
大语言模型(LLM)处于人工智能创新的前沿,但其庞大的规模往往会影响推理效率。例如,Llama 3 70B 和 Llama 4 Scout 109B 等模型在处理大型上下文窗口时,可能需要超出常规 GPU 承载能力的内存。
例如,以半精度(FP16)加载 Llama 3 70B 和 Llama 4 Scout 109B 模型,分别需要约 140 GB 和 218 GB 的内存。在推理过程中,这些模型通常还需维护额外的数据结构,例如键值(KV)缓存,其显存占用会随着上下文长度和批量大小的增加而增长。以 Llama 3 70B 为例,当处理单个用户的 128k token 上下文窗口(批量大小为 1)时,KV 缓存将占用约 40 GB 显存,且随着用户数量的增加呈线性增长。在生产环境中,若尝试将此类大型模型完全加载至 GPU 显存中,很可能因显存容量不足而引发显存溢出(OOM)错误。
在 NVIDIA Grace Blackwell 和 NVIDIA Grace Hopper 架构中,CPU 与 GPU 通过 NVIDIA NVLink C2C 实现互联。NVLink-C2C 的内存一致性技术支持 CPU 和 GPU 共享统一的内存地址空间(如图 1 所示),使两者能够直接访问和操作相同的数据,无需显式的数据传输或重复的内存复制。
该设置使得大型数据集和模型能够更便捷地被访问和处理,即使其规模超出传统 GPU 显存的容量限制。Grace Hopper 和 Grace Blackwell 中通过 NVLink-C2C 实现的高带宽连接与统一内存架构,显著提升了大语言模型微调、KV 缓存卸载、推理以及科学计算等任务的效率。这种架构不仅支持数据在组件间的快速传输,还可在 GPU 显存不足时灵活利用 CPU 内存,从而保障高性能运行。
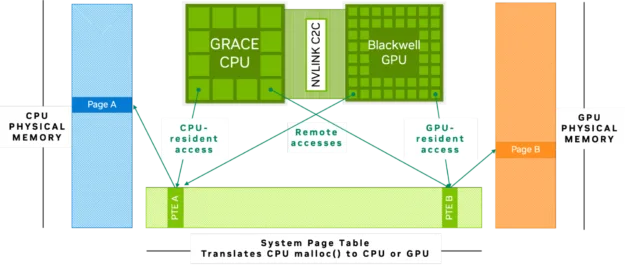
例如,当在采用统一内存架构的 NVIDIA GH200 Grace Hopper 超级芯片等平台上加载模型时,系统可利用 96 GB 的高带宽 GPU 显存,并直接访问连接至 CPU 的 480 GB LPDDR 内存,无需显式的数据传输操作。这种架构扩展了总体可用内存,使得处理那些仅依靠 GPU 难以容纳的大型模型和数据集成为可能。
代码演示
在本博文中,我们将以 Llama 3 70B 模型和 GH200 超级芯片为例,展示如何利用统一显存将大型模型流式加载至 GPU,并阐释前述相关概念。
入门指南
首先,我们需要配置环境并接入 Llama 3 70B 模型。请注意,以下代码示例专为在搭载 NVIDIA Grace Hopper GH200 超级芯片的机器上运行而设计,旨在展示其统一内存架构的优势。相同的技术同样适用于基于 NVIDIA Grace Blackwell 的系统。<!–
这包含几个简单的步骤:
- 从 Hugging Face 申请模型访问权限:访问 Hugging Face 上的 Llama 3 70B 模型页面,申请访问权限。
- 生成访问令牌:请求获得批准后,请在 Hugging Face 帐户设置中创建访问令牌。此令牌将用于以编程方式验证您对模型的访问权限。
- 安装所需的软件包:在与模型交互之前,请安装必要的 Python 库。在 GH200 计算机上打开 Jupyter notebook 并运行以下命令:
#Install huggingface and cuda packages
!pip install --upgrade huggingface_hub
!pip install transformers
!pip install nvidia-cuda-runtime-cu12
- 登录 Hugging Face: 安装软件包后,使用您生成的令牌登录 Hugging Face。huggingface_hub 库提供了一种便捷的方法来执行此操作:
#Login into huggingface using the generated token
from huggingface_hub import login
login("enter your token")将 Llama 3 70B 模型加载到 GH200 上时会发生什么情况?
当您尝试将 Llama 3 70B 模型加载到 GPU 显存中时,系统会将模型的参数(即权重)载入 NVIDIA CUDA 显存。在半精度(FP16)格式下,这些权重大约需要 140 GB 的显存空间。然而,GH200 仅提供 96 GB 显存,不足以容纳整个模型,因此模型无法完全加载,系统将因显存不足而抛出 OOM 错误。在下一单元中,我们将通过代码示例演示这一现象。
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="meta-llama/Llama-3.1-70B") #loads the model into the GPU memory执行上述命令后,将看到以下错误信息:
Error message:
OutOfMemoryError: CUDA out of memory. Tried to allocate 896.00 MiB. GPU 0 has a total capacity of 95.00 GiB of which 524.06 MiB is free. Including non-PyTorch memory, this process has 86.45 GiB memory in use. Of the allocated memory 85.92 GiB is allocated by PyTorch, and 448.00 KiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management.从错误信息可以看出,GPU 显存已接近上限。您可以通过执行以下命令来进一步确认 GPU 显存的使用情况:
!nvidia-smi运行命令后,您应获得与下图类似的输出结果。该输出显示,我们在 GPU 上的显存使用量达到了 97.871 GB,超过了 96.746 GB 的可用显存。请参考此论坛,以更好地理解如何解读输出内容。
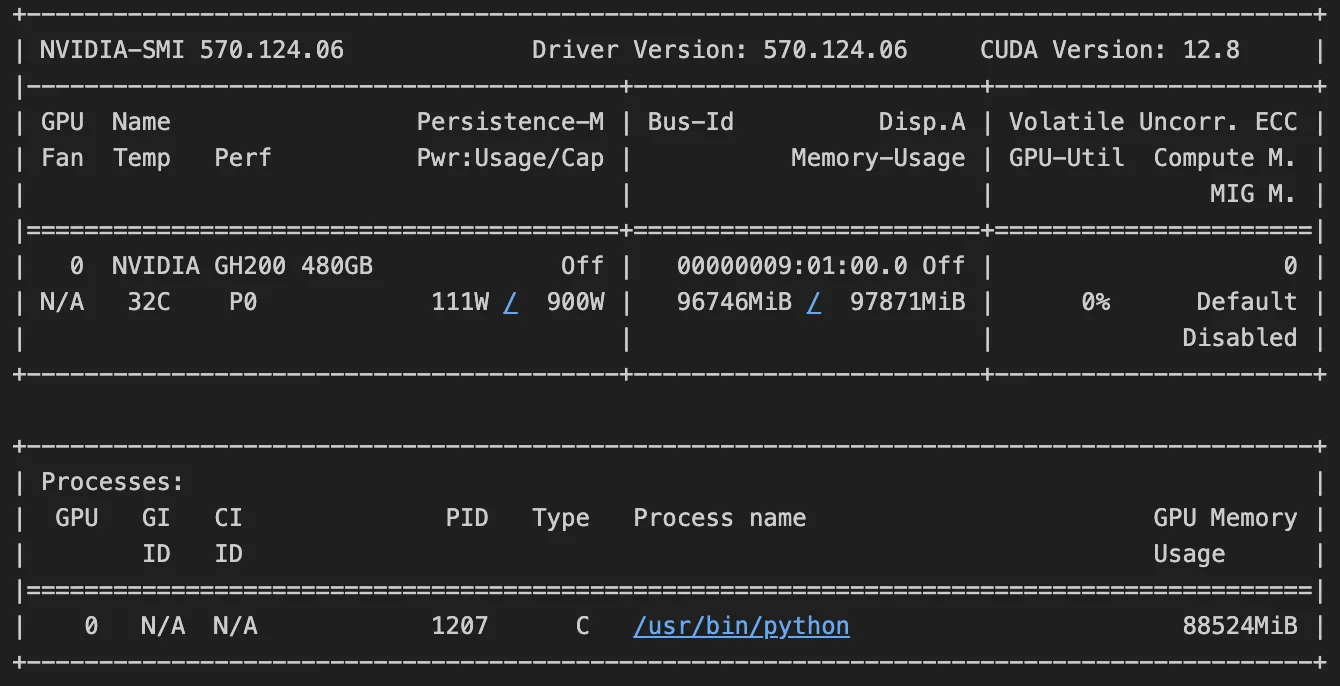
为了准备后续步骤并释放 GPU 显存,我们将清除当前失败尝试中残留的所有变量。请在以下命令中将 <PID> 替换为您的 Python 进程 ID,该 ID 可通过运行 !nvidia-smi 命令获取。
!kill -9 <PID>如何解决这个内存溢出错误?
该问题可通过使用托管内存分配来解决,这种分配方式允许 GPU 在访问自身内存的同时,也能访问 CPU 的内存。在 GH200 系统上,统一内存架构使 CPU(最高可达 480 GB)和 GPU(最高可达 144 GB)能够共享单一地址空间,并透明地访问彼此的内存。通过将 RAPIDS Memory Manager(RMM)库配置为使用托管内存,开发者可以分配同时被 CPU 和 GPU 访问的内存,从而使工作负载突破物理 GPU 内存的限制,而无需进行手动数据传输。
import rmm
import torch
from rmm.allocators.torch import rmm_torch_allocator
from transformers import pipeline
rmm.reinitialize(managed_memory=True) #enabling access to CPU memory
torch.cuda.memory.change_current_allocator(rmm_torch_allocator)
#instructs PyTorch to use RMM memory manager to use unified memory for all memory allocations
pipe = pipeline("text-generation", model="meta-llama/Llama-3.1-70B")运行模型加载命令时,我们不会遇到 OOO 内存错误,因为我们现在可以访问更大的内存空间。
现在,您可以通过命令向大语言模型发送提示并接收其响应。
pipe("Which is the tallest mountain in the world?")总结
随着模型规模的持续扩大,将模型参数加载到 GPU 已成为一项重大挑战。本文探讨了统一显存架构如何通过让 GPU 无需显式数据传输即可访问 CPU 内存与自身显存,突破这一限制,从而更高效地在现代硬件上运行先进的大语言模型。
如需详细了解如何管理 CPU 和 GPU 显存,建议参考 Rapid Memory Manager 的相关文档。








