
생성형 AI의 동적 영역에서 확산 모델은 텍스트 프롬프트가 포함된 고품질 이미지를 생성하기 위한 가장 강력한 아키텍처로 각광받고 있습니다. 안정적 확산과 같은 모델은 크리에이티브 애플리케이션에 혁신을 가져왔습니다.
그러나 확산 모델의 추론 프로세스는 반복적인 노이즈 제거 단계가 필요하기 때문에 계산 집약적일 수 있습니다. 이는 최적의 엔드투엔드 추론 속도를 달성하기 위해 노력하는 기업과 개발자에게 상당한 과제를 제시합니다.
NVIDIA TensorRT 9.2.0부터는 이미지 품질을 유지하면서 NVIDIA 하드웨어에서 확산 배포 속도를 크게 높일 수 있도록 향상된 8비트(FP8 또는 INT8) 훈련 후 양자화(PTQ)를 갖춘 동급 최고의 양자화 툴킷을 개발했습니다. TensorRT의 8비트 양자화 기능은 특히 크리에이티브 비디오 편집 애플리케이션을 제공하는 선도적인 업체들 사이에서 많은 생성형 AI 회사들이 선호하는 솔루션이 되었습니다.
이 게시물에서는 Stable Diffusion XL을 사용한 TensorRT의 성능에 대해 설명합니다. 또한 지연 시간이 짧은 안정적인 확산 추론을 위해 TensorRT가 최고의 선택이 될 수 있는 기술적 차별화 요소에 대해 소개합니다. 마지막으로, 몇 줄의 변경만으로 모델 속도를 높이기 위해 TensorRT를 사용하는 방법을 보여드립니다.
벤치마킹
확산 모델에 대한 NVIDIA TensorRT INT8 및 FP8 양자화 레시피는 FP16에서 실행되는 기본 PyTorch의 torch.compile과 비교하여 NVIDIA RTX 6000 Ada GPU에서 1.72배 및 1.95배의 속도 향상을 달성합니다. INT8에 비해 FP8의 추가적인 속도 향상은 주로 다중 헤드 주의(MHA) 레이어의 양자화 덕분입니다. TensorRT 8비트 양자화를 사용하면 생성형 AI 애플리케이션의 응답성을 향상시키고 추론 비용을 절감할 수 있습니다.
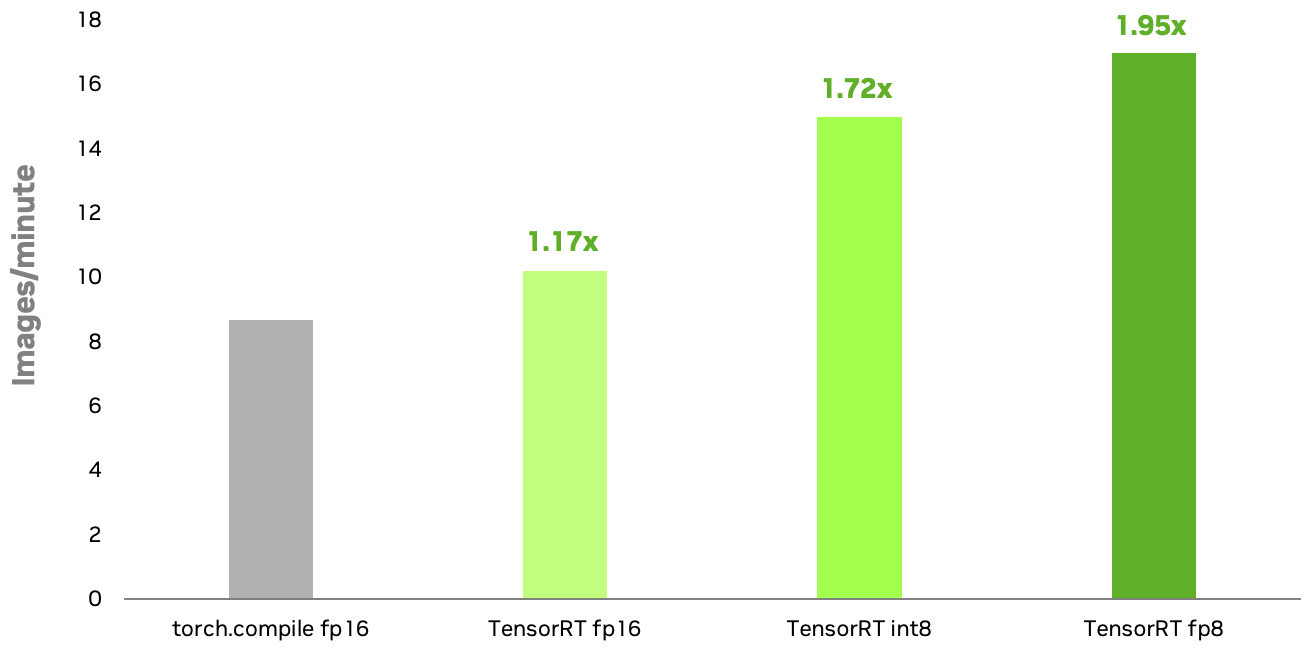
컨피규레이션: Stable Diffusion XL 1.0 기본 모델, 이미지 해상도=1024×1024, 배치 크기=1, 50단계의 오일러 스케줄러, NVIDIA RTX 6000 Ada GPU. TensorRT INT8 양자화는 현재 사용 가능하며, FP8은 곧 출시될 예정입니다. TensorRT FP8의 벤치마크는 출시 시점에 변경될 수 있습니다.
추론 속도를 높이는 것 외에도 TensorRT 8비트 양자화는 이미지 품질을 보존하는 데 탁월합니다. 독점적인 양자화 기술을 통해 원본 FP16 이미지와 매우 유사한 이미지를 생성합니다. 이러한 기술은 이 글의 뒷부분에서 다룹니다.

TensorRT 솔루션: 추론 속도 문제 극복
PTQ는 많은 AI 작업에서 메모리 공간을 줄이고 추론 속도를 높이기 위한 압축 방법으로 간주되지만, 확산 모델에서 바로 사용할 수 있는 것은 아닙니다. 확산 모델에는 고유한 다단계 노이즈 제거 프로세스가 있으며 각 시간 단계에서 노이즈 추정 네트워크의 출력 분포가 크게 달라질 수 있습니다. 따라서 단순한 PTQ 보정 방법은 적용하기 어렵습니다.
기존 기술에서 SmoothQuant는 LLM에 8비트 가중치, 8비트 활성화(W8A8) 양자화를 가능하게 하는 인기 있는 PTQ 방법으로 주목받고 있습니다. 이 기법의 주요 혁신은 수학적으로 동등한 변환을 통해 양자화 과제를 활성화에서 가중치로 이전함으로써 활성화 이상값을 해결하는 접근 방식에 있습니다.
이러한 효과에도 불구하고 사용자들은 SmoothQuant 내에서 매개변수를 수동으로 정의하는 데 어려움을 겪는 경우가 많습니다. 또한 경험적 연구에 따르면 SmoothQuant는 다양한 이미지 특성에 적응하는 데 어려움을 겪으며 실제 시나리오에서 유연성과 성능이 제한되는 것으로 나타났습니다. 또한 기존의 다른 확산 모델 양자화 기법은 단일 버전의 확산 모델에만 맞춤화된 반면, 사용자는 다양한 버전의 모델 속도를 높일 수 있는 일반적인 접근 방식을 찾고 있습니다.
이러한 문제를 해결하기 위해 NVIDIA TensorRT는 정교하고 세분화된 튜닝 파이프라인을 개발하여 SmoothQuant의 각 모델 레이어에 대한 최적의 파라미터 설정을 결정합니다. 피처 맵의 특정 특성에 따라 자체 튜닝 파이프라인을 개발할 수 있습니다. 이 기능을 사용하면 고객의 요구에 따라 기존 방식에 비해 원본 이미지의 풍부한 디테일을 보존하는 우수한 이미지 품질을 얻을 수 있는 TensorRT 양자화를 구현할 수 있습니다.
활성화 분포는 시간 단계에 따라 크게 달라질 수 있으며, 이미지의 모양과 전체적인 스타일은 주로 노이즈 제거 프로세스의 초기 단계에서 Q-Diffusion의 결과에 따라 결정됩니다. 따라서 기존의 최대 보정을 사용하면 초기 단계에서 큰 양자화 오류가 발생합니다.
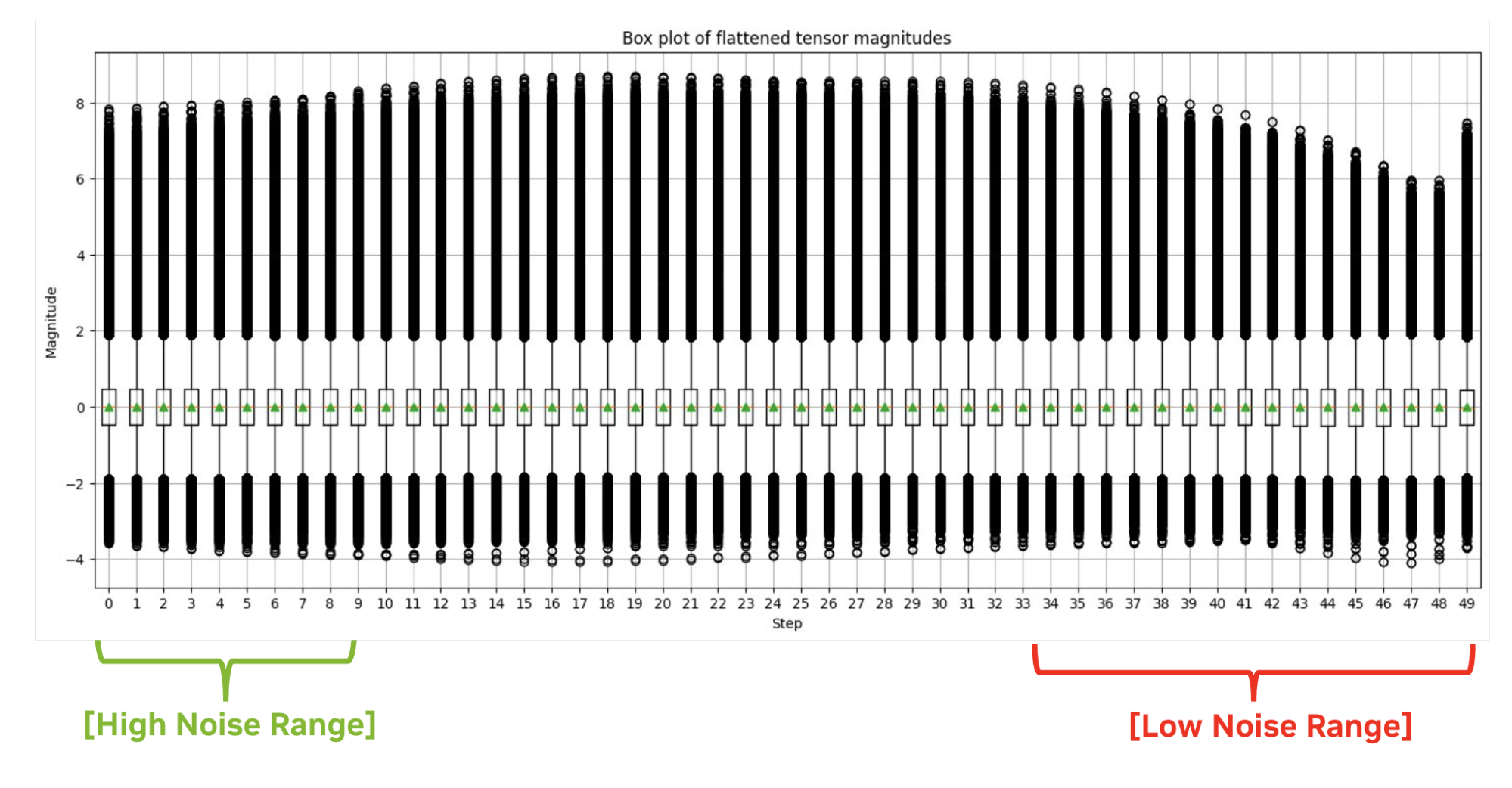
대신 선택한 단계 범위에서 최소 양자화 스케일링 계수를 선택적으로 사용했는데, 이는 활성화의 이상값이 최종 이미지 품질에 그다지 중요하지 않다는 사실을 발견했기 때문입니다. 퍼센타일 퀀트(Percentile Quant)라고 이름 붙인 이 맞춤형 접근 방식은 단계 범위의 중요한 백분위수에 초점을 맞춥니다. 이를 통해 TensorRT는 원래 FP16 정밀도로 생성된 이미지와 거의 동일한 이미지를 생성할 수 있습니다.

확산 모델 가속화를 위한 TensorRT 8비트 양자화 사용
이제 /NVIDIA/TensorRT GitHub 리포지토리에 엔드투엔드, SDXL, 8비트 추론 파이프라인이 호스팅되어 NVIDIA GPU에서 최적화된 추론 속도를 달성하기 위해 바로 사용할 수 있는 솔루션이 제공됩니다.
단일 명령을 실행하여 퍼센타일 퀀트로 이미지를 생성하고 데모확산으로 지연 시간을 측정합니다. 이 섹션에서는 INT8을 예로 사용하지만, FP8의 워크플로우도 거의 동일합니다.
python demo_txt2img_xl.py "enchanted winter forest with soft diffuse light on a snow-filled day" --version xl-1.0 --onnx-dir onnx-sdxl --engine-dir engine-sdxl --int8 --quantization-level 3다음은 이 명령과 관련된 주요 단계에 대한 개요입니다:
- 보정
- ONNX 내보내기
- TensorRT 엔진 빌드
캘리브레이션
보정은 양자화 중 목표 정밀도의 범위를 계산하는 단계입니다. 현재 TensorRT의 양자화 기능은 TensorRT 8비트 양자화 예제에 포함된 종속성인 nvidia-ammo에 패키징되어 있습니다.
# Load the SDXL-1.0 base model from HuggingFace
import torch
from diffusers import DiffusionPipeline
base = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
)
base.to("cuda")
# Load calibration prompts:
from utils import load_calib_prompts
cali_prompts = load_calib_prompts(batch_size=2,prompts="./calib_prompts.txt")
# Create the int8 quantization recipe
from utils import get_percentilequant_config
quant_config = get_percentilequant_config(base.unet, quant_level=3.0, percentile=1.0, alpha=0.8)
# Apply the quantization recipe and run calibration
import ammo.torch.quantization as atq
quantized_model = atq.quantize(base.unet, quant_config, forward_loop)
# Save the quantized model
import ammo.torch.opt as ato
ato.save(quantized_model, 'base.unet.int8.pt')ONNX 내보내기
정량화된 모델 체크포인트를 얻은 후 ONNX 모델을 내보낼 수 있습니다.
# Prepare the onnx export
from utils import filter_func, quantize_lvl
base.unet = ato.restore(base.unet, 'base.unet.int8.pt')
quantize_lvl(base.unet, quant_level=3.0)
atq.disable_quantizer(base.unet, filter_func) # `filter_func` is used to exclude layers you don't quantize
# Export the ONNX model
from onnx_utils import ammo_export_sd
base.unet.to(torch.float32).to("cpu")
ammo_export_sd(base, 'onnx_dir', 'stabilityai/stable-diffusion-xl-base-1.0')TensorRT 엔진 빌드
INT8 UNet ONNX 모델을 사용하면 TensorRT 엔진을 구축할 수 있습니다.
결론
생성형 AI 시대에는 사용 편의성을 우선시하는 추론 솔루션을 갖추는 것이 무엇보다 중요합니다. NVIDIA TensorRT를 사용하면 독점적인 8비트 양자화 기술을 통해 추론 속도를 최대 2배까지 원활하게 가속화하는 동시에 뛰어난 사용자 경험을 위해 이미지 품질을 저하시키지 않고 유지할 수 있습니다.
속도와 품질 사이의 균형을 맞추기 위한 TensorRT의 노력은 AI 애플리케이션 가속화를 위한 선도적인 선택으로 자리매김하여 최첨단 솔루션을 손쉽게 제공할 수 있도록 지원합니다.
양자화 관련 GTC 세션에 등록하여 전문가 패널로부터 생성형 AI 모델의 추론 속도와 모델 압축을 최적화하는 방법에 대해 자세히 알아보세요. 애플리케이션이 LLM을 기반으로 하는 경우, TensorRT-LLM을 사용한 SOTA 양자화 기법으로 추론 속도를 높이는 방법을 살펴보는 것이 좋습니다.
자세한 내용은 다음 리소스를 참조하세요:
- NVIDIA GTC 2024의 LLM을 위한 최고의 추론 세션
- 구글 젬마를 위한 추론을 향상시키는 NVIDIA TensorRT-LLM
- TensorRT SDK
- /NVIDIA/TensorRT-LLM GitHub 리포지토리