
Jetson용 NVIDIA Metropolis 마이크로서비스는 최신 AI 접근 방식을 사용하면서 프로덕션 품질의 비전 AI 애플리케이션을 빠르게 구축할 수 있는 배포하기 쉬운 서비스 제품군을 제공합니다.
이 포스팅에서는 거의 모든 모델에 대한 일반적인 레시피로 사용할 수 있는 참조 예제를 통해 NVIDIA Jetson 엣지 AI 플랫폼에서 Metropolis 마이크로서비스를 사용하여 생성형 AI 기반 애플리케이션을 개발 및 배포하는 방법을 설명합니다.
이 레퍼런스 예제에서는 독립형 제로 샷 감지 NanoOwl 애플리케이션을 사용하며, 이를 Jetson용 Metropolis 마이크로서비스와 통합하여 신속하게 프로토타이핑하고 프로덕션에 배포할 수 있도록 합니다.
생성형 AI로 애플리케이션 혁신
생성형 AI는 모델이 이전 방법보다 더 개방적인 방식으로 세상을 이해할 수 있도록 지원하는 새로운 종류의 머신 러닝입니다.
대부분의 생성형 AI의 핵심은 인터넷 규모의 데이터로 학습된 트랜스포머 기반 모델입니다. 이러한 모델은 여러 도메인에 걸쳐 훨씬 더 폭넓게 이해하므로 다양한 작업의 근간으로 사용할 수 있습니다. 이러한 유연성 덕분에 CLIP, Owl, Llama, GPT, Stable Diffusion과 같은 모델은 자연어 입력을 이해할 수 있습니다. 제로 또는 퓨 샷 학습이 가능합니다.

Jetson용 생성형 AI 모델에 대한 자세한 내용은 NVIDIA Jetson 생성형 AI 랩 및 NVIDIA Jetson으로 생성형 AI 실현을 참조하세요.
Jetson용 Metropolis 마이크로서비스
Metropolis 마이크로서비스는 Jetson에서 프로덕션에 바로 사용할 수 있는 AI 애플리케이션을 빠르게 구축하는 데 사용할 수 있습니다. Metropolis 마이크로서비스는 카메라 관리, 시스템 모니터링, IoT 디바이스 통합, 네트워킹, 스토리지 등을 위한 쉽게 배포할 수 있는 모듈식 Docker 컨테이너 세트입니다. 이러한 컨테이너를 한데 모아 강력한 애플리케이션을 만들 수 있습니다. 그림 2는 사용 가능한 마이크로서비스를 보여줍니다.
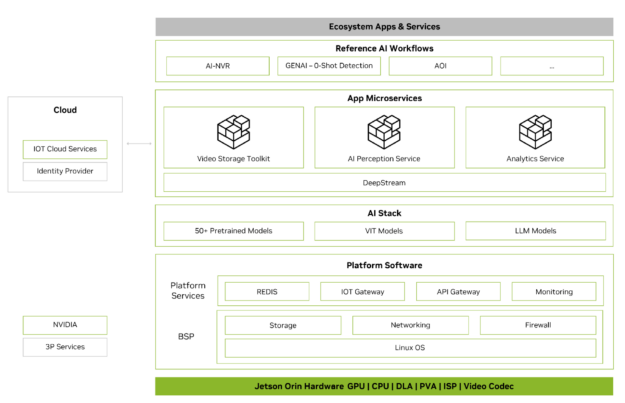
자세한 내용은 Jetson용 Metropolis 마이크로서비스 백서를 참조하세요.
Metropolis 마이크로서비스와 생성형 AI 앱 통합
Metropolis 마이크로서비스와 생성형 AI를 결합하여 교육이 거의 또는 전혀 필요하지 않은 모델을 활용할 수 있습니다. 그림 3은 Jetson의 Metropolis Microservices를 사용하여 생성형 AI 기반 애플리케이션을 구축하는 일반적인 방법으로 사용할 수 있는 NanoOwl 참조 예제의 다이어그램을 보여줍니다.
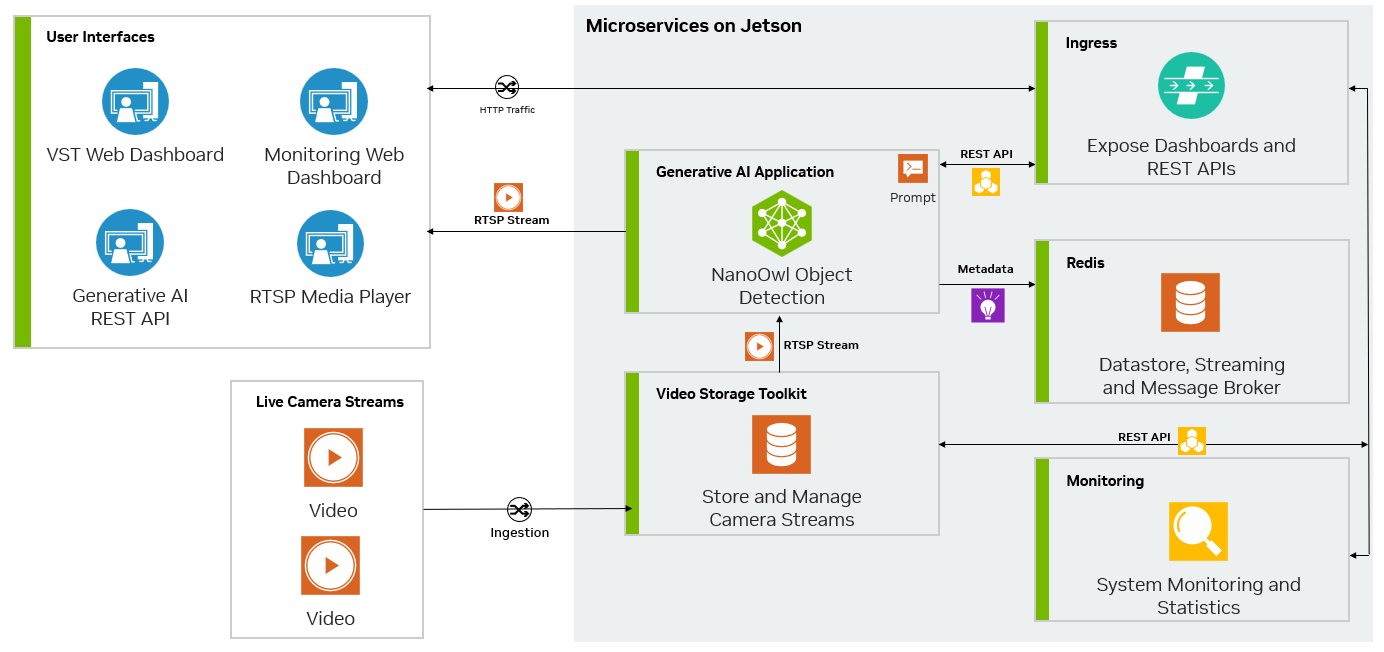
Metropolis 마이크로서비스를 통한 애플리케이션 사용자 정의
GitHub에는 많은 오픈 소스 생성형 AI 모델이 있으며, 일부는 Jetson에서 특별히 실행되도록 최적화되어 있습니다. 이러한 모델 중 일부는 NVIDIA Jetson 생성형 AI 랩에서 찾을 수 있습니다.
이러한 모델의 대부분은 공통점이 많습니다. 일반적으로 텍스트와 이미지를 입력으로 받을 수 있습니다. 이러한 모델은 먼저 구성 옵션을 사용하여 메모리에 로드해야 합니다. 그런 다음 이미지와 텍스트가 전달되는 추론 함수로 모델을 호출하여 출력을 생성할 수 있습니다.
Python 참조 예제에서는 생성형 AI 모델로 NanoOwl을 사용했습니다. 그러나 참조 예제의 일반적인 레시피는 거의 모든 생성형 AI 모델에 적용할 수 있습니다.
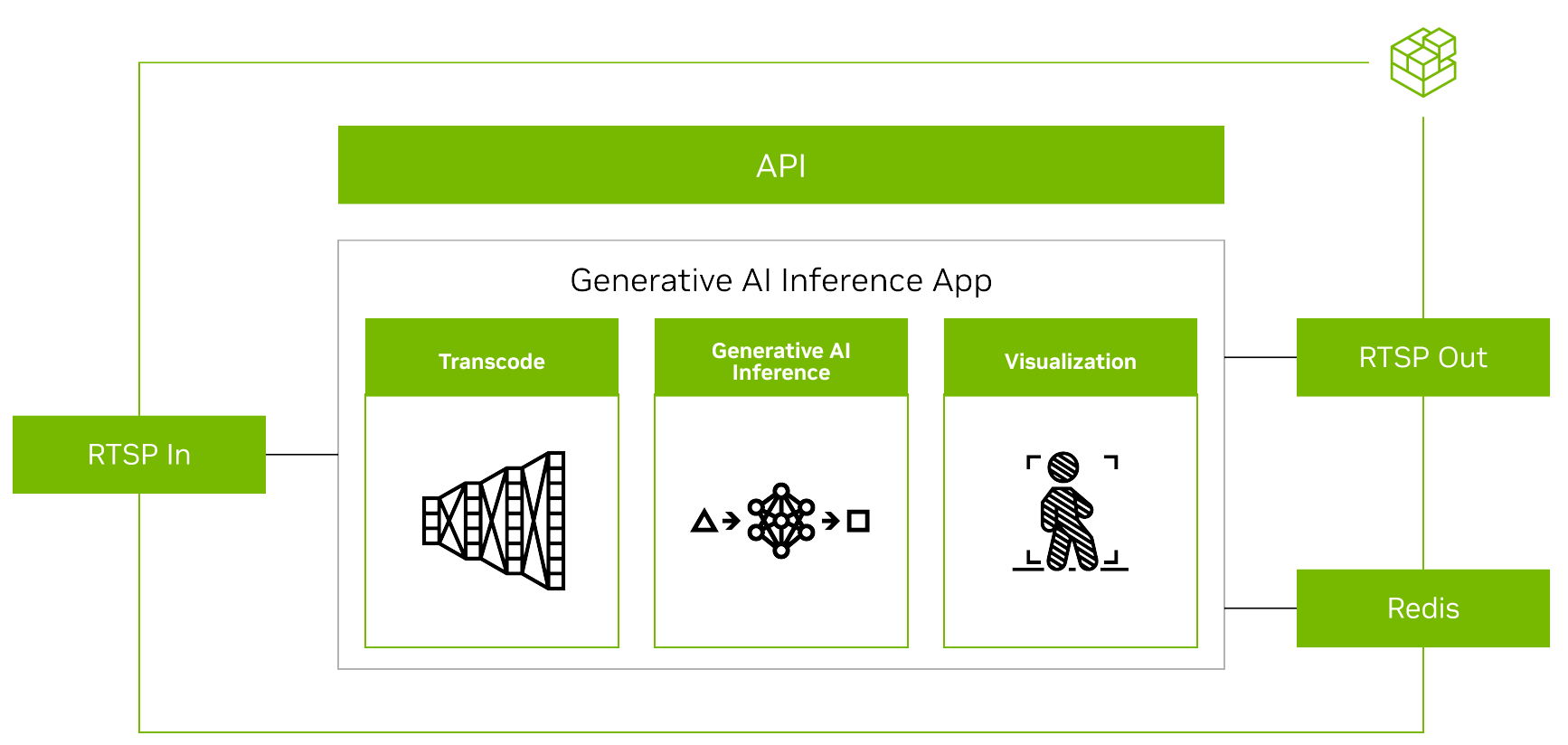
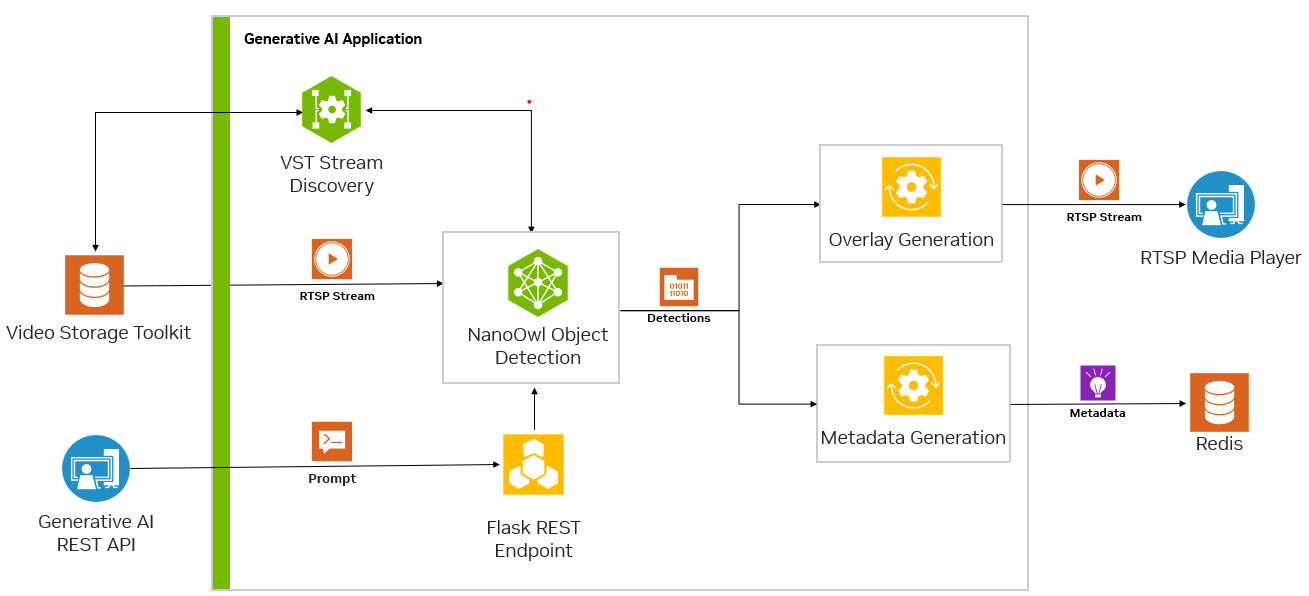
Metropolis 마이크로서비스로 생성형 AI 모델을 실행하려면 먼저 다른 마이크로서비스의 입력과 출력을 조정해야 합니다(그림 4).
스트리밍 비디오의 경우, 입력과 출력은 RTSP 프로토콜을 사용합니다. RTSP는 비디오 수집 및 관리 마이크로서비스인 비디오 스토리지 툴킷(VST)에서 스트리밍됩니다. 출력은 오버레이된 추론 출력과 함께 RTSP를 통해 스트리밍됩니다. 출력 메타데이터는 다른 애플리케이션이 데이터를 읽을 수 있는 Redis 스트림으로 전송됩니다. 자세한 내용은 Metropolis 마이크로서비스가 포함된 비디오 스토리지 툴킷 데모 동영상을 참조하세요.
둘째, 생성형 AI 애플리케이션에는 프롬프트와 같은 일부 외부 인터페이스가 필요하므로 애플리케이션이 REST API 요청을 수신할 수 있어야 합니다.
마지막으로, 애플리케이션은 다른 마이크로서비스와 원활하게 통합될 수 있도록 컨테이너화되어야 합니다. 그림 5는 Redis에서 NanoOwl 객체를 감지하고 메타데이터를 출력하는 예시를 보여줍니다.
이 참조 예제에서는 NanoOwl을 사용합니다. 그러나 Python에서 호출할 수 있는 로드 및 추론 함수가 있는 모든 모델에 대해 이 단계를 따를 수 있습니다. 이 게시물에는 생성형 AI와 Metropolis 마이크로서비스를 결합하는 방법의 주요 아이디어를 강조하기 위해 몇 가지 Python 코드 예제가 표시되어 있지만, 일반적인 레시피에 집중하기 위해 일부 코드는 생략되었습니다. 전체 구현에 대한 자세한 내용은 /NVIDIA-AI-IOT/mmj_genai GitHub 프로젝트의 참조 예제를 참조하십시오.
Metropolis 마이크로서비스와의 통합을 위한 생성형 AI 모델을 준비하려면 다음 단계를 따르세요:
- 모델 추론을 위한
predict함수 호출 jetson-utils라이브러리를 사용하여 RTSP I/O를 추가합니다.- 플라스크의 신속한 업데이트를 위해 REST 엔드포인트를 추가합니다.
mmj_utils를 사용하여 오버레이를 생성합니다.mmj_utils를 사용하여 VST와 상호 작용하여 스트림을 가져옵니다.mmj_utils를 사용하여 Redis에 메타데이터를 출력합니다.
모델 추론을 위한 예측 함수 호출
NanoOwl은 생성형 AI 모델을 OwlPredictor 클래스로 래핑합니다. 이 클래스가 인스턴스화되면 모델을 메모리에 로드합니다. 이미지와 텍스트 입력에 대한 추론을 수행하려면 predict 함수를 호출하여 출력을 가져옵니다.
이 경우 출력은 감지된 객체에 대한 경계 상자 및 레이블 목록입니다.
import PIL.Image
import time
import torch
from nanoowl.owl_predictor import OwlPredictor
image = PIL.Image.open("my_image.png")
prompt = ["an owl", "a person"]
#Load model
predictor = OwlPredictor(
"google/owlvit-base-patch32",
image_encoder_engine="../data/owlvit_image_encoder_patch32.engine"
)
#Embed Text
text_encodings = predictor.encode_text(text)
#Inference
output = predictor.predict(
image=image,
text=prompt,
text_encodings=text_encodings,
threshold=0.1,
pad_square=False)대부분의 생성형 AI 모델은 유사한 Python 인터페이스를 가지고 있습니다. 이미지와 텍스트 입력이 있고, 모델을 로드해야 하며, 모델이 프롬프트와 이미지에서 추론하여 일부 출력을 얻을 수 있습니다. 자체 생성형 AI 모델을 가져오려면 클래스로 래핑하고 OwlPredictor 클래스와 유사한 인터페이스를 구현하면 됩니다.
jetson-utils 라이브러리를 사용하여 RTSP I/O 추가하기
jetson-utils 라이브러리를 사용하여 RTSP 비디오 스트림 입력을 추가할 수 있습니다. 이 라이브러리는 RTSP 스트림에서 프레임을 캡처하고 새 RTSP 스트림에서 프레임을 출력하는 데 사용할 수 있는 videoSource 및 videoOutput 클래스를 제공합니다.
from jetson_utils import videoSource, videoOutput
stream_input = "rtsp://0.0.0.0:8554/input"
stream_output = "rtsp://0.0.0.0:8555/output"
#Create stream I/O
v_input = videoSource(stream_input)
v_output = videoOutput(stream_output)
while(True):
image = v_input.Capture() #get image from stream
output = predictor.predict(image=image, text=prompt, ...)
new_image = postprocess(output)
v_output.Render(new_image) #write image to stream 이 코드 예제는 RTSP 스트림에서 프레임을 캡처한 다음 모델 추론 함수에 전달할 수 있습니다. 모델 출력에서 새 이미지가 생성되어 출력 RTSP 스트림에 렌더링됩니다.
Flask로 신속한 업데이트를 위한 REST 엔드포인트 추가하기
많은 생성형 AI 모델은 일종의 프롬프트 또는 텍스트 입력을 허용합니다. 사용자나 다른 서비스가 프롬프트를 동적으로 업데이트할 수 있도록 하려면 프롬프트 업데이트를 수락하고 이를 모델에 전달하는 Flask를 사용하여 REST 엔드포인트를 추가하세요.
Flask 서버를 모델과 더 쉽게 통합하려면 자체 스레드에서 Flask 서버를 시작하기 위해 호출할 수 있는 래퍼 클래스를 만드세요. 자세한 내용은 /NVIDIA-AI-IOT/mmj_genai GitHub 프로젝트를 참조하세요.
from flask_server import FlaskServer
#Launch flask server and connect queue to receive prompt updates
flask_queue = Queue() #hold prompts from flask input
flask = FlaskServer(flask_queue)
flask.start_flask()
while(True):
...
if not flask_queue.empty(): #get prompt update
prompt = flask_queue.get()
output = predictor.predict(image=image, text=prompt, ...)들어오는 프롬프트 업데이트를 보관하는 큐를 통해 메인 스크립트와 플라스크 엔드포인트를 연결하세요. GET 요청이 REST 엔드포인트로 전송되면, Flask 서버는 업데이트된 프롬프트를 대기열에 넣습니다. 그러면 메인 루프가 큐에서 새 프롬프트가 있는지 확인하고 업데이트된 클래스에 대한 추론을 위해 모델에 전달할 수 있습니다.
mmj_utils를 사용해 오버레이 생성하기
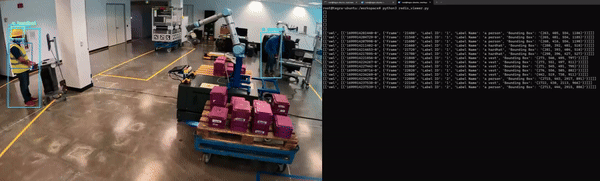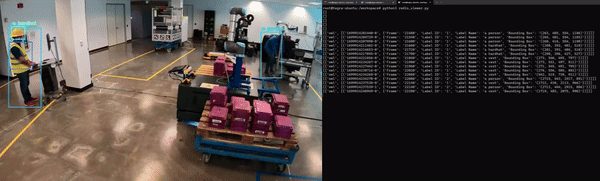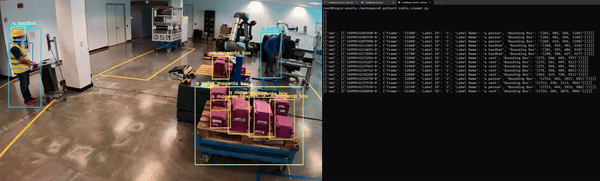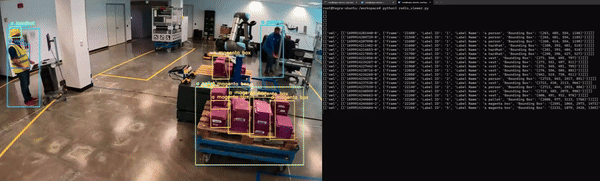
컴퓨터 비전 작업의 경우, 모델 출력의 시각적 오버레이를 보는 것이 좋습니다(그림 6). 객체 감지 모델의 경우, 입력 이미지에 모델이 생성한 경계 상자와 레이블을 오버레이하여 모델이 각 객체를 감지한 위치를 확인할 수 있습니다.

이 작업을 수행하려면 mmj_utils 라이브러리의 DetectionGenerationCUDA라는 유틸리티 클래스를 사용합니다. 이 라이브러리는 오버레이를 생성하는 데 사용되는 CUDA 가속 함수를 제공하는 jetson_utils에 의존합니다.
from mmj_utils.overlay_gen import DetectionOverlayCUDA
overlay_gen = DetectionOverlayCUDA(draw_bbox=True, draw_text=True, text_size=45) #make overlay object
while(True):
...
output = predictor.predict(image=image, text=prompt, ...)
#Generate overlay and output
text_labels = [objects[x] for x in output.labels]
bboxes = output.boxes.tolist()
image = overlay_gen(image, text_labels, bboxes)#generate overlay
v_output.Render(image)여러 키워드 인자를 사용하여 DetectionGenerationCUDA 오브젝트를 인스턴스화하여 텍스트 크기, 경계 상자 크기 및 색상을 필요에 맞게 조정할 수 있습니다. mmj_utils를 사용한 오버레이 생성에 대한 자세한 내용은 /NVIDIA-AI-IOT/mmj_utils GitHub 리포지토리를 참조하세요.
오버레이를 생성하려면 오브젝트를 호출하고 입력 이미지, 레이블 목록, 모델에서 생성된 바운딩 박스를 전달합니다. 그런 다음 입력 이미지에 레이블과 바운딩 박스를 그리고 오버레이가 적용된 수정된 이미지를 반환합니다. 그런 다음 이 수정된 이미지를 RTSP 스트림에서 렌더링할 수 있습니다.
mmj_utils를 사용하여 VST와 상호 작용하여 스트림 가져오기
VST는 RTSP 스트림을 관리하고 입력 및 출력 스트림을 볼 수 있는 멋진 웹 UI를 제공할 수 있습니다. VST와 통합하려면 VST REST API를 직접 사용하거나 VST REST API를 감싸는 mmj_utils의 VST 클래스를 사용하세요.
Python 스크립트에서 RTSP 입력 스트림을 하드코딩하는 대신 VST에서 RTSP 스트림 링크를 가져옵니다. 이 링크는 IP 카메라 또는 VST를 통해 관리되는 기타 비디오 스트림 소스에서 가져올 수 있습니다.
from mmj_utils.vst import VST
vst = VST("http://0.0.0.0:81")
vst_rtsp_streams = vst.get_rtsp_streams()
stream_input = vst_rtsp_streams[0]
v_input = videoSource(stream_input)
...이것은 VST에 연결하고 첫 번째 유효한 RTSP 링크를 가져옵니다. 여기에 더 복잡한 로직을 추가하여 특정 소스에 연결하거나 입력을 동적으로 변경할 수 있습니다.
mmj_utils를 사용하여 Redis에 메타데이터 출력하기
생성형 AI 모델은 다른 서비스에서 분석 및 인사이트를 생성하기 위해 다운스트림에서 사용할 수 있는 메타데이터를 생성합니다.
이 경우, NanoOwl은 감지된 객체에 대한 바운딩 박스를 출력합니다. 이 정보는 분석 서비스에서 캡처할 수 있는 Redis 스트림의 Metropolis 스키마에서 출력할 수 있습니다. mmj_utils 라이브러리에는 Redis에서 탐지 메타데이터를 생성하는 데 도움이 되는 클래스가 있습니다.
from mmj_utils.schema_gen import SchemaGenerator
schema_gen = SchemaGenerator(sensor_id=1, sensor_type="camera", sensor_loc=[10,20,30])
schema_gen.connect_redis(aredis_host=0.0.0.0, redis_port=6379, redis_stream="owl")
while True:
...
output = predictor.predict(image=image, text=prompt, ...)
#Output metadata
text_labels = [objects[x] for x in output.labels]
schema_gen(text_labels, bboxes)입력 카메라 스트림에 대한 정보로 SchemaGenerator 객체를 인스턴스화하고 Redis에 연결할 수 있습니다. 그런 다음 모델에서 생성된 텍스트 레이블과 바운딩 박스를 전달하여 객체를 호출할 수 있습니다. 감지 정보는 Metropolis 스키마로 변환되고 다른 마이크로서비스에서 사용할 수 있도록 Redis로 출력됩니다.
애플리케이션 배포
애플리케이션을 배포하기 위해 Ingress 및 Redis와 같은 플랫폼 서비스를 설정할 수 있습니다. 그런 다음, docker compose를 통해 사용자 정의 생성 AI 컨테이너를 VST와 같은 애플리케이션 서비스와 결합합니다. 필요한 모든 I/O 및 마이크로서비스 통합이 준비된 메인 애플리케이션이 준비되면(그림 7), 애플리케이션을 배포하고 Metropolis 마이크로서비스와 연결할 수 있습니다.
- 생성형 AI 애플리케이션을 컨테이너화합니다.
- 필요한 플랫폼 서비스를 설정합니다.
docker compose로 애플리케이션을 실행합니다.- 실시간으로 출력을 확인합니다.
생성형 AI 애플리케이션 컨테이너화
배포를 위한 첫 번째 단계는 Docker를 사용하여 생성형 AI 애플리케이션을 컨테이너화하는 것입니다.
이를 위한 쉬운 방법은 jetson-containers 프로젝트를 사용하는 것입니다. 이 프로젝트는 생성형 AI 모델을 포함한 머신 러닝 애플리케이션을 지원하기 위해 Jetson용 Docker 컨테이너를 쉽게 빌드할 수 있는 방법을 제공합니다. jetson-containers를 사용하여 필요한 종속성이 있는 컨테이너를 만든 다음, 애플리케이션 코드와 생성형 AI 모델을 실행하는 데 필요한 기타 패키지를 포함하도록 컨테이너를 추가로 사용자 지정하세요.
NanoOwl 예제용 컨테이너를 빌드하는 방법에 대한 자세한 내용은 GitHub 프로젝트의 /src/readme 파일을 참조하세요.
필요한 플랫폼 서비스 설정
다음으로 Metropolis 마이크로서비스에서 제공하는 필요한 플랫폼 서비스를 설정합니다. 이러한 플랫폼 서비스는 Metropolis 마이크로서비스와 함께 애플리케이션을 배포하는 데 필요한 많은 기능을 제공합니다.
이 참조 생성 AI 애플리케이션에는 인그레스, Redis, 모니터링 플랫폼 서비스만 필요합니다. 플랫폼 서비스는 APT를 통해 빠르게 설치하고 systemctl로 실행할 수 있습니다.
필요한 플랫폼 서비스를 설치하고 실행하는 방법에 대한 자세한 내용은 Jetson용 Metropolis 마이크로서비스 빠른 시작 가이드를 참조하세요.
docker compose로 애플리케이션 시작
애플리케이션이 컨테이너화되고 필요한 플랫폼 서비스가 설정되었으면 docker compose를 사용하여 VST 또는 Analytics와 같은 다른 애플리케이션 서비스와 함께 애플리케이션을 시작할 수 있습니다.
이렇게 하려면 필요한 시작 옵션과 함께 실행할 컨테이너를 정의하는 docker-compose.yaml 파일을 만듭니다. docker 작성 파일을 정의한 후에는 docker 작성 up 및 docker 작성 down 명령을 사용하여 애플리케이션을 시작하거나 중지할 수 있습니다.
docker 배포에 대한 자세한 내용은 GitHub 프로젝트의 /deploy/readme 파일을 참조하세요.
실시간으로 출력 보기
애플리케이션이 배포된 후에는 VST를 통해 RTSP 스트림을 추가하고 REST API를 통해 생성형 AI 모델과 상호 작용하여 신속한 업데이트를 전송하고 RTSP 출력을 보면서 실시간으로 탐지 변경 사항을 확인할 수 있습니다. 또한 Redis에서 메타데이터 출력을 확인할 수도 있습니다.
결론
이 게시물에서는 생성형 AI 모델을 가져와서 Jetson용 Metropolis 마이크로서비스와 통합하는 방법을 설명했습니다. 생성형 AI와 Metropolis 마이크로서비스를 사용하면 유연하고 정확한 지능형 비디오 분석 애플리케이션을 빠르게 구축할 수 있습니다.
제공되는 서비스에 대한 자세한 내용은 Jetson용 Metropolis 마이크로서비스 제품 페이지를 참조하십시오. 전체 참조 애플리케이션과 이를 직접 구축하고 배포하는 방법에 대한 자세한 단계를 보려면 /NVIDIA-AI-IOT/mmj_genai GitHub 프로젝트를 참조하십시오.