NVIDIA Base Command Platform 提供了自信地开发复杂软件的能力,这些软件符合科学计算工作流程所需的性能标准。该平台为开发人员提供高效配置和管理人工智能工作流程所需的工具,从而为人工智能开发提供云托管和本地解决方案。集成的数据和用户管理简化了用户和管理员的体验。
现在,使用 NVIDIA Modulus 和基本指挥平台在团队和地点之间创建高保真数字双胞胎是 high-performance computing ( HPC )工作流可用的最新工具。对于从预测最优 airplane maintenance schedules 到 simulating wind farms 的许多用例来说,创建和使用数字双胞胎对于节省时间和金钱至关重要。
开始使用这些用例可能会让人望而却步。然而,一个集成良好的解决方案会带来所有的不同,并使开发人员能够专注于解决问题。 Base Command Platform 只需点击几下即可实现 NGC 目录软件的全方位功能,并能够创建强大的物理知情机器学习( physics ML )神经网络和气候模型。
利用 FourCastNet 进行气候建模
FourCastNet 是开源 Modulus 平台的一部分,专注于以以前不可能的速度创建全球天气预报。它依靠傅立叶神经算子和变换器在性能和分辨率上实现了这一令人难以置信的飞跃。 FourCastNet 现在与基本命令平台兼容。
视频1. 使用 FourCastNet 加速极端天气预测
ERA5 dataset 是一个几十年来整个地球的复杂天气数据集,用于训练和验证这样一个复杂的模型。 FourCastNet 是实现 NVIDIA Earth-2 数字孪生的关键技术。有关更多信息,请参阅 NVIDIA to Build Earth-2 Supercomputer to See Our Future 。
Modulus 团队一直在寻求提高 FourCastNet 的性能,最近更新了它,使用 NVIDIA Data Loading Library ( DALI )将数据摄入 GPU ,进一步加快了洞察时间。
在基本指挥平台上使用 Modulus 提高可扩展性
当在一个可以扩展到几个基于 GPU 的系统的环境中运行时, Modulus 的全部功能就会释放出来。没有比基本命令平台更好的方法来运行像 Modulus 这样的高度可扩展平台来训练像 FourCastNet 这样的大型模型。
为了运行这些示例,我们将稍微修改过的 Modulus NGC container 版本上传到了一个基本指挥平台组织,该组织可以访问由 NVIDIA DGX A100 系统组成的加速计算环境。我们将 1TB 的 ERA5 数据集上传到同一环境中的工作空间。
为了支持协调的多实例工作负载, Base Command Platform 集成了一个名为 bcprun 的工具。bcprun通过抽象机器学习( ML )从业者的复杂性并消除工作负载容器(如mpirun)中对额外软件的需求,简化了多实例工作负载部署。它还为最初为 HPC 调度器(如 Slurm )编写的应用程序提供了一个更容易的入门路径。
以下代码示例显示了 FourCastNet 在 Base Command Platform 上的单实例作业启动:
ngc batch run \
--name "bcp-dali.fcn.training.ml-model.modulus" \
--total-runtime 12H \
--org org-name \
--ace ace-name \
--instance dgxa100.80g.8.norm \
--workspace ERA5_test_21Vars:/era5/ngc_era5_data/:RO \
--result /results \
--image "nvcr.io/org-name/team-name/modulus:22.09-examples_0.4" \
--commandline "\
set -x && \
cd /examples/fourcastnet/ && \
ln -s /era5/stats . && \
python fcn_era5.py \
custom.train_dataset.kind=dali \
custom.num_workers.grid=1 \
training.max_steps=50000 \
training.print_stats_freq=500 \
network_dir=/results/network_checkpoint
"要扩展到两个 NVIDIA DGX A100 八个 GPU 实例(共 16 个),请使用以下命令(在 bold 中突出显示更改):
ngc batch run \
--name "bcp-dali.fcn.training.ml-model.modulus" \
--total-runtime 12H \
--org org-name \
--ace ace-name \
--replicas "2" \
--array-type "PYTORCH" \
--instance dgxa100.80g.8.norm \
--workspace ERA5_test_21Vars:/era5/ngc_era5_data/:RO \
--result /results \
--image "nvcr.io/org-name/team-name/modulus:22.09-examples_0.4" \
--commandline "\
set -x && \
cd /examples/fourcastnet/ && \
mkdir -p /results/network_checkpoint && \
ln -s /era5/stats . && \
bcprun --nnodes \$NGC_ARRAY_SIZE \
--npernode \$NGC_GPUS_PER_NODE \
--cmd '\
python fcn_era5.py \
custom.train_dataset.kind=dali \
custom.num_workers.grid=1 \
training.max_steps=50000 \
training.print_stats_freq=500 \
network_dir=/results/network_checkpoint
'
"bcprun的添加以及添加的参数确保指定的命令(来自--cmd参数)在为作业创建的每个副本上运行(如--replicas和--nnodes参数所指定)。--npernode参数确保在每个实例上为该实例中的每个 GPU 运行一个进程。这导致此作业总共启动了 16 个进程(每个复制副本中有 8 个,总共两个复制副本)。要扩展到使用四个实例,请将--replicas参数设置为四个而不是两个。
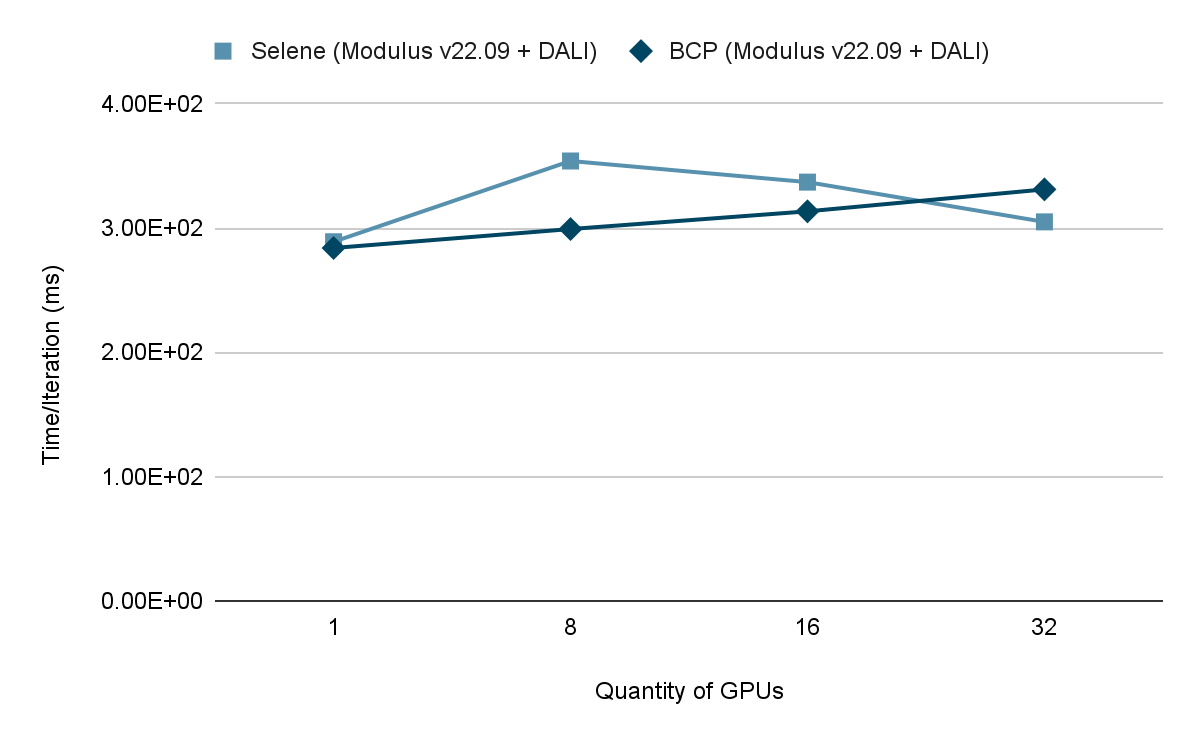
基本命令平台不仅为 ML 从业者和管理员提供了易用性,而且证明了已经实现了最高性能。 NVIDIA Selene supercomputer 与 Modulus 运行 FourCastNet 训练进行比较。
在 Selene 上测试了工作负载后,我们在基本指挥平台部署上无缝复制了工作负载,并在两个环境之间获得了几乎相同的结果。这一结果有力地证明,基本指挥平台可以支持企业和科学计算用例中客户最苛刻的性能要求。
对开发者 Kaustubh Tangsali 的采访
为了了解更多关于在 Base Command Platform 上使用 NVIDIA Modulus 的经验,我们采访了 Modulus 团队的开发人员 Kaustubh Tangsali 。 Kaustubh 领导了在基本指挥平台上运行 FourCastNet 和其他几个软件示例的调查。
简要描述您的行业背景和经验。
我主要在软件行业工作,应用于模拟和计算流体动力学。我致力于 Modulus 平台的开发,这是一个领域专家和人工智能从业者开发物理 ML 模型的框架。我曾与 NVIDIA Thermal 团队等内部合作伙伴密切合作,使用 Modulus 设计散热器,还与几个外部合作伙伴合作,使用 Modulus 加快工作流程。
您在基础指挥平台上使用 Modulus 工作了多长时间?
自 2020 年年中以来,我一直在基地指挥平台上使用 Modulus 。
在基地指挥平台上,日常使用是什么样子的?您的开发周期是什么样子的?
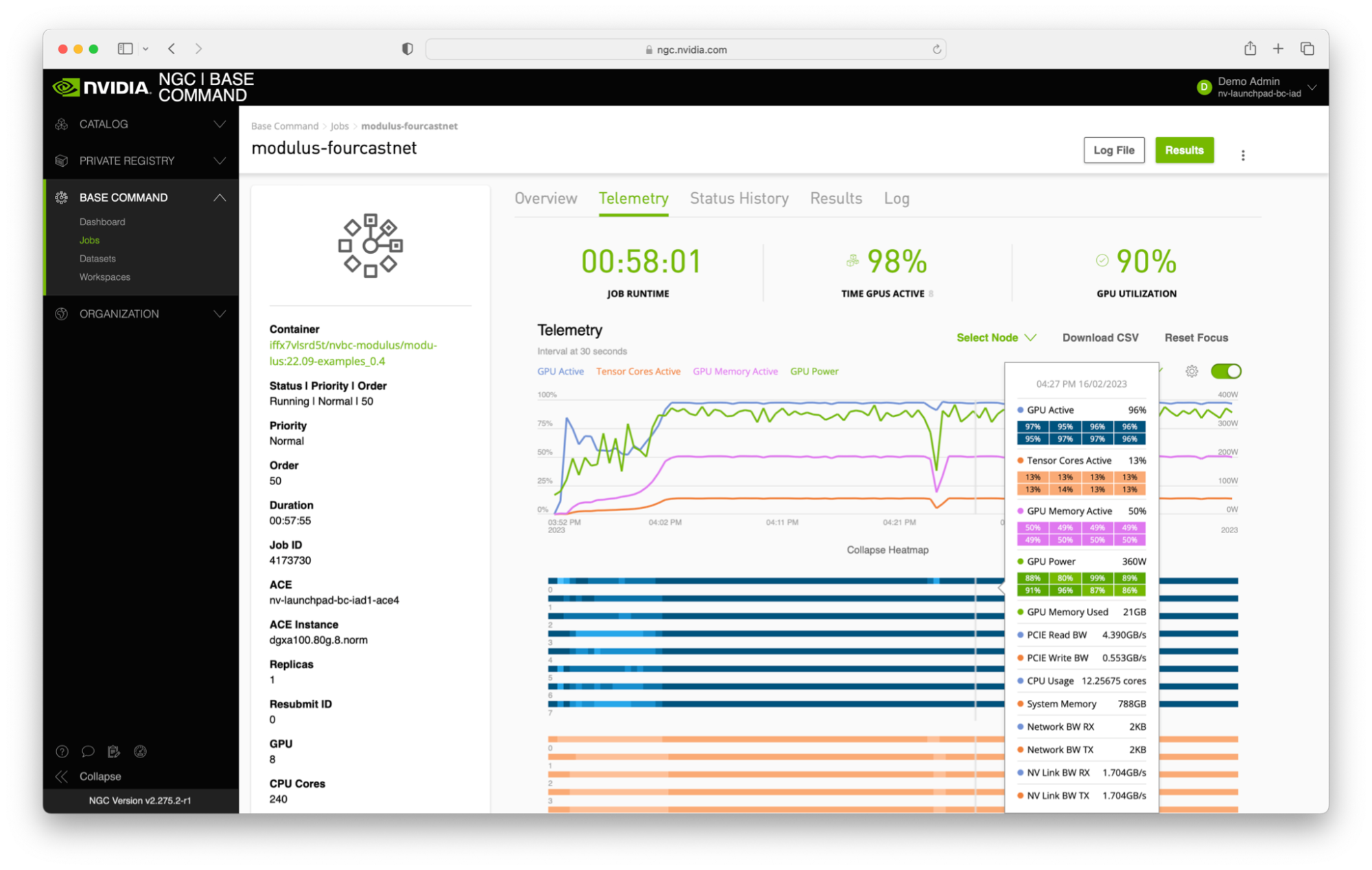
在我对代码或模型进行了一些本地测试后,我通常会将代码安装在基本命令平台工作区中,然后使用 NGC web 界面或仅使用命令行界面( CLI )启动作业。 Jupyter 接口非常适合早期调试。当模型运行到完成时,我下载检查点和结果以进行进一步分析。在运行时,我还使用日志功能和遥测技术来监视作业的状态。
基本指挥平台环境与您使用过的其他环境相比如何?
基本指挥平台的 web 界面是我觉得有用的东西。监视作业、查看用于启动作业的命令、克隆作业以及使用不同的实例类型等功能都很容易。我认为获得最新和最好的 NVIDIA 硬件是一大优势。
对于刚开始使用基地指挥平台的人,你有什么建议吗?
NVIDIA Base Command Platform User Guide 有很好的文档记录,涵盖了数据科学家可能遇到的许多常见用例,包括单 GPU 、多[Z1K1’和多实例作业的命令示例。正如我前面提到的,在扩展作业之前,我喜欢在开发的早期阶段利用运行作业的交互式特性,CLI会对其进行优化。
总结
NVIDIA Modulus 等尖端数字孪生技术依靠强大的计算环境不断进步。基本指挥平台在一组易于使用的界面中利用 NVIDIA GPU 的强大功能,继续 NVIDIA 的使命,即让高级软件功能广泛可访问,以解决重要问题。有关更多信息,请参阅 Simplifying AI Development with NVIDIA Base Command Platform 。
通过 NVIDIA LaunchPad for Modulus 中的短期访问开启您的推理之旅。没有必要设置自己的环境。
有关 NVIDIA Modulus 的更多信息,请参阅 NVIDIA 深度学习研究所课程 Introduction to Physics-Informed Machine Learning with Modulus 。
要获取最新版本的详细信息,请访问 download and try NVIDIA Modulus 。
Register for NVIDIA GTC 2023 for free 并参加 Enterprises Share Their Experience with DGX Cloud 会议,了解由基本指挥平台提供支持的广泛用例。