
확산 모델은 산업 전반의 크리에이티브 워크플로우를 혁신하고 있습니다. 이 모델은 노이즈 제거 확산 기술을 통해 무작위 노이즈를 반복적으로 AI 기반 작품으로 변형하여 단순한 텍스트 또는 이미지 입력을 기반으로 멋진 이미지를 생성합니다. 이 모델은 마케팅을 위한 개인화된 콘텐츠 제작, 사진 속 사물에 대한 상상력 넘치는 배경 생성, 게임용 고품질 환경 및 캐릭터 디자인 등 다양한 기업 사용 사례에 적용할 수 있습니다.
확산 모델은 워크플로우를 개선하는 데 유용한 도구가 될 수 있지만, 대규모로 배포할 경우 계산 집약적인 모델이 될 수 있습니다. 4개의 이미지로 구성된 단일 배치를 생성하는 데 CPU와 같은 비전문 하드웨어에서는 몇 분이 걸릴 수 있으며, 이는 창의적인 흐름을 차단하고 엄격한 서비스 수준 협약(SLA)을 충족하려는 많은 개발자에게 장애가 될 수 있습니다.
이 포스팅에서는 NVIDIA AI 추론 플랫폼이 어떻게 이러한 문제를 해결할 수 있는지 Stable Diffusion XL(SDXL)에 중점을 두고 설명합니다. 먼저 기업이 프로덕션 환경에 SDXL을 배포할 때 직면하는 일반적인 문제부터 시작하여 NVIDIA L4 Tensor 코어 GPU, NVIDIA TensorRT 및 NVIDIA Triton 추론 서버 기반의 Google Cloud G2 인스턴스가 이러한 문제를 완화하는 데 어떻게 도움이 되는지 자세히 살펴봅니다. 선도적인 AI 컴퓨터 비전 스타트업인 렛츠 인핸스(Let’s Enhance)가 NVIDIA AI 추론 플랫폼과 Google 클라우드에서 SDXL을 사용하여 기업이 클릭 한 번으로 매력적인 제품 이미지를 제작할 수 있도록 지원하는 방법을 조명합니다. 마지막으로, Google Cloud에서 SDXL을 사용하여 비용 효율적인 이미지 생성을 시작하는 방법에 대한 단계별 튜토리얼을 제공합니다.
SDXL 프로덕션 배포의 어려움 극복하기
프로덕션 환경에서 AI 워크로드를 배포하는 데는 여러 가지 어려움이 따릅니다. 여기에는 기존 모델 서비스 인프라 내에서 모델을 배포하고, 추론 요청의 일괄 처리를 최적화하여 처리량과 대기 시간을 개선하며, 예산 제약에 맞춰 인프라 비용을 유지하는 것이 포함됩니다.
그러나 프로덕션 환경에서 확산 모델을 배포하는 데는 컨볼루션 신경망에 대한 의존도, 이미지 전처리 및 후처리 작업에 대한 요구 사항, 엄격한 엔터프라이즈 SLA 요구 사항으로 인해 많은 어려움이 있습니다.
이 포스팅에서는 이러한 각 측면에 대해 자세히 살펴보고 NVIDIA 풀 스택 추론 플랫폼이 이러한 문제를 완화하는 데 어떻게 도움이 될 수 있는지 알아보겠습니다.
GPU에 특화된 텐서 코어 활용하기
안정적 확산의 핵심은 노이즈가 있는 이미지, 즉 난수 행렬 집합으로 시작하는 U-Net 모델입니다. 이 행렬은 더 작은 하위 행렬로 쪼개지고, 그 위에 일련의 컨볼루션(수학적 연산)이 적용되어 노이즈가 적은 정제된 결과물이 만들어집니다. 각 컨볼루션에는 곱셈과 누적 연산이 수반됩니다. 이 노이즈 제거 프로세스는 새롭고 향상된 최종 이미지를 얻을 때까지 여러 번 반복됩니다.

계산 복잡성을 고려할 때 이 절차는 NVIDIA 텐서 코어와 같은 특정 유형의 GPU 코어의 이점을 크게 누릴 수 있습니다. 이러한 특수 코어는 처음부터 행렬 곱셈-누적 연산을 가속화하도록 설계되어 이미지 생성 속도가 빨라집니다.
200개 이상의 텐서 코어를 자랑하는 NVIDIA 범용 L4 GPU는 프로덕션 환경에 SDXL을 배포하려는 기업에게 이상적인 비용 효율적인 AI 가속기입니다. 기업은 G2 인스턴스를 통해 클라우드에서 L4 GPU를 제공하는 최초의 CSP인 Google Cloud와 같은 클라우드 서비스 제공업체를 통해 L4 GPU에 액세스할 수 있습니다.

이미지 전처리 및 후처리 자동화
SDXL을 사용하는 실제 엔터프라이즈 애플리케이션에서 이 모델은 다른 컴퓨터 비전 모델과 이미지 편집 전처리 및 후처리 단계를 포함하는 보다 광범위한 AI 파이프라인의 일부입니다.
예를 들어, SDXL을 사용하여 신제품 출시 캠페인의 배경 장면을 만들려면 장면 생성을 위해 제품 이미지를 SDXL 모델에 입력하기 전에 예비 줌인 전처리 단계가 필요할 수 있습니다. 또한 결과물인 SDXL 이미지 출력은 마케팅 캠페인에 사용하기에 적합하기 전에 이미지 업스케일러를 사용하여 더 높은 해상도로 업스케일링하는 등의 추가 후처리가 필요할 수 있습니다.
이러한 다양한 전처리 및 후처리 단계를 간소화된 AI 파이프라인으로 통합하는 작업은 오픈 소스 Triton 추론 서버와 같은 모든 기능을 갖춘 AI 추론 모델 서버를 사용하여 자동화할 수 있습니다. 따라서 수동 코드를 작성하거나 컴퓨팅 환경 전체에서 데이터를 앞뒤로 복사할 필요가 없어 불필요한 대기 시간이 발생하고 컴퓨팅 및 네트워킹 리소스를 낭비할 필요가 없습니다.
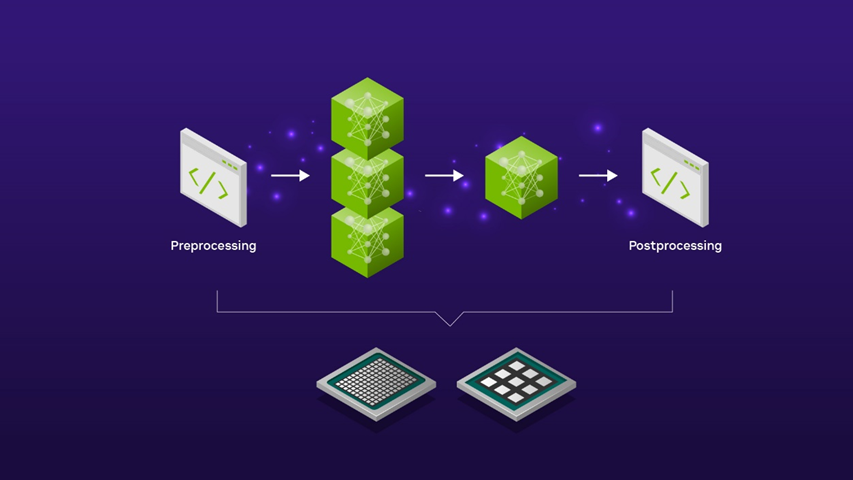
트리톤 추론 서버를 사용해 SDXL 모델을 제공하면 로우 코드 접근 방식으로 한 모델의 출력이 다음 모델의 입력으로 공급되는 방식을 정의할 수 있는 모델 앙상블 기능을 활용할 수 있습니다. 전처리 및 후처리 단계는 CPU에서, SDXL 모델은 GPU에서 실행하도록 선택하거나 전체 파이프라인을 GPU에서 실행하도록 선택하여 지연 시간이 매우 짧은 애플리케이션을 구현할 수 있습니다. 어느 옵션을 선택하든 SDXL 파이프라인의 엔드투엔드 지연 시간을 완벽하게 유연하게 제어할 수 있습니다.
프로덕션 환경을 위한 효율적인 확장
점점 더 많은 기업이 비즈니스 전반에 걸쳐 SDXL을 통합하고자 하면서 들어오는 사용자 요청을 효율적으로 일괄 처리하고 GPU 활용도를 극대화하는 과제가 점점 더 복잡해지고 있습니다. 이러한 복잡성은 긍정적인 사용자 경험을 위해 지연 시간을 최소화하는 동시에 처리량을 향상시켜 운영 비용을 절감해야 할 필요성에서 비롯됩니다.
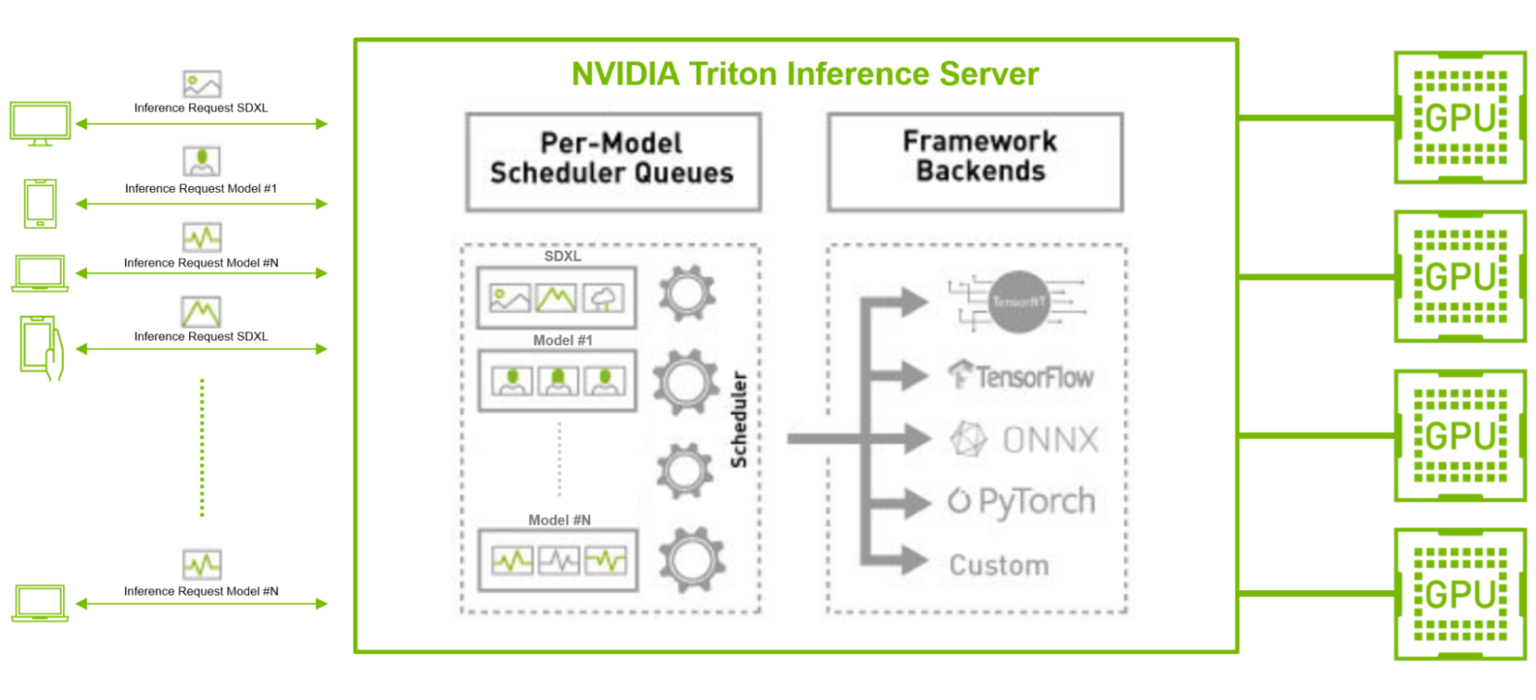
트리톤 추론 서버와 같이 동시 모델 실행 및 동적 배치 기능을 갖춘 추론 서버와 함께 TensorRT와 같은 오픈 소스 GPU 모델 최적화 도구를 사용하면 이러한 문제를 완화할 수 있습니다.
예를 들어, 특히 대량의 클라이언트 요청이 들어오는 프로덕션 환경에서 SDXL 모델을 다른 TensorFlow 및 PyTorch 이미지 분류 또는 특징 추출 AI 모델과 병렬로 실행하는 시나리오를 생각해 보세요. 여기서 SDXL 모델은 지연 시간이 짧은 추론을 위해 모델을 최적화하는 TensorRT로 컴파일할 수 있습니다.
또한 트리톤 추론 서버는 동적 일괄 처리 및 동시 추론 기능을 통해 백엔드 프레임워크에 관계없이 모델 전반에 걸쳐 대량의 수신 요청을 효율적으로 일괄 처리하고 분산할 수 있습니다. 이 접근 방식은 처리량을 최적화하여 기업이 더 적은 리소스와 낮은 총 소유 비용으로 사용자 요구 사항을 충족할 수 있도록 지원합니다.
평범한 제품 사진을 멋진 마케팅 자산으로 바꾸기
NVIDIA AI 추론 플랫폼의 성능을 활용하여 프로덕션 환경에서 SDXL을 서비스하는 기업의 좋은 예로 Let’s Enhance를 들 수 있습니다. 이 선구적인 AI 스타트업은 3년 이상 Triton Inference Server를 사용해 NVIDIA Tensor 코어 GPU에 30개 이상의 AI 모델을 배포해 왔습니다.
최근 Let’s Enhance는 SDXL 모델을 사용해 평범한 제품 사진을 전자상거래 웹사이트 및 마케팅 캠페인을 위한 아름다운 시각적 자산으로 변환하는 최신 제품인 AI Photoshoot의 출시를 축하했습니다.
다양한 프레임워크와 백엔드에 대한 트리톤 추론 서버의 강력한 지원과 동적 배치 기능 세트를 통해 Let’s Enhance의 설립자이자 CTO인 Vlad Pranskevichus는 ML 엔지니어링 팀의 개입을 최소화하면서 SDXL 모델을 기존 AI 파이프라인에 원활하게 통합할 수 있었고, 연구 및 개발 작업에 더 많은 시간을 할애할 수 있게 되었습니다.
성공적인 개념 증명을 통해 이 AI 이미지 향상 스타트업은 SDXL 모델을 Google Cloud G2 인스턴스의 NVIDIA L4 GPU로 마이그레이션하여 비용을 30% 절감했으며, 2024년 중반까지 여러 파이프라인의 마이그레이션을 완료하는 로드맵을 수립했습니다.

L4 GPU와 TensorRT를 사용한 SDXL 시작하기
다음 섹션에서는 최고의 가격 대비 성능을 위해 Google Cloud의 G2 인스턴스에 TensorRT에 최적화된 버전의 SDXL을 신속하게 배포하는 방법을 보여드리겠습니다. NVIDIA 드라이버를 사용하여 Google Cloud에서 VM 인스턴스를 스핀업하려면 다음 단계를 따르세요.
다음 머신 구성 옵션을 선택합니다:
- 머신 유형: g2-standard-8
- CPU 플랫폼: 인텔 캐스케이드 레이크
- 최소 CPU 플랫폼: 없음
- 디스플레이 장치: 비활성화됨
- GPU: 1 x NVIDIA L4
g2-standard-8 머신 유형은 NVIDIA L4 GPU 1개와 vCPU 4개를 갖추고 있습니다. 필요한 메모리 용량에 따라 더 큰 머신 유형을 사용할 수 있습니다.
다음 부팅 디스크 옵션을 선택하고 소스 이미지가 선택되어 있는지 확인합니다:
- 유형: 밸런스드 퍼시스턴트 디스크
- 크기: 500GB
- 영역: us-central1-a
- 레이블: None
- 사용 중: 인스턴스-1
- 스냅샷 일정: 없음
- 소스 이미지: c0-deeplearning-common-gpu
- 암호화 유형: Google 관리
- 일관성 그룹: 없음
Google 딥 러닝 VM에는 최신 NVIDIA GPU 라이브러리가 포함되어 있습니다.
VM 인스턴스가 실행되고 나면 브라우저 창에서 연결, SSH, 열기 및 인증을 선택합니다. 그러면 브라우저 창에 SSH 터미널이 로드됩니다.
다음 단계에 따라 TensorRT를 사용하여 최적화된 Stable Diffusion XL을 사용하여 이미지를 생성하세요.
TensorRT OSS 리포지토리를 복제합니다:
https://console.cloud.google.com/marketplace/product/click-to-deploy-images/deeplearning?project=nvidia-ngc-publicNVIDIA-docker를 설치하고 PyTorch 컨테이너를 실행합니다:
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker최신 TensorRT 릴리스를 설치합니다:
https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker필요한 패키지를 설치합니다:
export TRT_OSSPATH=/workspace
export HF_TOKEN=<your_hf_token_to_download_models>
cd $TRT_OSSPATH/demo/Diffusion
pip3 install -r requirements.txt이제 “art deco, realistic”이라는 프롬프트와 함께 TensorRT에 최적화된 Stable Diffusion XL 모델을 실행합니다:
python3 demo_txt2img_xl.py "art deco, realistic" --hf-token=$HF_TOKEN --version xl-1.0 --batch-size 1 --build-static-batch --num-warmup-runs 5 --seed 3 --verbose --use-cuda-graph그러면 노트북에서 볼 수 있는 멋진 이미지가 생성됩니다:
from IPython.display import display
from PIL import Image
img = Image.open('output/xl_base-fp16-art_deco,_-1-xxxx.png')
display(img)
축하합니다! TensorRT로 최적화된 Stable Diffusion XL을 사용하여 샘플 이미지를 생성했습니다.
처리량을 높이려면 최대 8개의 L4 GPU를 활용하는 더 큰 머신 유형을 사용하고 각 GPU에 모델을 로드하여 효율적인 병렬 처리를 할 수 있습니다. 더 빠른 추론을 위해 노이즈 제거 단계 수, 이미지 해상도 또는 정밀도를 조정할 수 있습니다. 예를 들어, 앞의 예에서 노이즈 제거 단계 수를 30개에서 20개로 줄이면 초당 이미지 처리량이 1.5배 증가합니다.
L4 GPU는 가격 대비 성능이 뛰어납니다. 비용에 민감한 애플리케이션과 오프라인 배치 이미지 생성에 이상적인 NVIDIA A100 텐서 코어 GPU에 비해 1달러당 1.4배 더 많은 이미지를 생성합니다. 그러나 지연 시간에 민감한 애플리케이션에는 L4에 비해 A100 또는 H100이 각각 3.8~7.9배 더 빠르게 이미지를 생성하므로 더 나은 선택입니다.
성능은 배치 크기, 해상도, 노이즈 제거 단계, 데이터 정밀도 등 추론 과정에서 여러 요인에 따라 달라집니다. 추가 최적화 및 구성 옵션에 대한 자세한 내용은 /NVIDIA/TensorRT GitHub 리포지토리의 DemoDiffusion 예제를 참조하세요.
Triton 추론 서버로 프로덕션 환경에 SDXL 배포하기
다음은 g2-standard-32 머신 유형에서 Triton 추론 서버를 사용하여 프로덕션 환경에서 SDXL 모델을 배포하는 방법입니다.
Triton 추론 서버 튜토리얼 리포지토리를 복제합니다:
git clone https://github.com/triton-inference-server/tutorials.git -b r24.02 --single-branch
cd tutorials/Popular_Models_Guide/StableDiffusion 트리톤 추론 서버 확산 컨테이너 이미지를 구축합니다:
./build.sh컨테이너 이미지에서 대화형 셸을 실행합니다. 다음 명령은 컨테이너를 시작하고 현재 디렉터리를 작업 공간으로 볼륨 마운트합니다:
./run.shStable Diffusion XL TensorRT 엔진을 빌드합니다. 몇 분 정도 걸립니다.
./scripts/build_models.sh --model stable_diffusion_xl빌드가 완료되면 예상 출력은 다음과 같습니다:
diffusion-models
|-- stable_diffusion_xl
|-- 1
| |-- xl-1.0-engine-batch-size-1
| |-- xl-1.0-onnx
| `-- xl-1.0-pytorch_model
`-- config.pbtxt트리톤 추론 서버를 시작합니다. 이 데모에서는 EXPLICIT 모델 제어 모드를 사용하여 로드되는 Stable Diffusion 버전을 제어합니다. 프로덕션 배포에 대한 자세한 내용은 보안 배포 고려 사항을 참조하세요.
tritonserver --model-repository diffusion-models --model-control-mode explicit --load-model stable_diffusion_xl완료되면 예상 출력은 다음과 같습니다:
<SNIP>
I0229 20:22:22.912465 1440 server.cc:676]
+---------------------+---------+--------+
| Model | Version | Status |
+---------------------+---------+--------+
| stable_diffusion_xl | 1 | READY |
+---------------------+---------+--------+
<SNIP>/sy별도의 대화형 셸에서 새 컨테이너를 시작하여 샘플 트리톤 추론 서버 클라이언트를 실행합니다. 다음 명령은 컨테이너를 시작하고 현재 디렉터리를 작업 공간으로 볼륨 마운트합니다:
./run.shStable Diffusion XL에 프롬프트를 보냅니다:
python3 client.py --model stable_diffusion_xl --prompt "butterfly in new york, 4k, realistic" --save-image
축하합니다! 트리톤으로 SDXL을 성공적으로 배포했습니다.
트리톤 추론 서버를 사용한 동적 일괄 처리
기본 Triton 추론 서버를 설정하고 실행한 후에는 이제 max_batch_size 매개변수를 늘려 동적 일괄 처리를 활성화할 수 있습니다.
트리톤 추론 서버가 실행 중이면 중지합니다. 대화형 셸에서 CTRL-C를 입력하여 서버를 중지할 수 있습니다.
모델 구성 파일인 ./diffusion-models/stable_diffusion_xl/config.pbtxt를 편집하여 배치 크기를 2로 늘립니다:
- 이전:
max_batch_size: 1 - 이후:
max_batch_size: 2
배치 크기 2에 맞게 TRT 엔진을 다시 빌드합니다. 몇 분 정도 걸립니다.
./scripts/build_models.sh --model stable_diffusion_xl빌드가 완료되면 예상 출력은 다음과 같습니다:
diffusion-models
|-- stable_diffusion_xl
|-- 1
| |-- xl-1.0-engine-batch-size-2
| |-- xl-1.0-onnx
| `-- xl-1.0-pytorch_model
`-- config.pbtxt트리톤 추론 서버를 다시 시작합니다:
tritonserver --model-repository diffusion-models --model-control-mode explicit --load-model stable_diffusion_xl완료되면 예상 출력은 다음과 같습니다:
<SNIP>
I0229 20:22:22.912465 1440 server.cc:676]
+---------------------+---------+--------+
| Model | Version | Status |
+---------------------+---------+--------+
| stable_diffusion_xl | 1 | READY |
+---------------------+---------+--------+
<SNIP>서버에 동시 요청을 보냅니다. 서버가 여러 요청을 동적으로 일괄 처리하려면 요청을 병렬로 보내는 여러 클라이언트가 있어야 합니다. 샘플 클라이언트를 사용하면 클라이언트 수를 늘려 동적 일괄 처리의 이점을 확인할 수 있습니다.
python3 client.py --model stable_diffusion_xl --prompt "butterfly in new york, 4k, realistic" --clients 2 –requests 5서버 로그와 메트릭을 살펴봅니다. 동적 일괄 처리, 동시 요청, 정보 수준 로깅을 활성화한 이 예제는 각 요청에 포함된 프롬프트 수에 대한 추가 정보를 TensorRT 엔진에 출력합니다.
57291 │ I0229 20:36:23.017339 2146 model.py:184] Client Requests in Batch:2
57292 │ I0229 20:36:23.017428 2146 model.py:185] Prompts in Batch:2

그림 9. NVIDIA Triton 동적 배칭을 사용하여 SDXL로 생성된 이미지 예시
요약
NVIDIA AI 추론 플랫폼에 SDXL을 배포하면 기업은 확장 가능하고 안정적이며 비용 효율적인 솔루션을 얻을 수 있습니다.
TensorRT와 Triton Inference Server는 모두 성능을 극대화하고 프로덕션 지원 배포를 간소화할 수 있으며, 구글 클라우드 마켓플레이스에서 제공되는 NVIDIA AI Enterprise의 일부로 포함되어 있습니다. AI Enterprise는 AI 추론을 지원하는 오픈 소스 컨테이너 및 프레임워크를 위한 엔터프라이즈급 안정성, 보안, 관리 편의성과 함께 NVIDIA 지원 서비스를 제공합니다.
또한 엔터프라이즈 개발자는 시각 콘텐츠용 맞춤형 생성형 AI를 위한 파운드리인 NVIDIA Picasso를 통해 확산 기반 모델을 훈련, 미세 조정, 최적화 및 추론할 수 있습니다.
SDXL은 NVIDIA AI 파운데이션 모델과 NGC 카탈로그의 일부로 제공되며, 브라우저에서 직접 SDXL을 빠르게 사용해 볼 수 있는 사용하기 쉬운 인터페이스를 제공합니다.
NVIDIA GTC 2024에서 확산 모델 추론 파이프라인을 강화하는 방법에 대해 자세히 알아보세요:
- 세계에서 가장 빠르고 안정적인 확산
- 확산 모델: 생성형 AI 빅뱅
- 멀티모달 생성형 AI와 NVIDIA로 예술적인 초상화 만들기
- AI 추론의 실제: 강화하기
- NVIDIA Picasso를 사용한 시각적 생성형 AI 애플리케이션 구축하기