一个常见的技术误区是,性能和复杂性直接相关。也就是说,高性能的实现也是实现和管理最具挑战性的。但是,在考虑数据中心网络时,情况并非如此。
与以太网相比,InfiniBand 可能听起来令人生畏且新奇,但它实际上是更易于部署和维护的,因为它从一开始就是为了实现最高性能而设计的。当您考虑 AI 基础设施的连接时,InfiniBand 集群操作和维护指南可以帮助您尽可能简化全栈 InfiniBand 网络的设置和操作。
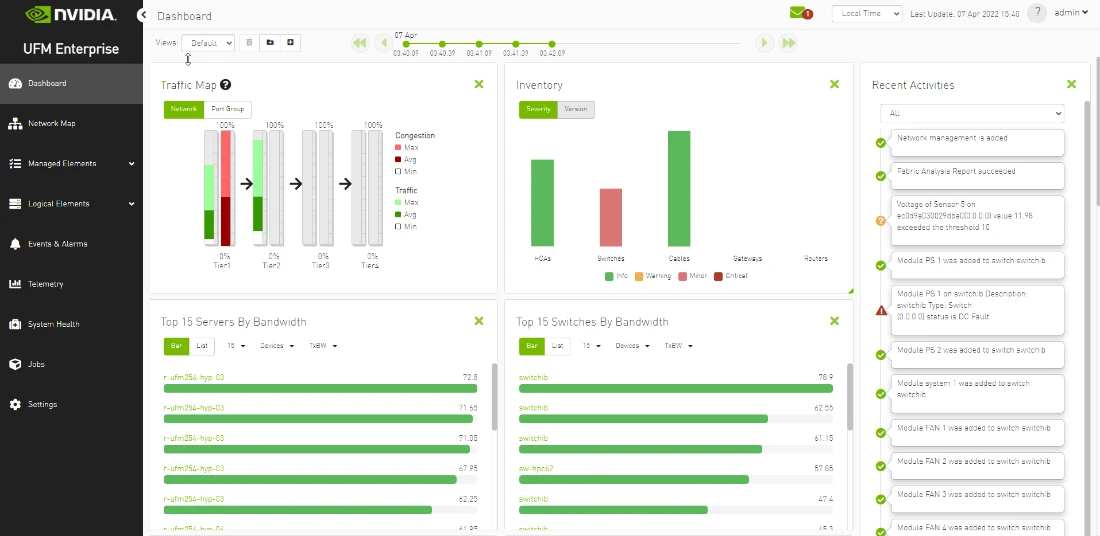
本指南全面介绍了简化网络运营的基本步骤,特别详细介绍了如何使用 NVIDIA Unified Fabric Manager(UFM)来协助初始配置和持续维护计划,适用于第 0 天、第 1 天和第 2 天的网络运营。
UFM 是一个功能强大的工具集,具有广泛的遥测和分析功能。但是,开始使用 UFM 了解集群监控和管理的基础知识不需要任何高级前提条件或专业知识。
集群构建和操作
本指南将为您介绍启动设置:
- 验证 UFM 运行状态
- 生成网络运行状况报告和拓扑验证
- 验证集群性能
该指南还介绍了使用 UFM Telemetry 进行拥塞分析。UFM 遥测和监控功能非常强大。Grafana、Fluentd、Slurm 和 Zabbix 等工具的第三方插件使您能够捕获重要的网络指标,并将其用于您选择的平台。
当管理员知道集群处于正常初始状态时,本指南会建议集群维护机制,并提供定期维护检查列表。
一分钟/持续维护:
- 检查故障排除列表中的场景,并按照说明进行解决。
每周维护:
- 监控链路监控关键指标的趋势(可在 UFM 用户界面中获取)。
- 运行集群拓扑验证检查和网络运行状况验证测试。
- 使用 ClusterKit (包含在 HPC-X 中)验证性能 KPI 软件包)。
- 检查 UFM 中捕获的温差,确保您的冷却系统正常工作。
季度/年度维护:
- 查看最新的固件和软件版本说明,以及经过验证的配置,并在可能的情况下进行升级。请访问此链接获取更多信息。
- 通过联系 NVIDIA 网络支持人员或您指定的 NVIDIA 联系人,对 NVIDIA 网络运行状况进行年度审查
其中许多检查都可以通过 API 实现自动化和配置。本指南提供了指向适当检查的链接,UFM API 文档 使这种设置变得简单、无缝。
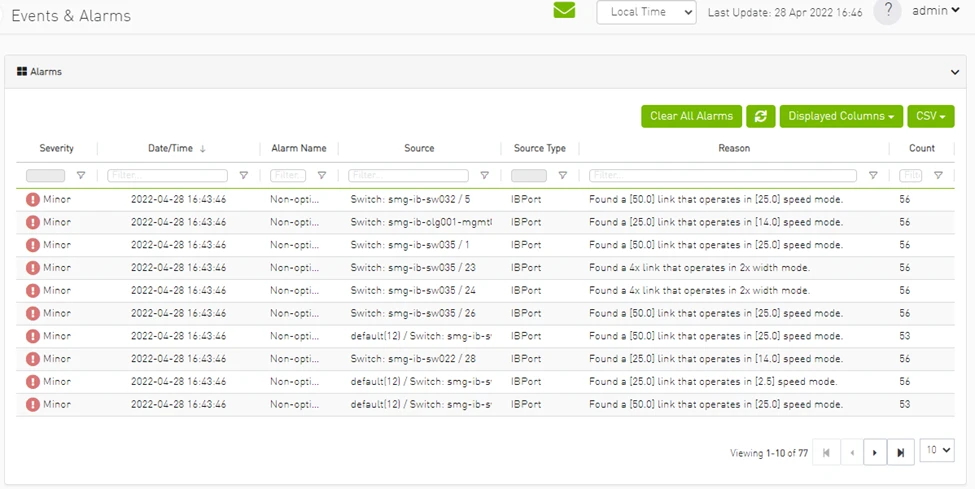
问题解决
当然,没有完美的系统。即使是运行良好的机器(如 InfiniBand 集群),也经常会遇到意想不到的问题。
但是,作为管理员,集群维护指南是您的一站式商店。它包括一个章节,描述了最常见的场景,以及如何解决这些场景。本节包括场景以及如何检测它(使用相应的 UFM 警报事件 ID),然后是达成解决方案的一系列步骤。它涵盖了简单和常见的错误,如端口错误、拍击链路和线缆连接问题,以及性能降低或带宽低等更复杂的挑战。
总结
在构建网络时,性能是一个关键的考虑因素,但不必将性能和易用性视为权衡。
InfiniBand 易于为 AI 采用、部署和操作。利用 UFM 的强大功能,集群操作和维护指南包含网络管理员需要了解的所有内容。它比打开网络认证课本简单得多,因为集群指南不到 40 页。
考虑为您的 AI 基础架构选择简单易用的 NVIDIA Quantum InfiniBand.