
행렬 곱셈과 어텐션 메커니즘은 현대 AI 워크로드의 연산적 기반입니다. NVIDIA cuDNN과 같은 라이브러리는 고도로 최적화된 구현을 제공하며, CUTLASS와 같은 프레임워크는 깊이 있는 커스터마이징 기능을 제공합니다. 하지만 많은 개발자와 연구자는 성능과 프로그래머블성을 모두 갖춘 중간 수준의 솔루션을 필요로 합니다.
오픈소스 Triton 컴파일러는 NVIDIA Blackwell 아키텍처에서 이러한 요구를 충족하며, Blackwell의 고급 기능을 직관적인 프로그래밍 모델을 통해 제공합니다.
NVIDIA와 OpenAI의 지속적인 협업 결과, Triton 컴파일러는 이제 NVIDIA Blackwell 아키텍처를 지원합니다. 이를 통해 개발자와 연구자는 Python 기반의 Triton 컴파일러를 활용하여 Blackwell 아키텍처의 최신 기능을 쉽게 사용할 수 있습니다.
NVIDIA Blackwell에서의 성능 향상
NVIDIA Blackwell 아키텍처는 순수 연산 성능과 구조적 혁신 모두에서 큰 개선을 제공합니다. NVIDIA와 OpenAI의 협업은 이러한 기능을 Triton의 컴파일러 인프라를 통해 투명하게 활용할 수 있도록 최적화하는 데 초점을 맞췄으며, 특히 다음 두 가지 주요 영역에서 성과를 보였습니다.
- 행렬 곱셈 (Matrix Multiplications), 특히 Flash Attention
- 새로운 정밀도(Precision) 형식 지원
행렬 곱셈 최적화
NVIDIA Blackwell 아키텍처는 처음부터 향상된 처리량과 에너지 효율성을 위해 설계된 새로운 Tensor Core를 도입했습니다.
Triton의 Matrix Multiply-Accumulate (MMA) 파이프라인 기술을 확장하여, NVIDIA Blackwell의 새로운 Tensor Core를 자동으로 활용할 수 있도록 했습니다. 이를 위해 메모리 접근 패턴을 면밀히 분석하고, 정교한 컴파일러 변환을 적용하여 연산과 데이터 이동이 최적으로 중첩(overlap)되도록 설계했습니다.
그 결과, FP8 및 FP16 GEMM 연산에서 뛰어난 성능을 즉시 제공하며, 이러한 최적화는 Triton의 tl.dot 기본 연산을 사용하는 모든 커널에 자동으로 적용됩니다. Triton은 라이브러리 구현과 비교하여 주요 사용 사례에서 거의 최적에 가까운 성능을 달성했습니다.
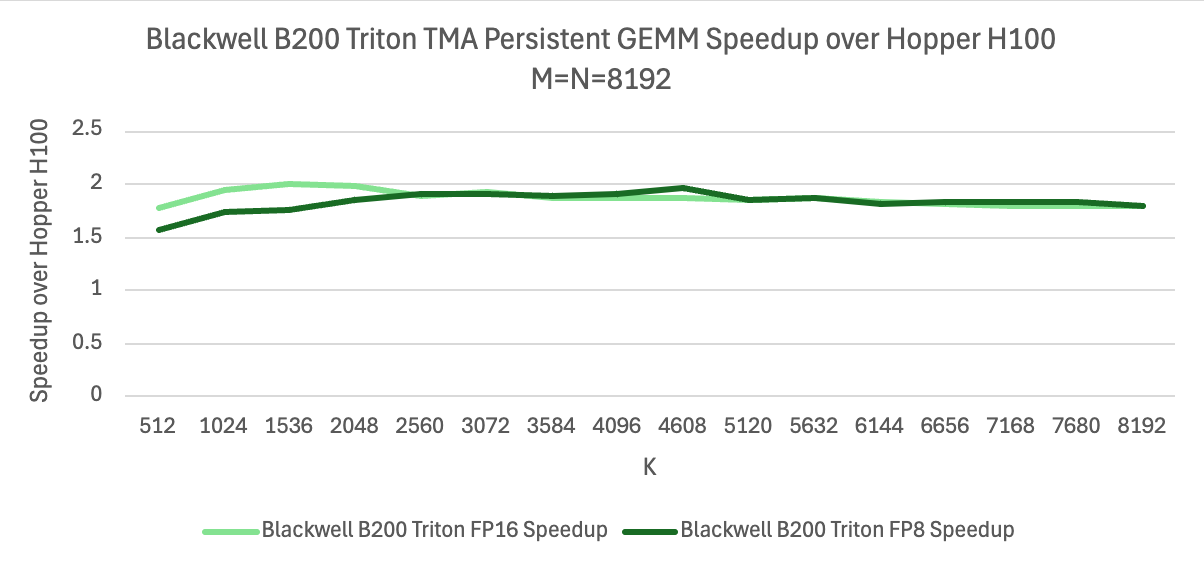
그림 1은 Triton 최적화가 NVIDIA Blackwell 아키텍처에서 FP16 및 FP8 성능을 어떻게 향상시키는지 보여줍니다. 이 분석은 일반적인 생성형 AI(Generative AI) 크기의 GEMM 커널에서 이루어졌으며, 해당 예제는 Triton 튜토리얼에서 제공됩니다.
Flash Attention 최적화
Flash Attention은 현대 Transformer 아키텍처에서 핵심적인 연산이며, NVIDIA Blackwell에서는 Triton을 활용해 최대 1.5배 빠른 속도(FP16 기준)를 달성했습니다.
현재 FP8 및 기타 정밀도에서 절대적인 성능 향상을 위한 추가 최적화가 진행 중이지만, 기존 제품에서도 NVIDIA Blackwell으로 즉시 전환할 수 있도록 지원하는 것이 이번 작업의 목표였습니다.
또한, 기존의 Triton 기반 Flash Attention 구현을 변경 없이 그대로 사용하면서 이러한 성능 향상을 “무료”로 제공한다는 점도 중요한 부분입니다.
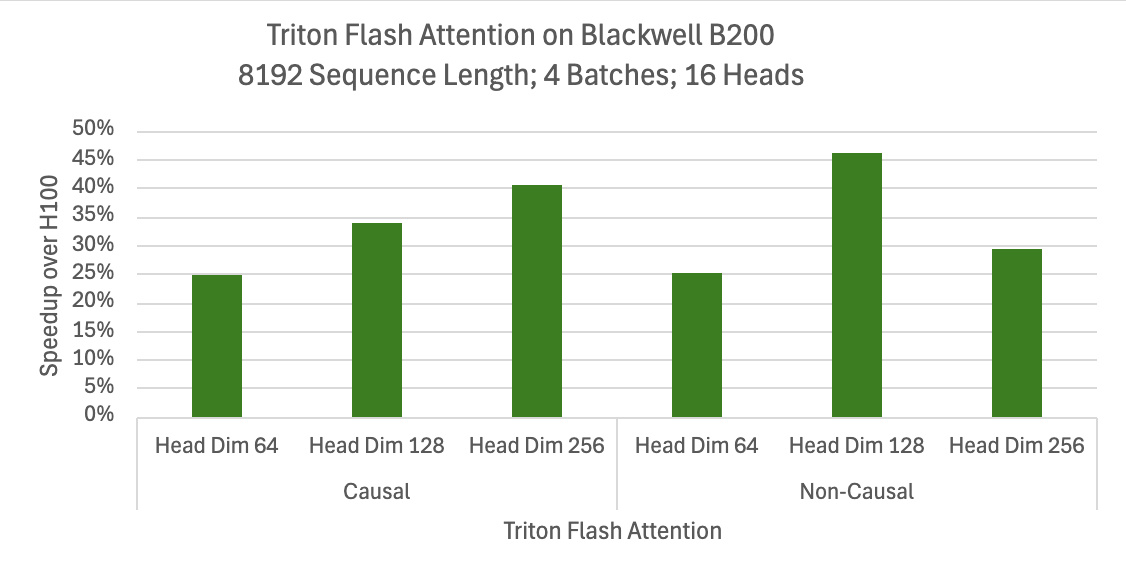
그림 2는 Flash Attention 커널을 포함한 복잡한 워크로드에서도 NVIDIA Blackwell 아키텍처가 Triton 컴파일러 최적화를 통해 얼마나 큰 성능 향상을 제공하는지 보여줍니다. 일부 최적화는 NVIDIA Hopper 아키텍처의 어텐션 성능도 향상시켰지만, 이 데이터에는 포함되지 않았습니다.
새로운 정밀도(Precision) 형식 지원
NVIDIA Blackwell은 혁신적인 블록 스케일 부동소수점(Block-scaled floating point) 형식을 도입했습니다. 이는 오픈 컴퓨팅 프로젝트(OCP)의 마이크로 스케일링 형식(microscaling formats)을 포함하며, Triton은 이제 이러한 기능을 NVIDIA Blackwell 하드웨어 가속을 위해 활용할 수 있도록 지원합니다.
이러한 새로운 형식은 기존의 비네이티브 블록 스케일링 기법보다 더 높은 평균 정밀도를 제공하면서도 성능을 향상시킵니다. 이는 현재 LLM 추론 프로젝트에서 자주 사용되는 방식보다 우수한 성능을 발휘합니다.
MXFP8 GEMM 연산은 기존 FP8 GEMM 연산과 유사한 뛰어난 성능을 제공하며, Tensor Core에서 직접 스케일링을 수행할 수 있도록 지원합니다.
MXFP4는 새로운 정밀도-성능 절충(trade-off) 지점을 제공하며, FP8 및 MXFP8 GEMM 연산 대비 2배 향상된 하드웨어 가속 성능을 제공합니다.
새로운 블록 스케일 부동소수점 지원에 대한 자세한 내용은 Triton의 최신 튜토리얼에서 확인할 수 있습니다.
향후 개선될 영역
MXFP4와 같은 서브바이트 데이터 형식의 레이아웃 및 패킹을 더욱 최적화할 필요가 있습니다. 커널 개발자와 프레임워크 통합을 더욱 원활하게 만들기 위해 커뮤니티와 협력해 개선할 예정입니다.
GEMM_K 값이 작은 경우, 모든 데이터 형식에서 행렬 곱셈 커널의 활용률이 상대적으로 낮습니다. 현재는 커널 내부에서 수동 서브 타일링(sub-tiling) 방식을 적용해 해결하고 있으며, 이는 GEMM 튜토리얼에서 예제로 제공됩니다. 향후에는 컴파일러에서 자동화된 워프(warp) 최적화를 적용하여 문제를 해결할 계획입니다.
더 많은 정보
Triton의 창시자인 Phillippe Tillet과 NVIDIA는 오는 3월 17일 NVIDIA GTC 컨퍼런스에서 NVIDIA Blackwell과 Triton을 활용한 최적화 및 성능 향상에 대한 심층적인 내용을 발표할 예정입니다.
GTC 2025에 온라인 또는 오프라인으로 참여하세요.
이번 릴리스는 Triton에서 NVIDIA Blackwell을 지원하기 위한 강력한 기반을 구축하는 첫걸음입니다. 여러분도 개발 과정에 기여할 수 있습니다.
- Triton의 전체 구현을 GitHub /triton-lang/triton 저장소에서 확인하세요.
- GPU MODE Discord 커뮤니티에 참여해 논의하세요.
- 다양한 예제 및 튜토리얼 컬렉션을 확인하세요.
문의사항이나 아이디어가 있나요?
NVIDIA 제품 관리자 Matthew Nicely를 GitHub에서 태그하여 의견을 공유하세요.