최근 딥 러닝의 진화와 벡터 임베딩(vector embedding)의 사용으로 추천 모델이 빠르게 발전하고 있습니다. 추천 모델의 복잡성이 증가함에 따라 이들을 지원할 강력한 시스템이 요구되고 있는데요. 이는 프로덕션 단계의 배포와 유지보수 문제로 이어지기도 합니다.
‘모놀리스: 실시간 추천 시스템과 무충돌 임베딩 테이블(Monolith: Real Time Recommendation System With Collisionless Embedding Table)’이라는 제목의 논문에서 바이트댄스(ByteDance)는 온라인 훈련과 임베딩의 롤링 업데이트, 결함 허용(fault tolerance) 등을 지원하는 추천 시스템의 구축 방법을 소개합니다.
이번 포스팅에서는 오프라인과 온라인, 그리고 온라인 대규모 추천 시스템 아키텍처에 대해 자세히 알아봅니다. 배포에 중점을 두고 NVIDIA Merlin을 빌딩 블록 프레임워크로, 레디스(Redis)를 실시간 데이터 레이어로 사용하는 엔드-투-엔드 추천 시스템의 예제를 구성해봅니다. 끝으로 프로덕션 준비 완료와 아키텍처 간소화를 위한 클라우드 배포 지침과 관리형 레디스 옵션을 살펴봅니다.
RedisVentures/Redis-Recsys 깃허브 저장소에서 코드를 다운로드하고, 각각의 예제와 함께 관련 에셋을 확인하세요. 이 인프라의 아마존 웹 서비스(AWS) 배포를 도울 테라폼 스크립트와 앤서블 플레이북이 제공됩니다.
추천 시스템 아키텍처
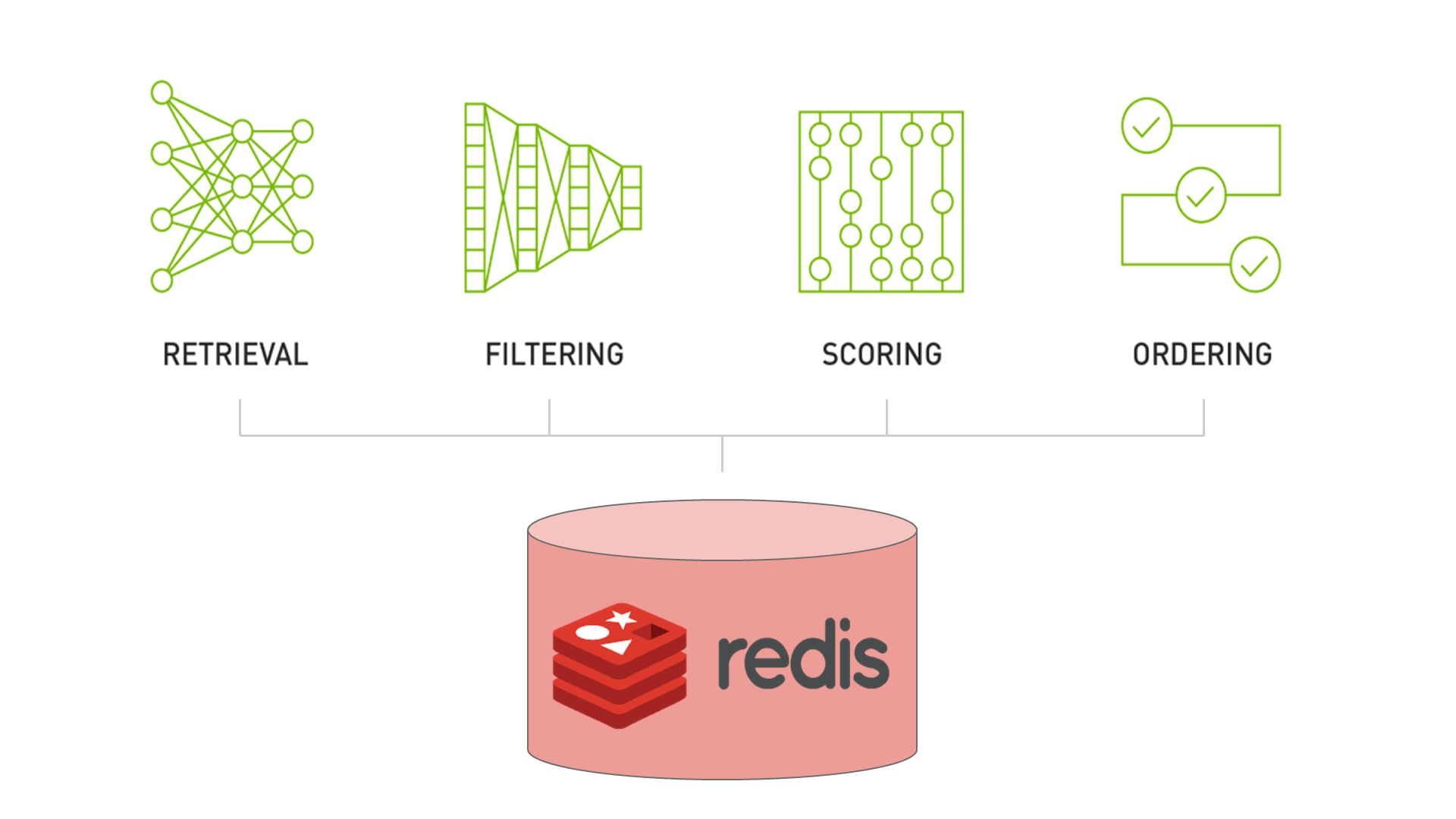
NVIDIA Merlin 추천 시스템은 ‘추천 모델을 넘어 추천 시스템으로(Recommender Systems, Not Just Recommender Models)’에서 논의된 바와 같이 다음의 4단계 패턴에 의존합니다.
- 사용자와 최종적으로 연계될 아이템을 포함해 합리적인 관련성을 가진 집합의 검색
- 해당 모델로는 실행이 거의 불가능해 사실상 원치 않는 아이템의 필터링
- 사용자가 관심을 가질 가능성이 있는 아이템 세트의 점수화(또는 순위화)
- 비즈니스의 다른 필요나 제약 조건에 맞춰 모델의 아웃풋을 정리하는 아이템 정렬
검색(retrieval), 필터링(filtering), 점수화(scoring), 정렬(ordering)의 4단계는 프로덕션 단계의 추천 시스템 대부분을 아우르는 설계 패턴입니다(Figure 1 참고). 이 포스팅에서는 점수화와 순위화(ranking)를 동의어로 사용하며, 추천 시스템에서 특히 연산 집약적인 단계에 해당하는 검색과 순위화를 중점적으로 살펴보겠습니다.
검색 단계
검색 프로세스는 대체로 빠르지만 그리 꼼꼼하지는 않습니다. 잠재적 후보들이 모여 있는 대규모 풀에서 관련성을 가진 하위 집합이 선택됩니다. 이 단계에서는 정밀성보다 효율성이 더 중시됩니다.
오늘날의 검색 시스템에서 후보들의 카탈로그는 잠재적 아이템 전체를 딥 러닝 모델에 통과시켜 만든 밀집(dense) 임베딩으로 전환됩니다. 레디서치(RediSearch)나 파이스(FAISS)로 인덱싱하면 수백만 개의 임베딩을 비교할 수 있으며, 가장 유사한 후보 임베딩을 저지연으로 검색할 수 있습니다.
순위화 단계
순위화 단계에서는 효율성보다 정밀성이 훨씬 중요합니다. 따라서 순위화 모델은 검색 단계보다 연산적으로 더 복잡한 경우가 많습니다. 딥 러닝의 발전 덕분에 순위화 단계에서 전보다 많은 데이터를 아우를 수 있게 됐습니다.
메타(Meta)가 만든 딥 러닝 추천 모델(DLRM) 등이 순위화에 활용되며, 특정 사용자를 위해 수백만 개에 달하는 후보의 순위를 매기는 방법을 학습할 수 있습니다. 그러나 인풋이 후보 몇 천 개 수준으로 제한적입니다.
대규모 순위화 시스템은 종종 2개 이상의 하위 단계, 즉 성긴(coarse) 순위화와 미세 순위화 또는 재순위화로 구성되어 보다 정교한 기법을 구현하거나 추가 정보를 넣어 최종 아웃풋에 영향을 줍니다. 이런 조합은 후보들의 수를 추가적으로 줄일 수 있는 만큼 연산 비용을 증가시킵니다.
추천 시스템 아키텍처와 관련한 보다 자세한 정보는 ‘추천과 검색을 위한 시스템 디자인(System Design for Recommendations and Search)’을 참고하세요. 해당 포스팅은 대표 기업들에 배포된 일부 예제들을 다룹니다.
참고로 우리가 ‘오프라인’이라는 용어를 전체 추천 시스템의 배포 아키텍처를 뜻하는 말로 사용하는 반면, 위에서 소개한 포스팅의 저자 유진 얀(Eugene Yan)의 ‘오프라인’은 모델을 훈련하는 단계를 뜻합니다.
오프라인 추천 시스템
‘오프라인 추천 시스템’은 배치(batch) 컴퓨팅을 활용해 대규모 데이터세트를 처리하고 향후 검색을 위한 추천을 저장합니다.
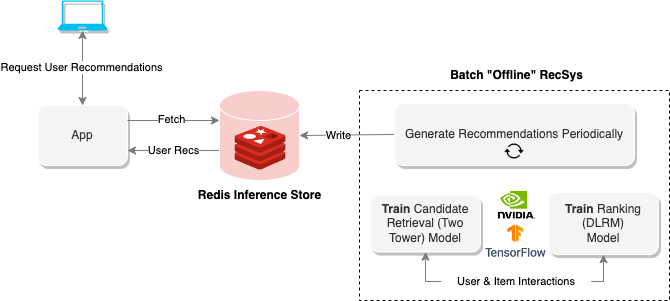
배치 컴퓨팅은 실시간 다중 단계 추천 시스템의 복잡한 호스팅을 감당할 수 없거나, 빠른 시작과 실행이 필요한 개발자에게 특히 유용합니다. 이 시스템들은 어느 정도의 간격을 두고 리프레시가 진행되지만 높은 정밀도와 그에 따른 컴퓨팅 시간의 추가가 요구되는 비즈니스 목표에 적합합니다. 정기 뉴스레터나 이메일 마케팅 등을 예로 들 수 있습니다.
Figure 2는 추천의 저장과 검색에 레디스만을 사용한 오프라인 아키텍처입니다. ‘오프라인 배치 추천 시스템(Offline Batch Recommender System)’ 노트북에서는 알리바바 클릭과 컨버전 예측(Alibaba Click and Conversion Prediction) 데이터세트용으로 레디스 오프라인 시스템을 만드는 방법을 만나볼 수 있습니다.
검색: 투 타워
후보 검색 모델은 투 타워(two-tower) 방식의 신경망 아키텍처입니다. 사용자 타워(user tower)는 사용자의 선호를 모델링하고, 아이템 타워(item tower)는 아이템의 특성을 모델링합니다.
노트북 예제는 훈련에 네거티브 샘플링을 사용합니다. 이 모델은 사용자 순위나 점수 같은 직접(explicit) 피드백을 활용하는 대신, 사용자 인터랙션이나 클릭 등의 간접(implicit) 피드백을 활용합니다. 훈련을 마친 임베딩으로는 특정 사용자와 인터랙션할 가능성이 가장 높은 쪽으로 아이템 카탈로그를 좁힙니다. 임베딩은 또한 콘텐츠 기반 추천이나 고객 세분화 등 다른 전자상거래 활용 사례에서 아이템간 또는 사용자간 유사성 파악에 응용될 수 있습니다.
순위화: DLRM
순위화 모델은 추천 시스템에서 폭넓게 사용되는 일종의 머신 러닝 모델로 관련도나 사용자 인터랙션에 기반해 아이템의 순위를 정합니다. 이 모델들은 클릭과 구매 내역, 평점 등의 과거 인터랙션과 사용자 선호를 고려해 개별화된 추천을 생성합니다.
주피터 노트북의 예제는 사용자-아이템 쌍의 점수와 순위를 매기는 하이브리드 모델 아키텍처인 DLRM을 사용합니다. DLRM 아키텍처에 대한 더 자세한 정보는 ‘순위화 모델 내보내기(Exporting Ranking Models)’를 참고하세요.
추천 생성과 서비스
추천 시스템의 마지막은 저지연 데이터 레이어에 생성된 추천의 호스팅입니다. 레디스 같은 키-값 스토어(key-value store)를 사용하면 온라인 추천 시스템 인프라를 호스팅하는 복잡성 없이 거의 실시간으로 추천에 액세스할 수 있습니다.
이제부터는 앞서 설명한 파이프라인을 가져와 실시간 서빙 레이어를 배포하고 추천을 온라인으로 생성하는 방법을 살펴보겠습니다.
온라인 추천 시스템
온라인 추천 시스템은 온디맨드 방식으로 추천을 생성합니다. 배치 지향적 시스템과 달리 확장성과 엔드-투-엔드 지연 시간(대개 100~300밀리초 미만)이 가장 중요한 요소로 고려되는 경우가 많습니다.
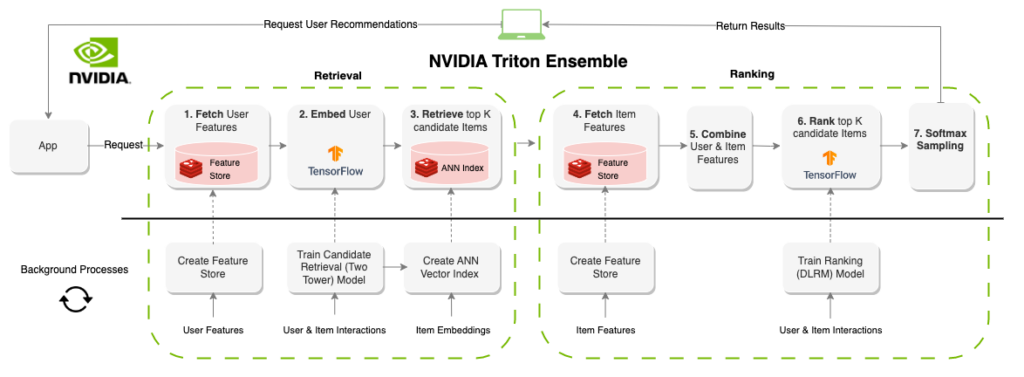
여기서는 피처 스토리지(레디스)와 오케스트레이션(피스트), 벡터 데이터베이스와 검색(레디스), 추론(NVIDIA Triton)으로 온라인 추천 시스템을 구축하는 데 필요한 인프라를 살펴봅니다.
그리고 뒤이어 소개할 노트북은 NVIDIA Triton 추론 서버의 앙상블 기능으로 각 인프라를 서로 연결하는 방법을 개략적으로 보여줍니다.
피처 스토리지
추천 시스템의 두 분류를 밀접하게 본떠 가장 널리 배포되는 유형의 피처 스토어가 바로 오프라인과 온라인 스토어입니다.
오프라인 피처 스토어
‘오프라인 피처 스토어(offline feature store)’는 일반적으로 대용량(10TB 이상)의 보존성, 디스크 기반 데이터베이스입니다. 과거 피처를 포함한 모든 모델 피처가 오프라인 스토어에 보관됩니다. 아파치 스파크(Apache Spark) 같은 배치 프로세싱 프레임워크는 오프라인 스토어의 피처를 지정된 간격에 맞춰 온라인 피처 스토어에 머티리얼라이즈(materialize)하는 데 종종 사용됩니다. 가령 스파크-레디스는 피처를 레디스에 로드하는 데 자주 쓰입니다.
온라인 피처 스토어
‘온라인 피처 스토어(online feature store)’는 용량보다 지연 시간 절감에 집중하며, 피처는 대개 인메모리(in-memory)에 보관합니다. 피처 일부가 오프라인 스토어에서 온라인 스토어로 머티리얼라이즈되어 가장 “최신”의 피처만이 서빙을 위해 보관됩니다. 온라인 스토어는 서빙 파이프라인에서 직접 쿼리되어 머신 러닝 모델에 풍부한 추론용 피처 벡터를 제공합니다.
이 두 번째 예제에서 레디스는 온라인 피처 스토어의 역할을 하며, 여기에 파케이(parquet) 파일(오프라인 스토어)의 사용자와 아이템 피처가 머리티얼라이즈됩니다. 피처 오케스트레이션 프레임워크인 피스트(Feast)는 피처를 정의하고, 머티리얼라이제이션을 구성하고, 런타임에서 모델 피처를 쿼리합니다.
임베딩 서빙
오프라인 예제에서는 투 타워 모델을 써서 사용자와 아이템을 인코딩해 임베딩을 만듭니다. 그러나 온라인 서빙의 경우, 사용자 타워만을 활용하고 벡터 데이터베이스를 배포해 아이템 임베딩의 호스팅과 검색을 진행하면 시스템 전반의 지연 시간을 줄일 수 있습니다.
지연 시간 절감과 더불어 벡터 데이터베이스는 쿼리 서빙을 방해하지 않고 임베딩을 업데이트하게 지원합니다. 오프라인 노트북은 생성된 아이템 임베딩을 파일에 저장해 시스템 설정 방식을 온라인 노트북으로 확인하게 해줍니다.
레디스는 온라인 피처 스토어로 사용될 뿐 아니라 레디서치 모듈을 가진 아이템 임베딩의 근사 최근접 이웃(ANN) 인덱스로도 활용됩니다. 레디서치는 버전 2.4에서 벡터 인덱스 지원을 추가한 바 있습니다.
‘온라인 다중 단계 렉시스 구성 요소 구축하기(Building Online Multi-Stage Recsys Components)’ 노트북은 피처 스토리지와 벡터 임베딩 검색을 위해 피스트와 레디스를 설정하는 방법을 소개합니다.
실시간 추천 서빙
추론 서빙 플랫폼인 NVIDIA Triton은 다수의 백엔드를 보유해 서로 다른 모델 유형과 파이프라인을 지원합니다. 앙상블 백엔드를 사용하면 방향성 비순환 그래프(DAG)에서 실행할 여러 단계의 정의가 가능합니다. 피스트와 레디스의 설정이 끝난 뒤에 NVIDIA Triton 앙상블(Figure 3)을 정의해 추천 시스템 파이프라인을 온디맨드로, 주어진 user_id 값에 맞춰 실행할 수 있습니다.
‘Triton Inference Server로 온라인 다중 단계 렉시스 배포하기(Deploying Online Multi-Stage RecSys with Triton Inference Server)’ 노트북은 NVIDIA Triton 앙상블을 정의하는 방법과 함께 NVIDIA Triton 파이썬(Python) 클라이언트를 사용해 쿼리하는 예제를 제공합니다.
설계 시 고려 사항
이 시스템은 실시간 추천을 지원하지만 그럼에도 설계 시 고려해야 할 사항들이 있습니다.
첫째, 오프라인 피처 스토어의 사용자 피처를 온라인 스토어에 주기적으로 퍼블리싱해야 합니다. 가령 사용자가 전자상거래 사이트에서 동작을 수행 중인 상황에서 피처가 충분한 빈도로 머티리얼라이즈되지 않으면 추천이 정지 상태로 표시될 수 있습니다. 반면 머티리얼라이제이션이 지나치게 빈번하면 레디스의 쓰기 작업이 증가해 읽기 처리량이 감소하고, 서빙 파이프라인의 속도가 느려질 수 있습니다. 이 사이의 균형을 찾는 것이 핵심입니다.
둘째, 훈련된 모델의 경우 피처 드리프트(drift) 발생 여부를 모니터링해야 합니다. 피처들이 훈련 세트에 포함된 내용에서 업데이트됨에 따라 시간의 흐름과 함께 모델 성능이 바뀔 수 있습니다. 성능을 유지하려면 모델을 재훈련하고, 시간의 경과에 맞춰 업데이트해야 합니다. 벡터 인덱스에 저장된 임베딩 또한 모델과 함께 업데이트가 필요합니다. 레디스를 사용하면 증분형(incremental) 벡터 업데이트를 인덱스에 직접 수행하거나, 백그라운드에서 새 벡터 인덱스를 만들어 FT.ALIASADD 명령으로 바꿔넣기(swap-in)할 수 있습니다.
온라인, 대규모
대기업이 보유한 사용자와 아이템은 때로 수백만에 달합니다. 이 경우 모델의 전체 임베딩 테이블이 단일 GPU에 맞지 않을 수 있습니다.
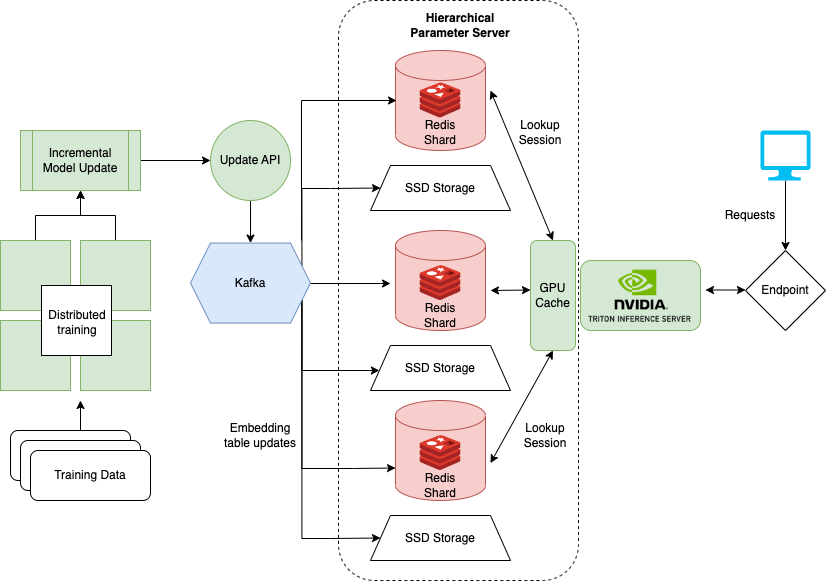
이를 위해 NVIDIA Merlin이 HugeCTR 백엔드를 만들었습니다. 이 백엔드는 분산 훈련과 업데이트, 추천 모델 서빙을 제공합니다.
‘대규모 추천 모델(Large-Scale Recommender Models)’ 노트북은 HugeCTR 배포에 중점을 두고 이 예제에 사용이 가능한 DLRM의 사전 훈련 버전을 제공합니다. HugeCTR과 분산 훈련에 대한 더 자세한 정보는 ‘Merlin 계층형 파라미터 서버로 추천 시스템 추론 스케일링하기(Scaling Recommendation System Inference with Merlin Hierarchical Parameter Server)’에서 확인하세요.
HugeCTR 서빙
위의 노트북에 배포된 DLRM 모델은 앞선 섹션에서 살펴본 순위화 모델 온라인 추천 시스템과 동일합니다. 이제부터는 순위화 단계를 보다 깊이 탐구하면서 HugeCTR이 다중 단계 추천 시스템의 순위화 단계에 필요한 역량을 지원하는 방법을 살펴보겠습니다.
HugeCTR은 정확도를 올리지만 모델의 연산 비용 또한 높이는 사용자-아이템간 인터랙션 수백만 가지를 설명할 순위화 모델을 만들 수 있습니다. 앞서 언급한 대로 순위화 단계는 검색 단계보다 느리고 더 정확하며, 특정 활용 사례에 할당된 가용 시간 예산의 상당 부분을 차지합니다.
계층형 파라미터 서버
HugeCTR은 계층형 파라미터 서버(HPS)를 사용해 다중 서버 전반에 임베딩을 분산합니다(Figure 4 참고). HPS는 3곳에 위치한 캐시에 임베딩을 저장하는 계층형 메모리 시스템으로, 속도와 용량의 균형을 점진적으로 맞춰갑니다.
GPU 캐시 레이어
GPU 캐시는 액세스가 가장 빈번한 임베딩을 추론이 진행될 곳과 가장 가까운 위치에 보관합니다. 임베딩이 이미 GPU상에 있으므로 추론 시에 데이터 이동에 따른 지연 시간이 줄어듭니다. 임베딩의 액세스 패턴은 대개 멱법칙(power law)을 모방하며, GPU 캐시를 최대한 많은 임베딩으로 채울 때 이익을 극대화할 수 있습니다.
CPU 메모리 레이어
CPU 메모리 레이어는 GPU 캐시보다 용량이 큽니다. 그러나 데이터는 추론 전에 GPU로 옮겨야 하며, 추론 시에는 액세스가 더 느립니다. HPS의 CPU 메모리 레이어는 분산 해시 맵(hash map) 등의 다중 접근법을 구현합니다. 노트북 예제에서는 레디스를 사용해 임베딩을 메모리의 캐시에 저장합니다. HugeCTR은 레디스 클러스터를 완전 지원해 임베딩 테이블 메모리를 서버 전반에 분산시킵니다.
SSD 레이어
SSD 레이어는 HPS에서 가장 크고 느린 레이어입니다. 전체 임베딩 테이블이 SSD 레이어에 보관됩니다. 이 레이어는 분산된 임베딩 테이블이 장애 시나리오 발생 시에도 손실되지 않게 보장해줍니다. 이를 위해 각 서버마다 모든 모델용 임베딩 테이블의 전체 세트가 포함되어 있습니다.
롤링 업데이트
임베딩 업데이트는 온라인 추천 시스템의 호스팅에 필수적인 부분입니다. 온라인 추천 시스템의 예제에서 우리는 레디스 기능을 바탕으로 백그라운드에서 업데이트를 진행했습니다. 그러나 이 업데이트는 훈련을 마친 DLRM 모델이 사용하는 임베딩 테이블은 처리하지 않습니다.
그 대신 피처와 모델의 드리프트를 피하기 위한 업데이트를 진행해야 합니다. 업데이트는 새 버전의 DLRM을 NVIDIA Triton으로 업로드해 수행할 수 있습니다. 그러나 HugeCTR 프레임워크로 훈련한 것과 같은 대규모 모델들은 전체 크기가 테라바이트 규모에 달할 수 있어 업데이트가 쉽지 않습니다.
대규모 모델의 업데이트 문제를 해결하기 위해 NVIDIA는 카프카(Kafka)를 사용하는 롤링 업데이트 시스템을 구현했습니다. 이 시스템은 업데이트된 임베딩을 카프카 파이프라인 메시지로 NVIDIA Triton 서버의 HugeCTR 백엔드에 보냅니다. 그 결과 DLRM 모델의 온라인 훈련과 서빙이 동시에 수행됩니다. 이 같은 온라인의 대규모 아키텍처는 ‘모놀리스: 실시간 추천 시스템과 무충돌 임베딩 테이블’에서 논의된 아키텍처와 아주 유사합니다.
클라우드 기반 배포
첨부된 노트북은 NVIDIA Triton을 HugeCTR 백엔드로, HPS를 도커(로컬)와 AWS(클라우드)의 테라폼으로 구성, 배포하는 방법의 예제를 보여줍니다. 그러나 경우에 따라서는 HPS 인프라의 자체 관리형 배포가 바람직하지 않을 수 있습니다.
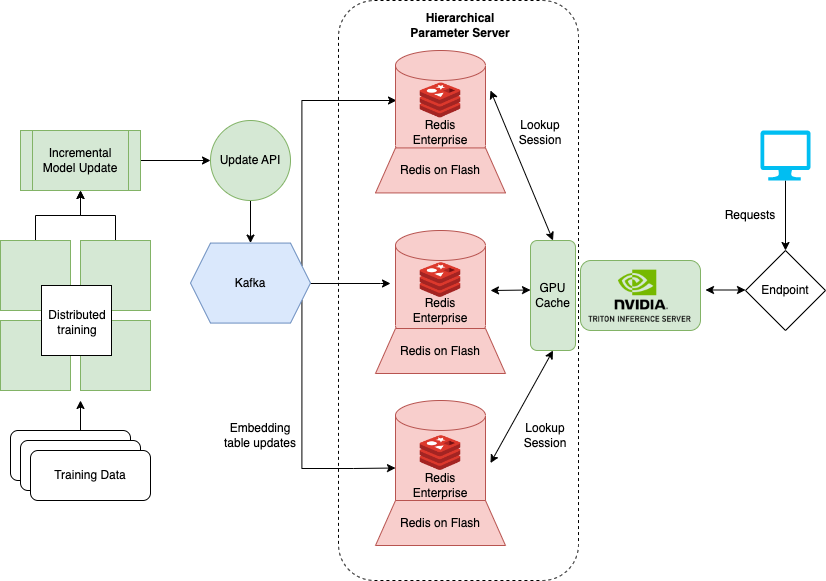
HPS의 규모별 실행에 필요한 여러 인프라의 시작과 관리를 제공하는 레디스 공급업체들이 있습니다. 그중 한 곳인 레디스 엔터프라이즈(Redis Enterprise)는 클라우드에 배포된 관리형 버전의 레디스를 제공하고, HPS 인프라를 간소화합니다.
Figure 5에서는 RocksDB 기반 SSD 레이어가 레디스 엔터프라이즈 플래시 기능(RoF)으로 대체됐습니다. RoF를 사용하면 NVIDIA Triton의 HugeCTR 모델을 재배포할 필요 없이 레디스에서 SSD와 플래시 간 비율을 직접 조정할 수 있습니다. 이는 트래픽의 고점과 저점 조정에 유용합니다.
기존의 RocksDB 레이어에서는 각 모델의 임베딩 테이블이 모든 추론 노드에 저장되어 시스템 가용성을 향상시킵니다. 이렇게 하면 치명적인 이벤트가 발생하는 경우에도 최소한 하나의 컴퓨팅 인스턴스는 살아남아 모델 파라미터와 추론 서비스가 복구될 수 있습니다. 그 대신 RoF는 복제(replication)를 레디스 데이터베이스 샤드 전반에 분산시켜 전체 HPS 스토리지의 요구 사항을 줄입니다.
레디스 엔터프라이즈는 서비스 수준 계약(SLA)을 통해 자동 조치(failover times) 시간과 가용성(99.999%), 액티브 액티브 지오 디스트리뷰션(active-active geo distribution), 데이터베이스의 추가 샤딩으로 확장이 가능한 아이옵스(IOPS)를 제공합니다. 임베딩을 업데이트할 카프카 메시지의 구독자(subscriber) 수도 단일 엔드포인트로 줄어듭니다. 이 아키텍처를 사용하면 전체 서버가 간단해지고 유지관리 또한 쉬워집니다.
이 인프라를 AWS에서 시작하기 위한 테라폼 스크립트와 엔서블 플레이북을 RedisVentures/Redis-Recsys 깃허브 저장소에서 만나볼 수 있습니다.
요약
이번 포스팅에서는 NVIDIA Merlin 프레임워크로 추천 시스템을 생성하고 레디스를 실시간 데이터 레이어로 사용하는 세 가지 활용 사례를 살펴봤습니다. 각각의 사례는 연산이 특히 복잡한 애플리케이션에서 데이터가 확장될 때조차 저지연 솔루션을 제공합니다.
이 블로그에 열거된 SDK의 대부분의 독점 액세스, 얼리 액세스, 기술 세션, 데모, 교육 과정, 리소스는 NVIDIA 개발자 프로그램 회원은 무료로 혜택을 받으실 수 있습니다. 지금 무료로 가입하여 NVIDIA의 기술 플랫폼에서 구축하는 데 필요한 도구와 교육에 액세스하시고 여러분의 성공을 가속화 하세요.