
NVIDIA는 NVIDIA GTC 2025에서 DeepSeek-R1 추론 성능 세계 기록을 발표했습니다. 8개의 NVIDIA Blackwell GPU가 탑재된 단일 NVIDIA DGX 시스템은 거대한 최첨단 6,710억 개 파라미터 DeepSeek-R1 모델에서 사용자당 초당 250토큰 이상 또는 최대 초당 30,000토큰 이상의 처리량을 달성할 수 있습니다. 이러한 성능 스펙트럼 양쪽에서의 급격한 발전은 NVIDIA Blackwell 아키텍처에 최적화된 NVIDIA의 개방형 추론 개발자 도구 생태계 개선 덕분에 가능했습니다.
이러한 성능 기록은 NVIDIA 플랫폼이 최신 NVIDIA Blackwell Ultra GPU와 NVIDIA Blackwell GPU에서 추론의 한계를 계속해서 확장함에 따라 더욱 향상될 것입니다.
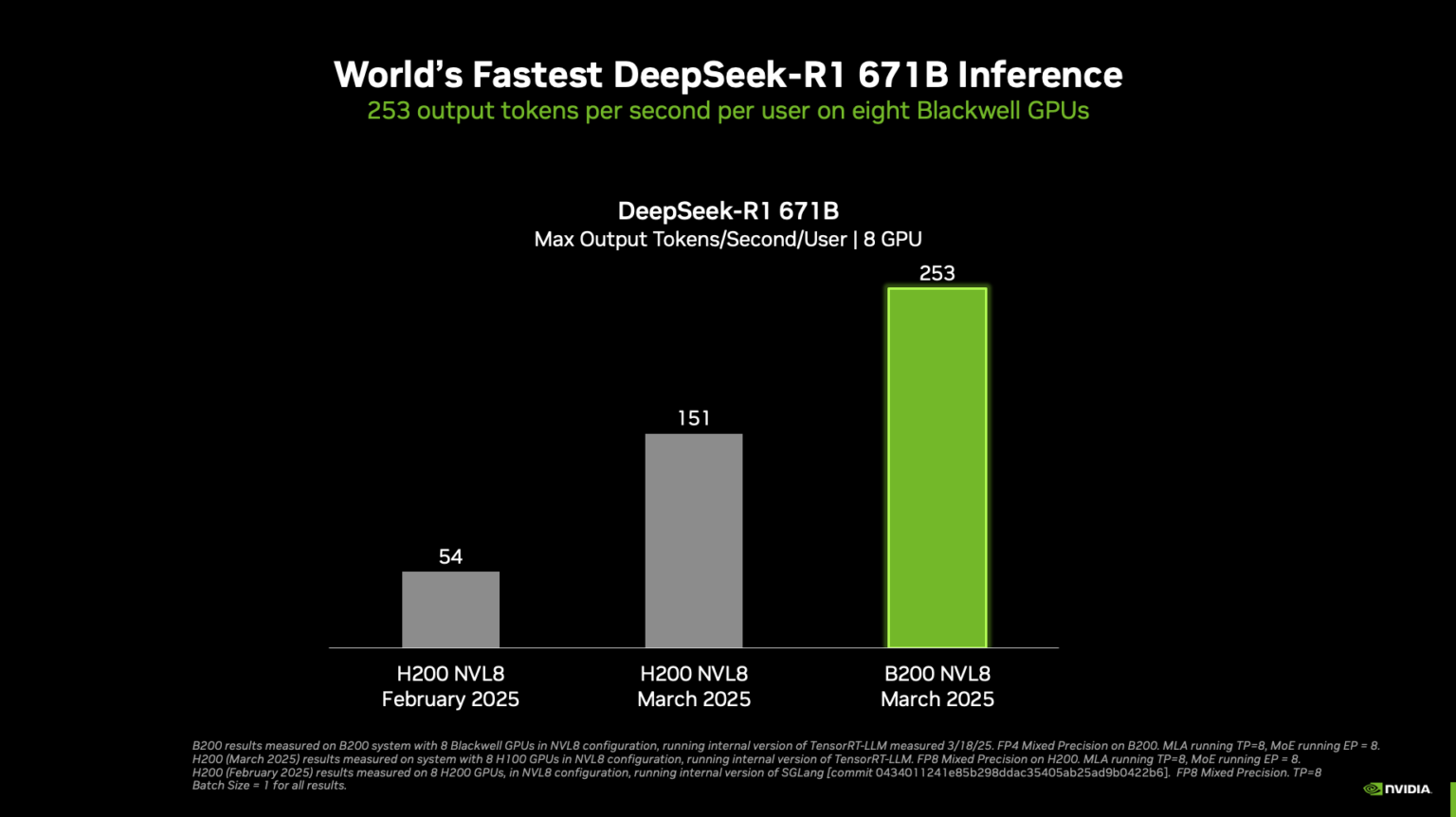
단일 DGX B200 8-GPU 시스템과 단일 DGX H200 8-GPU 시스템 | B200 및 H200은 TensorRT-LLM의 내부 버전에서 실행된 3월 및 2월 수치 | 3월은 입력 1,024 토큰, 출력 2,048 토큰이었으며, 2월과 1월은 입력 1,024 토큰, 출력 1,024 토큰 | Concurrency(동시성) 1 | B200은 FP4, H100 및 H200은 FP8 정밀도.
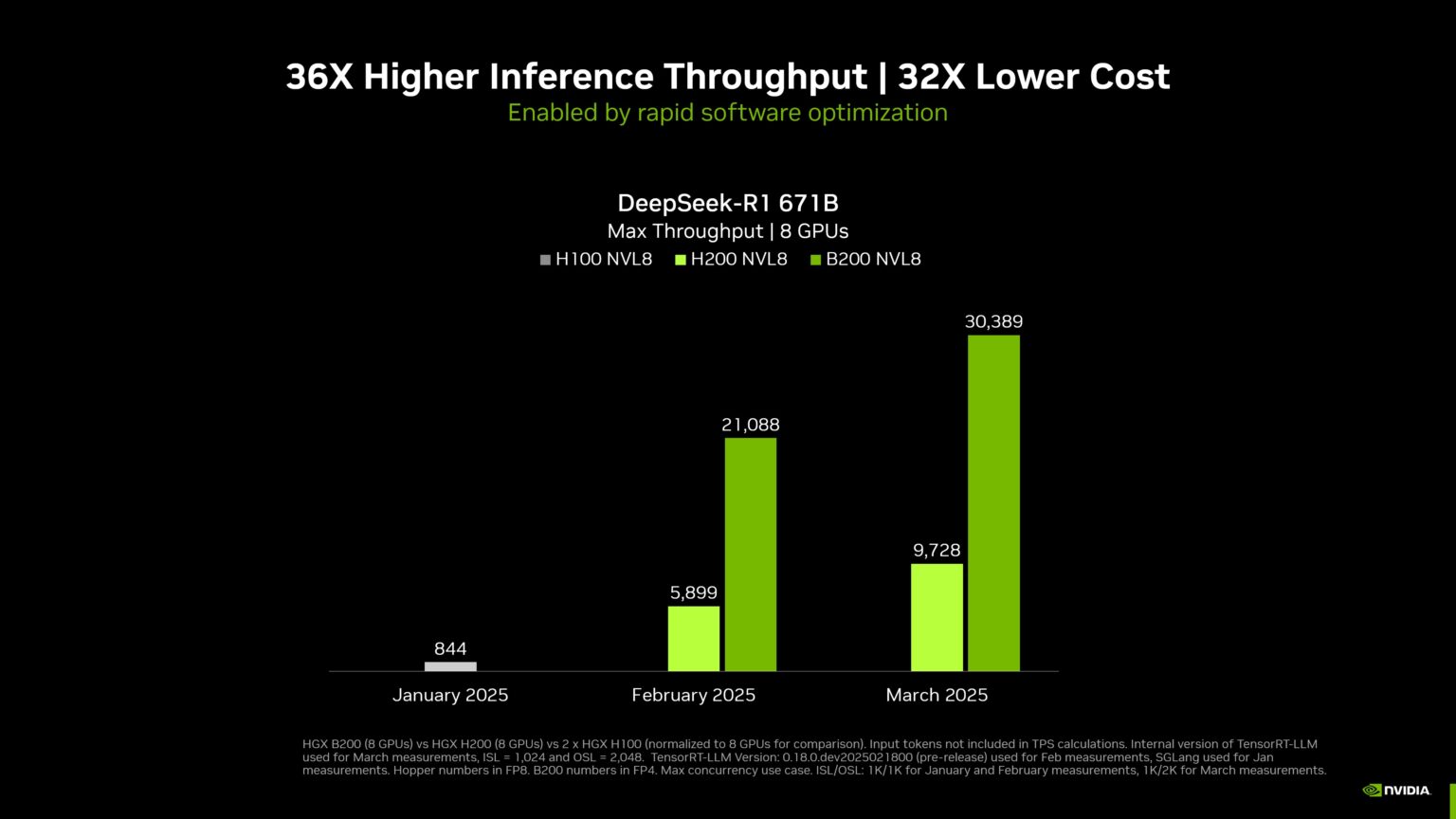
그림 2. 하드웨어와 소프트웨어의 조합을 통해 NVIDIA는 2025년 1월 이후 DeepSeek-R1 671B 모델의 처리량을 약 36배 증가시켰으며, 이는 토큰당 비용을 약 32배 개선하는 결과로 이어졌습니다.
최대 처리량(8-GPU 시스템 기준) | 단일 DGX B200 8-GPU 시스템, 단일 DGX H200 8-GPU 시스템, 두 대의 DGX H100 8-GPU 시스템(정규화됨) | TensorRT-LLM 내부 버전 | 3월, 입력 1,024 토큰, 출력 2,048 토큰, 2월 및 1월, 입력 1,024 토큰, 출력 1,024 토큰 | Concurrency(동시성) 최대(MAX) | B200은 FP4, H200/H100은 FP8 정밀도.
NVIDIA 추론 생태계는 세계에서 가장 큽니다. 이는 개발자들이 최대 사용자 경험 또는 최대 효율성을 목표로 하든, 자신들의 배포 요구사항에 맞춰 솔루션을 구축할 수 있도록 합니다. 여기에는 NVIDIA에서 직접 제공하는 오픈 소스 도구뿐만 아니라, 최신 Blackwell 아키텍처와 소프트웨어 발전을 활용하는 커뮤니티 제공 도구구도 포함됩니다.
이러한 Blackwell 발전에는 FP4 가속화가 적용된 5세대 텐서 코어를 통해 최대 5배 더 많은 AI 컴퓨팅 성능, 5세대 NVLink 및 NVLink Switch를 통해 이전 세대 대비 2배의 NVIDIA NVLink 대역폭, 그리고 훨씬 더 큰 NVLink 도메인으로의 확장성이 포함됩니다. 이러한 성능 향상은 칩 단위 및 데이터센터 규모 모두에서, DeepSeek-R1과 같은 최첨단 LLM을 위한 높은 처리량, 낮은 지연 시간 추론의 핵심 동력입니다.
가속 컴퓨팅은 강력한 하드웨어 인프라 그 이상을 요구합니다. 오늘날 가장 까다로운 워크로드에서 최적의 성능을 제공하고, 새로운 더욱 도전적인 워크로드가 나타날 때 이를 처리할 준비를 갖추기 위해서는 최적화되고 빠르게 진화하는 소프트웨어 스택이 필요합니다. NVIDIA는 예외적인 워크로드 성능을 제공하기 위해 칩, 시스템, 라이브러리, 알고리즘 등 기술 스택의 모든 계층을 지속적으로 최적화하고 있습니다.
이번 블로그는 NVIDIA TensorRT-LLM, NVIDIA TensorRT, TensorRT Model Optimizer, CUTLASS, NVIDIA cuDNN, 그리고 PyTorch, JAX, TensorFlow를 포함한 인기 AI 프레임워크 등 NVIDIA Blackwell 플랫폼을 최대한 활용하기 위한 NVIDIA 추론 생태계의 다양한 업데이트에 대한 개요를 제공합니다. 또한, 두 개의 NVLink Switch 칩을 사용하여 연결된 8개의 Blackwell GPU를 특징으로 하는 NVIDIA DGX B200 시스템에서 측정된 새로운 성능 및 정확도 데이터를 공유합니다.
TensorRT 생태계: NVIDIA Blackwell에 최적화된 완벽한 추론 스택
NVIDIA TensorRT 생태계는 개발자들이 NVIDIA GPU에서 프로덕션 추론 배포를 최적화할 수 있도록 설계되었습니다. 이는 AI 모델의 준비, 가속화 및 배포를 가능하게 하는 여러 라이브러리를 포함하며, 이 모든 것이 이제 최신 NVIDIA Blackwell 아키텍처에서 실행될 준비가 되어 있습니다. 이는 이전 세대인 NVIDIA Hopper 아키텍처와 비교하여 지속적으로 큰 성능 향상을 보여줍니다.
TensorRT Model Optimizer는 추론 속도 최적화를 위한 첫 단계입니다. 이는 양자화, 증류, 가지치기, 희소성, 투기적 디코딩을 포함한 최첨단 모델 최적화 기술을 제공하여 추론 중 모델을 더 효율적으로 만듭니다. 최신 TensorRT Model Optimizer 0.25 release는 post-training quantization (PTQ) 및 quantization-aware training (QAT) 모두에 대해 Blackwell FP4를 지원하여 전체 추론 컴퓨팅 처리량을 최적화하고 다운스트림 추론 프레임워크의 메모리 사용량을 줄입니다.
모델이 최적화된 후에는 모델을 효율적으로 실행하기 위해 고성능 추론 프레임워크가 필수적입니다. TensorRT-LLM은 개발자에게 실시간 및 비용, 에너지 효율적인 LLM 추론을 가능하게 하는 도구 상자를 제공합니다. 최신 TensorRT-LLM 0.17 release는 Blackwell 지원을 추가하고 Blackwell 인스트럭션, 메모리 계층 및 FP4에 대한 맞춤형 최적화를 제공합니다.
PyTorch로 설계된 TensorRT-LLM은 일반적인 LLM 추론 작업에 대한 강력하고 유연한 커널과 비행 중 배치(in-flight batching), KV 캐시 메모리 관리 및 투기적 디코딩과 같은 고급 런타임 기능을 통해 최고의 성능을 제공합니다.
인기 있는 딥러닝 프레임워크인 PyTorch, JAX 및 TensorFlow도 Blackwell에서의 추론 및 훈련을 모두 지원하도록 업데이트되었습니다. vLLM 및 Ollama와 같은 다른 LLM 서비스 프레임워크도 이제 Blackwell GPU에서 사용할 수 있습니다. 다른 프레임워크들도 가까운 미래에 지원될 예정입니다.
Blackwell과 TensorRT 추론 성능
Blackwell 아키텍처는 TensorRT 소프트웨어와 결합하여 Hopper 아키텍처에 비해 상당한 추론 성능 향상을 가능하게 합니다. 이러한 성능 향상은 훨씬 더 뛰어난 컴퓨팅 성능, 메모리 대역폭 및 최적화된 소프트웨어 스택을 통해 탁월한 제공 성능을 달성한 결과입니다.
DeepSeek-R1, Llama 3.1 405B, Llama 3.3 70B를 포함한 인기 있는 커뮤니티 모델에서 TensorRT 소프트웨어를 실행하고 FP4 정밀도를 사용하는 DGX B200 플랫폼은 이미 DGX H200 플랫폼에 비해 3배 이상 더 많은 추론 처리량을 제공하고 있습니다.
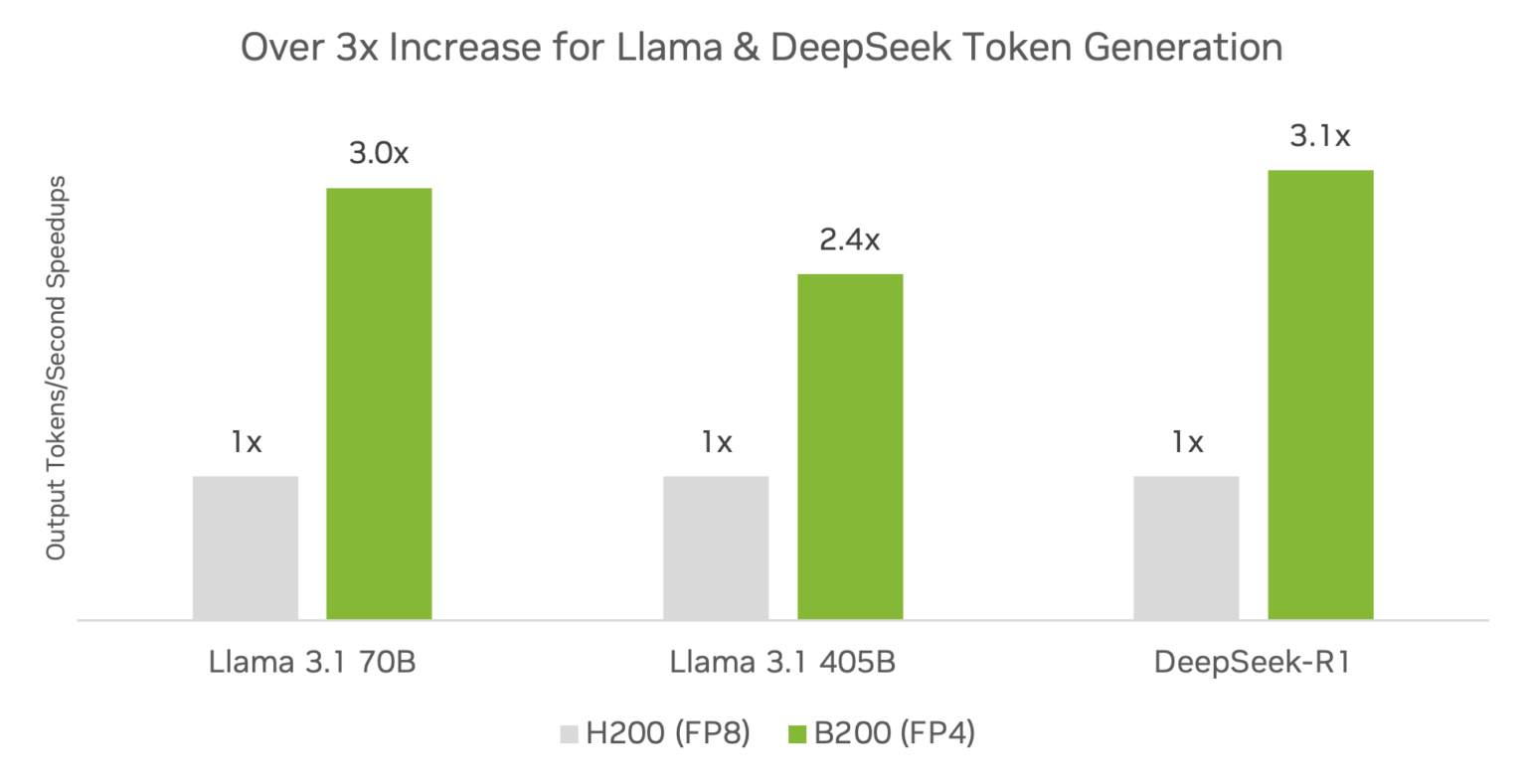
사전 사양입니다. 변경될 수 있습니다.
TensorRT Model Optimizer v0.23.0. TensorRT-LLM v0.17.0. 최대 배치 크기 2048, 실제 배치 크기는 TensorRT-LLM 인플라이트 배칭(Inflight Batching)을 사용하여 동적. H200은 FP16/BF16 GEMM + FP8 KV 캐시. B200은 FP4 GEMM + FP8 KV 캐시. 처리량 가속
Llama 3.3 70B: ISL 2048, OSL 128
Llama 3.1 405B: ISL 2048, OSL 128
DeepSeek-R1: ISL 1024, OSL 1024
더 낮은 정밀도 연산의 이점을 활용하기 위해 모델을 양자화할 때, 프로덕션 배포를 위해서는 최소한의 정확도 손실을 보장하는 것이 중요합니다. DeepSeek-R1의 경우, TensorRT Model Optimizer FP4 사후 훈련 양자화(PTQ)는 표 1에 표시된 바와 같이 다양한 데이터셋에서 FP8 기준선에 비해 최소한의 정확도 손실을 가져옵니다.
| MMLU | GSM8K | AIME 2024 | GPQA Diamond | MATH-500 | |
| DeepSeek R1-FP8 | 90.8% | 96.3% | 80.0% | 69.7% | 95.4% |
| DeepSeek R1-FP4 | 90.7% | 96.1% | 80.0% | 69.2% | 94.2% |
인기 있는 Llama 3.1 405B 및 Llama 3.3 70B 모델의 기준 BF16 정밀도와 FP4 양자화에 대한 정확도 결과는 표 2에 제공됩니다.
| MMLU Baseline | GSM8K Baseline | |
| Llama 3.1 405B-BF16 | 86.5% | 96.3% |
| Llama 3.1 405B-FP4 | 86.1% | 96.1% |
| Llama 3.3 70B-BF16 | 82.5% | 95.3% |
| Llama 3.3 70B-FP4 | 80.5% | 92.6% |
FP4와 같은 낮은 정밀도로 배포할 때, 미세 조정 데이터셋을 사용할 수 있다면 QAT(Quantization-Aware Training)를 적용하여 정확도를 복구할 수 있습니다. QAT의 가치를 설명하기 위해, TensorRT Model Optimizer를 사용하여 FP4로 QAT 양자화된 Nemotron 4 15B 및 Nemotron 4 340B은 BF16 기준선에 비해 손실 없는 FP4 양자화를 달성합니다 (표 3).
| Nemotron 4 15B Base | Nemotron 4 340B Base | |
| BF16 (baseline) | 64.2% | 81.1% |
| FP4 with PTQ | 61.0% | 80.8% |
| FP4 with QAT | 64.5% | 81.4% |
FP4를 활용한 TensorRT 및 TensorRT Model Optimizer로 Blackwell에서 이미지 생성 효율성 증대
이전에는 TensorRT 및 TensorRT Model Optimizer를 통해 INT8 및 FP8을 포함한 8비트 데이터 형식으로 양자화된 디퓨전 모델을 사용하여 고성능 이미지 생성이 가능했습니다.
이제 NVIDIA Blackwell 및 FP4 정밀도는 AI 이미지 생성에 훨씬 더 나은 성능을 제공합니다. 이러한 이점은 NVIDIA GeForce RTX 50 series GPU로 구동되는 AI PC에서 로컬로 이미지를 생성하려는 사용자에게도 확장됩니다.
Black Forest Lab의 Flux.1 model 제품군은 뛰어난 프롬프트 준수 및 복잡한 장면 생성 능력을 제공하는 최첨단 텍스트-투-이미지 모델입니다. 개발자들은 이제 Black Forest Lab의 Hugging Face 컬렉션에서 FP4 Flux 모델을 다운로드하고 TensorRT로 직접 배포할 수 있습니다.
이러한 양자화된 모델은 Black Forest Labs에서 TensorRT Model Optimizer FP4 워크플로우 및 레시피를 사용하여 생성되었습니다. Blackwell에서 FP4 이미지 생성의 이점을 설명하기 위해, FP4 Flux.1-dev 모델은 FP16과 비교하여 처리량(초당 이미지 수)에서 최대 3배의 속도 향상을 달성하며, 동시에 VRAM 사용량을 최대 5.2배 압축하고 이미지 품질을 유지합니다 (표 4).
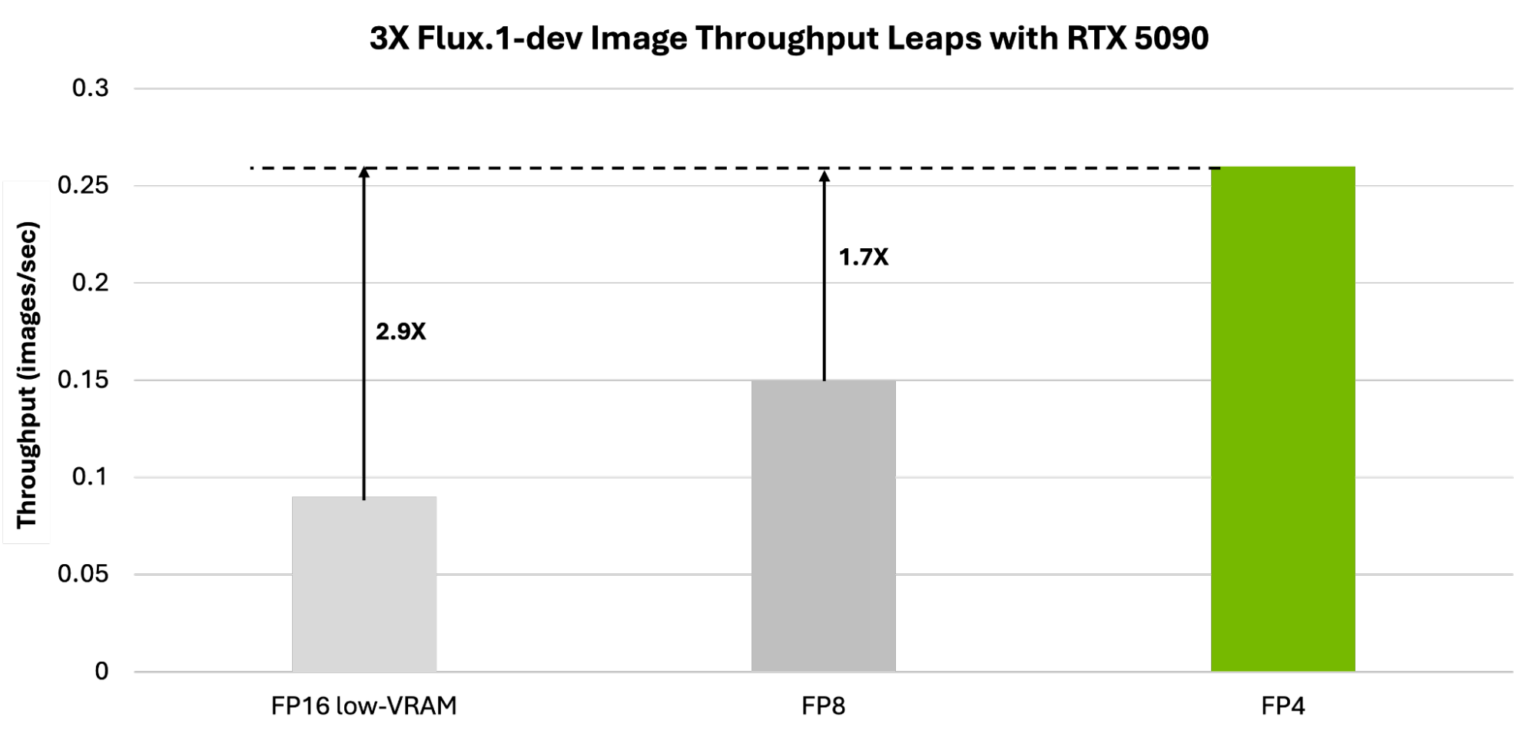
Flux.1-dev에서 트랜스포머 백본만 FP4로 양자화되었으며, 다른 부분은 BF16 형식으로 유지됩니다. TensorRT DemoDiffusion의 저-VRAM 모드는 FLUX.1-dev에 사용된 T5, CLIP, VAE 및 FLUX 트랜스포머를 필요할 때 로드하고 완료되면 언로드합니다. 이는 FLUX의 최대 메모리 사용량이 네 가지 개별 모델 크기의 최댓값 내에 유지되도록 하지만, 추론 중 각 모델을 로드하고 언로드해야 하므로 추가 지연 시간이 발생합니다.
| VRAM usage (GB) | VRAM usage compression | |
| FP16 (Baseline) | 51.4 | 1x |
| FP16 low-VRAM | 23.3 | 2.2x |
| FP8 | 26.3 | 1.9x |
| FP8 low-VRAM | 19.9 | 2.6x |
| FP4 | 19.5 | 2.6x |
| FP4 low-VRAM | 9.9 | 5.2x |
그림 5는 FP4로 양자화된 Flux 모델로 생성된 이미지를 보여주며, 주어진 프롬프트에 대해 이미지 품질과 내용이 BF16 기준과 어떻게 일치하는지 강조합니다. 또한, 표 5는 1,000개 이미지를 사용하여 FP4 이미지 품질, 관련성 및 매력을 정량적으로 평가한 결과를 제공합니다.

상단 이미지 입력 프롬프트: “두 개의 거대한 별이 광활한 우주에서 춤추고 있으며, 강렬한 중력으로 인해 서로에게 더 가까이 끌려가고 있다. 한 별이 블랙홀로 붕괴하면서 찬란한 에너지 폭발을 일으키고, 우주를 배경으로 눈부신 빛의 향연을 연출한다. 소용돌이치는 가스와 먼지 구름이 이 장관을 둘러싸고 있으며, 그 안에 담긴 상상할 수 없는 힘을 암시한다.”
하단 이미지 입력 프롬프트: “부드럽고 푹신한 동물의 털로 질감이 입혀진 사실적인 구체가 이미지 중앙의 평범한 색 배경에 놓여 있다. 털은 부드럽고 실제 같은 움직임으로 물결치며, 털에 의해 드리워진 그림자는 매력적인 시각적 효과를 만들어낸다. 렌더링은 고품질의 옥탄(Octane) 외관을 가지고 있다.”
| Image Reward | CLIP-IQA | CLIPScore | |
| BF16 | 1.118 | 0.927 | 30.15 |
| FP4 PTQ | 1.096 | 0.923 | 29.86 |
| FP4 QAT | 1.119 | 0.928 | 29.92 |
표 5. Image Reward,CLIP-IQA, CLIPScore를 사용한 FP4 이미지 품질 정량적 평가 (높을수록 좋음)
Flux.1-dev 모델, 30단계, 1K 이미지. TensorRT Model Optimizer v0.23.0 FP4 레시피. 2025년 1월 24일 NVIDIA H100 GPU에서 시뮬레이션됨. 시뮬레이션은 RTX 5090의 TensorRT 커널 레벨과 수학적으로 동일합니다. 실제 점수는 RTX 5090에서 약간 다를 수 있습니다.
TensorRT 10.8 업데이트는 이제 하이엔드 GeForce RTX 50 시리즈 GPU에서 최고 FP4 성능으로 Flux.1-Dev 및 Flux.1-Schnell 모델을 실행할 수 있습니다. –low-vram 모드를 사용하면 GeForce RTX 5070과 같이 메모리 구성이 제한된 시스템에서도 이러한 모델을 실행할 수 있습니다. 또한, TensorRT는 Black Forest Labs에서 제공하는 Depth 및 Canny Flux ControlNet도 지원합니다. 지금 TensorRT demo/Diffusion.을 사용하여 시도해 볼 수 있습니다.
cuDNN을 통한 Blackwell 최적화 딥러닝 프리미티브
2014년 출시 이후, NVIDIA cuDNN은 GPU에서 딥러닝 워크로드를 가속화하는 데 핵심적인 역할을 해왔습니다. 핵심 딥러닝 프리미티브의 고도로 최적화된 구현을 제공함으로써 PyTorch, TensorFlow, JAX와 같은 프레임워크가 최첨단 성능을 제공할 수 있도록 했습니다. 이러한 프레임워크와의 원활한 통합과 다양한 GPU 아키텍처에 걸친 최적화된 성능을 통해 cuDNN은 훈련부터 추론까지 엔드-투-엔드 딥러닝 워크로드를 구동하는 성능 엔진으로 자리매김했습니다
cuDNN 9.7 릴리스를 통해 데이터센터 및 GeForce 제품군 모두에서 NVIDIA Blackwell 아키텍처에 대한 지원을 확장하고 있습니다. 개발자들은 cuDNN 작업을 최신 Blackwell 텐서 코어로 마이그레이션할 때 상당한 성능 향상을 기대할 수 있습니다. 이 라이브러리는 블록 스케일링 FP8 및 FP4 연산을 위한 Blackwell의 고급 기능을 활용하는 최적화된 GEMM(General Matrix Multiply) API를 제공하여, 저수준 최적화의 복잡성을 추상화함으로써 개발자들이 혁신에 집중할 수 있도록 합니다.
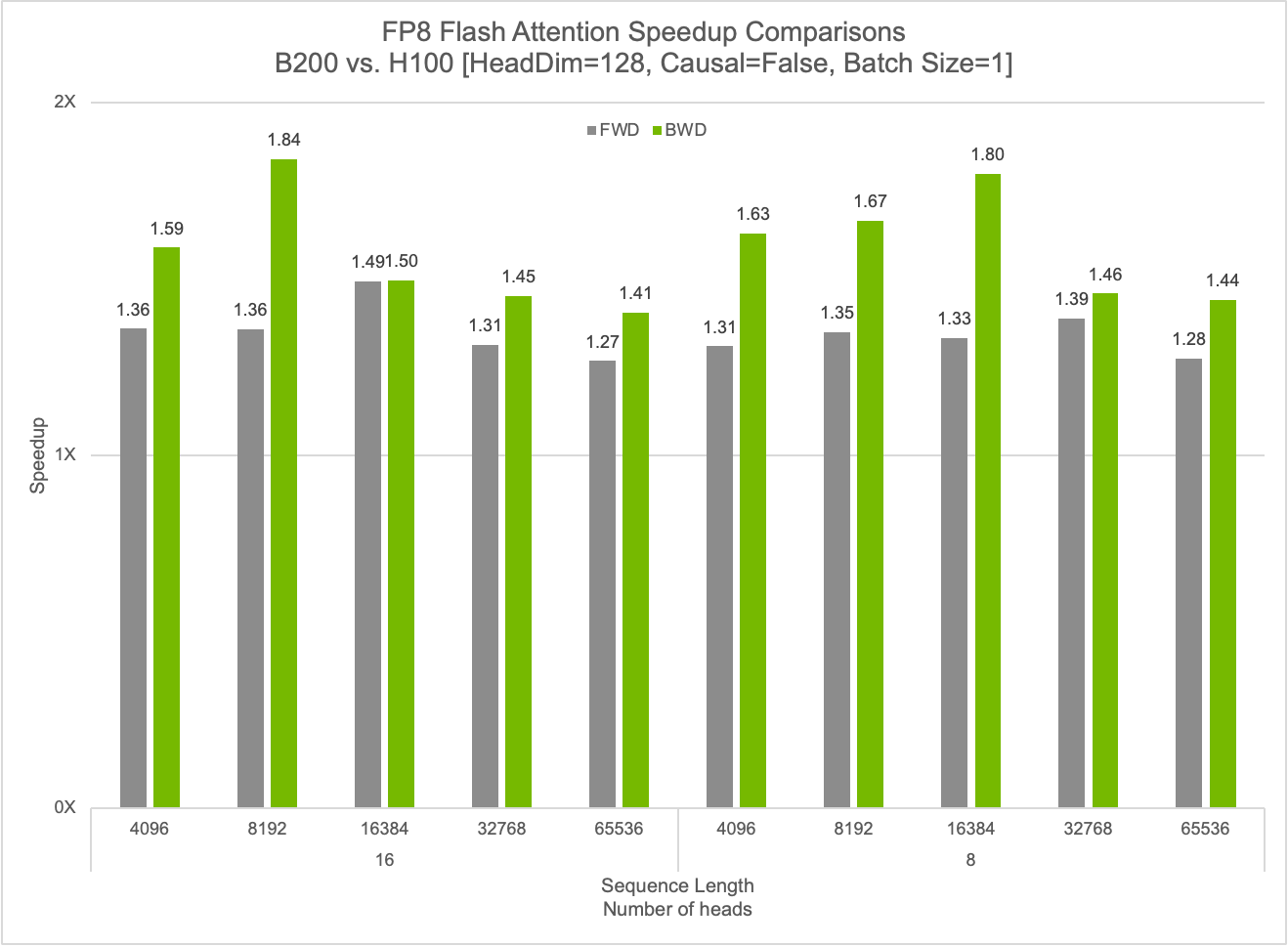
cuDNN은 FP8 플래시 어텐션(Flash Attention) 연산에서 상당한 성능 향상을 제공하여, FP8 커널을 통해 순방향 전파에서 최대 50%의 속도 향상과 역방향 전파에서 84%의 속도 향상을 달성합니다. 이 라이브러리는 또한 Blackwell 아키텍처에서 고급 퓨전 기능을 갖춘 고도로 최적화된 GEMM 연산을 제공합니다. 앞으로 cuDNN은 딥러닝 워크로드에 대한 더 큰 성능 향상을 위해 퓨전 지원을 계속 확장할 것입니다.
CUTLASS를 통해 고성능 Blackwell 커널 제작
CUTLASS는 2017년 첫 출시 이후, NVIDIA GPU에서 고성능 CUDA 커널을 구현하는 연구원 및 개발자에게 중요한 역할을 해왔습니다. 개발자에게 NVIDIA 텐서 코어를 대상으로 하는 GEMM(General Matrix Multiply) 및 컨볼루션과 같은 사용자 지정 작업을 설계할 수 있는 포괄적인 도구를 제공함으로써, FlashAttention과 같은 혁신적인 기술 개발에 결정적인 역할을 했으며 GPU 가속 컴퓨팅의 초석으로 자리매김했습니다.
CUTLASS 3.8 릴리스를 통해 NVIDIA Blackwell 아키텍처에 대한 지원을 확장하여, 개발자들이 모든 새로운 데이터 유형을 지원하는 차세대 텐서 코어를 활용할 수 있도록 했습니다. 여기에는 새로운 협소 정밀도 MX 형식과 NVIDIA 자체 FP4가 포함되어, 개발자들이 가속 컴퓨팅의 최신 혁신을 통해 사용자 지정 알고리즘과 프로덕션 워크로드를 최적화할 수 있도록 지원합니다. 그림 7은 텐서 코어 연산에서 최대 98%의 상대적 최대 성능을 달성할 수 있음을 보여줍니다.
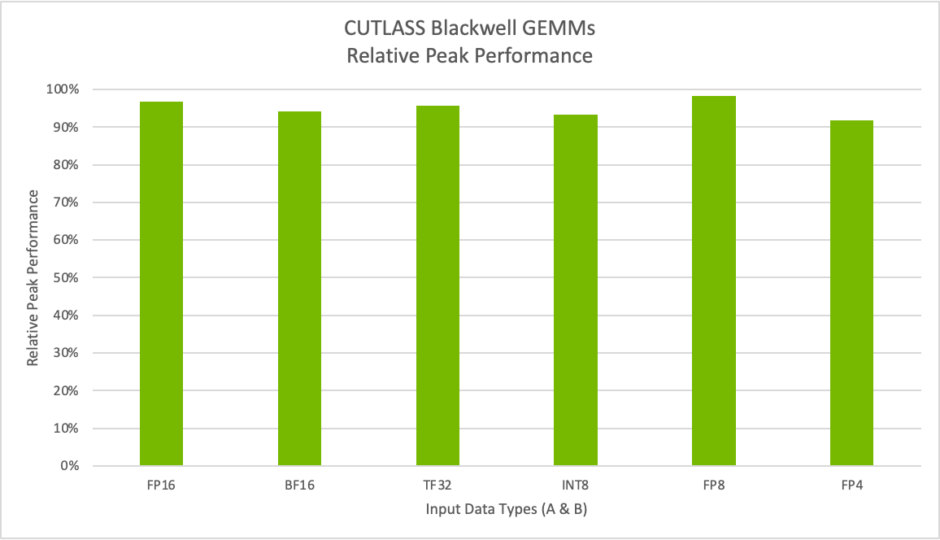
벤치마크는 B200 시스템에서 수행되었습니다. M=K=16384, N=17290.
CUTLASS는 그룹화된 GEMM(Grouped GEMM) 및 혼합 입력 GEMM(Mixed Input GEMM) 연산과 같은 인기 있는 기능을 Blackwell에 제공합니다. 그룹화된 GEMM은 여러 Expert 연산을 병렬로 수행하는 더 효율적인 방법을 제공하여 MoE(Mixture-of-Experts) 모델을 가속화하는 데 도움을 줍니다. 혼합 입력 GEMM은 모델 가중치가 GPU 메모리 소비를 지배하는 LLM(대규모 언어 모델)의 GPU 메모리 요구 사항을 줄일 수 있는 양자화된 커널을 구동합니다.
OpenAI Triton의 Blackwell 지원
OpenAI Triton 컴파일러 또한 이제 Blackwell을 지원하여, 개발자와 연구자들이 Python 기반 컴파일러를 통해 최신 Blackwell 아키텍처 기능을 활용할 수 있게 되었습니다. OpenAI Triton은 이제 Blackwell 아키텍처의 최신 아키텍처 혁신을 활용할 수 있으며, 여러 중요한 사용 사례에서 거의 최적의 성능을 달성할 수 있습니다. 자세한 내용은 NVIDIA와 OpenAI가 공동 저술한 NVIDIA Blackwell에서 OpenAI Triton이 AI 성능 및 프로그래밍 가능성 향상을 참조하십시오.
요약
NVIDIA Blackwell 아키텍처는 FP4 텐서 코어를 갖춘 2세대 트랜스포머 엔진과 5세대 NVLink 스위치를 포함한 NVLink 등 생성형 AI 추론을 가속화하는 많은 혁신적인 기능들을 포함합니다. NVIDIA는 NVIDIA GTC 2025에서 세계 기록 DeepSeek-R1 추론 성능을 발표했습니다. 8개의 NVIDIA Blackwell GPU가 탑재된 단일 NVIDIA DGX 시스템은 거대한 최첨단 6,710억 매개변수 DeepSeek-R1 모델에서 사용자당 초당 250토큰 이상 또는 최대 초당 30,000토큰 이상의 처리량을 달성할 수 있습니다.
풍부한 라이브러리들은 이제 NVIDIA Blackwell에 최적화되어 개발자들이 오늘날의 AI 모델과 미래의 진화하는 환경 모두에서 추론 성능을 크게 향상시킬 수 있도록 할 것입니다. NVIDIA AI Inference 플랫폼에 대해 자세히 알아보고 최신 AI inference 성능 업데이트에 대한 정보를 받아보세요.
감사의 글
이 작업은 Matthew Nicely, Nick Comly, Gunjan Mehta, Rajeev Rao, Dave Michael, Yiheng Zhang, Brian Nguyen, Asfiya Baig, Akhil Goel, Paulius Micikevicius, June Yang, Alex Settle, Kai Xu, Zhiyu Cheng, Chenjie Luo를 포함한 많은 분들의 뛰어난 기여 없이는 불가능했을 것입니다.
관련 리소스
- GTC 세션: TensorRT 모델 옵티마이저로 Blackwell 추론 활성화하기
- GTC 세션: Blackwell에서 안정적이고 확장 가능한 FP8 딥 러닝 트레이닝
- GTC 세션: cuDNN으로 Blackwell에서 딥 러닝 성능 활용하기
- NGC 컨테이너: Triton 추론 서버 PB 2024년 10월(PB 24h2)
- SDK: Triton 추론 서버
- SDK: 비디오 코덱