他几家公司宣布他们的候选人正在试验中。在专注于基于人工智能的发现的制药公司中,有关于 160 discovery programs 的公开信息,据报道其中 15 种产品正在临床开发中。
基于人工智能的药物发现的前沿是 generating high-quality proteins 等应用的生成人工智能模型。这些大型、强大的模型从多 GPU 、多节点、高性能计算( HPC )基础设施上的未标记数据(如测序数据)中学习。
有了 NVIDIA BioNeMo Service ,生物生成人工智能的工作流程得到了优化和交钥匙。你可以专注于使人工智能模型适应合适的候选药物,而不是处理配置文件和建立超级计算基础设施。
生物 NeMo 服务
Bio NeMo 服务是早期药物发现中生成人工智能的云服务,在一个地方拥有九个最先进的大型语言和扩散模型。
Bio NeMo 中的模型可以通过 web 界面或完全管理的 API 访问,并且可以在 NVIDIA DGX Cloud 上进行进一步的训练和优化。
使用 Bio NeMo 服务,您可以执行以下任何任务:
- 生成大型蛋白质库。
- 使用嵌入来完善蛋白质库,构建属性预测因子。
- 生成具有特定财产的小分子。
- 快速准确地预测和可视化数十亿蛋白质的 3D 结构。
- 开展大规模的配体到小分子姿态估计活动。
- 下载蛋白质、分子和预测的 3D 结构。
生物 NeMo 服务中的生成人工智能模型
Bio NeMo 服务有九个人工智能生成模型,涵盖了开发人工智能药物发现管道的广泛应用:
- AlphaFold 2 、 ESMFold 和 OpenFold 用于从初级氨基酸序列预测 3D 蛋白质结构
- ESM-1nv 和 ESM-2 用于蛋白质性质预测
- ProtGPT2 用于蛋白质生成
- 用于小分子生成的 MegaMolBART 和 MoFlow
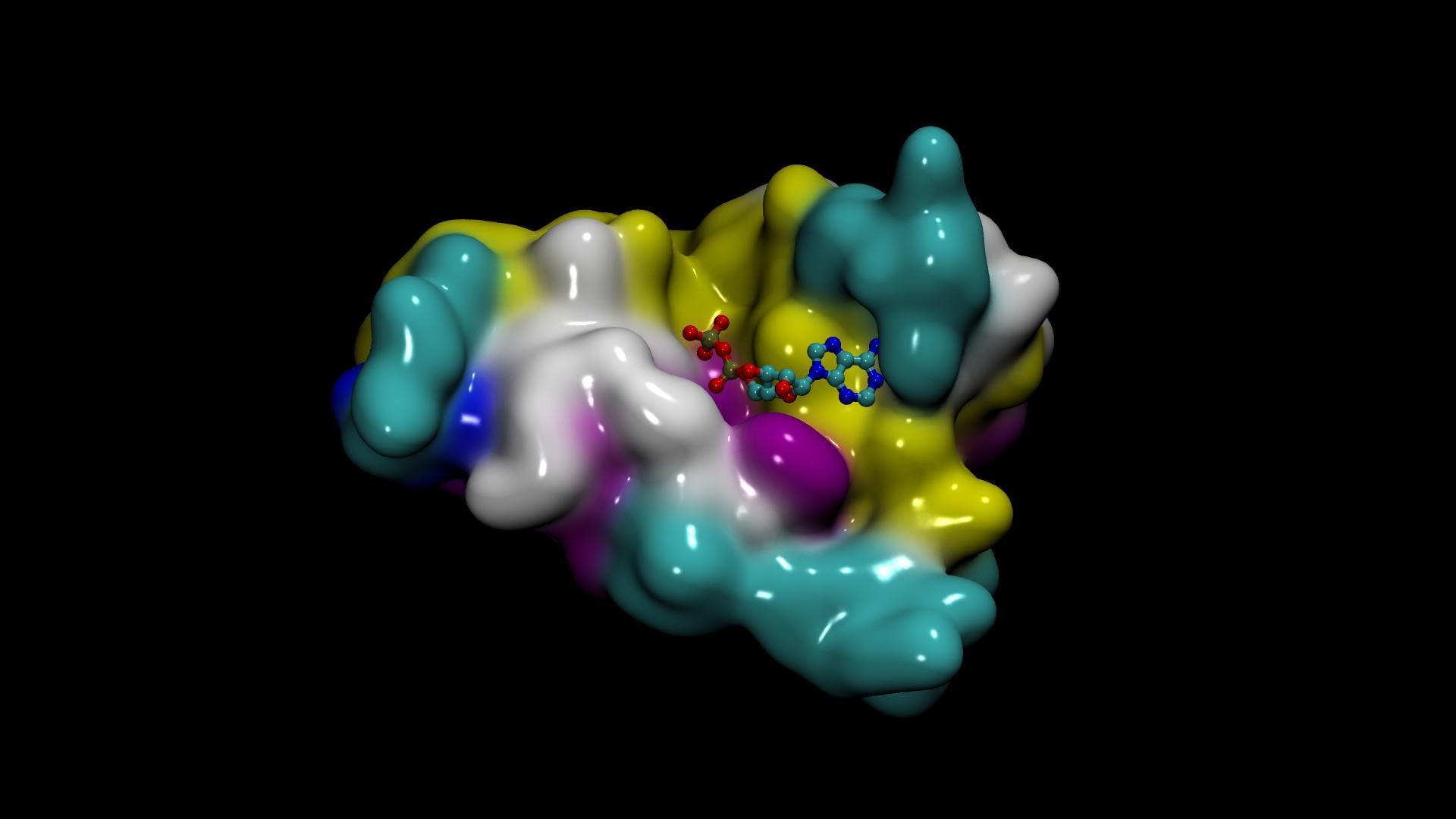
- DiffDock 用于预测小分子与蛋白质的结合结构
3D 蛋白质结构预测
蛋白质结构预测模型使科学家能够从其初级线性氨基酸序列预测 3D 蛋白质结构。 AlphaFold 2 、 OpenFold 和 ESMFold 是 Bio NeMo 服务中可用于蛋白质结构预测的模型。
DeepMind 的 AlphaFold 2 在 CASP14, 达到了一个重要的里程碑,它在预测蛋白质 3D 结构方面达到了接近实验的准确性。 AlphaFold 2 使用深度学习并在 JAX 中开发,即使只有少数同源序列可用,也能高精度预测蛋白质的氨基酸序列与其 3D 结构之间的关系。
OpenFold 是 DeepMind 的 AlphaFold 2 模型的忠实复制,用于从初级氨基酸序列预测 3D 蛋白质结构。虽然 AlphaFold 2 是在 JAX 工作流中开发的,但 OpenFold 的代码基于 PyTorch 。 OpenFold 实现了与原始模型相似的精度,并以 0.96 Å RMSD95 的精度预测了中值主干。
Bio NeMo 将 OpenFold 加速了 6 倍,这样药物发现研究人员就可以分析更大的数据集并进行更多的迭代。 Bio NeMo 中的 OpenFold 也是可训练的,这意味着可以为专门研究创建变体。
Meta 的 ESMFold 是一种基于 transformer 的、超快的 3D 蛋白质结构预测,基于 ESM-2 嵌入,无需多序列比对( MSA )。它包括一个折叠头,可以实现完全端到端的单序列结构预测器。该模型通过无监督预训练学习蛋白质序列,可以预测单个蛋白质序列的结构,而不需要许多同源序列作为输入。
在单个 NVIDIA GPU 上, ESMFold 在 14.2 秒内预测出 384 个残基的蛋白质,比单个 AlphaFold 2 模型快 6 倍。在较短的序列上,改进增加到~ 60 倍。
蛋白质性质预测
Meta 最先进的 ESM-1 and ESM-2 是用于蛋白质进化规模建模的 LLM 。他们受到 BERT 架构的启发,并以掩蔽语言建模为目标,在数百万个蛋白质序列上进行训练。 ESM-1 和 ESM-2 了解了最终产生 2D 蛋白质结构和功能的氨基酸之间的模式和依赖性。
Bio NeMo 中的 ESM-1nv 是 Meta 的 ESM-1b 的忠实复制, ESM-1b 是蛋白质进化规模建模的 LLM 。它基于 BERT 架构,并在数百万个蛋白质序列上进行训练,目标是掩蔽语言建模。 ESM-1nv 学习最终产生蛋白质结构和功能的氨基酸之间的模式和依赖性。
通过 Bio NeMo , ESM-1nv 经过优化,可在大型计算基础设施(如 DGX Cloud )上重新训练、扩展和微调。
当 ESM-1nv 通常用于从氨基酸序列预测多种蛋白质财产时, ESM-2 通常用于预测突变对蛋白质稳定性的影响。
在 Bio NeMo 服务中嵌入 ESM-1nv 和 ESM-2 可以用于拟合下游任务模型,以了解感兴趣的蛋白质财产,例如亚细胞位置、热稳定性、水溶性和保守区域或可变区域。这是通过训练一个通常小得多的模型来实现的,该模型具有监督学习目标,以从蛋白质序列的嵌入中推断特性。这种方法已被证明在一系列预测任务上提供了最先进的准确性。
小分子生成
MegaMolBART 和 MoFlow 是生物 NeMo 中的生成化学 AI 模型。 MegaMolBart 是一个基于 transformer 的大型生成化学模型,用于分子优化。它使用 SMILES ,一种表示小分子化学结构的字符串表示法。由阿斯利康和 NVIDIA 开发的 MegaMolBART 最适合生成具有实验测试的结合亲和力的新小分子,以及用于分子嵌入。
MegaMolBART 依赖于 NVIDIA NeMo ,它为开发、训练和部署深度学习模型(包括 Megatron 模型)提供了一个强大的环境。
Megatron 为 PyTorch 照明提供了增强功能,例如具有 YAML 文件和检查点管理的超参数可配置性。它还允许使用 NVIDIA NeMo – NeMo 开发和训练大型 transformer 模型,这使得具有数据并行性、模型并行性和混合精度的多 GPU 、多节点训练易于配置。
使用 ZINC-15 数据库对 MegaMolBART 进行预训练。从满足以下限制的部分中选择了大约 14.5 亿个分子( SMILES 串):
- 分子量<= 500 道尔顿
- 对数 P <= 5
- 反应性水平为“反应性”
- 可购买性被“注释”
来自威尔康奈尔医学院团队的基于流的生成模型 MoFlow 学习分子图及其潜在表示之间的可逆映射。由深度图生成模型驱动生成具有所需化学财产的分子图可以加速药物发现过程。
MoFlow 通过一种新颖的、基于条件流的方法实现了最先进的性能。它使用图卷积,并产生一个遵循键价约束的有效分子图。它用于分子生成、重建和优化。
蛋白质生成
ProtGPT2 由 ISMB 和德国拜勒大学创建,是一种基于 GPT2 transformer 体系结构的 LLM ,可生成 de novo 蛋白质序列,以识别独特的结构、财产和功能。当训练数据有限时,该模型对于生成自定义蛋白质序列是最优的。
它是在蛋白质空间数据库 UniRef50 上训练的,有 36 层,参数为 738M 。使用因果建模目标来训练 ProtGPT2 ,其中训练模型以预测序列中的下一个标记(或在这种情况下,低聚物)。通过这样做,该模型学习了蛋白质的内部表示,并可以说蛋白质语言。
分子对接
麻省理工学院 Jameel 诊所的 DiffDock 是一个扩散生成人工智能模型。它预测小分子配体与蛋白质的结合结构,称为 molecular docking 或 pose prediction 。
DiffDock 具有快速的推理时间,并提供具有高选择性精度的置信度估计。该模型具有高度的准确性和计算效率。它在 PDBBind 盲对接基准上实现了新的最先进的 38% 的前 1 预测, RMSD < 2A ,大大超过了以前的最佳搜索( 23% )和深度学习方法( 20% )。
DiffDock 在 PDBBind 基准的分子复合物上进行了评估,并与最先进的基于搜索的方法(如 SMINA 和 GLIDE )以及最近的深度学习方法 EquiBind 和 TANKBind 进行了比较。 DiffDock 可以帮助人工智能药物发现管道,并为下游任务集成开辟新的研究途径。
开始使用 Bio NeMo
要了解更多关于 Bio NeMo 的信息并申请尽早访问 Bio NeMo 服务,请参阅 BioNeMo 页面。
本周, NVIDIA GTC 2023 在 latest AI advances in drug discovery 上举行了多次会议。免费注册,即可按需访问所有内容,并查看以下关于人工智能药物发现和生物 NeMo 的课程:
- A Transformative A I Platform to Accelerate Biologics Discovery
- Generative Deep Learning with BioNeMo for Protein Therapeutics
- AI-Powered Drug Discovery
- Understanding the Chemical and Biological Language of Life with LLMs using BioNeMo
- Using AI to Accelerate Scientific Discovery
- Artificial Intelligence Captures the Language of Life Written in Proteins