
코드 한 줄로 추론 속도를 높여주는 NVIDIA TensorRT와 PyTorch의 새로운 통합인 Torch-TensorRT가 매우 기대됩니다. PyTorch는 오늘날 전 세계 수백만 명이 사용하는 최고의 딥 러닝 프레임워크입니다. TensorRT는 데이터센터, 임베디드 및 오토모티브 디바이스에서 실행되는 GPU 가속 플랫폼에서 고성능 딥 러닝 추론을 위한 SDK입니다. 이런 통합 덕분에 PyTorch 사용자는 TensorRT를 사용할 때 간소화된 워크플로우를 통해 매우 높은 추론 성능을 경험할 수 있습니다.
Torch-TensorRT란?
Torch-TensorRT는 NVIDIA GPU에서 TensorRT의 추론 최적화를 활용하는 PyTorch용 통합입니다. 또한 코드 한 줄만으로 NVIDIA GPU에서 성능을 최대 6배 향상해주는 간단한 API를 제공합니다.
이 통합은 감소된 정밀도 FP16, INT8 등의 TensorRT 최적화를 활용하는 동시에, TensorRT가 모델 하위 그래프를 지원하지 않을 때 기본 PyTorch로 폴백하도록 지원합니다. 간단한 개요는 NVIDIA Torch-TensorRT 시작하기 영상을 참조하세요.
Torch-TensorRT의 작동 방식
Torch-TensorRT는 TorchScript의 확장 기능으로 작동합니다. 또한 호환 가능한 하위 그래프를 최적화하고 실행하여 PyTorch가 나머지 그래프를 실행할 수 있도록 합니다. PyTorch의 포괄적이고 유연한 기능 세트는 모델을 구문 분석하고 그래프에서 TensorRT와 호환 가능한 부분을 최적화하는 Torch-TensorRT와 함께 사용됩니다.
컴파일 후 최적화된 그래프를 사용하는 것은 TorchScript 모듈을 실행하는 것과 같으며 사용자는 더 나은 TensorRT 성능을 경험할 수 있습니다. Torch-TensorRT 컴파일러의 아키텍처는 호환 가능한 하위 그래프를 위한 다음 세 단계로 구성됩니다.
- TorchScript 모듈 낮추기
- 변환하기
- 실행하기
TorchScript 모듈 낮추기
첫 번째 단계에서 Torch-TensorRT는 TorchScript 모듈을 낮춤으로써, TensorRT로 더 직접 매핑되는 표현에 공통 연산을 구현하는 작업을 간소화합니다. 이렇게 패스가 낮아져도 그래프 자체의 기능에는 영향을 미치지 않는다는 사실에 유의해야 합니다.

{kind=link}
변환하기
변환 단계에서 Torch-TensorRT는 다음과 같이 TensorRT와 호환 가능한 하위 그래프를 자동으로 식별하여 TensorRT 작업으로 변환합니다.
- 정적 값이 있는 노드가 계산되고 상수로 매핑됩니다.
- Tensor 계산을 나타내는 노드는 하나 이상의 TensorRT 레이어로 변환됩니다.
- 나머지 노드는 TorchScripting에 남아 표준 TorchScript 모듈로 반환되는 하이브리드 그래프를 형성합니다.
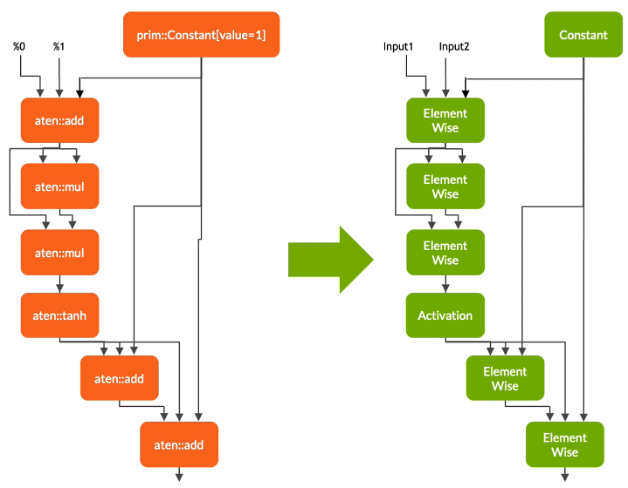
수정된 모듈은 TensorRT 엔진이 임베디드된 상태로 반환됩니다. 즉, PyTorch 코드, 모델 가중치, TensorRT 엔진 등 전체 모델이 단일 패키지로 포팅될 수 있습니다.
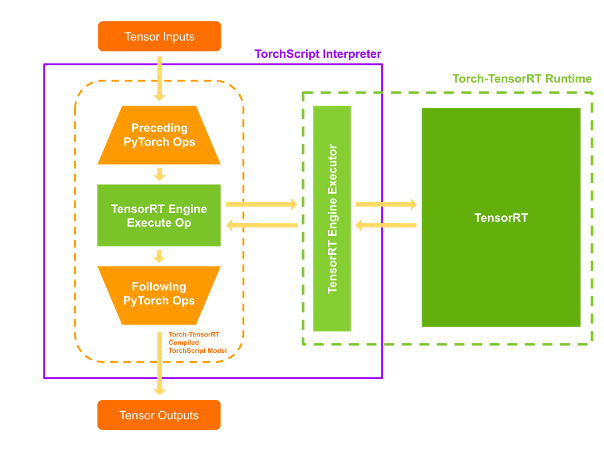
실행하기
컴파일된 모듈을 실행하면 Torch-TensorRT는 엔진이 실행 가능한 라이브 상태가 되도록 설정합니다. 수정된 TorchScript 모듈을 실행하면 TorchScript 인터프리터가 TensorRT 엔진을 호출하고 모든 입력을 전달합니다. 엔진이 실행되고 일반 TorchScript 모듈처럼 인터프리터에 결과를 다시 푸시합니다.
Torch-TensorRT 기능
Torch-TensorRT에는 INT8 및 희소성 지원과 같은 기능이 도입되었습니다.
INT8 지원
Torch-TensorRT는 다음 두 가지 기술을 통해 저정밀도 추론 지원을 확장합니다.
- 트레이닝 후 양자화(PTQ)
- 양자화 인식 트레이닝(QAT)
PTQ의 경우 TensorRT는 대상 도메인의 샘플 데이터로 모델을 실행하는 보정 단계를 사용합니다. IT는 FP32의 활성화를 추적하여 FP32와 INT8 추론 사이의 정보 손실을 최소화하는 INT8에 대한 매핑을 보정합니다. TensorRT 애플리케이션을 사용하려면 TensorRT 보정기에 샘플 데이터를 제공하는 보정기 클래스를 작성해야 합니다.
Torch-TensorRT는 PyTorch의 기존 인프라를 사용하여 보정기를 더 쉽게 구현할 수 있습니다. LibTorch는 전처리·배치 입력 데이터를 간소화하는 DataLoader 및 Dataset API를 제공합니다. 이런 API는 C++ 및 Python 인터페이스를 통해 노출되므로 PTQ를 더 쉽게 사용할 수 있습니다. 자세한 내용은 트레이닝 후 양자화(PTQ)를 참조하세요.
QAT의 경우 TensorRT에는 PyTorch의 양자화 관련 Ops를 TensorRT에 매핑하는 새로운 API인 QuantizeLayer 및 DequantizeLayer가 도입되었습니다. aten:fake_quantize_per_*_affine과 같은 연산은 내부적으로 Torch-TensorRT를 통해 QuantizeLayer + DequantizeLayer로 변환됩니다. Torch-TensorRT를 사용하여 PyTorch QAT 기술로 트레이닝된 모델을 최적화하는 방법에 대한 자세한 내용은 Torch-TensorRT를 사용하여 INT8에 양자화 인식 트레이닝 모델 배포를 참조하세요.
희소성
NVIDIA Ampere 아키텍처는 네트워크 가중치에서 세분화된 희소성을 사용하는 NVIDIA A100 GPU에 3세대 Tensor 코어를 도입합니다. 딥 러닝의 핵심인 행렬 곱셈 누적 작업의 정확도를 낮추지 않으면서도 고밀도 수학 처리량을 최대로 제공합니다.
- TensorRT는 이런 Tensor 코어에서 딥 러닝 모델의 일부 희소 레이어를 등록하고 실행하는 작업을 지원합니다.
- Torch-TensorRT는 컨볼루션 레이어와 완전 연결 레이어에 대한 지원을 확장합니다.
예시: 이미지 분류를 위한 처리량 비교
이 게시물에서는 EfficientNet이라는 이미지 분류 모델을 통해 추론 작업을 진행하며 PyTorch, TorchScript JIT, Torch-TensorRT가 모델을 내보내고 최적화할 때 발생하는 처리량을 계산합니다. 자세한 내용은 Torch-TensorRT GitHub 리포지토리의 엔드 투 엔드 예시 노트북을 참조하세요.
설치 및 전제 조건
이 단계를 수행하려면 다음 리소스가 필요합니다.
- NVIDIA GPU, 컴퓨팅 아키텍처 7 이하 버전이 탑재된 Linux 시스템
- 19.03 이상 버전으로 설치된 Docker
- PyTorch, Torch-TensorRT, 그리고 NGC 카탈로그에서 가져온 모든 종속성을 갖춘 Docker 컨테이너
지침에 따라 nvcr.io/nvidia/pytorch:21.11-py3 태그가 지정된 Docker 컨테이너를 실행합니다.
Docker 컨테이너에 라이브 bash 터미널이 생성되었으므로 JupyterLab 인스턴스를 시작하고 Python 코드를 실행합니다. 포트 8888을 통해 JupyterLab을 시작하고 토큰을 TensorRT로 설정합니다. 브라우저에서 JupyterLab의 그래픽 사용자 인터페이스에 간편하게 액세스할 수 있는 시스템 IP 주소를 확보합니다.
Jupyter lab --allow-root --IP=0.0.0.0 --NotebookApp.token=’TensorRT’ --port 8888브라우저에서 포트 8888을 통해 이 IP 주소로 이동합니다. 로컬 시스템에서 이 예시를 실행 중인 경우 Localhost:8888로 이동합니다.
브라우저에서 JupyterLab의 그래픽 사용자 인터페이스에 연결하고 나면 새로운 Jupyter 노트북을 만들 수 있습니다. 사전 트레이닝된 컴퓨터 비전 모델, 가중치, 스크립트가 포함된 PyTorch 라이브러리인 timm을 설치하는 것부터 시작합니다. 이 라이브러리에서 EfficientNet-b0 모델을 가져옵니다.
pip install timm관련 라이브러리를 가져와서 EfficientNet-b0용 PyTorch nn.Module 개체를 만듭니다.
import torch
import torch_tensorrt
import timm
import time
import numpy as np
import torch.backends.cudnn as cudnn
torch.hub._validate_not_a_forked_repo=lambda a,b,c: True
efficientnet_b0 = timm.create_model('efficientnet_b0',pretrained=True)이 efficientnet_b0 개체의 forward 메서드에 임의의 부동 숫자 Tensor를 전달하여 이 모델로부터 예측값을 구합니다.
model = efficientnet_b0.eval().to("cuda")
detections_batch = model(torch.randn(128, 3, 224, 224).to("cuda"))
detections_batch.shape이렇게 하면 128개의 샘플과 1,000개의 클래스에 해당하는 [128, 1000]의 Tensor가 반환됩니다.
PyTorch JIT 컴파일 메서드와 Torch-TensorRT AOT 컴파일 메서드를 모두 활용하여 이 모델을 벤치마크하려면 간단한 벤치마크 유틸리티 함수를 작성합니다.
cudnn.benchmark = True
def benchmark(model, input_shape=(1024, 3, 512, 512), dtype='fp32', nwarmup=50, nruns=1000):
input_data = torch.randn(input_shape)
input_data = input_data.to("cuda")
if dtype=='fp16':
input_data = input_data.half()
print("Warm up ...")
with torch.no_grad():
for _ in range(nwarmup):
features = model(input_data)
torch.cuda.synchronize()
print("Start timing ...")
timings = []
with torch.no_grad():
for i in range(1, nruns+1):
start_time = time.time()
pred_loc = model(input_data)
torch.cuda.synchronize()
end_time = time.time()
timings.append(end_time - start_time)
if i%10==0:
print('Iteration %d/%d, avg batch time %.2f ms'%(i, nruns, np.mean(timings)*1000))
print("Input shape:", input_data.size())
print('Average throughput: %.2f images/second'%(input_shape[0]/np.mean(timings)))이제 이 모델에서 추론 작업을 진행할 준비가 되었습니다.
PyTorch 및 TorchScript를 사용한 추론
먼저 PyTorch 모델을 그대로 사용하고 배치 크기 1의 평균 처리량을 계산합니다.
model = efficientnet_b0.eval().to("cuda")
benchmark(model, input_shape=(1, 3, 224, 224), nruns=100)
TorchScript JIT 모듈에도 동일한 단계를 반복할 수 있습니다.
traced_model = torch.jit.trace(model, torch.randn((1,3,224,224)).to("cuda"))
torch.jit.save(traced_model, "efficientnet_b0_traced.jit.pt")
benchmark(traced_model, input_shape=(1, 3, 224, 224), nruns=100)
PyTorch와 TorchScript JIT를 통해 보고된 평균 처리량은 비슷합니다.
Torch-TensorRT를 사용한 추론
Torch-TensorRT를 사용하여 혼합 정밀도로 모델을 컴파일하려면 다음 명령을 실행합니다.
trt_model = torch_tensorrt.compile(model,
inputs= [torch_tensorrt.Input((1, 3, 224, 224))],
enabled_precisions= { torch_tensorrt.dtype.half} # Run with FP16
)
마지막으로 이 Torch-TensorRT 최적화 모델을 벤치마크합니다.
benchmark(trt_model, input_shape=(1, 3, 224, 224), nruns=100, dtype="fp16")
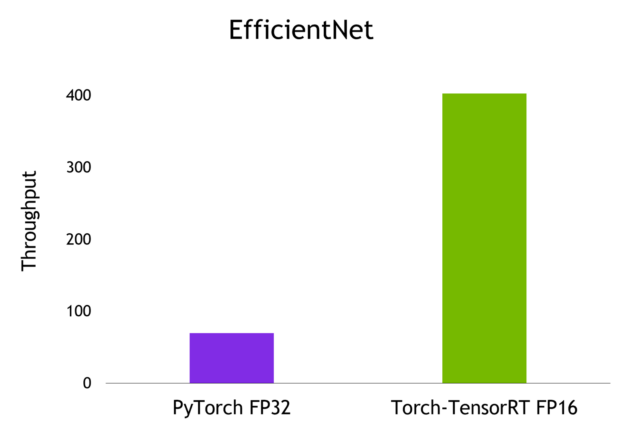
벤치마크 결과
다음은 배치 크기가 1인 NVIDIA A100 GPU에서 달성한 결과입니다.
요약
코드 한 줄만으로 최적화되는 Torch-TensorRT는 모델 성능을 최대 6배 향상해줍니다. 또한 PyTorch을 쉽고 유연하게 사용하면서도 최고 성능의 NVIDIA GPU를 경험할 수 있도록 지원합니다.
여러분의 모델에서 사용해 보고 싶으신가요? PyTorch NGC 컨테이너에서 Torch-TensorRT를 다운로드하여 코드 변경 없이도 TensorRT 최적화를 통해 PyTorch 추론 속도를 높일 수 있습니다.
이 블로그에 열거된 SDK의 대부분의 독점 액세스, 얼리 액세스, 기술 세션, 데모, 교육 과정, 리소스는 NVIDIA 개발자 프로그램 회원은 무료로 혜택을 받으실 수 있습니다. 지금 무료로 가입하여 NVIDIA의 기술 플랫폼에서 구축하는 데 필요한 도구와 교육에 액세스하시고 여러분의 성공을 가속화 하세요.