
어텐션 기반 아키텍처를 갖춘 트랜스포머는 강력한 성능, 병렬 처리, 키-값(KV) 캐시를 활용한 장기 기억 능력 덕분에 언어 모델(LM)로서 가장 널리 사용됩니다. 하지만 계산 비용이 이차적으로 증가하고 메모리 사용량이 많아 효율성이 떨어지는 문제가 있습니다. 반면, Mamba 및 Mamba-2와 같은 상태 공간 모델(SSM)은 연속적인 복잡성을 줄이고 하드웨어 최적화에 적합하지만, 기억회상(memory recall) 작업에서 한계를 보이며 일반적인 벤치마크 성능에 영향을 미칩니다.
NVIDIA 연구원들은 최근 효율성과 성능 향상을 모두 달성하기 위해 트랜스포머 어텐션 메커니즘을 SSM과 통합하는 하이브리드 헤드 병렬 아키텍처를 특징으로 하는 소형 언어 모델(SLM) 제품군인 Hymba 를 제안했습니다. Hymba에서 어텐션 헤드는 고해상도 기억을 제공하고, SSM 헤드는 효율적인 문맥 요약이 가능합니다.
Hymba의 새로운 아키텍처는 몇 가지 인사이트를 보여줍니다:
- 어텐션의 오버헤드: 어텐션 계산의 50% 이상을 비용이 적게 드는 SSM 계산으로 대체할 수 있습니다.
- 로컬 어텐션 우위: SSM 헤드가 요약한 글로벌 정보 덕분에 일반 및 회상 집약적인 작업의 성능 저하 없이 대부분의 글로벌 어텐션을 로컬 어텐션으로 대체할 수 있습니다.
- KV 캐시 중복성: 키-값 캐시는 헤드와 레이어 간에 상관관계가 높기 때문에 헤드(그룹 쿼리 어텐션)와 레이어(크로스 레이어 KV 캐시 공유) 간에 공유할 수 있습니다.
- 소프트맥스 어텐션 제한: 어텐션 메커니즘은 하나로 합산하도록 제한되어 희소성과 유연성이 제한됩니다. 저희는 프롬프트에 추가되는 학습 가능한 메타토큰을 도입하여 중요한 정보를 저장하고 어텐션 메커니즘과 관련된 ‘강제 참석’ 부담을 완화합니다.
이 게시물은 Hymba 1.5B가 비슷한 크기의 최신 오픈 소스 모델인 Llama 3.2 1B, OpenELM 1B, Phi 1.5, SmolLM2 1.7B, Danube2 1.8B, Qwen2.5 1.5B에 비해 유리하게 작동한다는 것을 보여줍니다. 비슷한 크기의 Transformer 모델과 비교했을 때 Hymba는 더 높은 처리량을 달성하고 캐시 저장에 필요한 메모리도 10배 더 적습니다.
Hymba 1.5B는 Hugging Face 컬렉션과 GitHub에서 출시되었습니다.
Hymba 1.5B 성능
그림 1은 평균 작업 정확도, 시퀀스 길이 대비 캐시 크기(MB), 처리량(틱/초) 측면에서 Hymba 1.5B와 하위 2B 모델(Llama 3.2 1B, OpenELM 1B, Phi 1.5, SmolLM2 1.7B, Danube2 1.8B, Qwen2.5 1.5B)을 비교한 결과입니다.
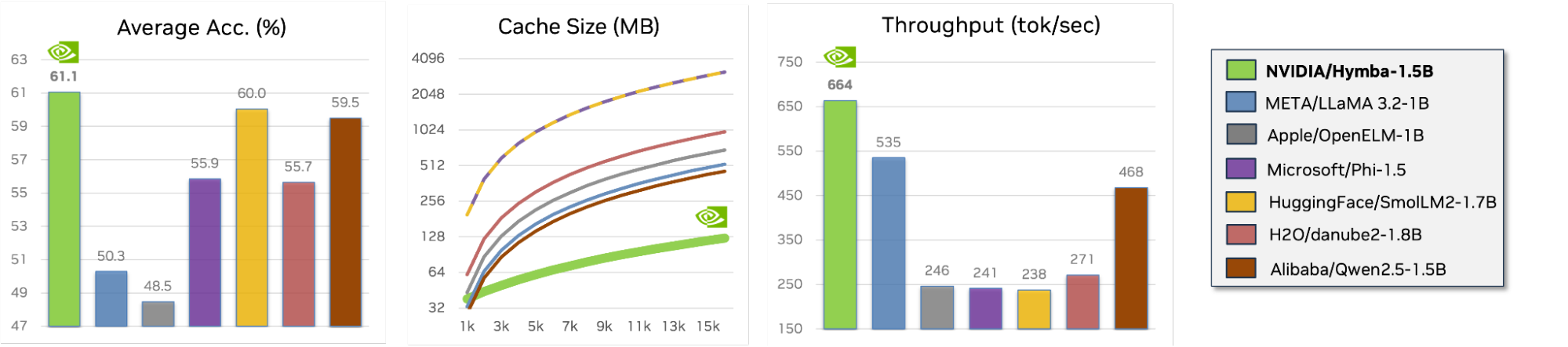
이 실험에서는 MMLU, ARC-C, ARC-E, PIQA, Hellaswag, Winogrande, SQuAD-C를 대상으로 작업을 수행했습니다. 처리량은 PyTorch를 사용하여 시퀀스 길이가 8K, 배치 크기가 128인 NVIDIA A100 GPU에서 측정되었습니다. 처리량 측정 중 메모리 부족(OOM) 문제가 발생한 모델의 경우, OOM이 해결될 때까지 배치 크기를 절반으로 줄여 OOM 없이 달성 가능한 최대 처리량을 측정했습니다.
Hymba 모델 설계
Mamba와 같은 SSM은 변압기의 이차적 복잡성과 대규모 추론 시간 KV 캐시 문제를 해결하기 위해 도입되었습니다. 그러나 저해상도 메모리로 인해 SSM은 기억 회상과 성능에 어려움을 겪습니다. 이러한 한계를 극복하기 위해 효율적이고 고성능의 소형 LM을 개발하기 위한 로드맵을 표 1에 제시합니다.
| 구성 | 상식적 추론 (%) ↑ | 회상 (%) ↑ | 처리량(토큰/초) ↑ | 캐시 크기(MB) ↓ | 설계 이유 |
| 300M 모델 크기와 100B 학습 토큰에 대한 소거 | |||||
| 트랜스포머(Llama) | 44.08 | 39.98 | 721.1 | 414.7 | 정확한 회상 성능, 비효율적인 처리 |
| State-space 모델(Mamba) | 42.98 | 19.23 | 4720.8 | 1.9 | 효율적이지만 회상 성능이 부정확 |
| A. + 어텐션 헤드(순차적) | 44.07 | 45.16 | 776.3 | 156.3 | 회상 성능 향상 |
| B. + 멀티 헤드(병렬) | 45.19 | 49.90 | 876.7 | 148.2 | 두 모듈의 균형 개선 |
| C. + 로컬/글로벌 어텐션 | 44.56 | 48.79 | 2399.7 | 41.2 | 계산 및 캐시 효율 향상 |
| D. + KV 캐시 공유 | 45.16 | 48.04 | 2756.5 | 39.4 | 캐시 효율성 |
| E. + 메타 토큰 | 45.59 | 51.79 | 2695.8 | 40.0 | 학습된 메모리 초기화 |
| 1.5B 모델 크기와 1.5T 학습 토큰으로 확장 | |||||
| F. + 크기/데이터 | 60.56 | 64.15 | 664.1 | 78.6 | 작업 성능 대폭 향상 |
| G. + 컨텍스트 길이 확장(2K→8K) | 60.64 | 68.79 | 664.1 | 78.6 | 멀티샷 및 회상 작업 성능 개선 |
융합된 하이브리드 모듈
하이브리드 헤드 모듈 내에서 어텐션과 SSM 헤드를 병렬로 융합하는 것이 순차적 스태킹보다 성능이 우수하다는 연구 결과가 발표되었습니다. Hymba는 하이브리드 헤드 모듈 내에서 어텐션 헤드와 SSM 헤드를 병렬로 융합하여 두 헤드가 동일한 정보를 동시에 처리할 수 있도록 합니다. 이 아키텍처는 추론과 회상 정확도를 향상시킵니다.

효율성 및 KV 캐시 최적화
어텐션 헤드는 작업 성능을 향상시키지만, KV 캐시 요구 사항을 증가시키고 처리량을 감소시킵니다. 이를 완화하기 위해 Hymba는 로컬 어텐션과 글로벌 어텐션을 결합하고 크로스 레이어 KV 캐시 공유를 사용하여 하이브리드 헤드 모듈을 최적화합니다. 이를 통해 성능 저하 없이 처리량을 3배 향상시키고 캐시를 거의 4배까지 줄입니다.
메타 토큰
입력에 사전 학습된 128개의 임베딩 세트가 추가되어 관련 정보에 대한 집중력을 높이기 위해 학습된 캐시 초기화 기능을 수행합니다. 이 토큰은 두 가지 용도로 사용됩니다:
- 백스톱 토큰으로 작용하여 어텐션을 효과적으로 재분배함으로써 어텐션 유출을 완화합니다.
- 압축된 세계 지식 캡슐화

모델 분석
이 섹션에서는 동일한 훈련 설정 하에서 서로 다른 아키텍처에 대한 동등 조건에서의 비교를 제시합니다. 그런 다음 사전 학습된 다양한 모델에서 SSM과 어텐션의 어텐션 맵을 시각화합니다. 마지막으로, 가지치기를 통해 Hymba에 대한 헤드 중요도 분석을 수행합니다. 이 섹션의 모든 분석은 Hymba의 디자인 선택이 효과적인 방법과 이유를 설명하는 데 도움이 됩니다.
동등한 조건에서의 비교 (Apples-to-apples comparison)
우리는 Hymba, 순수 Mamba2, FFN이 포함된 Mamba2, Llama3 스타일, Samba 스타일(Mamba-FFN-Attn-FFN) 아키텍처를 동등한 조건에서 비교했습니다. 모든 모델은 동일한 학습 레시피를 사용하여 SmolLM-Corpus에서 100억 개의 토큰으로 처음부터 학습되었으며, 모델 파라미터 수는 10억 개로 통일했습니다.
모든 결과는 Hugging Face 모델에서 lm-evaluation-harness를 사용하여 제로샷 설정으로 평가되었습니다. Hymba는 상식적 추론, 질문 응답, 그리고 회상 중심 작업에서 가장 우수한 성능을 보여주었습니다.
표 2는 언어 모델링 및 회상 중심 작업과 상식적 추론 작업에서 다양한 모델 아키텍처를 비교하며, Hymba는 모든 지표에서 강력한 성능을 보여줍니다. Hymba는 언어 작업에서 가장 낮은 퍼플렉서티를 기록했으며(Wiki의 경우 18.62, LMB의 경우 10.38), 회상 중심 작업에서도 견고한 결과를 나타냈습니다. 특히 SWDE에서 54.29, SQuAD-C에서 44.71을 기록하며, 이 범주에서 가장 높은 평균 점수(49.50)를 달성했습니다.
| 모델 | 언어 (PPL) ↓ | 회상 중심 작업 (%) ↑ | 상식적 추론 (%) ↑ |
| Mamba2 | 15.88 | 43.34 | 52.52 |
| Mamba2 w/ FFN | 17.43 | 28.92 | 51.14 |
| Llama3 | 16.19 | 47.33 | 52.82 |
| Samba | 16.28 | 36.17 | 52.83 |
| Hymba | 14.5 | 49.5 | 54.57 |
상식 추론과 질의응답에서 Hymba는 SIQA(31.76)와 TruthfulQA(31.64) 같은 대부분의 작업에서 다른 모델들을 능가하며 평균 점수 54.57을 기록했습니다. 이는 Llama3와 Mamba2를 약간 상회하는 수준입니다. 전반적으로 Hymba는 다양한 범주에서 효율성과 작업 성능 모두에서 뛰어난 균형 잡힌 모델로 두각을 나타냅니다.
어텐션 맵 시각화
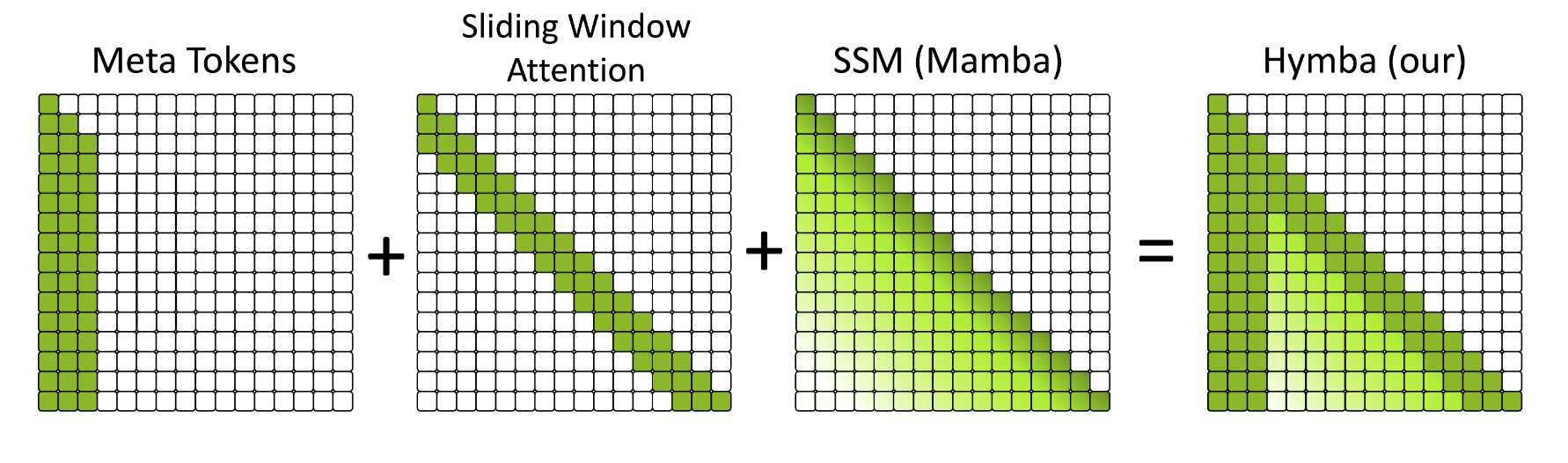
Hymba의 어텐션 맵 요소는 크게 네 가지로 분류됩니다:
- Meta: 모든 실제 토큰이 메타 토큰에 할당하는 어텐션 점수로, 모델이 메타 토큰에 얼마나 집중하는지를 나타냅니다. 어텐션 맵의 초기 열(예: Hymba는 첫 128열)에 위치합니다.
- BOS (Beginning-of-Sequence): 모든 실제 토큰이 시퀀스 시작 토큰에 할당하는 어텐션 점수로, 메타 토큰 바로 다음 열에 위치합니다.
- Self: 실제 토큰이 자기 자신에 할당하는 어텐션 점수로, 맵의 대각선 라인에 나타납니다.
- Cross: 다른 실제 토큰에 할당하는 어텐션 점수로, 맵의 비대각선 영역에 위치합니다.
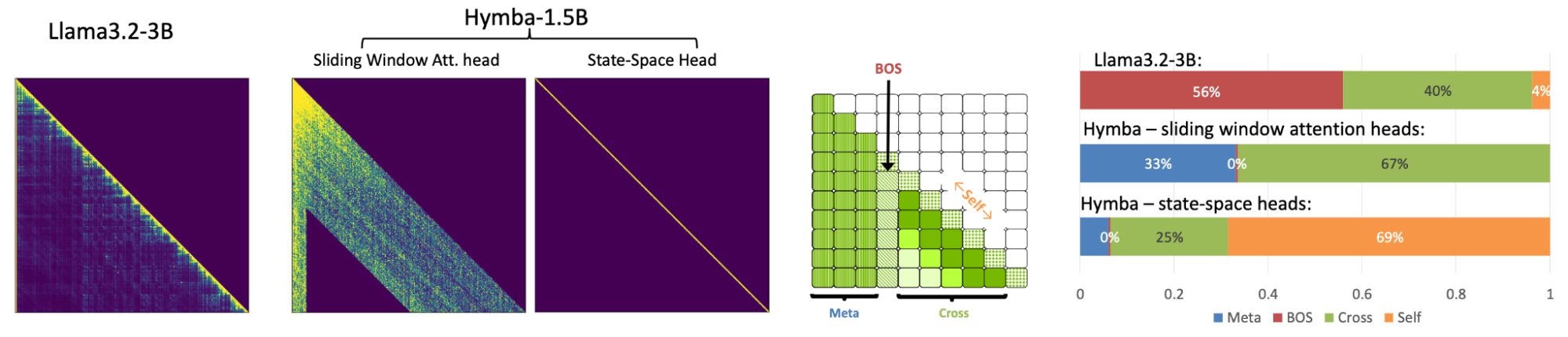
Hymba의 어텐션 패턴은 기본 Transformer와 크게 다릅니다. 기본 Transformer에서는 어텐션 점수가 BOS에 더 집중되는 경향이 있으며, 이는 Attention Sink 연구 결과와 일치합니다. 또한 기본 Transformer는 Self 어텐션 점수 비율이 더 높습니다. 반면 Hymba는 메타 토큰, 어텐션 헤드, SSM 헤드가 상호 보완적으로 작동하여 다양한 유형의 토큰에 대한 어텐션 점수가 더 균형 있게 분배됩니다.
특히, 메타 토큰은 BOS에서 어텐션 점수를 분산시켜 모델이 실제 토큰에 더 집중할 수 있게 합니다. SSM 헤드는 글로벌 컨텍스트를 요약하여 현재 토큰(Self 어텐션 점수)에 더 초점을 맞춥니다. 반면, 어텐션 헤드는 Self와 BOS 토큰에는 덜 집중하고, 다른 토큰(Cross 어텐션 점수)에 더 많은 관심을 둡니다. 이는 Hymba의 하이브리드 헤드 설계가 다양한 토큰 유형 간의 어텐션 분배를 효과적으로 균형화하고, 성능을 향상시킬 가능성이 있음을 시사합니다.
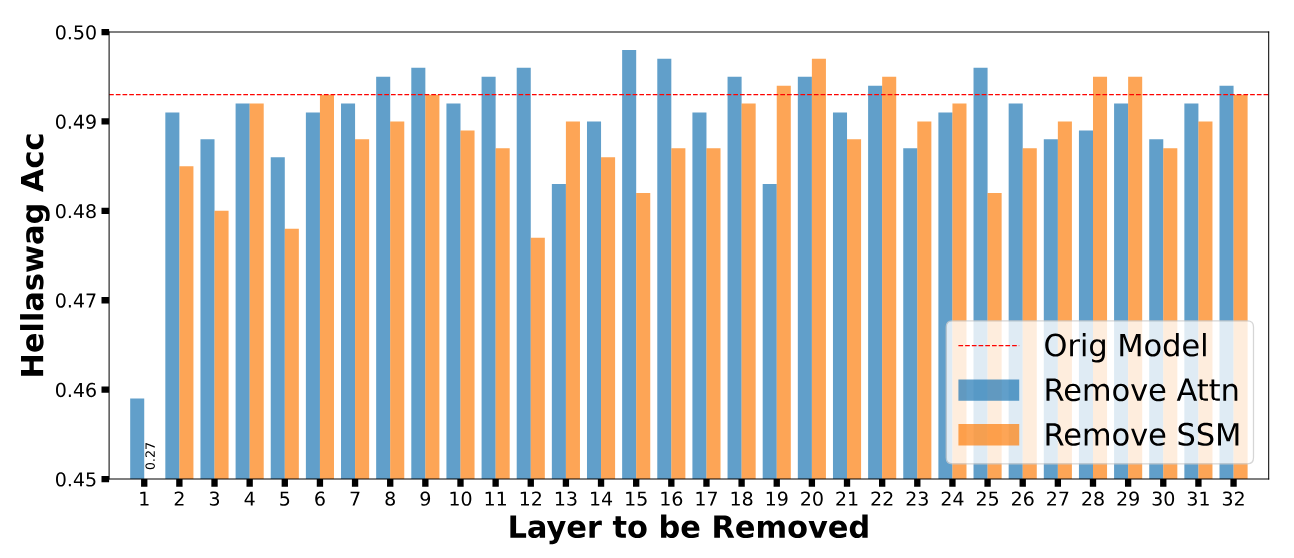
헤드 중요도 분석
우리는 각 레이어에서 어텐션과 SSM(Stepwise Sequential Memory) 헤드의 상대적 중요도를 분석하기 위해, 해당 헤드를 제거한 후 최종 정확도를 측정했습니다. 이 분석을 통해 다음과 같은 결과를 도출했습니다:
- 같은 레이어 내 어텐션/SSM 헤드의 상대적 중요도는 입력에 따라 다르며, 과제(task)에 따라 변동한다. 이는 다양한 입력을 처리할 때 두 헤드가 서로 다른 역할을 수행할 수 있음을 시사합니다.
- 첫 번째 레이어의 SSM 헤드는 언어 모델링에서 매우 중요한 역할을 한다. 이를 제거하면 정확도가 무작위 추측(random guess) 수준으로 크게 하락합니다.
- 일반적으로, 하나의 어텐션/SSM 헤드를 제거하면 Hellaswag 데이터셋에서 각각 평균적으로 0.24%/1.1%의 정확도 감소를 초래한다. 이는 SSM 헤드가 어텐션 헤드보다 더 높은 중요도를 갖는 경향이 있음을 보여줍니다.
모델 아키텍처 및 학습 최적화 방법
이 섹션에서는 Hymba 1.5B Base와 Hymba 1.5B Instruct 모델의 주요 아키텍처 설계와 학습 방법론을 다룹니다.
모델 아키텍처
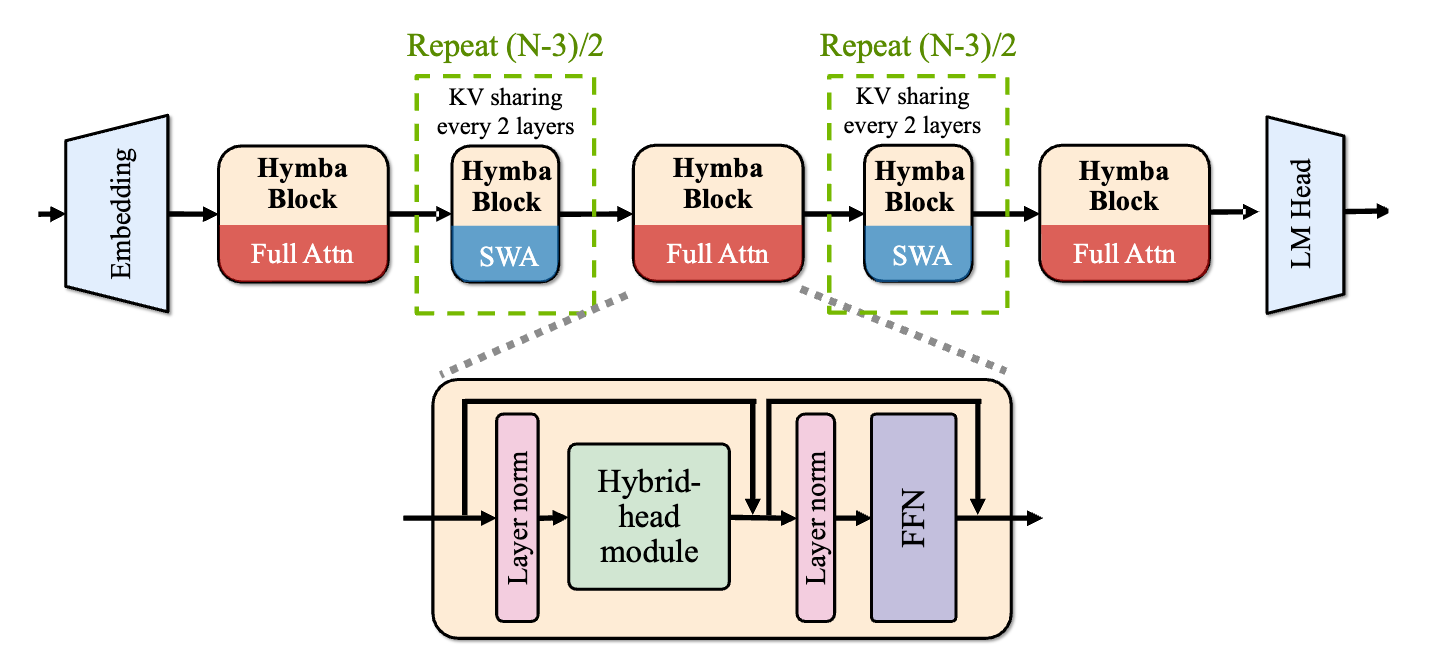
- 하이브리드 아키텍처: 하이브리드 아키텍처에서는 Mamba가 요약 작업에 탁월하며 일반적으로 현재 토큰에 더 초점을 맞추는 반면, 어텐션은 더 정밀하게 작동하며 스냅샷 메모리처럼 동작합니다. 이 두 가지를 병렬로 결합하면 각 방식의 이점을 병합할 수 있지만, 표준적인 순차적 결합 방식은 이러한 이점을 충분히 활용하지 못합니다. SSM(Structured State Space Models)과 어텐션 헤드 간의 매개변수 비율은 5:1로 설정되었습니다.
- 슬라이딩 윈도우 어텐션: 첫 번째, 마지막, 그리고 중간 레이어를 포함한 3개의 레이어에서는 전체 어텐션 헤드가 유지되며, 나머지 90%의 레이어에서는 슬라이딩 윈도우 어텐션 헤드가 사용됩니다.
- 크로스 레이어 KV 캐시 공유: 연속된 두 개의 어텐션 레이어 사이에서 KV 캐시 공유가 구현되었습니다. 이 방식은 GQA(Generalized Query Attention) KV 캐시를 어텐션 헤드 간에 공유하는 것 외에도 추가적으로 적용됩니다.
- 메타 토큰: 총 128개의 메타 토큰은 비지도 학습으로 학습되며, 거대 언어 모델(LLM)에서 발생할 수 있는 엔트로피 붕괴(entropy collapse) 문제를 방지합니다. 또한 어텐션 싱크(Attention sink) 현상을 완화하고, 이 메타 토큰은 일반적인 지식을 저장하는 역할을 합니다.
학습 최적화 방법
- 사전학습: 두 단계로 이루어진 기반 모델 학습 방식을 채택하였습니다. 첫 번째 단계에서는 큰 학습률을 일정하게 유지하면서 비교적 필터링되지 않은 대규모 코퍼스 데이터를 사용하고, 이후 고품질 데이터를 사용하여 학습률을 1e-5로 낮추는 방식의 연속적인 학습률 감소가 수행되었습니다. 이 접근법은 첫 번째 단계를 지속적으로 학습하거나 중단 후 재개할 수 있는 유연성을 제공합니다.
- 명령어 세부 튜닝: Instruct 모델 튜닝은 세 단계로 진행됩니다. 첫 번째 단계인 SFT-1에서는 모델에 강력한 추론 능력을 제공하며, 코드, 수학, 함수 호출, 롤플레이, 그리고 기타 특정 작업 데이터를 학습한다. 두 번째 단계인 SFT-2는 모델이 인간의 명령을 따르는 능력을 학습하도록 돕습니다.

성능 및 효율성 평가
1.5T의 토큰만 사전 학습하는 Hymba 1.5B 모델은 모든 소형 LM 중에서 가장 우수한 성능을 보이며, 모든 트랜스포머 기반 LM보다 더 나은 처리량과 캐시 효율성을 달성합니다.
예를 들어, 13배 더 많은 토큰으로 사전 훈련된 가장 강력한 기준선인 Qwen2.5와 벤치마킹했을 때 Hymba 1.5B는 평균 정확도 1.55% 향상, 처리량 1.41배, 캐시 효율성 2.90배를 달성했습니다. 2T 미만의 토큰으로 훈련된 가장 강력한 소형 LM인 h2o-danube2와 비교했을 때, 저희 방법은 평균 정확도 5.41% 향상, 처리량 2.45배, 캐시 효율성 6.23배를 달성합니다.
| 모델 | # 매개변수 | 기차 토큰 | 토큰/s | 캐시(MB) | MMLU 5-shot | ARC-E 0-shot | ARC-C 0-shot | PIQA 0-shot | Wino. 0-shot | Hella. 0-shot | SQuAD-C 1-shot | 평균 |
| Open ELM-1 | 1.1B | 1.5T | 246 | 346 | 27.06 | 62.37 | 19.54 | 74.76 | 61.8 | 48.37 | 45.38 | 48.57 |
| Rene v0.1 | 1.3B | 1.5T | 800 | 113 | 32.94 | 67.05 | 31.06 | 76.49 | 62.75 | 51.16 | 48.36 | 52.83 |
| Phi 1.5 | 1.3B | 0.15T | 241 | 1573 | 42.56 | 76.18 | 44.71 | 76.56 | 72.85 | 48 | 30.09 | 55.85 |
| Smol LM | 1.7B | 1T | 238 | 1573 | 27.06 | 76.47 | 43.43 | 75.79 | 60.93 | 49.58 | 45.81 | 54.15 |
| Cosmo | 1.8B | .2T | 244 | 1573 | 26.1 | 62.42 | 32.94 | 71.76 | 55.8 | 42.9 | 38.51 | 47.2 |
| h20 danube2 | 1.8B | 2T | 271 | 492 | 40.05 | 70.66 | 33.19 | 76.01 | 66.93 | 53.7 | 49.03 | 55.65 |
| Llama3.2 1B | 1.2B | 9T | 535 | 262 | 32.12 | 65.53 | 31.39 | 74.43 | 60.69 | 47.72 | 40.18 | 50.29 |
| Qwen 2.5 | 1.5B | 18T | 469 | 229 | 60.92 | 75.51 | 41.21 | 75.79 | 63.38 | 50.2 | 49.53 | 59.51 |
| AMD OLMo | 1.2B | 1.3T | 387 | 1049 | 26.93 | 65.91 | 31.57 | 74.92 | 61.64 | 47.3 | 33.71 | 48.85 |
| Smol LM2 | 1.7B | 11T | 238 | 1573 | 50.29 | 77.78 | 44.71 | 77.09 | 66.38 | 53.55 | 50.5 | 60.04 |
| Llama 3.2 3B | 3.0B | 9T | 191 | 918 | 56.03 | 74.54 | 42.32 | 76.66 | 69.85 | 55.29 | 43.46 | 59.74 |
| Hymba | 1.5B | 1.5T | 664 | 79 | 51.19 | 76.94 | 45.9 | 77.31 | 66.61 | 53.55 | 55.93 | 61.06 |
인스트럭트 모델
Hymba 1.5B Instruct 모델은 모든 작업의 평균에서 가장 높은 성능을 달성하여 이전 최신 모델인 Qwen 2.5 Instruct를 약 2% 앞섰습니다. 특히 Hymba 1.5B는 GSM8K/GPQA/BFCLv2에서 각각 58.76/31.03/46.40의 점수로 다른 모든 모델을 능가합니다. 이러한 결과는 특히 복잡한 추론 능력이 필요한 영역에서 Hymba 1.5B의 우수성을 보여줍니다.
| 모델 | # 매개변수 | MMLU ↑ | IFEval ↑ | GSM8K ↑ | GPQA ↑ | BFCLv2 ↑ | 평균 ↑ |
| SmolLM | 1.7B | 27.80 | 25.16 | 1.36 | 25.67 | -* | 20.00 |
| OpenELM | 1.1B | 25.65 | 6.25 | 56.03 | 21.62 | -* | 27.39 |
| Llama 3.2 | 1.2B | 44.41 | 58.92 | 42.99 | 24.11 | 20.27 | 38.14 |
| Qwen2.5 | 1.5B | 59.73 | 46.78 | 56.03 | 30.13 | 43.85 | 47.30 |
| SmolLM2 | 1.7B | 49.11 | 55.06 | 47.68 | 29.24 | 22.83 | 40.78 |
| Hymba 1.5B | 1.5B | 52.79 | 57.14 | 58.76 | 31.03 | 46.40 | 49.22 |
결론
새로운 Hymba 소형 LM 제품군은 어텐션 헤드의 고해상도 회상 기능과 SSM 헤드의 효율적인 컨텍스트 요약 기능을 결합한 하이브리드 헤드 아키텍처를 특징으로 합니다. Hymba의 성능을 더욱 최적화하기 위해 학습 가능한 메타 토큰이 도입되어 어텐션 헤드와 SSM 헤드 모두에 대한 학습 캐시 역할을 함으로써 모델의 두드러진 정보에 대한 집중력을 향상시킵니다. Hymba의 로드맵, 포괄적인 평가 및 제거 연구를 통해 Hymba는 광범위한 작업에서 새로운 최첨단 성능을 설정하여 정확도와 효율성 모두에서 우수한 결과를 달성합니다. 또한 이 연구는 하이브리드 헤드 아키텍처의 장점에 대한 귀중한 통찰력을 제공하여 향후 효율적인 LM 연구에 대한 유망한 방향을 제시합니다.
Hybma 1.5B Base 및 Hymba 1.5B Instruct에 대해 자세히 알아보세요.
감사의 말
이 연구는 Wonmin Byun, Zijia Chen, Ameya Sunil Mahabaleshwarkar, Shih-Yang Liu, Matthijs Van Keirsbilck, Min-Hung Chen, Yoshi Suhara, Nikolaus Binder, Hanah Zhang, Maksim Khadkevich, Yingyan Celine Lin, Jan Kautz, Pavlo Molchanov 및 Nathan Horrocks를 비롯한 많은 사람들의 도움으로 작성되었습니다.