大型语言模型( LLM ),如 GPT,由于其理解和生成类人文本的能力,已成为自然语言处理( NLP )中的革命性工具。这些模型基于大量不同的数据进行训练,使其能够学习模式、语言结构和上下文关系。它们是基础模型,可以针对广泛的下游任务进行定制,具有高度的通用性。
诸如分类之类的下游任务可以包括基于预定义标准对文本进行分析和分类,这有助于诸如情绪分析或垃圾邮件检测之类的任务。在封闭式问答( QA )中,他们可以根据给定的上下文提供精确的答案。在生成任务中,它们可以生成类似人类的文本,例如故事写作或诗歌创作。即使是头脑风暴, LLM 也可以利用其庞大的知识库产生创造性和连贯性的想法。
LLM 的适应性和多功能性使其成为广泛应用的宝贵工具,使企业、研究人员和个人能够以显著的效率和准确性完成各种任务。
这篇文章向您展示了 LLM 如何使用分布式数据集和联合学习来适应下游任务,以保护隐私并提高模型性能。
LLM 适应下游任务
参数高效的 LLM 微调已经成为使用特定于任务的模块的一种重要方法,其中保持预训练的 LLM 层固定,同时使较小的附加参数集适应手头的特定任务。为了促进这一过程,已经开发了各种技术,包括prompt tuning,p-tuning,adapters,LoRA等。
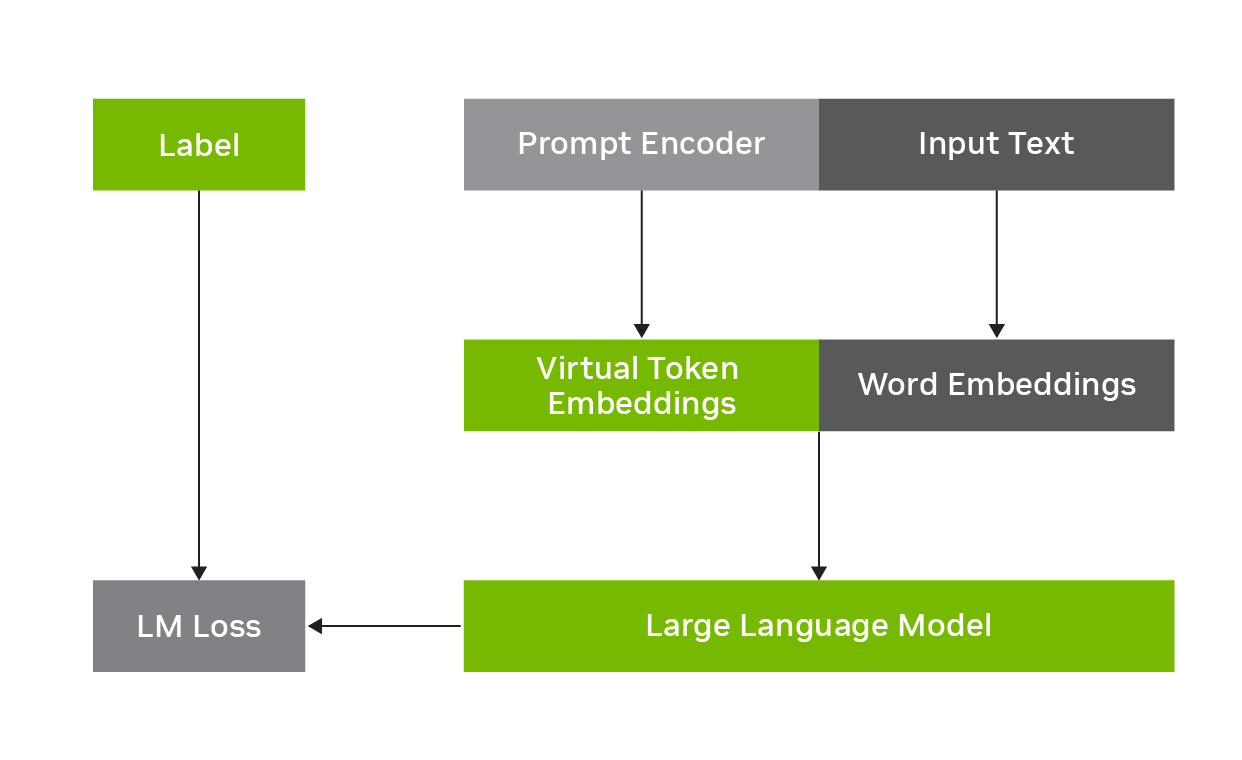
例如, p 调整包括冻结 LLM 并学习预测与原始输入文本组合的虚拟令牌嵌入,如图 1 所示.任务特定的虚拟令牌嵌入由提示编码器网络预测,该网络与输入单词嵌入一起被馈送到 LLM 中,以在推理时增强下游任务的性能。它是参数有效的,因为只有提示编码器参数必须在输入文本和标签上进行训练,而基本 LLM 参数可以保持固定。
联合学习
由于监管限制和复杂的官僚程序,使用私人数据训练人工智能模型带来了重大挑战。隐私法规和数据保护法通常禁止共享敏感信息,限制了传统数据共享方法的可行性。此外,数据注释是模型训练的一个关键方面,它会产生巨大的成本,并需要大量的时间和精力。
认识到数据是一种宝贵的资产,联合学习(FL)已经成为一种解决这些问题的技术。FL 通过共享模型而不是原始数据来绕过传统的模型训练过程。参与的客户端使用它们各自的私有数据集在本地训练模型,并聚合更新的模型参数,从而保护底层数据的隐私,同时共同受益于培训过程中获得的知识。
不需要直接的数据交换,这降低了与数据隐私法规相关的合规风险,并在联盟中的合作者之间分配了繁重的数据注释成本。
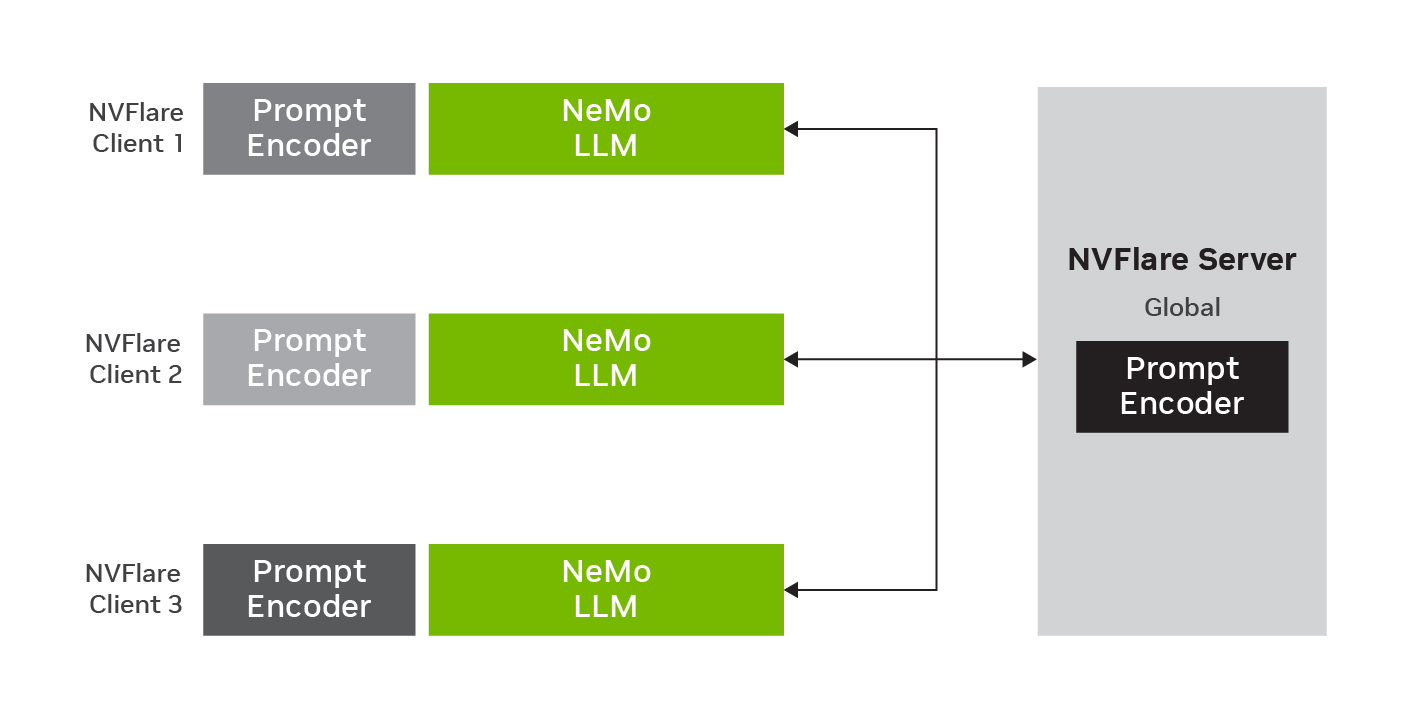
图 2 显示了具有全局模型和三个客户端的联合 p 调谐。 LLM 参数保持固定,同时在本地数据上训练提示编码器参数。在本地训练之后,新参数在服务器上聚合,以更新全局模型,用于下一轮联合学习。
将 LLM 的适应性与下游任务联合起来
FL 通过利用去中心化的数据源使 LLM 能够适应下游任务。通过在不共享原始数据的情况下跨多个参与者协作训练 LLM ,可以通过利用集体知识和将模型暴露于更广泛的语言模式来增强 LLM 的准确性、稳健性和可推广性(图 2 )。此外, FL 还提供了各种模型自适应和推理选项,包括基于聚合数据训练的全局模型和为个人客户量身定制的个性化模型。
情绪分析的联合 p 调谐
本节提供了 LLM 的联合自适应示例,使用 NVIDIA NeMo 框架 对具有下游任务的 NVIDIA Flare 进行 p 调谐。NeMo 和 NVIDIA Flare 都是由 NVIDIA 开发的开源工具包。此微调过程非常有效,因为只需要交换几十万个参数,大大减少了通信负担。
在这个情绪分析任务中,可以使用 p 调谐有效地微调 NeMo Megatron-GPT 模型,它具有 200 亿个参数。它使用 Financial PhraseBank dataset,其中包含了从散户投资者的角度对财经新闻标题的看法。更多详细信息,请参阅 Good Debt or Bad Debt: Detecting Semantic Orientations in Economic Texts。
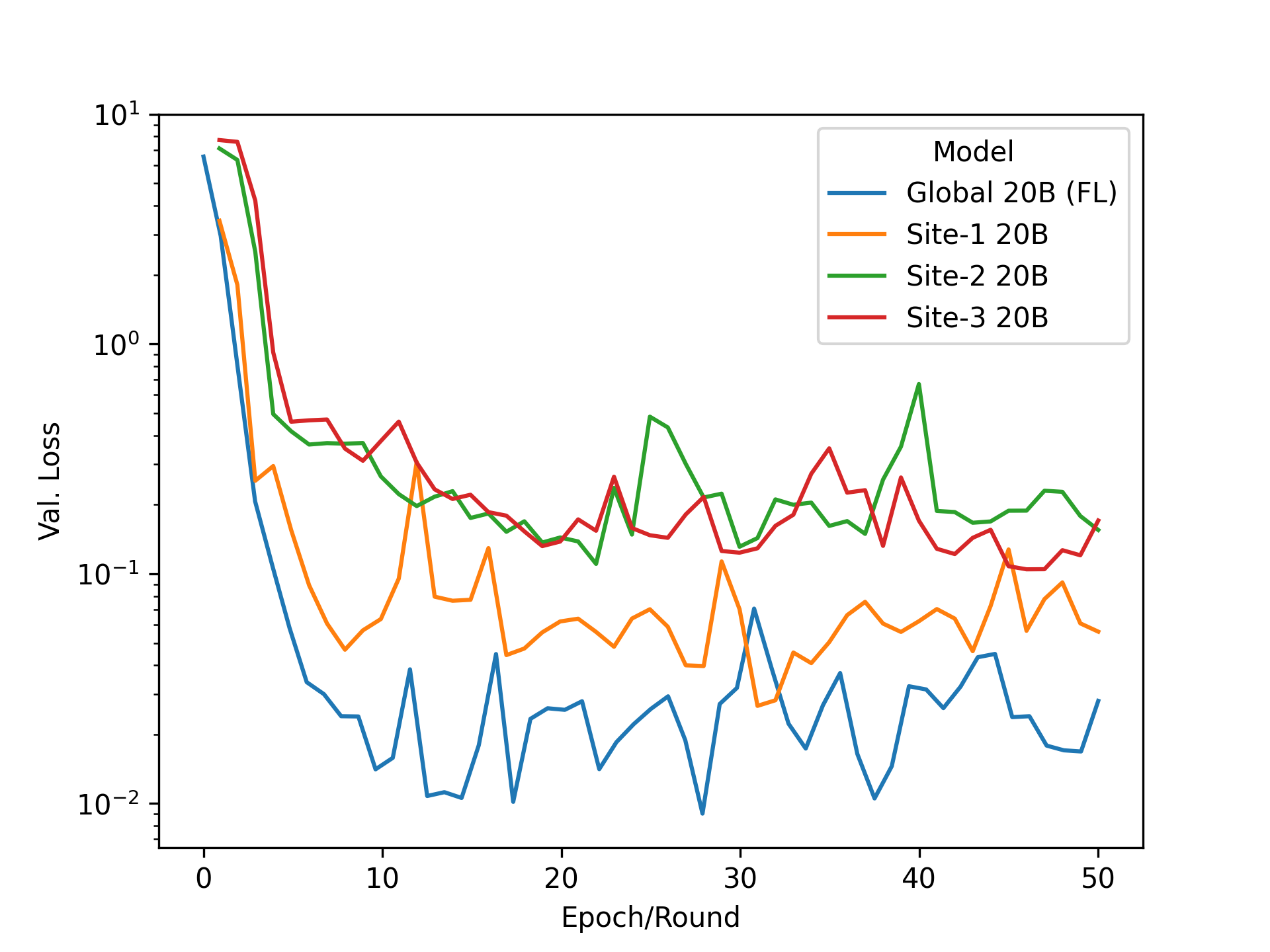
示例输入和模型预测如图 3 所示。该数据总共包含 1800 对标题和相应的情绪标签。在 p 调谐中,仅更新可训练提示编码器网络的 5000 万个参数(整个 20B 参数的 0 . 25% )。对于 FL 实验,数据被分为三组,对应于每个网站的 600 个标题和情感对。客户端使用相同的验证集来启用直接比较。

图 4a 比较了以集中方式训练模型与联合模型 50 个时期(或 FL 轮)的情况。在这两种设置中,自适应模型在下游任务上的表现相当,在验证集上实现了类似的低损失。图 4b 将每个客户端仅在其本地数据集上进行的训练与使用 FL 进行 p 调谐的模型进行了比较。通过有效地利用协作中可用的较大训练集,并实现比仅在其数据上进行训练更低的损失,可以看出使用联合 p 调谐的全局模型的明显优势。
结论
总的来说,这篇文章强调了联邦 p 调整在使 LLM 适应下游任务方面的潜力,强调了 FL 在实现协作学习以保护隐私和提高模型性能方面的好处。一些关键要点是:
- GPT 等大型语言模型彻底改变了 NLP ,为分类、问答、生成和头脑风暴等各种下游任务提供了多功能性。
- 联合学习通过共享模型参数而不是原始数据来解决与私人数据相关的挑战,确保隐私并降低合规风险。
- 使用特定任务模块(如即时调整或 p 调整)对 LLM 进行微调,可以有效地适应特定任务。
- FL 促进了协作训练和推理,从而提高了模型性能。
有关详细信息,请参阅NVIDIA Flare documentation和NVIDIA NeMo framework page。要复制此处解释的实验和其他 LLM 任务,请探索Examples of NeMo-NVFlare Integration这里提出的联合 p 调谐方法可以进一步与附加的privacy-preservingNVIDIA Flare 提供的解决方案,例如homomorphic encryption和differential privacy。要了解更多信息,请参阅NVIDIA FLARE: Federated Learning from Simulation to Real-World.