
거대 언어 모델(LLM)은 우리가 컴퓨터와 상호작용하는 방식을 근본적으로 바꾸고 있습니다. 이러한 모델은 인터넷 검색부터 사무 생산성 도구에 이르기까지 다양한 애플리케이션에 통합되고 있습니다. 실시간 콘텐츠 생성, 텍스트 요약, 고객 서비스 챗봇, 질의응답 사용 사례를 발전시키고 있습니다.
오늘날 LLM 기반 애플리케이션은 주로 클라우드에서 실행되고 있습니다. 하지만 게임, 창의성, 생산성, 개발자 경험 등 Windows PC에서 로컬로 LLM을 실행하면 이점을 얻을 수 있는 사용 사례도 많습니다.
CES 2024에서 NVIDIA는 Windows PC용 NVIDIA RTX 시스템에서 LLM 추론 및 개발을 가속화할 수 있는 몇 가지 개발자 도구를 발표했습니다. 이제 NVIDIA 엔드투엔드 개발자 도구를 사용하여 NVIDIA RTX AI 지원 PC에서 LLM 애플리케이션을 제작 및 배포할 수 있습니다.
커뮤니티 모델 및 네이티브 커넥터 지원
NVIDIA는 NVIDIA RTX 시스템에서 기존에 지원되던 Llama2, Mistral-7B 및 Code Llama에 더해 Phi-2를 비롯한 인기 커뮤니티 모델에 대한 최적화된 지원을 발표했습니다. 이러한 모델은 개발자에게 폭넓은 선택권을 제공하며, NVIDIA TensorRT-LLM 추론 백엔드를 사용하여 동급 최고의 성능을 제공합니다.
NVIDIA는 오픈 소스 커뮤니티와 협력하여 LlamaIndex와 같은 인기 애플리케이션 프레임워크에 대한 TensorRT-LLM용 네이티브 커넥터를 개발했습니다. 이 커넥터는 Windows PC에서 일반적으로 사용되는 애플리케이션 개발 도구에 대한 원활한 통합을 제공합니다. 여기에서 커넥터의 LlamaIndex 구현 예제를 확인하세요.
또한 코드 한 줄만 변경하여 클라우드 또는 로컬 Windows PC에서 실행 중인 LLM 애플리케이션 간에 쉽게 전환할 수 있도록 TensorRT-LLM용 OpenAI Chat API 래퍼를 개발했습니다. 이제 클라우드에서 애플리케이션을 디자인하든, NVIDIA RTX가 탑재된 로컬 PC에서 애플리케이션을 디자인하든, 커뮤니티에서 널리 사용되는 동일한 프레임워크로 유사한 워크플로우를 사용할 수 있습니다.
이러한 최신 발전은 이제 최근에 출시된 두 개의 오픈 소스 개발자 참조 애플리케이션을 통해 모두 액세스할 수 있습니다:
- 검색 증강 생성(RAG) 프로젝트는 NVIDIA RTX GPU가 탑재된 Windows PC에서 전적으로 실행되며 TensorRT-LLM 및 LlamaIndex를 사용합니다.
- 인기 있는 continue.dev 플러그인을 로컬 Windows PC에서 실행하는 레퍼런스 프로젝트로, OpenAI 채팅 API 호환을 위한 웹 서버가 포함되어 있습니다.
TensorRT-LLM 및 LlamaIndex를 사용한 Windows의 RAG
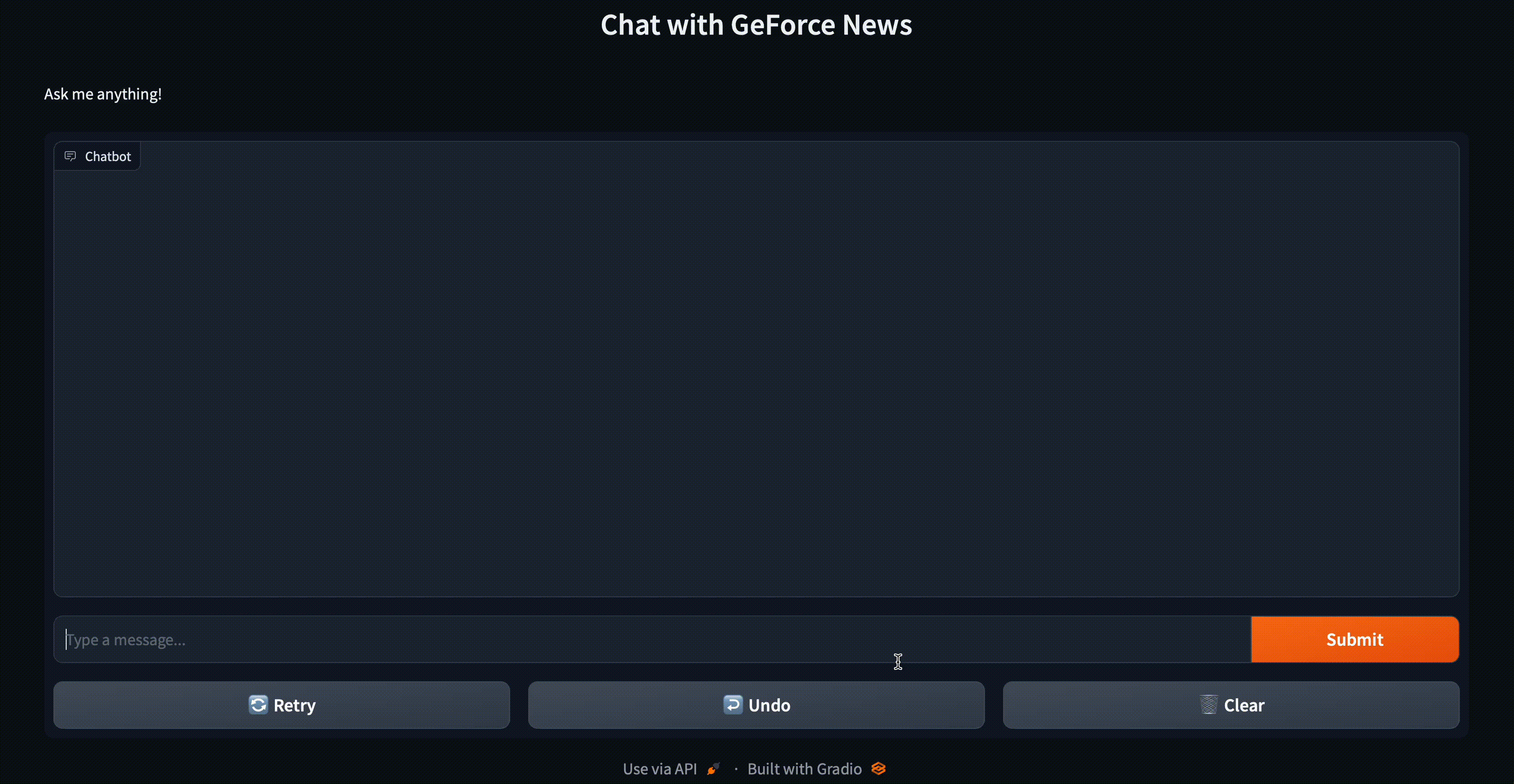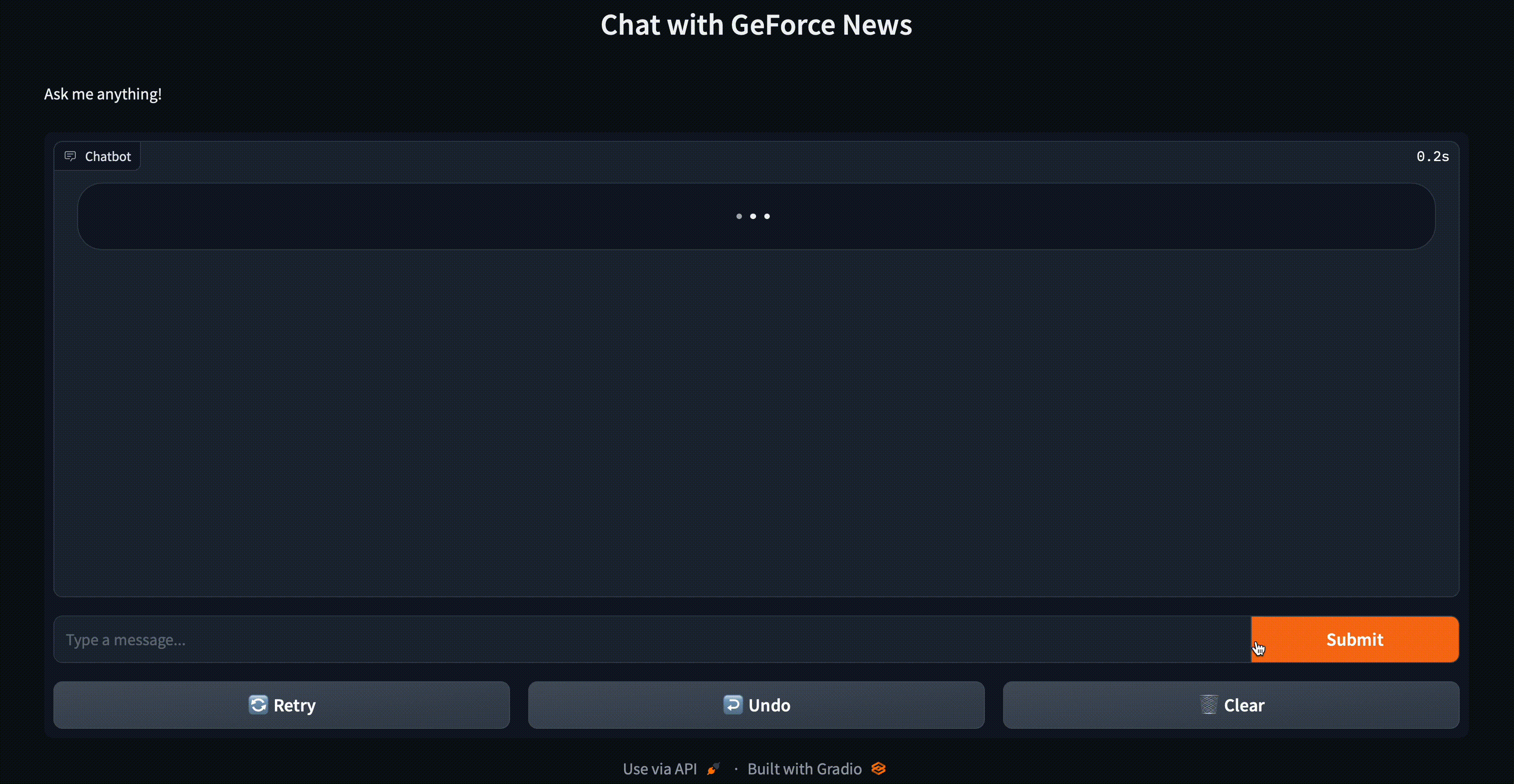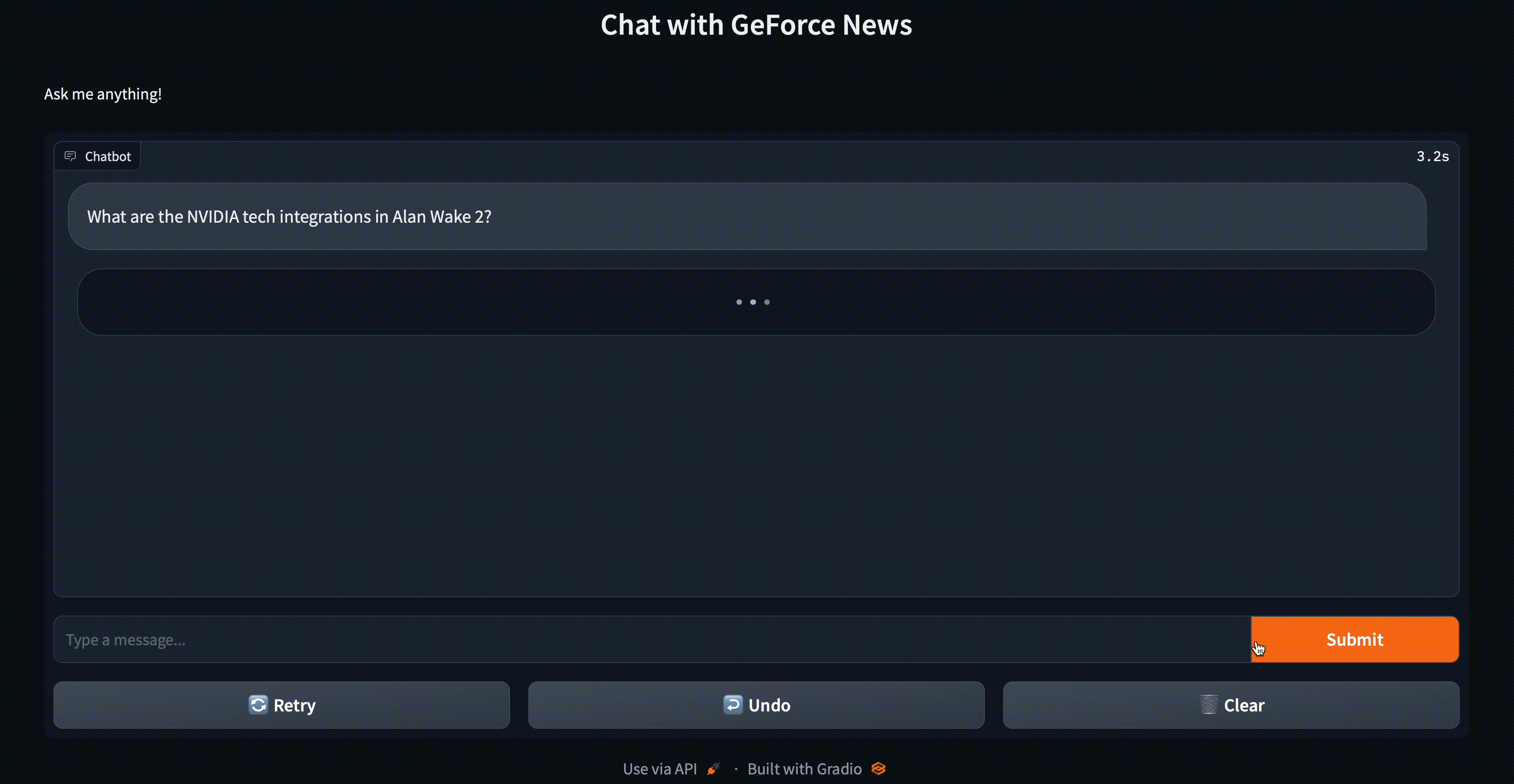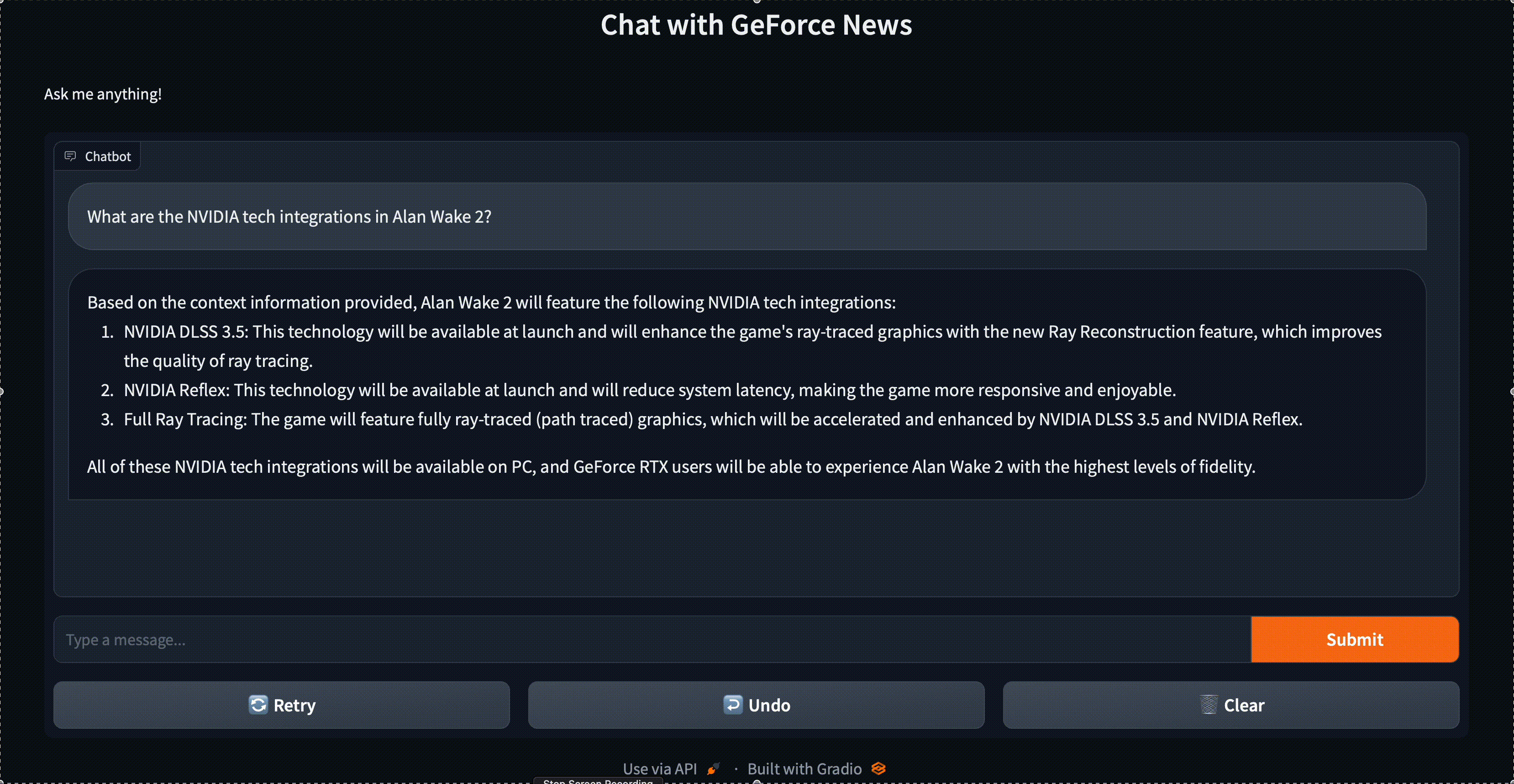
RAG 파이프라인은 Llama-2 13B 모델, TensorRT-LLM, LlamaIndex, FAISS 벡터 검색 라이브러리로 구성되어 있습니다. 이제 이 참조 애플리케이션으로 데이터와 쉽게 대화할 수 있습니다. 그림 1은 NVIDIA GeForce News로 구성된 데이터 세트를 보여줍니다.
CodeLlama-13B가 설치된 PC의 Continue.dev Visual Studio 코드 확장자
원래 continue.dev 플러그인은 클라우드에서 ChatGPT를 사용하여 LLM 기반 코드 지원을 제공하도록 설계되었습니다. 이 플러그인은 기본적으로 Visual Studio Code 통합 개발 환경과 함께 작동합니다. 이 플러그인은 단 한 줄의 코드 변경만으로 TensorRT-LLM용 OpenAI Chat API 래퍼를 사용하여 이제 NVIDIA RTX 지원 PC에서 로컬로 실행되는 Code Llama-13B 모델을 사용합니다. 이를 통해 빠른 로컬 LLM 추론을 위한 쉬운 경로를 제공합니다.
지금 GitHub에서 이 레퍼런스 프로젝트를 사용해 보세요.
로컬에서 LLM을 실행할 때의 이점
PC에서 로컬로 LLM을 실행하면 몇 가지 이점이 있습니다:
- 비용: LLM 추론을 위한 클라우드 호스팅 API나 인프라 비용이 들지 않습니다. 컴퓨팅 리소스에 직접 액세스할 수 있습니다.
- 상시 가동: 고대역폭 네트워크 연결에 의존하지 않고도 어디서나 LLM 기능을 사용할 수 있습니다.
- 성능: 지연 시간은 네트워크 품질과 무관하며, 전체 모델이 로컬에서 실행되므로 지연 시간이 짧습니다. 이는 게임이나 화상 회의와 같은 실시간 사용 사례에 중요할 수 있습니다. NVIDIA RTX는 최대 1300 TOPS의 가장 빠른 PC 가속기를 제공합니다.
- 개인정보보호: 개인 및 독점 데이터는 항상 장치에 보관할 수 있습니다.
1억 대 이상의 시스템이 출하된 NVIDIA RTX는 새로운 LLM 기반 애플리케이션을 위한 대규모 사용자 설치 기반을 제공합니다.
NVIDIA RTX의 LLM을 위한 개발자 워크플로우
이제 다음 옵션을 사용하여 NVIDIA RTX AI 지원 PC에서 LLM을 원활하게 실행할 수 있습니다:
- HuggingFace, NGC 및 NVIDIA AI 파운데이션에서 사전 최적화된 모델에 액세스합니다.
- NVIDIA NeMo 프레임워크가 포함된 NVIDIA DGX Cloud의 커스텀 데이터로 모델을 훈련하거나 커스터마이즈합니다.
- TensorRT-LLM을 사용하여 모델을 정량화 및 최적화하여 NVIDIA RTX에서 최고의 성능을 발휘합니다.
이 워크플로우는 클라우드와 PC 간에 원활하게 마이그레이션할 수 있는 NVIDIA AI Workbench와 같은 인기 있는 개발 도구와 함께 NVIDIA AI 플랫폼에 의해 구동됩니다.
AI Workbench는 단 몇 번의 클릭만으로 GPU 지원 환경 간에 생성형 AI 프로젝트를 협업하고 유연하게 마이그레이션할 수 있는 기능을 제공합니다. 프로젝트를 PC 또는 워크스테이션에서 로컬로 시작한 다음 데이터센터, 퍼블릭 클라우드 또는 NVIDIA DGX 클라우드 등 트레이닝을 위해 어디로든 확장할 수 있습니다. 그런 다음 모델을 로컬 NVIDIA RTX 시스템으로 다시 가져와서 추론 및 경량 커스터마이징을 위해 TensorRT-LLM을 사용할 수 있습니다.
AI Workbench는 이번 달 말에 베타 버전으로 출시될 예정입니다.
시작하기
최신 업데이트를 통해 이제 동일한 워크플로우에서 인기 있는 커뮤니티 모델과 프레임워크를 사용하여 클라우드에서 실행되는 애플리케이션을 빌드하거나 NVIDIA RTX가 탑재된 Windows PC에서 로컬로 실행할 수 있습니다. 기존 1억 개에 달하는 NVIDIA RTX PC 설치 기반에서 구동되는 애플리케이션에 LLM 기능을 간편하게 추가할 수 있습니다.
지금 LLM 기반 애플리케이션 및 프로젝트를 개발하는 방법에 대한 자세한 내용은 NVIDIA RTX 시스템으로 Windows PC에서 생성형 AI 개발 시작하기를 참조하세요.
생성형 AI 기반 Windows 앱 또는 플러그인에 대한 아이디어가 있으신가요? NVIDIA RTX 기반 생성형 AI 개발자 콘테스트에 참가하여 GeForce RTX 4090 GPU, GTC 오프라인 컨퍼런스 입장권 등을 받을 수 있습니다.
관련 리소스
- GTC 세션: 머신 러닝 애플리케이션뿐만 아니라 금융 애플리케이션에서 NVIDIA GPU 활용하기
- GTC 세션: 컴퓨터 게임 및 크리에이티브 산업을 위한 딥 러닝, LLM 및 생성형 모델
- GTC 세션: NVIDIA GPU 기반 애플리케이션을 위한 에너지 효율 최적화
- SDK: RTXMU
- SDK: TensorRT-ONNX 런타임
- 웨비나: 거대 언어 모델 구현하기