PDF 是共享财务报告、研究论文、技术文档和营销材料等信息的常用文件格式之一。然而,在构建有效的检索增强生成 (RAG) 系统时,从 PDF 中提取有用内容仍然是一项重大挑战。对于图表、表格和信息图等复杂元素而言,情况尤其如此。提取文本的准确性和清晰度直接影响到检索器在回答用户查询时显示相关上下文的能力。
应对这一挑战的主要方法有两种:光学字符识别 (OCR) 流程和视觉语言模型 (VLM) 。
- 专用 OCR 流程:这些系统 (例如 NVIDIA NeMo Retriever PDF Extraction 流程) 使用多阶段流程,其中涉及物体检测以定位特定元素 (图表、表格等) ,并应用针对每种元素类型定制的专用 OCR 和结构感知模型。
- VLM:这些功能强大的通用 AI 模型可以处理和解释图像和文本,从而直接从 PDF 页面图像中“理解”和描述图表和表格等视觉元素。例如,Llama 3.2 11B Vision Instruct 是 Llama 3.2 的 110 亿参数多模态版本,经过微调,可遵循图像感知指令。
RAG 开发者通常会问,每种方法在什么情况下最有意义,即专用的多模型工作流,还是单个通用 VLM?为了回答这个问题,我们进行了一些实验,将 NeMo Retriever 工作流与基于 VLM 的方法进行了比较,重点放在下游检索性能上。我们的研究结果表明,对于这一特定的检索任务,专用流程目前在准确性和效率方面具有明显优势。
本文比较了两种提取策略 (包括方法、数据集、指标和性能数字) ,以便您决定将哪种策略用于 RAG 工作流及其原因。
基准方法:NeMo Retriever PDF 提取
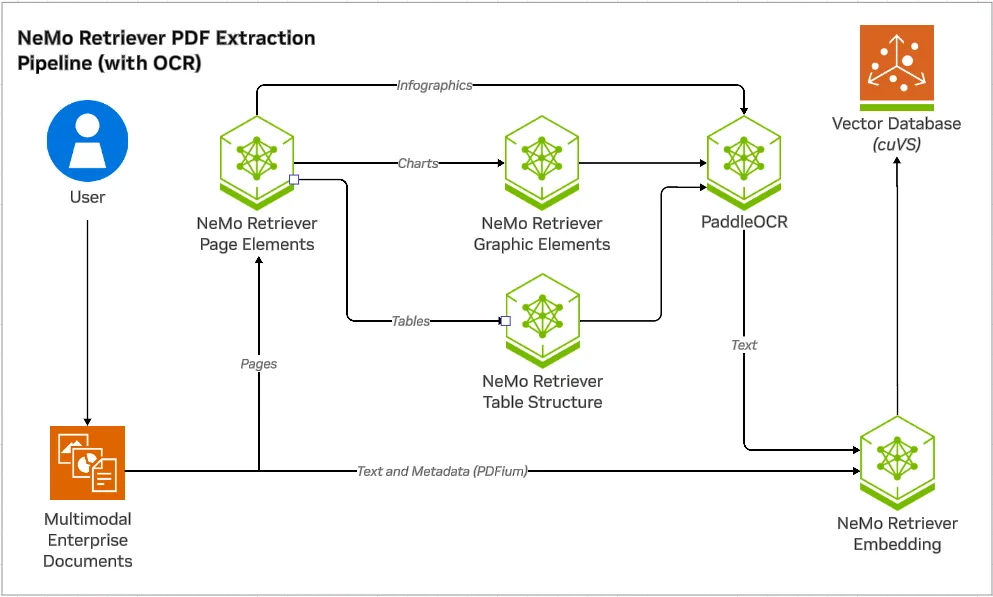
NeMo Retriever PDF Extraction 工作流专为从 PDF 中提取高保真信息而设计。其工作流程涉及以下步骤:
- 页面元素检测:模型首先识别每个 PDF 页面上的图表、表格和信息图的位置。
- 专业提取:然后,每个检测到的元素都由针对其结构进行优化的专用模型处理。
- 图表:与 OCR 相结合的图形元素模型 (例如 PaddleOCR) 可提取标题、轴、数据点和图例 (图表转文本) 。
- 表格:表格结构识别模型,可与 OCR 配合使用,将行、列和单元格准确解析为 Markdown 格式 (表格到文本) 。
- 信息图:由于信息图比图表和表格更多样化,结构化程度更低,因此仅应用 OCR 来提取文本内容 (信息图转文本) 。
这种模块化方法旨在通过使用针对每种数据类型的复杂性专门设计的工具,更大限度地提高准确性。
替代方法:使用 VLM 提取文本
替代方法将专用提取模块替换为单个 VLM,如图 2 所示。

我们的实验使用了通过 NVIDIA NIM 微服务访问的 Llama 3.2 11B Vision Instruct 模型。我们提示 VLM 描述检测到的元素,详情如下。
图表提示:
Describe the chart using the format below:
- Title: {Title}
- Axes: {Axis Titles}
- Data: {Data points}
Reply with empty text if no chart is present.
表格提示:
Describe the table using markdown format. Reply with empty text if no table is present.
Provide the raw data without explanation.
信息图提示:
Transcribe this infographic. Only describe visual elements if essential to understanding.
If unsure about content, don't guess.
我们还测试了一个更大的 Llama 3.2 90B Vision Instruct 模型,以确定是否扩展了改进后的结果。推理参数 (温度 = 0.5,top_p = 0.95,max_tokens = 1024) 保持一致。
实验性设置
我们的核心目标是衡量使用每种方法 (基准和替代方法) 提取的文本对下游检索的支持程度。
- 数据集:使用了两个不同的数据集。
- 收益数据集:包含 512 个 PDF 的内部集合,每个 PDF 包含 3000 多个图表、表格和信息图实例,以及 600 多个人工注释的检索问题。
- DigitalCorpora 10K 数据集:由 Digital Corpora 的 10000 个 PDF 组成的多样化公共基准测试,包含 1300 多个人工注释的问题,涵盖文本、表格、图表和信息图。
- 评估指标:召回率 5 用于衡量,即真值页面在检索到的前五个结果中排名的查询百分比。更高的召回率意味着提取的文本表示对于找到正确的信息更有效。
- 检索器:为了确保在后续基于文本的检索中公平比较这些提取方法,我们对基准 OCR 提取的文本和 VLM 生成的描述使用了相同的嵌入模型 (Llama 3.2 NV EmbedQA 1B v2) 和排序器 (Llama 3.2 NV RerankQA 1B v2) 。在两种方法检索其 top-k 块后,任何 LLM 或 VLM 都可以根据需要处理下游答案生成。由于该生成阶段独立于提取,因此不在本文的讨论范围内。
结果:检索准确性比较
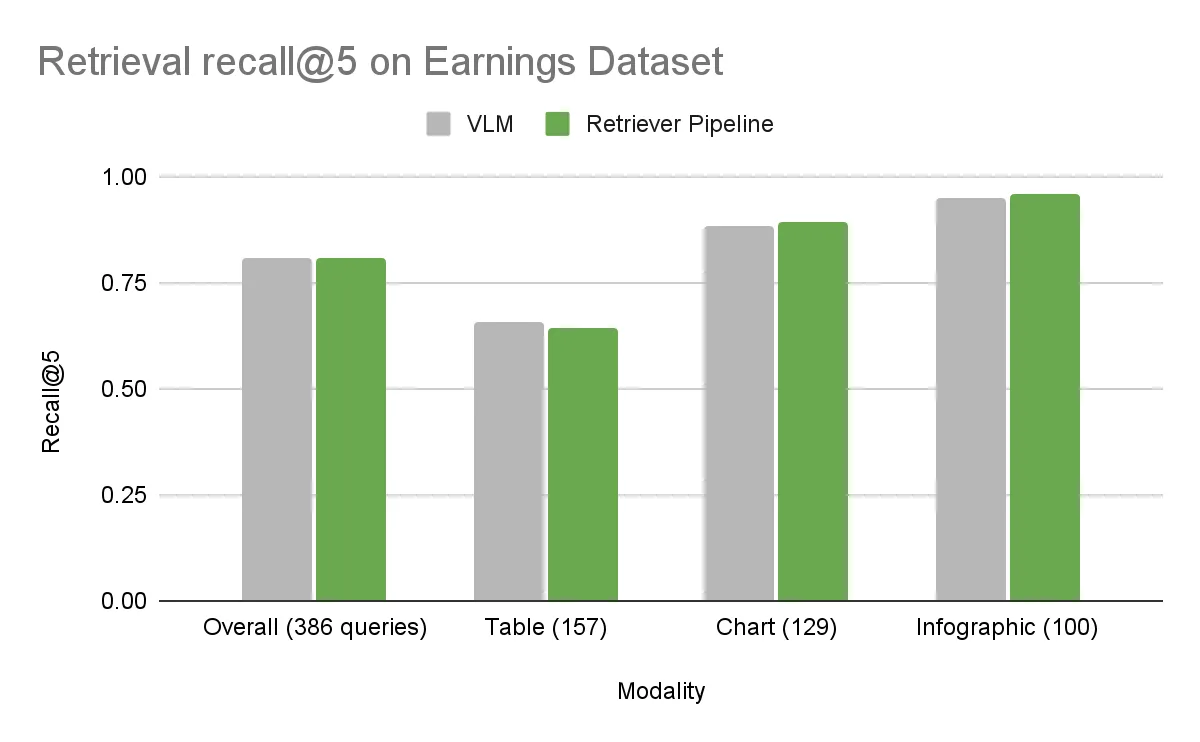
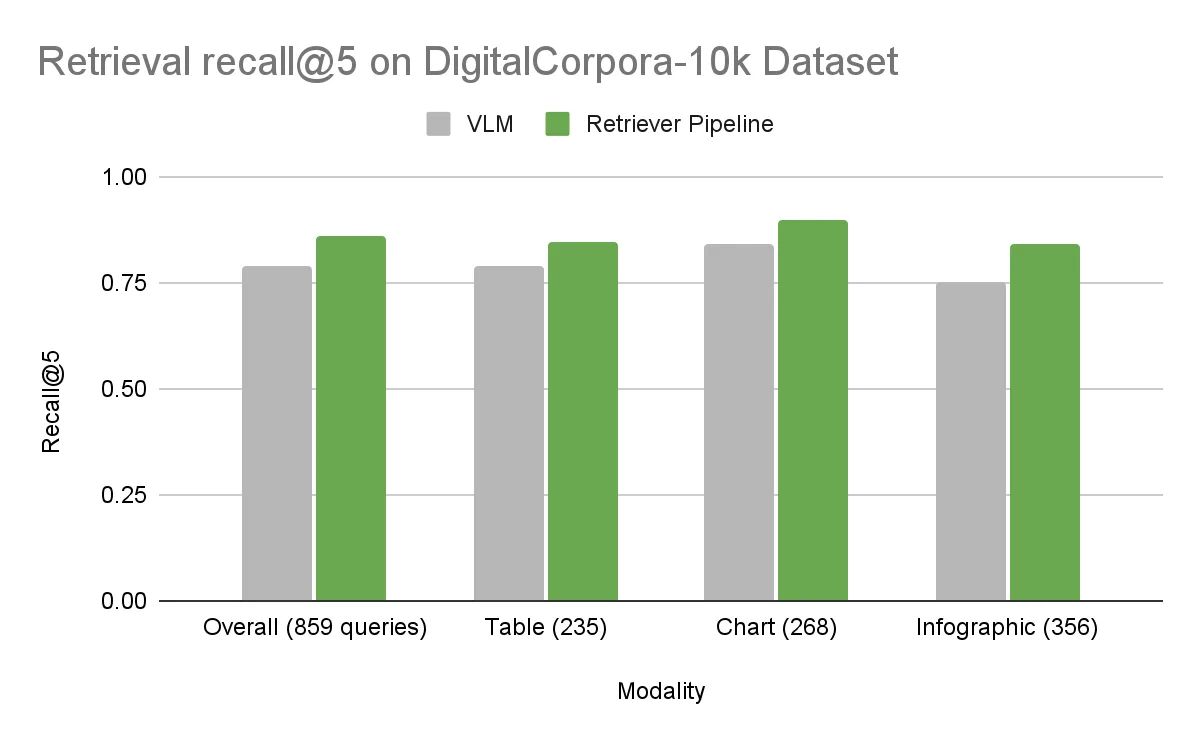
在收益数据集上,整体准确性基本相同。DigitalCorpora 10K 数据集具有更广泛的多样性,显示出明显的差异。基准 NeMo Retriever 工作流在所有视觉模态下的性能均优于 VLM,整体增量为 7.2%。
错误分析
通过调查 DigitalCorpora 10K 数据集上的错误,我们发现了 VLM 方法的常见故障模式。
错误解释
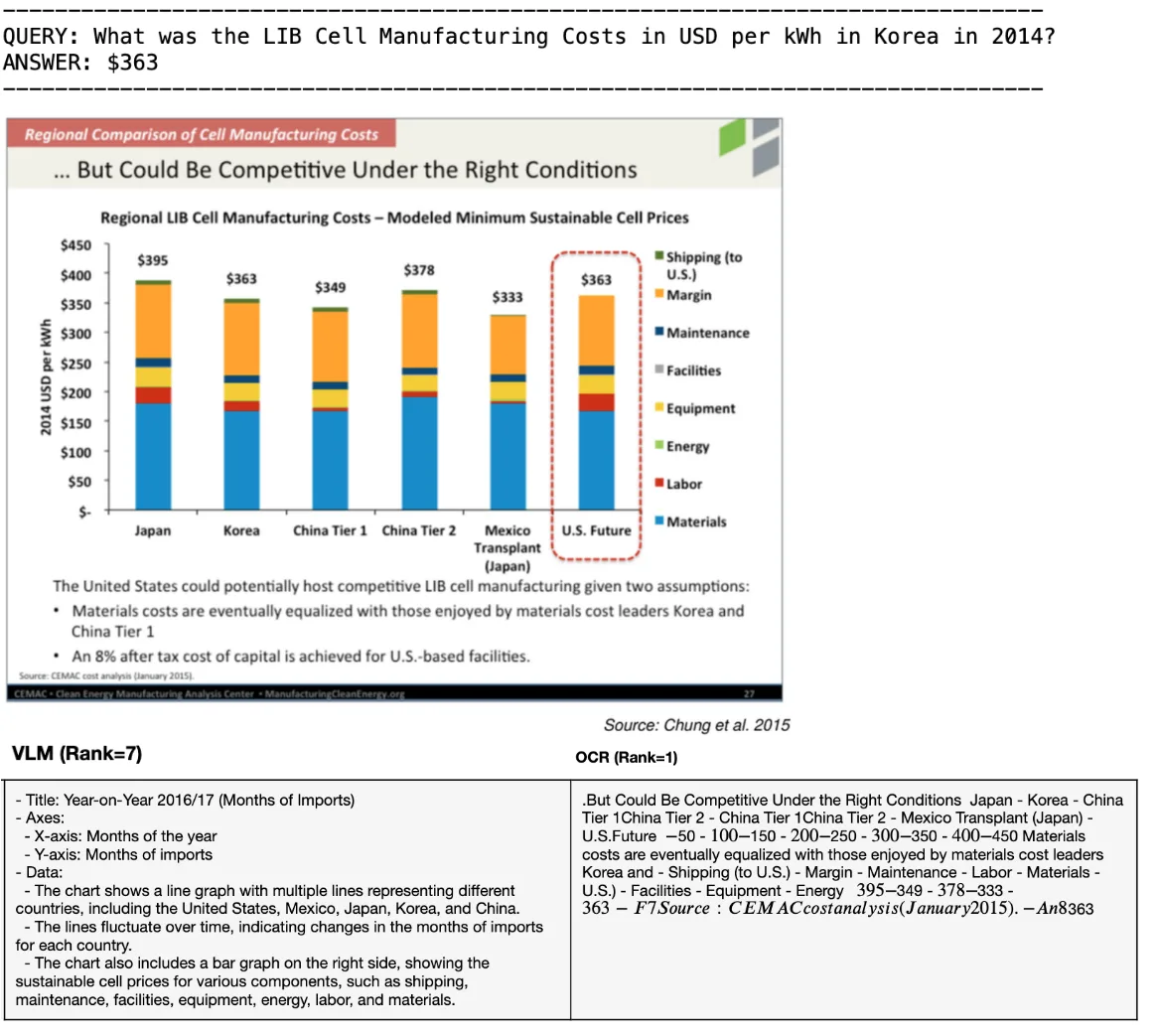
VLM 有时会误解视觉元素。例如,混淆图表类型 (直线与条形图) 、误读轴标签或数据点,或者无法理解图表的主要信息。在本示例中,VLM 描述提取了错误的标题,在折线图和条形图之间进行了混淆,并且没有捕获 Y 轴值。
无法提取嵌入式文本
VLM 有时会漏掉图表或信息图中的关键文本注释、详细说明或特定数据,而基于 OCR 的方法则擅长捕捉这些文本。在本示例中,VLM 没有从图表中提取关键嵌入文本,即“2020 年乘客数量下降了 35% 到 65%”。

幻觉和重复
在某些情况下,VLM 生成的描述包含虚构的细节 (幻觉) 或不必要的重复短语,这会增加文本表示的噪音。在本例中,VLM 对标题“租赁空缺率趋势”产生了幻觉,并没有捕捉到图形描述。

提取不完全
对于表格,VLM 有时无法捕获整个结构或省略行/ 列,如一些收入数据集示例所示,其中仅转录了表格数据的一部分。
相比之下,NeMo Retriever 工作流中的专用模型旨在处理这些特定结构并通过 OCR 提取文本,从而实现更真实、更完整的表征以供检索。
效率和实际注意事项
除了准确性之外,现实世界的部署还取决于数百万页的处理速度和成本效益。
延迟会影响新文档在搜索结果中的显示速度。吞吐量会影响您需要的机器数量和支出。Token 数量会增加嵌入和重排序过程中的成本。为了进行比较,我们测量了延迟、每秒页面数吞吐量和 token 使用量方面的工作流。
性能
我们在单个 NVIDIA A100 GPU 上对两个工作流的端到端延迟和吞吐量性能进行了基准测试。OCR 工作流的端到端延迟为每页 0.118 秒,包括将 PDF 页面转换为图像、检测页面上的元素以及从元素中提取文本。
Llama 3.2 11B Vision Instruct VLM 的平均推理时间为每张图表图像 2.58 秒,每张表格图像 6.86 秒,每张信息图图像 6.60 秒。总体而言,在整个 DigitalCorpora 10K 数据集上,仅图像转文本步骤的平均处理时间为每页 3.81 秒,涵盖全部 21.3 万页。请注意,并非所有页面都包含图表、表格或信息图。
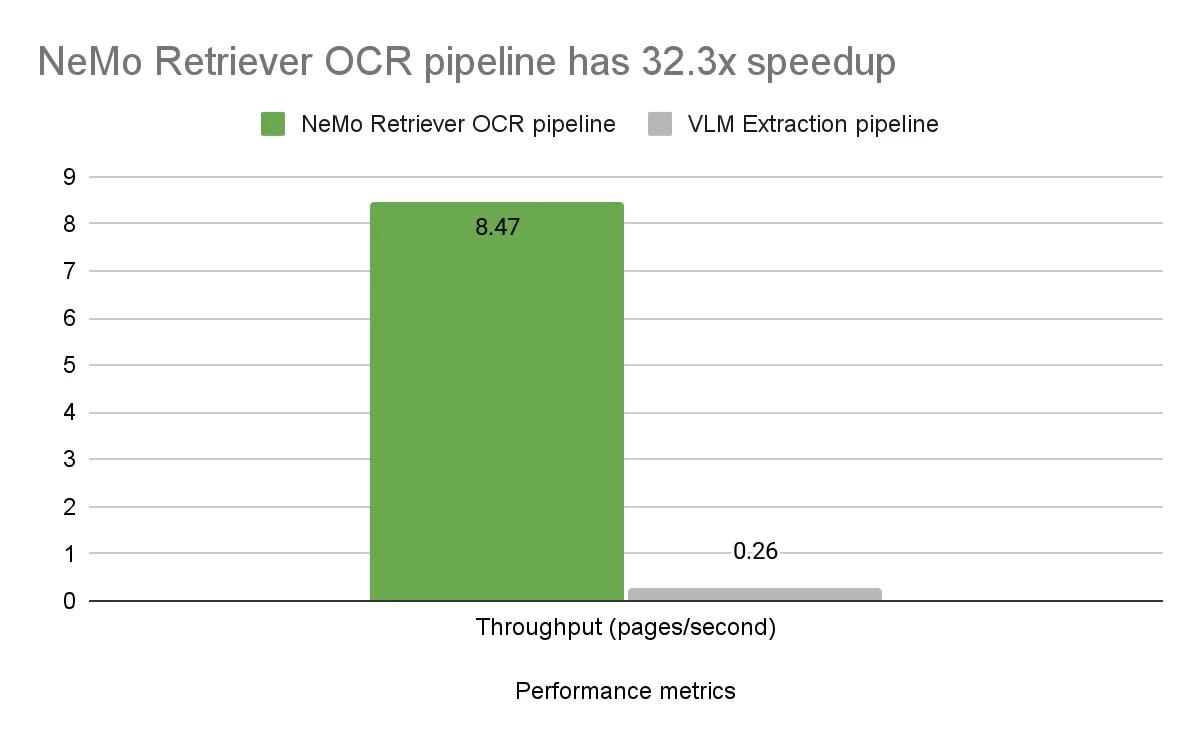
与更大的 VLM 模型相比,具有相对较小模型的 NeMo Retriever OCR 工作流的吞吐量明显更高,为 32.3 倍,延迟更低。
Token 使用情况
我们观察到,VLM 描述 (尤其是信息图描述) 生成的 token 通常比 OCR 基准多得多。VLM 倾向于描述视觉布局并添加叙事,而 OCR 方法则侧重于转录文本内容。这种增加的详细程度可能会在检索阶段嵌入和可选的重新排序期间导致更高的推理成本。
一致性
虽然 VLM 输出可能会有所不同 (由于非确定性因素,固定种子的输出甚至略有不同) ,但物体检测和 OCR 模型的确定性可提供更高的结果一致性。
其他观察结果
下文详细介绍了其他一些观察结果。
使用更大的 VLM
我们测试了将包含 110 亿个参数的 Llama 3.2 Vision 模型替换为包含 900 亿个参数的 Llama 3.2 90B Vision Instruct 模型。与直觉相反,这一变化并未提高数据集的检索召回性能。这表明,中型 11B 模型是一个强大的 VLM,足以完成此特定任务。
提示词的作用
众所周知,VLM 性能对提示很敏感。虽然我们的实验使用通用提示词来评估开箱即用的性能,但仔细的提示词工程和模型微调可能有助于缩小 VLM 和我们的专用 OCR 工作流之间的准确性差距,但不会缩小吞吐量差距。
OCR 限制
对于未来探索,一个有趣的观察结果涉及 OCR 方法达到极限的场景,特别是在提取未明确标注的信息时,例如从没有数字标签的图表中读取条形高度。例如,在初步实验中,我们发现 OCR 加上纯文本 LLM (Llama 3.1 Nemotron 70B Instruct) 检索到了正确的页面,但未能给出正确答案。
相比之下,大小相似的 VLM ( Llama 3.2 90B Vision Instruct) 直接使用视觉输入正确应答。这说明了 VLM 具有独特优势的领域。未来的研究可以系统评估 OCR 和 VLM 方法在此类多模态生成任务中的互补优势。

总结
我们比较了从复杂的 PDF 元素 (图表、表格和信息图) 中提取信息以进行下游文本检索的两种方法:
- 基于 OCR 的专用方法:NVIDIA NeMo Retriever PDF 提取工作流
- 基于 VLM 的通用方法与 Llama 3.2 11B Vision Instruct
作为检索工作流的一部分,我们对这两种方法进行了基准测试。虽然 VLM 并非专门为 PDF 转文本提取而设计,但它在无需额外微调的情况下展示了具有前景的文档解析能力。基于 OCR 的 NeMo Retriever 工作流对我们的测试数据集实现了更高的检索召回率,同时还在吞吐量、处理速度和推理效率方面提供了强大的性能优势。
NVIDIA 通过 NIM 微服务为开发者提供了一系列选项,包括用于专业提取任务的高度优化模型和功能强大的通用 VLM,使用户能够选择满足其特定需求的最佳方法。同样需要注意的是,专业提取模型和 VLM 都在迅速发展,文档理解的格局也将不断变化。
虽然此分析侧重于 RAG 工作流的检索部分,其中 OCR 方法目前具有明显的优势,但也存在互补用例,例如从复杂的视觉内容直接生成答案,其中 VLM 具有独特的优势。我们计划在后续的博文中探索 VLM 的互补优势。
开始使用 NVIDIA RAG Blueprint
准备好优化本文中讨论的 PDF 提取策略了吗?试用适用于 RAG 的 NVIDIA AI Blueprint,这是适用于基础 RAG 工作流的参考解决方案。此企业级参考实现提供了以下所需的所有组件:
- 使用您的数据集尝试不同的 PDF 提取方法。
- 利用先进的嵌入和嵌入重排序模型。
- 以更短的开发时间构建生产就绪型 PDF 提取工作流。






