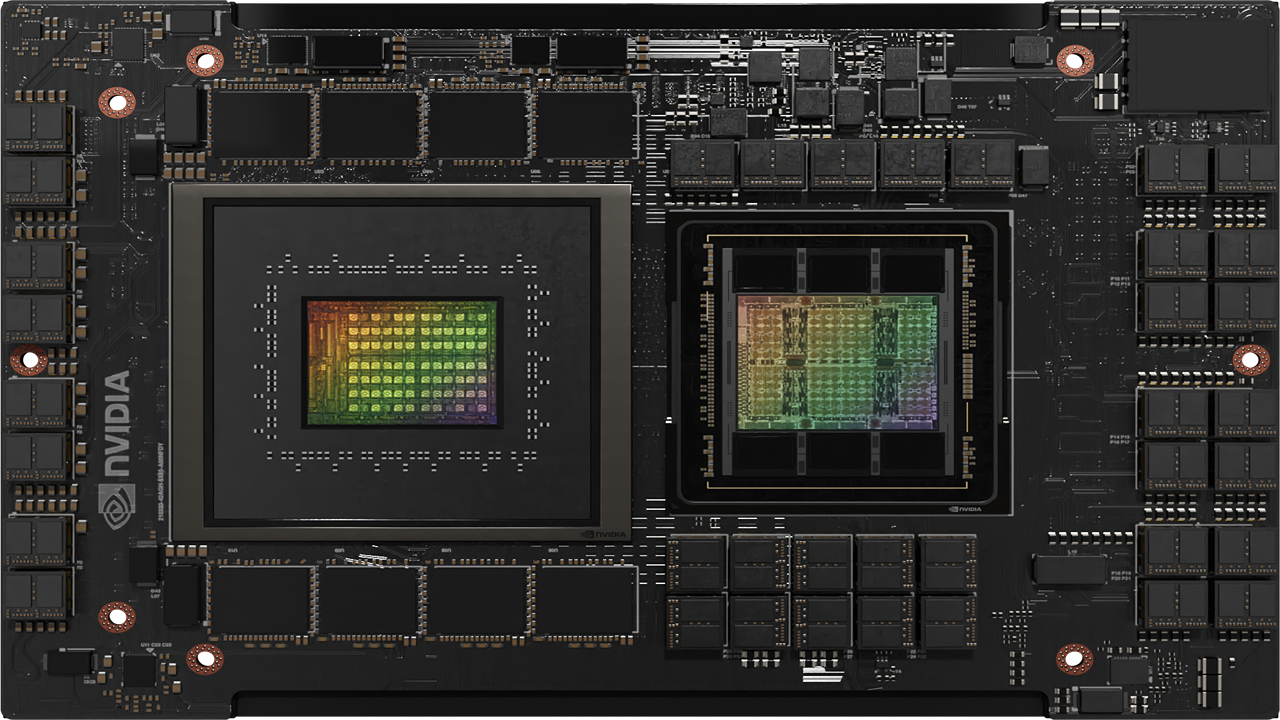
NVIDIA Grace CPU는 NVIDIA에서 처음으로 개발한 데이터 센터 CPU입니다. 개발 목적은 세계 최초의 슈퍼칩 설계였습니다.
NVIDIA Grace CPU는 오늘날 디지털 트윈, 클라우드 게이밍 및 그래픽, AI, 고성능 컴퓨팅(HPC)을 실행하는 데이터 센터 워크로드의 수요에 따라 우수한 성능과 에너지 효율을 제공할 수 있도록 설계되었으며, Arm Scalable Vector Extensions version two(SVE2) 명령어 세트를 구현하는 Armv9 CPU 코어 72개가 탑재된 것이 특징입니다. 이러한 코어들은 중첩 가상화 기능과 S-EL2 지원을 포함한 가상화 확장도 지원합니다.
NVIDIA Grace CPU가 지원하는 Arm 사양은 다음과 같습니다.
- RAS v1.1 Generic Interrupt Controller(GIC) v4.1
- Memory Partitioning and Monitoring(MPAM)
- System Memory Management Unit(SMMU) v3.1
Grace CPU는 NVIDIA Hopper GPU와 페어링하여 대규모 AI 훈련, 추론 및 HPC에 필요한 NVIDIA Grace CPU 슈퍼칩을 설계할 목적으로, 혹은 HPC 및 클라우드 컴퓨팅 워크로드의 요건에 따라 다른 Grace CPU와 페어링하여 고성능 CPU를 설계할 목적으로 만들어졌습니다.
본 게시글을 읽으면서 Grace CPU의 주요 기능에 대해 자세히 알아보세요.
NVLink-C2C를 통한 고속 칩-투-칩 인터커넥트
Grace Hopper 슈퍼칩과 Grace 슈퍼칩은 슈퍼칩 통신을 위한 백본 역할을 하는 NVIDIA NVLink-C2C 고속 칩-투-칩 인터커넥트를 통해 연결됩니다.
NVLink-C2C는 서버에서 다수의 GPU를 연결할 때, 그리고 NVLink Switch System으로 다수의 GPU 노드를 연결할 때 사용되는 NVIDIA NVLink를 확장한 것입니다.
NVLink-C2C는 패키지 다이 간 원시 양방향 대역폭이 900GB/s이기 때문에 PCIe Gen 5 x16 링크의 대역폭(NVLink 사용 시 NVIDIA Hopper GPU 사이에 제공되는 대역폭과 동일)보다 7배 빠른 반면 지연 시간은 더욱 낮습니다. 또한 필요한 전송 에너지가 비트당 1.3 피코줄에 불과하여 PCIe Gen 5과 비교했을 때 에너지 효율이 5배 이상 높습니다.
그 밖에도 NVLink-C2C는 코히어런트 인터커넥트이기 때문에 Grace CPU 슈퍼칩을 사용해 표준 코히어런트 CPU 플랫폼을 프로그래밍할 때, 그리고 Grace Hopper 슈퍼칩을 사용해 이기종 프로그래밍 모델을 프로그래밍할 때도 일관성이 유지됩니다.
NVIDIA Grace CPU를 사용한 표준 인증 플랫폼
NVIDIA Grace CPU 슈퍼칩은 소프트웨어 개발자에게 표준 인증 플랫폼을 제공할 목적으로 설계되었습니다. Arm은 Arm 에코시스템의 표준화를 위한 Arm SystemReady 이니셔티브에 따라 몇 가지 사양을 세트로 제공합니다.
Grace CPU는 상용 운영 체제 및 소프트웨어 애플리케이션과 호환성을 제공하는 Arm 시스템 표준을 대상으로 설계되었기 때문에 처음부터 NVIDIA Arm 소프트웨어 스택을 이용합니다.
또한 Grace CPU는 Arm Server Base System Architecture(SBSA)에 따라 표준 인증 하드웨어 및 소프트웨어 인터페이스를 사용합니다. 나아가서 Grace CPU 기반 시스템에서 표준 부팅 흐름을 따르기 위해 Arm Server Base Boot Requirements(SBBR)를 지원할 수 있도록 설계되었습니다.
그 밖에도 Grace CPU는 캐시 및 대역폭 분할과 대역폭 모니터링을 고려하여 Arm Memory Partitioning and Monitoring(MPAM)을 지원합니다.
Grace CPU는 Arm Performance Monitoring Units도 기본 제공하여 CPU 코어 성능을 비롯한 SoC(System-on-a-Chip) 아키텍처의 다른 서브시스템 성능까지 모니터링할 수 있습니다. 따라서 Linux perf 같은 표준 도구를 사용한 성능 측정도 가능합니다.
Grace Hopper 슈퍼칩을 통한 통합 메모리
Grace CPU와 Hopper GPU가 결합된 NVIDIA Grace Hopper 슈퍼칩은 CUDA 8.0에서 처음 도입된 CUDA Unified Memory 프로그래밍 모델을 기반으로 합니다.
NVIDIA Grace Hopper 슈퍼칩에 도입된 Unified Memory에는 공유 페이지 테이블이 포함되어 있어서 Grace CPU와 Hopper GPU가 주소 공간 및 페이지 테이블까지 CUDA 애플리케이션과 공유할 수 있습니다.
Hopper GPU 역시 페이징이 가능한 메모리 할당에 액세스할 수 있습니다. 따라서 Grace Hopper 슈퍼칩을 사용하는 프로그래머는 시스템 할당자로 GPU 메모리를 할당할 뿐만 아니라 malloc 메모리 포인터를 GPU와 교환할 수도 있습니다.
NVLink-C2C는 Grace CPU와 Hopper GPU 사이에서 원자적 연산을 지원하기 때문에 CUDA 10.2에서 처음 도입된 C++ 원자적 연산을 최대한 이용할 수 있습니다.
NVIDIA Scalable Coherency Fabric
Grace CPU는 NVIDIA Scalable Coherency Fabric(SCF)이 적용되었습니다. NVIDIA에서 설계한 SCF는 데이터 센터의 요건에 따라 확장 가능하도록 개발된 메시 패브릭이자 분산 캐시입니다. SCF는 3.2TB/s의 이분 대역폭을 제공하여 NVLink-C2C, CPU 코어, 메모리 및 시스템 IO 사이에서 데이터 트래픽 흐름이 가능합니다.
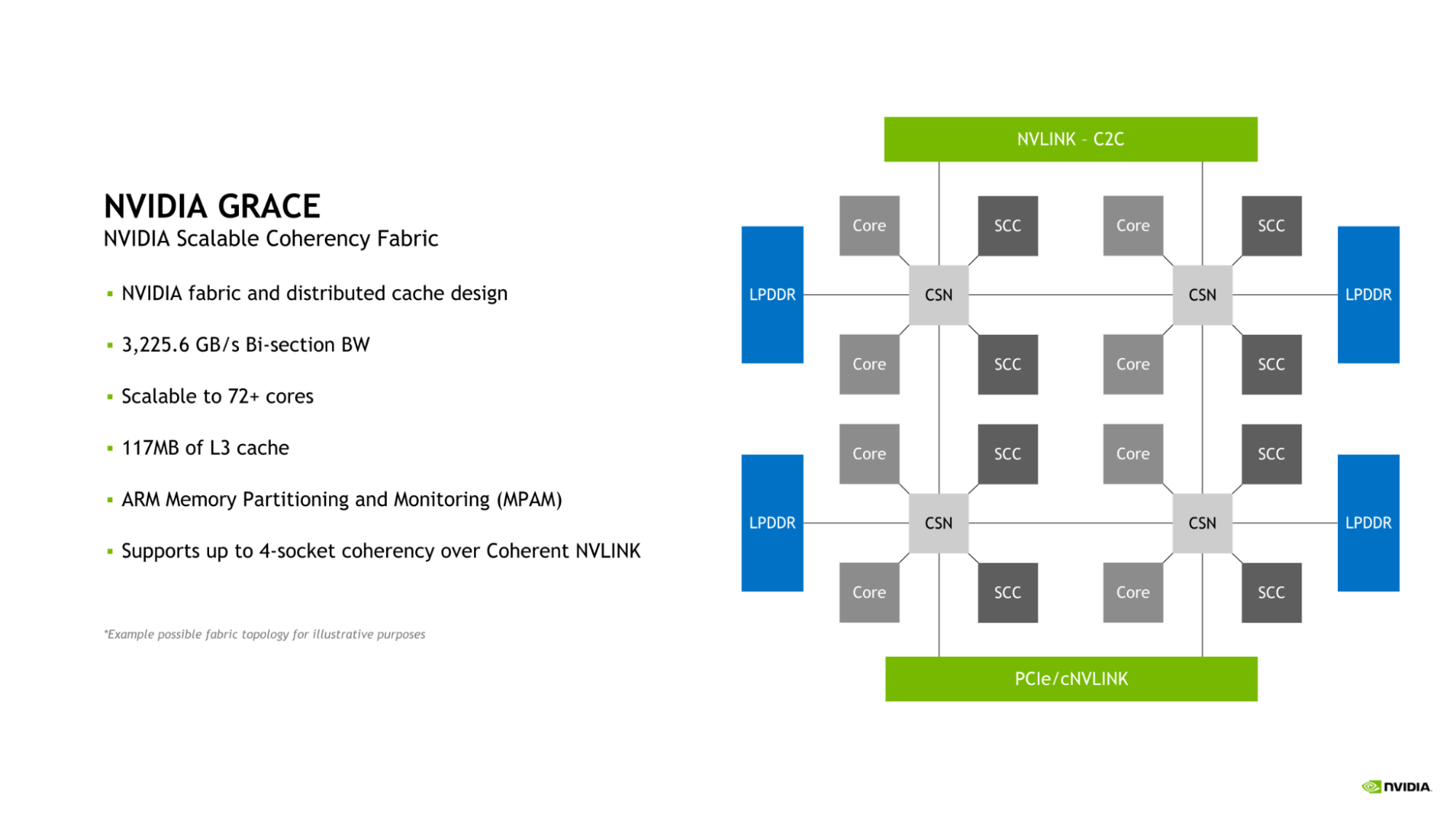
Grace CPU 1개에 CPU 코어 72개와 캐시 117MB가 탑재되지만 SCF는 이러한 구성을 넘어 확장할 수 있도록 설계되었습니다. Grace CPU 2개가 결합되어 Grace 슈퍼칩을 이루면 이러한 수치는 각각 2배가 되어 CPU 코어 수는 144개, L3 캐시는 234MB가 됩니다.
CPU 코어와 SCF 캐시 파티션(SCC)은 메시 전체로 분산됩니다. 캐시 스위치 노드(CSN)는 패브릭을 통해 데이터를 전송하여 CPU 코어와 캐시 메모리, 그리고 나머지 시스템 사이에서 인터페이스 역할을 하며 높은 대역폭 처리량을 지원합니다.
메모리 분할 및 모니터링
Grace CPU는 Memory System Resource Partitioning and Monitoring(MPAM) 기능을 지원합니다. 여기에서 MPAM이란 시스템 캐시와 메모리 리소스를 모두 분할할 수 있는 Arm 표준을 말합니다.
MPAM에 따라 파티션 ID(PARTID)가 시스템 내부 요청자에게 할당됩니다. 캐시 용량, 메모리 대역폭 같은 리소스를 각 PARTID에 따라 분할하거나 모니터링할 수 있는 이유도 이러한 설계에 있습니다.
Grace CPU에서 SCF 캐시는 MPAM을 사용해 캐시 용량 분할과 메모리 대역폭 분할을 모두 지원합니다. 또한 Performance Monitor Group(PMG)을 사용해 리소스 사용량을 모니터링하는 것도 가능합니다.
메모리 서브시스템을 통한 대역폭 및 에너지 효율 개선
Grace CPU는 우수한 대역폭과 에너지 효율을 위해 32채널 LPDDR5X 메모리 인터페이스를 구현합니다. 따라서 메모리 용량이 최대 512GB에 달하고, 메모리 대역폭도 최대 546GB/s에 이릅니다.
확장 GPU 메모리
Grace Hopper 슈퍼칩에서 빼놓을 수 없는 특징으로 확장 GPU 메모리(EGM)가 있습니다. 대규모 NVLink 네트워크에서 연결된 Hopper GPU가 Grace Hopper 슈퍼칩의 Grace CPU에 연결된 LPDDR5X 메모리에 액세스할 수 있기 때문에 GPU에 사용할 수 있는 메모리 풀이 크게 확장됩니다.
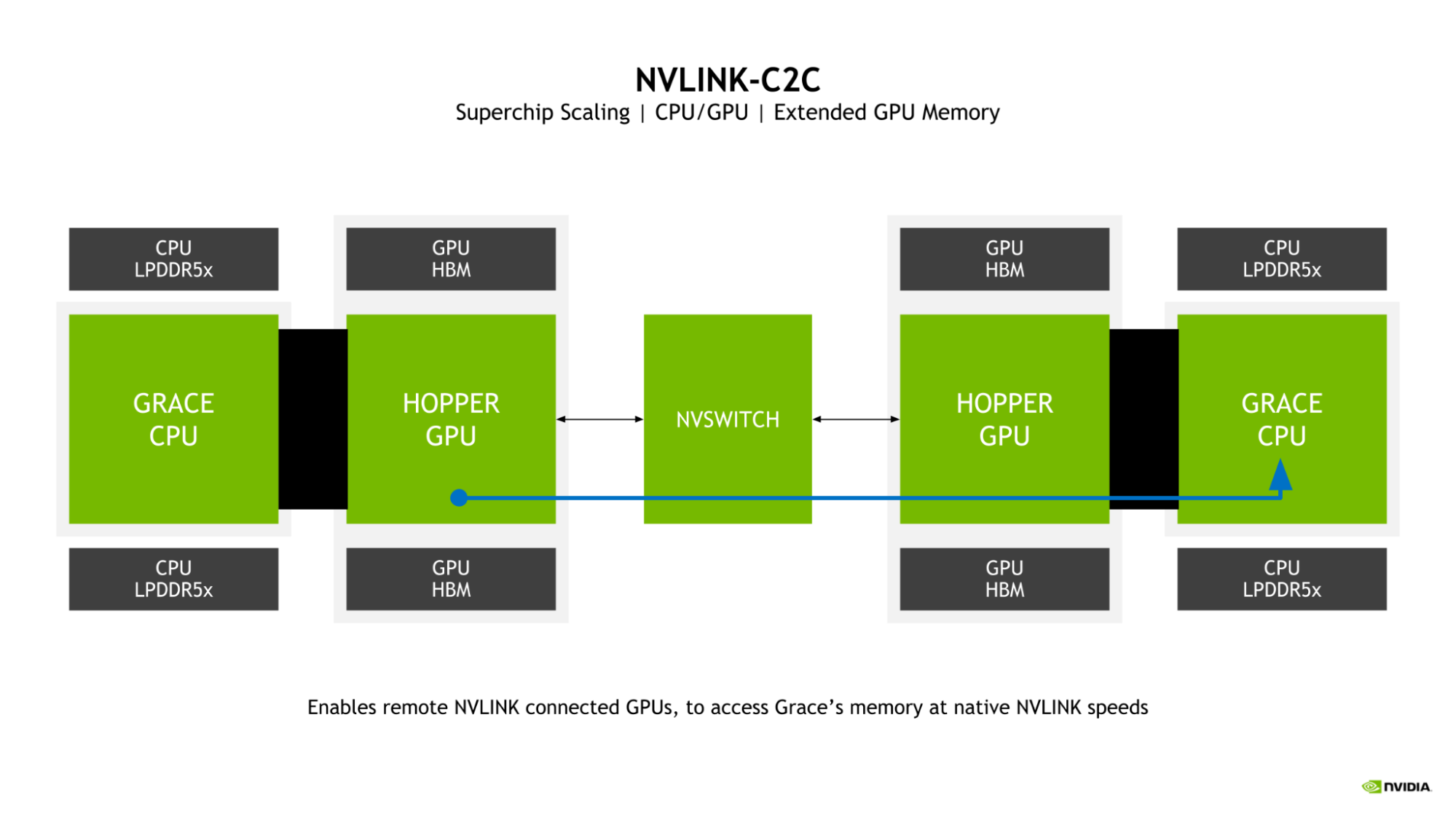
Hopper GPU가 NVLink Grace CPU 메모리에 기본 속도로 액세스할 수 있는 이유는 GPU를 서로 연결하는 NVLink와 NVLink-C2C의 양방향 대역폭이 슈퍼칩에서 서로 일치하기 때문입니다.
대역폭과 에너지 효율의 균형을 유지하는 LPDDR5X
Grace CPU에 LPDDR5X를 선택한 이유는 대규모 AI 및 HPC 워크로드에 따른 대역폭, 에너지 효율, 용량, 비용 등을 최적화하여 균형을 맞추어야 했기 때문입니다.
4사이트 HBM2e 메모리 서브시스템도 높은 메모리 대역폭과 우수한 에너지 효율을 제공했지만 DDR5 또는 LPDDR5X와 비교했을 때 기가바이트당 비용이 3배나 높았습니다.
또한 이러한 구성은 용량이 64GB로 제한되어 LPDDR5X를 사용했을 때 Grace CPU에 사용할 수 있는 최대 용량의 1/8에 불과했습니다.
그 밖에도 기존 8채널 DDR5 설계와 비교하면 Grace CPU LPDDR5X 메모리 서브시스템은 최대 53% 높은 대역폭을 제공할 뿐만 아니라 필요한 기가바이트당 전력도 1/8에 불과하여 전력 효율도 월등하게 높습니다.
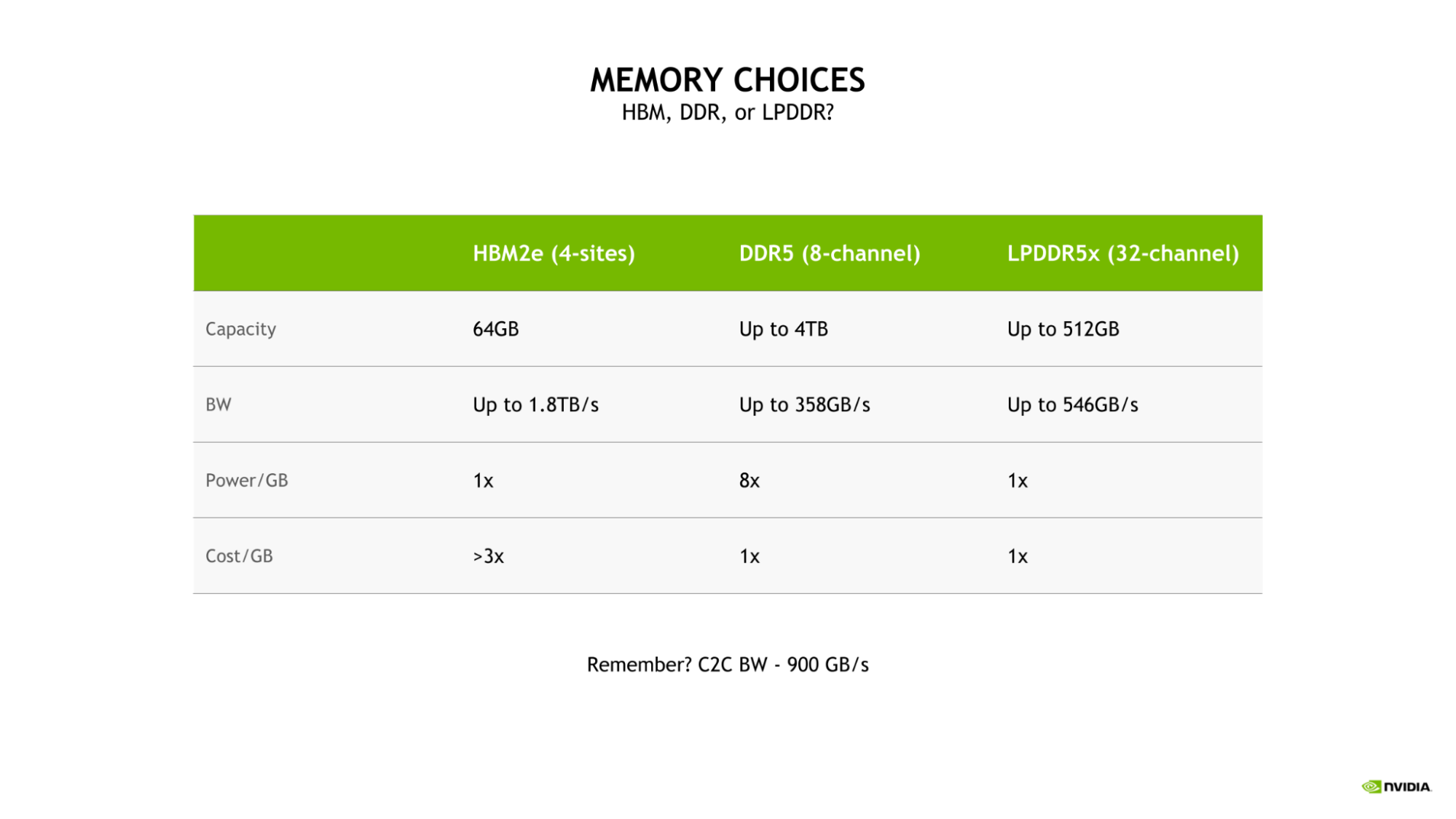
이처럼 LPDDR5X의 우수한 전력 효율 덕분에 총 전력 예산에서 여유 비용을 CPU 코어, GPU 스트리밍 멀티프로세서(SM) 같은 컴퓨팅 리소스에 추가로 투입할 수 있습니다.
NVIDIA Grace CPU I/O
Grace CPU는 오늘날 데이터 센터의 요건에 따라 고속 I/O를 보완할 수 있는 기능이 탑재되었습니다. Grace CPU SoC가 PCIe 연결 레인을 최대 68개까지, 그리고 PCIe Gen 5 x16 링크를 최대 4개까지 제공합니다. 또한 각 PCIe Gen 5 x16 링크가 최대 128GB/s의 양방향 대역폭을 제공하고, 추가 연결 시 PCIe Gen 5 x8 링크 2개로 이분하는 것도 가능합니다.
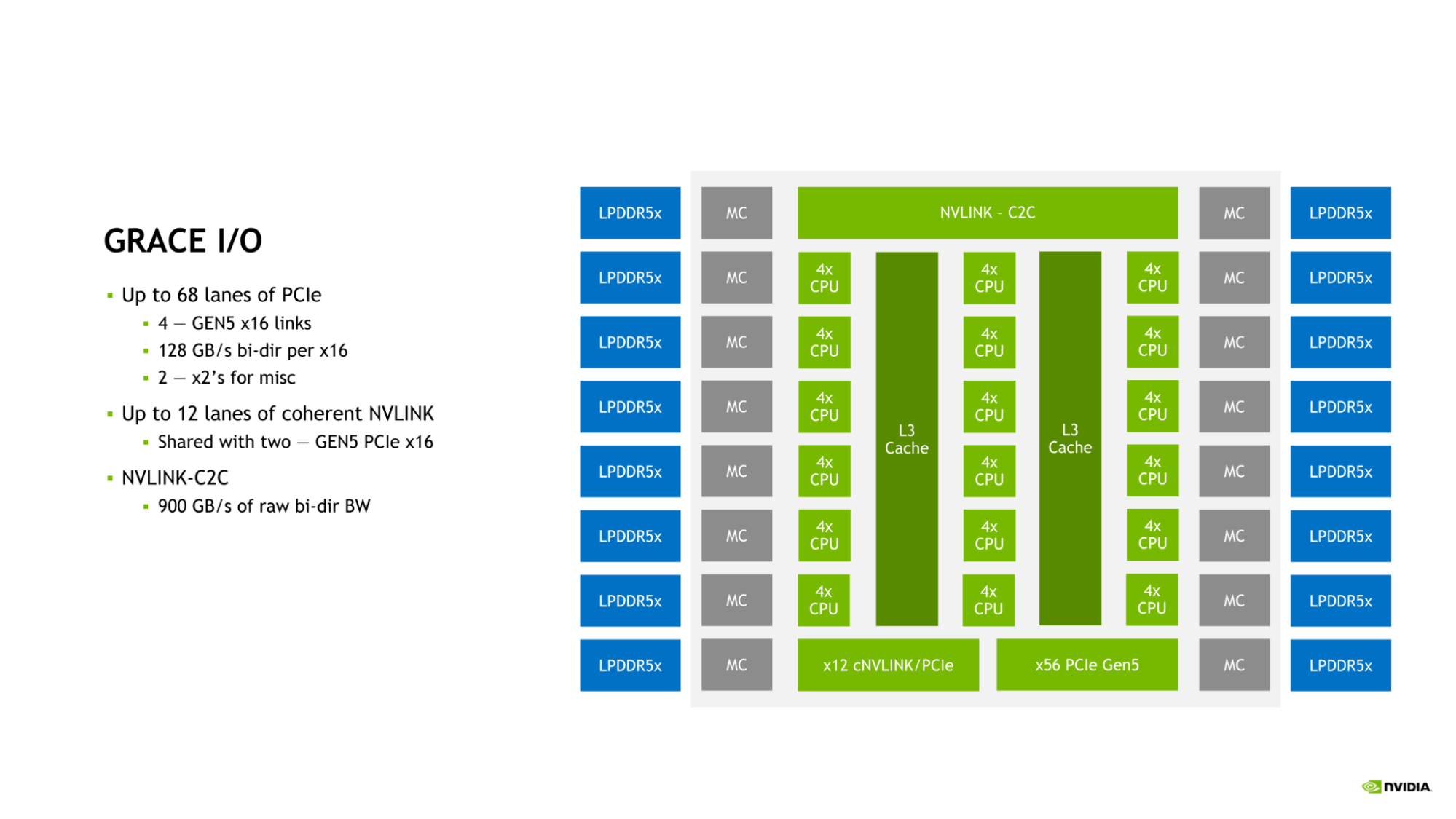
이러한 연결 외에 온다이 NVLink-C2C 링크를 사용해 Grace CPU를 다른 Grace CPU 또는 NVIDIA Hopper GPU에 연결하는 방법도 있습니다.
Grace CPU가 다양한 연결 옵션과 함께 오늘날 데이터 센터의 확장 성능에 필요한 대역폭을 충분히 제공할 수 있는 이유도 NVLink, NVLink-C2C, PCIe Gen 5가 이렇게 결합되어 있기 때문입니다.
NVIDIA Grace CPU 성능
NVIDIA Grace CPU는 단일 칩 구성과 Grace 슈퍼칩 구성에서 모두 우수한 컴퓨팅 성능을 발휘할 수 있도록 설계되어 SPECrate2017_int_base 스코어도 각각 370점과 740점으로 추산됩니다. 이처럼 반도체 이전(pre-silicon) 단계에서 추산한 점수는 GNU Compiler Collection(GCC)를 사용한 결과에 따른 것입니다.
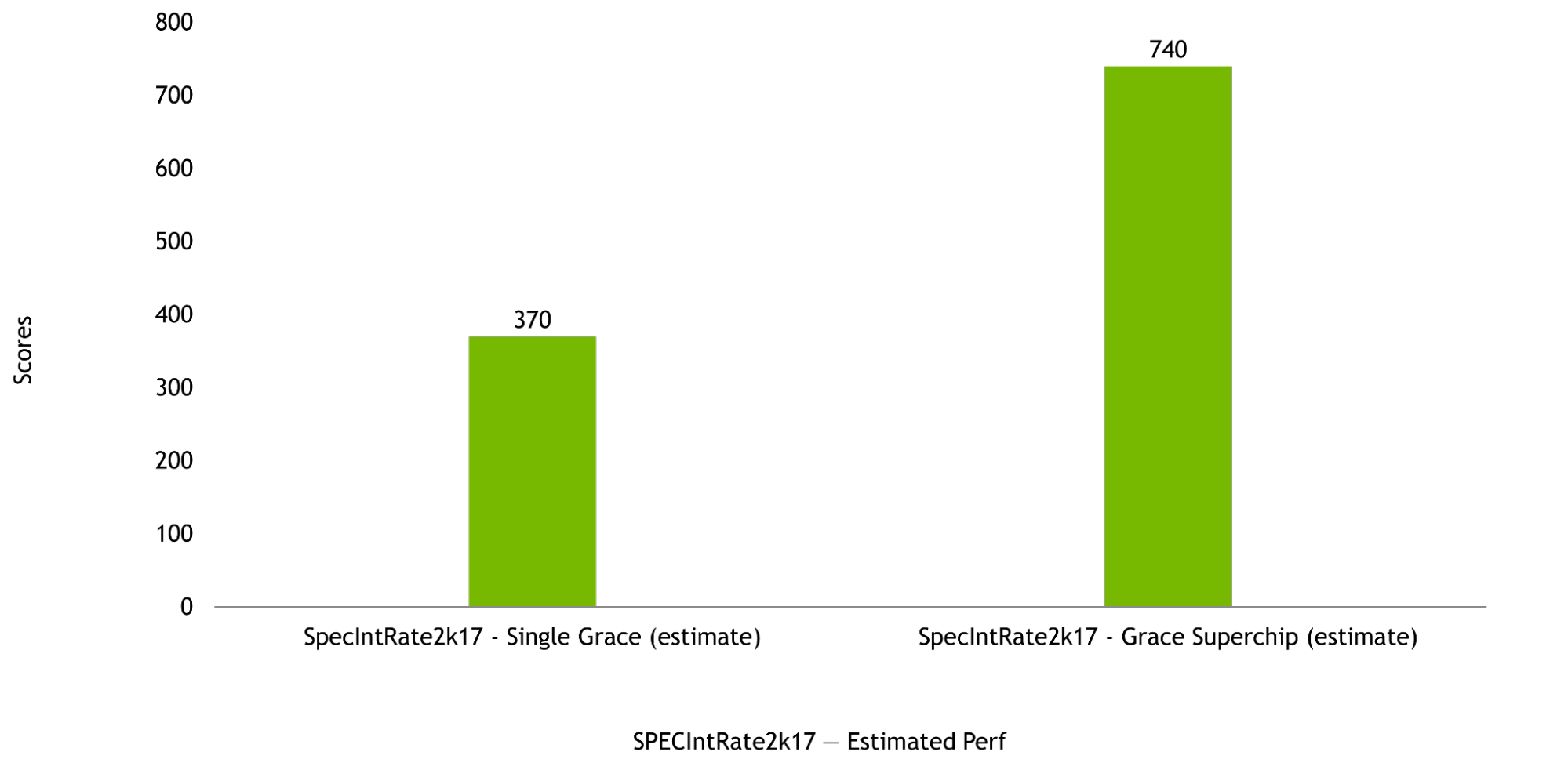
Grace CPU가 사용되는 워크로드에서는 메모리 대역폭이 무엇보다 중요합니다. Stream Benchmark 결과를 보면 단일 Grace CPU일 때 대역폭이 최대 536GB/s에 이르러 최대 이론 대역폭의 98%를 넘어설 것으로 예상됩니다.
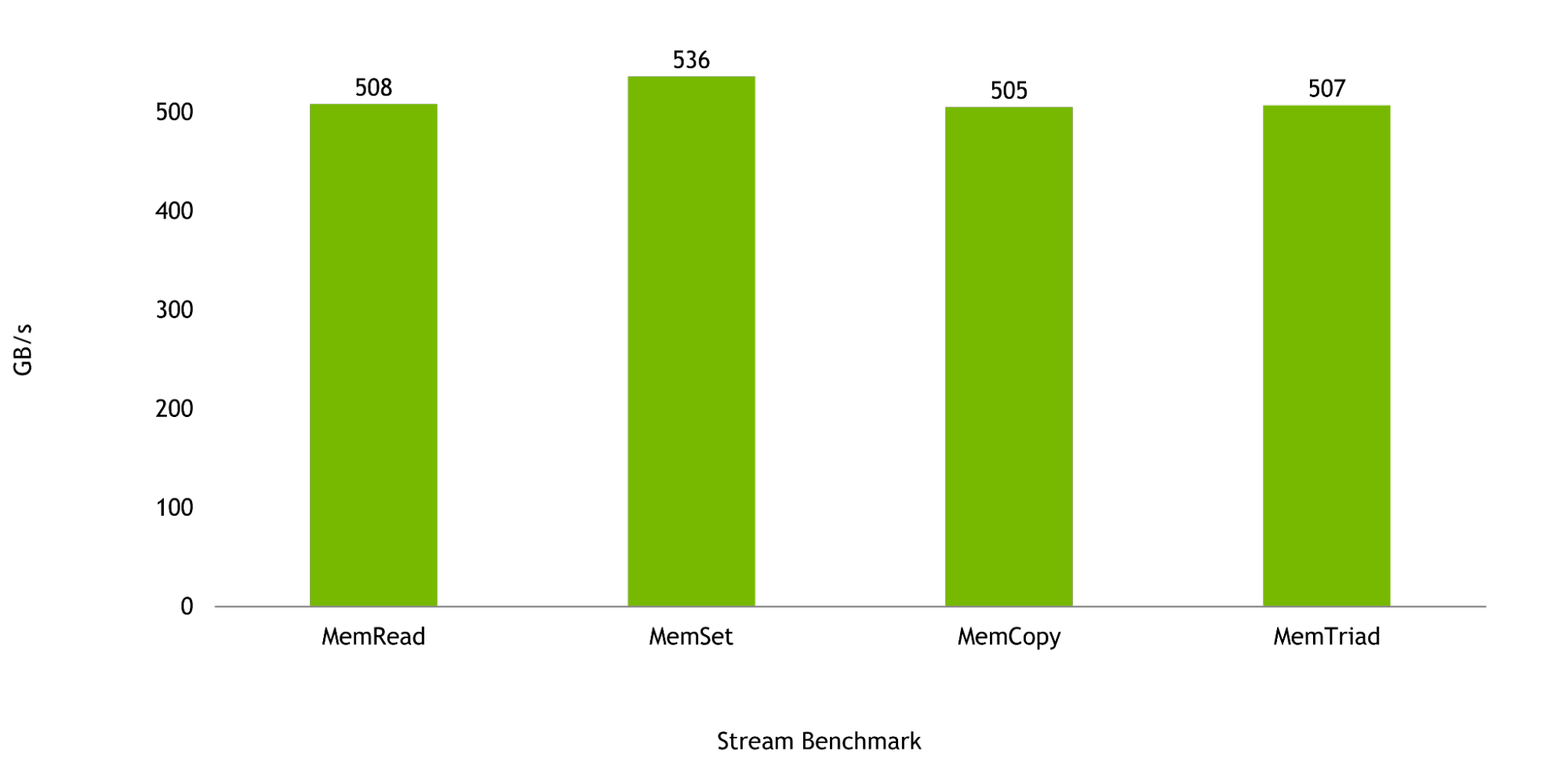
마지막으로 Grace Hopper 슈퍼칩의 성능을 극대화하려면 Hopper GPU와 Grace CPU 간 대역폭이 매우 중요합니다. GPU와 CPU 간 메모리 읽기 및 쓰기 속도는 각각 429GB/s와 407GB/s로 NVLink-C2C의 최대 이론 단방향 전송 속도의 95%와 90%를 넘어설 것으로 예상됩니다.
전체 읽기 및 쓰기 성능은 506GB/s로 단일 NVIDIA Grace CPU SoC에 사용할 수 있는 최대 이론 메모리 대역폭의 90%를 넘어설 것으로 기대됩니다.
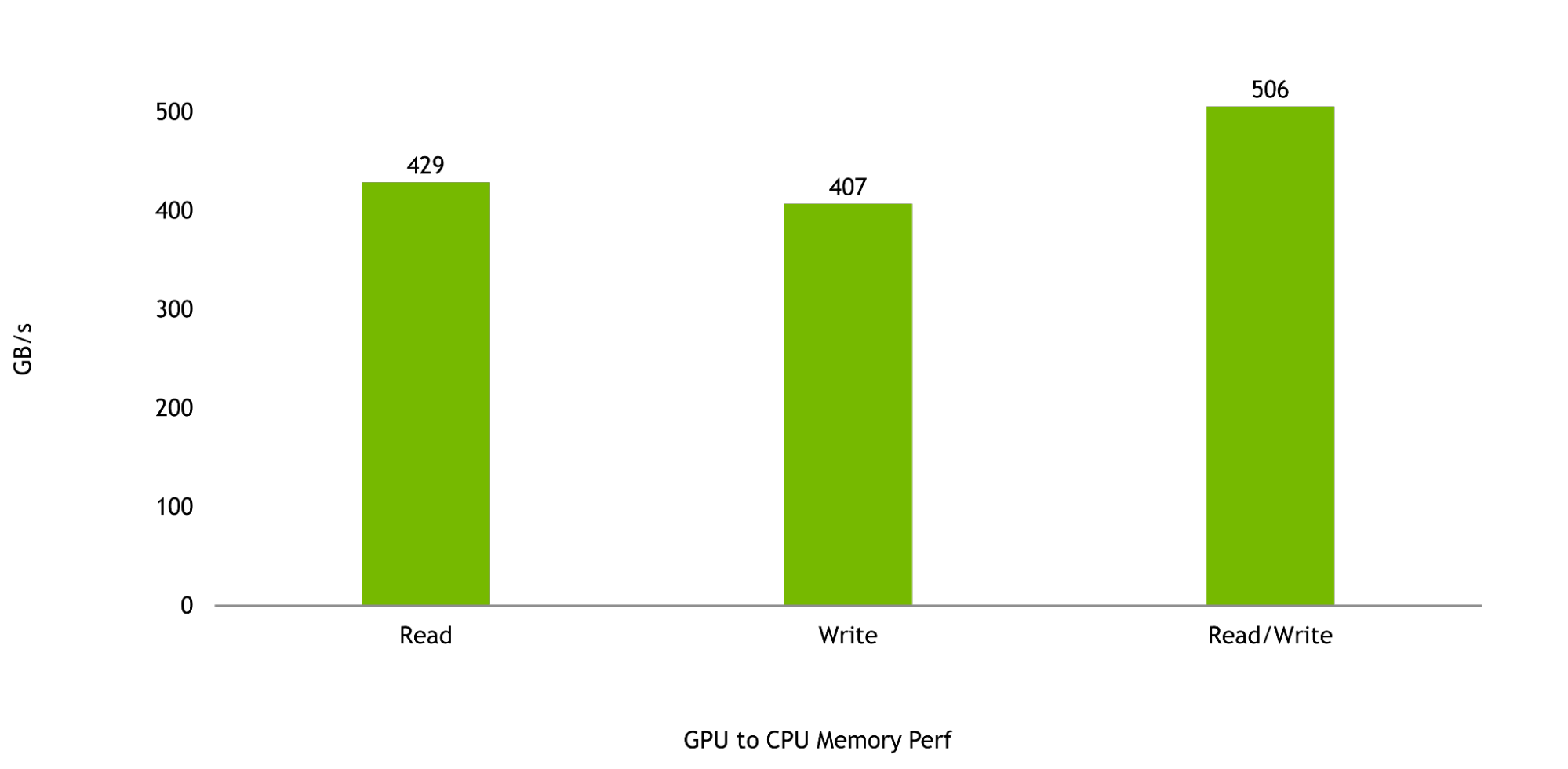
NVIDIA Grace CPU 슈퍼칩의 이점
NVIDIA Grace CPU 슈퍼칩은 코어 수 144개와 메모리 대역폭 1TB/s를 바탕으로 CPU 기반 고성능 컴퓨팅 애플리케이션에 탁월한 성능을 제공합니다. HPC 애플리케이션은 컴퓨팅 집약적이기 때문에 빠른 결과를 위해서는 가장 높은 성능의 코어와 가장 높은 메모리 대역폭, 그리고 적합한 코어당 메모리 용량이 필요합니다.
NVIDIA는 최고의 HPC, 슈퍼 컴퓨팅, 하이퍼스케일 및 클라우드 고객과 협력하여 Grace CPU 슈퍼칩을 설계하고 있습니다. Grace CPU 슈퍼칩과 Grace Hopper 슈퍼칩은 2023년 전반기에 출시될 예정입니다.
NVIDIA Grace Hopper 슈퍼칩과 NVIDIA Grace CPU 슈퍼칩에 대해 자세히 알고 싶다면 NVIDIA Grace CPU에서 확인할 수 있습니다.
이 블로그에 열거된 SDK의 대부분의 독점 액세스, 얼리 액세스, 기술 세션, 데모, 교육 과정, 리소스는 NVIDIA 개발자 프로그램 회원은 무료로 혜택을 받으실 수 있습니다. 지금 무료로 가입하여 NVIDIA의 기술 플랫폼에서 구축하는 데 필요한 도구와 교육에 액세스하시고 여러분의 성공을 가속화 하세요.