
모델이 커지고 더 많은 데이터로 학습되면서 기능이 늘어나고 활용도도 높아지고 있습니다. 이런 모델을 빠르게 훈련하려면 데이터센터 수준의 높은 성능이 필요합니다. GTC 2024에서 공개되고 현재 본격 생산 중인 NVIDIA Blackwell 플랫폼은 GPU, CPU, DPU, NVLink Switch 칩, InfiniBand Switch, Ethernet Switch 등 7가지 종류의 칩을 통합합니다. Blackwell 플랫폼은 GPU당 성능을 크게 향상시키고, 더 대규모 AI 클러스터를 구성할 수 있게 만들어 차세대 LLM 개발에 속도를 더할 것으로 기대됩니다.
AI 트레이닝 벤치마크 제품군인 MLPerf Training에서 NVIDIA는 프리뷰 부문에 Blackwell 플랫폼을 처음으로 사용한 결과를 발표했습니다. 결과는 모든 MLPerf Training 벤치마크에서 Hopper 기반 결과와 비교해 가속기당 성능이 크게 향상된 것을 보여줍니다. 주요 성과로는 GPT-3 사전 트레이닝에서 GPU당 성능이 2배, Llama 2 70B의 LoRA(Low-Rank Adaptation) 파인 튜닝에서 2.2배 향상된 점이 포함됩니다. NVIDIA는 모든 MLPerf Training 벤치마크에서 Blackwell 플랫폼을 활용한 결과를 제출하며 Hopper 대비 전반적으로 우수한 성능을 입증했습니다.
제출된 각 시스템에는 TDP(열 설계 전력) 1,000W로 작동하는 8개의 Blackwell GPU가 탑재되어 있으며, 5세대 NVLink와 최신 NVLink Switch를 통해 연결됩니다. 노드 간 연결은 NVIDIA ConnectX-7 SuperNIC과 NVIDIA Quantum-2 InfiniBand 스위치를 사용합니다. 앞으로 출시될 GB200 NVL72는 더 많은 컴퓨팅 성능, 확장된 NVLink 도메인, 더 높은 메모리 대역폭과 용량, 그리고 NVIDIA Grace CPU와의 긴밀한 통합을 특징으로 합니다. 이를 통해 HGX B200 대비 GPU당 성능이 훨씬 더 높아질 것으로 기대되며, ConnectX-8 SuperNIC과 새로운 Quantum-X800 Switch를 통해 효율적인 확장이 가능해질 전망입니다.
이 게시물에서는 이러한 놀라운 결과를 자세히 살펴봅니다.
Blackwell을 위한 소프트웨어 스택 강화
새로운 플랫폼 세대가 출시될 때마다 NVIDIA는 개발자가 고성능 워크로드를 달성할 수 있도록 하드웨어와 소프트웨어를 긴밀히 공동 설계합니다. Blackwell GPU 아키텍처는 Tensor 코어의 연산 처리량과 메모리 대역폭에서 획기적인 성능 향상을 이뤘습니다. NVIDIA 소프트웨어 스택도 이번 MLPerf Training 라운드에서 대폭 향상된 Blackwell의 기능을 최대한 활용할 수 있도록 여러 부분에서 개선되었습니다. 이 개선 사항에는 다음이 포함됩니다:
- 최적화된 GEMM, 컨볼루션 및 멀티 헤드 어텐션: Blackwell GPU 아키텍처의 더 빠르고 효율적인 텐서 코어를 효율적으로 활용하기 위해 새로운 커널이 개발되었습니다.
- 더 효율적인 컴퓨팅 및 통신 중첩: 아키텍처 및 소프트웨어 개선으로 멀티 GPU 실행 중 사용 가능한 GPU 리소스를 더 효율적으로 사용할 수 있습니다.
- 메모리 대역폭 활용도 향상: Hopper 아키텍처에 처음 도입된 텐서 메모리 가속기(TMA) 기능을 활용하는 새로운 소프트웨어가 cuDNN 라이브러리의 일부로 개발되어 정규화를 비롯한 여러 작업에서 HBM 대역폭 활용도가 향상되었습니다.
- 더 뛰어난 성능의 병렬 매핑: Blackwell GPU는 더 큰 HBM 용량을 도입하여 하드웨어 리소스를 보다 효율적으로 사용하는 언어 모델의 병렬 매핑을 가능하게 합니다.
Hopper의 성능을 더욱 향상시키기 위해 보다 유연한 타일링 옵션과 개선된 데이터 로컬리티를 지원하여 cuBLAS를 업그레이드했습니다. 최적화된 Blackwell 멀티헤드 어텐션 커널과 컨볼루션 커널은 cuDNN의 런타임 퓨전 엔진을 적극 활용했습니다. 이러한 최적화가 결합되면서 언어 모델에 최적화된 성능을 달성하는 데 NVIDIA Transformer 엔진 라이브러리가 핵심 역할을 했습니다.
Blackwell 아키텍처의 다양한 혁신, 앞서 언급한 최적화, 그리고 여기서 다 다루지 않은 소프트웨어 스택의 추가 개선 사항이 조화를 이루어 전반적으로 뛰어난 성능 향상에 기여했습니다.
Blackwell, LLM 사전 훈련에 큰 도약 실현
MLPerf Training 제품군에는 OpenAI가 개발한 GPT-3 모델을 기반으로 한 LLM 사전 훈련 벤치마크가 포함되어 있습니다. 이 벤치마크는 최첨단 파운데이션 모델의 훈련 성능을 평가하기 위한 테스트입니다. GPU당 성능 기준으로 이번 Blackwell의 결과는 네 번째 제출된 Hopper 대비 2배에 달하는 성능을 기록했습니다. 또한, NVIDIA Ampere 아키텍처 기반 HGX A100(MLCommons 검증 제외)과 비교했을 때 GPU당 성능이 약 12배 향상된 것으로 나타났습니다.
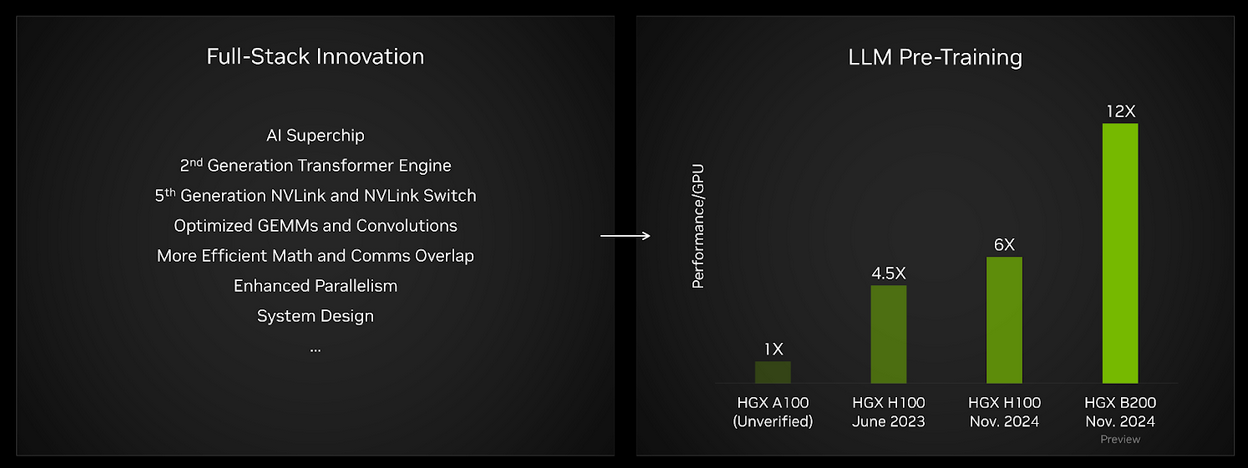
MLPerf 트레이닝, 비공개. HGX H100 2023년 6월, HGX H100 2024년 11월, HGX B200 결과는 MLCommons Association에서 검증했습니다. HGX A100 결과는 ML커먼스에 의해 검증되지 않았습니다. 항목 3.0-2069(512 H100 GPU), 4.1-0060(512 H100 GPU) 및 4.1-0082(64 Blackwell GPU)에서 얻은 검증된 결과이며 GPU별로 정규화되었습니다. 성능/GPU는 MLPerf 훈련의 주요 지표가 아닙니다. MLPerf 이름과 로고는 미국 및 기타 국가에서 MLCommons 협회의 등록 및 미등록 상표입니다. 모든 권리 보유. 무단 사용은 엄격히 금지됩니다. 자세한 내용은 www.mlcommons.org참조.
HGX B200에 탑재된 Blackwell GPU는 더 크고 대역폭이 높은 HBM3e 메모리를 사용해, GPU당 성능 저하 없이 64개의 GPU만으로 GPT-3 벤치마크를 실행할 수 있었습니다. 반면, HGX H100은 최적의 GPU당 성능을 내기 위해 256개의 GPU(32대의 HGX H100 서버)가 필요했습니다. Blackwell의 높은 GPU당 연산 처리량과 빠르고 대용량인 HBM3e 메모리 덕분에 GPT-3 175B 벤치마크를 적은 수의 GPU로도 높은 성능을 유지하며 실행할 수 있습니다.
Blackwell, LLM 파인 튜닝 속도 향상
Meta의 Llama 모델 제품군과 같은 대규모의 유능한 커뮤니티 LLM의 등장으로 기업은 사전 학습된 풍부한 성능의 모델을 이용할 수 있게 되었습니다. 이러한 모델은 파인 튜닝을 통해 특정 작업의 성능을 개선하도록 사용자 지정할 수 있습니다. MLPerf Training은 최근 매개변수 효율적 파인 튜닝(PEFT)의 일종인 로우랭크 적응(LoRA)을 적용하는 LLM 파인 튜닝 벤치마크를 Llama 2 70B 모델에 추가했습니다.
Meta의 Llama 모델 같은 대규모 커뮤니티 LLM이 등장하면서 기업은 이미 학습된 고성능 모델을 손쉽게 활용할 수 있게 되었습니다. 이러한 모델은 파인 튜닝을 통해 특정 업무에 최적화된 결과를 얻도록 사용자 설정이 가능합니다. MLPerf Training에서는 최근 LoRA(Low-Rank Adaptation) 방식의 파라미터 효율적 파인 튜닝(PEFT)을 활용하는 LLM 파인 튜닝 벤치마크를 Llama 2 70B 모델에 추가했습니다. Blackwell은 이런 파인 튜닝 작업을 더 빠르고 효율적으로 처리할 수 있도록 돕습니다.

항목 4.1-0080(프리뷰 카테고리)의 Blackwell GPU를 사용한 DGX B200 8-GPU 제출과 항목 4.1-0050(사용 가능 카테고리)의 8-GPU HGX H100 제출을 비교한 Llama 2 70B LoRA 미세 튜닝의 성능 비교 결과입니다. GPT-3 175B 비교는 항목 4.1-0057(사용 가능 카테고리)의 256 H100 GPU 제출물의 정규화된 GPU당 성능과 4.1-0082(프리뷰 카테고리)의 정규화된 GPU당 64 Blackwell GPU 제출물을 비교한 것입니다. 결과는 ML커먼스 협회에서 확인했습니다. MLPerf 이름 및 로고는 미국 및 기타 국가에서 MLCommons 협회의 등록 및 미등록 상표입니다. 모든 권리 보유. 무단 사용은 엄격히 금지됩니다. 자세한 내용은 www.mlcommons.org참조.
LLM 파인 튜닝 벤치마크에서 단일 HGX B200 서버는 HGX H100 서버에 비해 2.2배 더 뛰어난 성능을 제공합니다. 이로써 조직은 Hopper에 비해 Blackwell을 사용하여 LLM을 더 빠르게 맞춤화할 수 있으므로 배포 시간을 단축하고 궁극적으로 가치를 높일 수 있습니다.
모든 벤치마크에서 제출된 Blackwell 결과
NVIDIA는 모든 벤치마크에서 Blackwell을 사용한 결과를 제출했으며, 전반적으로 상당한 성능 향상을 보여주었습니다.
| 벤치마크 | Blackwell GPU당 성능 vs H100 성능 |
| LLM LoRA 파인 튜닝 | 2.2x |
| LLM 사전 훈련 | 2.0x |
| 그래프 신경망 | 2.0x |
| 텍스트 투 이미지 | 1.7x |
| 추천시스템 | 1.6x |
| 물체 감지 | 1.6x |
| 자연 언어 처리 | 1.4x |
MLPerf 교육 v4.1, 마감. 2024년 11월 13일에 다음 항목에서 검색된 결과: 4.1-0048, 4.1-0049, 4.1-0050, 4.1-0051, 4.1-0052, 4.1-0078, 4.1-0079, 4.1-0080, 4.1-0081, 4.1-0082. GPU당 정규화된 성능을 비교하여 계산된 속도 향상. GPU당 성능은 MLPerf 훈련의 주요 지표가 아닙니다. MLPerf 이름 및 로고는 미국 및 기타 국가에서 MLCommons 협회의 등록 및 미등록 상표입니다. 모든 권리 보유. 무단 사용은 엄격히 금지됩니다. 자세한 내용은 www.mlcommons.org참조.
계속해서 뛰어난 성능을 제공하는 Hopper
NVIDIA Hopper 아키텍처는 MLPerf Training v4.1에서도 가속기당 성능과 대규모 확장 모두에서 가장 뛰어난 성능을 지속적으로 보여주었습니다. 예를 들어, GPT-3 175B 벤치마크에서 Hopper의 가속기당 성능은 2023년 6월 발표된 MLPerf Training v3.0 결과에 비해 1.3배 향상되었습니다.
NVIDIA는 GPU당 처리 성능을 개선하는 데 그치지 않고, 확장 효율성을 크게 높여 11,616개의 H100 GPU를 활용한 GPT-3 175B 벤치마크 실행을 가능하게 했습니다. 이를 통해 전체 성능과 실행 규모 모두에서 여전히 벤치마크 기록을 유지하고 있습니다.
NVIDIA는 또한 HGX H200 플랫폼을 사용하여 결과를 제출했습니다. NVIDIA H200 텐서 코어 GPU는 NVIDIA H100 텐서 코어 GPU와 동일한 Hopper 아키텍처를 기반으로 제작됐으며, HBM3e 메모리를 탑재해 1.8배 더 많은 메모리 용량과 1.4배 더 많은 메모리 대역폭을 제공한다. Llama 2 70B 로우랭크 적응(LoRA) 벤치마크에서 H200을 사용한 NVIDIA 8-GPU 기록은 H100에 비해 약 16% 더 나은 성능을 제공했습니다.
핵심 사항
이번 MLPerf Training 결과는 NVIDIA Blackwell 플랫폼이 특히 LLM 사전 훈련과 파인 튜닝 작업에서 Hopper 플랫폼 대비 눈에 띄는 성능 향상을 보여준다는 점을 입증합니다. 한편, Hopper는 출시 이후 지속적인 소프트웨어 최적화를 통해 GPU당 성능과 대규모 확장성에서 여전히 우수한 성능을 유지하고 있습니다. 앞으로 있을 MLPerf Training에서는 더 큰 규모의 Blackwell 시스템과 함께 랙 스케일 GB200 NVL72 시스템을 사용한 결과도 발표할 계획입니다. Blackwell의 발전이 LLM 트레이닝에서 새로운 기준을 세울 것으로 기대됩니다.
관련 리소스
- GTC 세션: NVIDIA NeMo 및 AWS를 활용한 LLM 트레이닝 최적화
- GTC 세션: 클라우드 기반 LLM 트레이닝 클러스터의 해부학(CoreWeave 제공)
- GTC 세션 텍스트 생성을 위한 TensorRT-LLM을 사용한 LLM 최적화 및 확장(제공: CoreWave)
- NGC 컨테이너: NVIDIA MLPerf 추론
- NGC 컨테이너: NVIDIA MLPerf 추론
- NGC 컨테이너: Mixtral-8x7B-Instruct-v0.1