이 솔루션은 DeepStream 5.1을 필요로 합니다.
멀티 카메라 애플리케이션의 인기가 높아지고 있습니다. 이 어플리케이션은 자율주행 로봇, 지능형 영상 분석(IVA), AR/VR 애플리케이션을 구현하는 데 필수적인 역할을 합니다.구체적인 사용 사례에 관계없이 항상 구현해야 하는 일반적인 작업은 다음과 같습니다.
- 캡처
- 전처리
- 인코딩
- 디스플레이
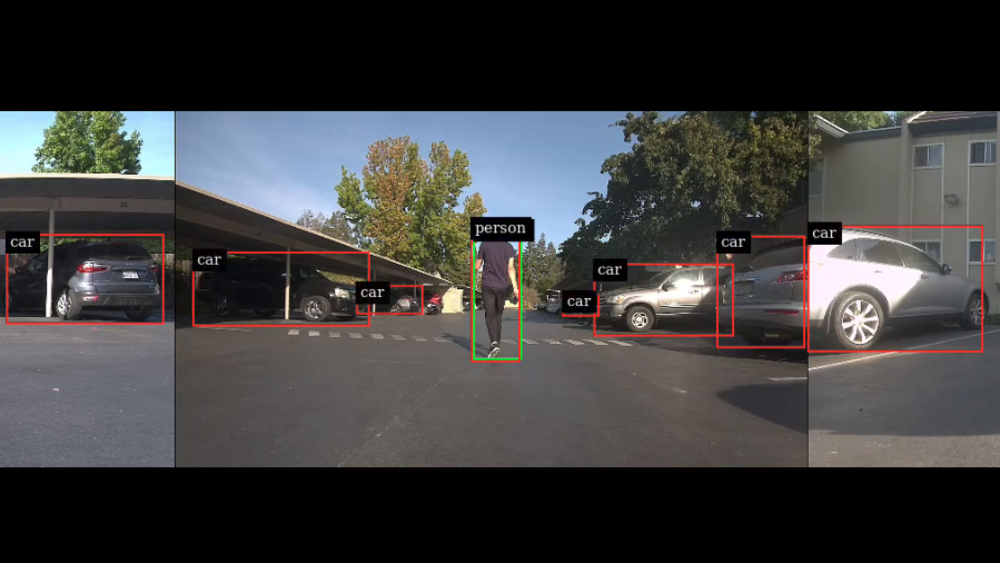
대부분의 경우 카메라 스트림에 DNN을 배포하고 탐지에 대해 사용자 지정 로직을 실행합니다.그림 1은 애플리케이션의 일반적인 흐름을 보여줍니다.
이 게시물에서는 NVIDIA Jetson 플랫폼에서 이러한 일반적인 작업을 효율적으로 실현하는 방법을 소개합니다. 구체적으로, 멀티 카메라 파이프라인을 생성하는 간편한 Python 패키지인 jetmulticam을 제시합니다.또한 서라운드 카메라 시스템이 있는 로봇의 구체적인 사용 사례를 시연합니다.마지막으로 DNN 개체 감지에 기반한 맞춤형 로직(사람 따르기)을 추가하여 다음 영상에 나오는 결과를 얻습니다.
멀티 카메라 하드웨어
카메라 선택 시 고려해야 할 매개변수는 해상도, 프레임 레이트, 광학, 글로벌/롤링 셔터, 인터페이스, 픽셀 크기 등입니다. NVIDIA 파트너의 호환되는 카메라에 대한 자세한 내용은 포괄적인 목록을 참조하세요.
이 특정 멀티 카메라 설정에서는 다음 하드웨어를 사용합니다.
- NVIDIA Jetson Xavier NX 모듈
- Leopard Imaging의 GMSL2 지원 캐리어 보드
- Leopard Imaging의 IMX185 GMSL2 카메라 3개
IMX185 카메라의 시야각은 각각 약 90°입니다. 그림 2와 같이 총 FOV가 270°가 되도록 서로 직각으로 장착합니다.
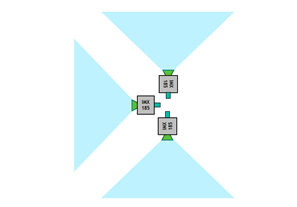
카메라는 GMSL 인터페이스를 사용하는데 이는 카메라를 Jetson 모듈에서 몇 미터 떨어진 곳에 배치할 수 있는 높은 유연성을 제공합니다. 이 경우 카메라를 최대 0.5m 높여서 세로 FOV를 더 넓힐 수 있습니다.
Jetmulticam 시작하기
먼저 Jetson 보드에 NVIDIA Jetpack SDK를 다운로드 및 설치합니다. 그 후 다음과 같이 jetmulticam 패키지를 설치합니다.
$ git clone https://github.com/NVIDIA-AI-IOT/jetson-multicamera-pipelines.git
$ cd jetson-multicamera-pipelines
$ bash scripts/install_dependencies.sh
$ pip3 install Cython
$ pip3 install .기본 멀티 카메라 파이프라인
설치가 끝나면 CameraPipeline 클래스를 사용하여 기본 파이프라인을 만들 수 있습니다. 초기화 인수가 있는 파이프라인에 포함할 카메라 목록을 전달합니다. 다음 예제에서 [0, 1, 2] 요소는 디바이스 노드 /dev/video0, /dev/video1 및 /dev/video2에 해당합니다.
from jetmulticam import CameraPipeline
p = CameraPipeline([0, 1, 2])이제 파이프라인이 초기화되고 시작되었습니다. 이제 파이프라인의 각 카메라에서 이미지를 읽고 numpy 배열로 액세스할 수 있습니다.
img0 = p.read(0) # img0 is a np.array
img1 = p.read(1)
img2 = p.read(2)다음 코드 예제와 같이 루프 내의 카메라에서 읽는 것이 편리한 경우가 많습니다. 파이프라인은 주 스레드에서 비동기적으로 실행되며 read는 항상 가장 최근 버퍼를 가져옵니다.
while True:
img0 = p.read(0)
print(img0.shape) # >> (1920, 1080, 3)
time.sleep(1/10)보다 복잡한 AI 파이프라인
이제 보다 복잡한 파이프라인을 구축할 수 있습니다. 이번에는 CameraPipelineDNN 클래스를 사용하여 더 복잡한 파이프라인을 비롯해 NGC 카탈로그의 사전 트레이닝된 두 모델인 PeopleNet 및 DashCamNet을 구성합니다.
import time
from jetmulticam import CameraPipelineDNN
from jetmulticam.models import PeopleNet, DashCamNet
if __name__ == "__main__":
pipeline = CameraPipelineDNN(
cameras=[2, 5, 8],
models=[
PeopleNet.DLA1,
DashCamNet.DLA0,
# PeopleNet.GPU
],
save_video=True,
save_video_folder="/home/nx/logs/videos",
display=True,
)
while pipeline.running():
arr = pipeline.images[0] # np.array with shape (1080, 1920, 3)
dets = pipeline.detections[0] # Detections from the DNNs
time.sleep(1/30)파이프라인 초기화의 요소는 다음과 같습니다.
- 카메라
- 모델
- 하드웨어 가속화
- 영상 저장
- 영상 표시
- 기본 루프
카메라
먼저 이전 예시와 마찬가지로 cameras 인수는 센서의 목록입니다. 이 경우 다음과 같이 디바이스 노드와 관련된 카메라를 사용합니다.
/dev/video2/dev/video5/dev/video8
cameras=[2, 5, 8]모델
두 번째 인수인 모델을 통해 파이프라인에서 실행할 사전 트레이닝된 모델을 정의할 수 있습니다.
models=[
PeopleNet.DLA1,
DashCamNet.DLA0,
# PeopleNet.GPU
],여기서는 NGC로부터 다음 두 개의 사전 트레이닝된 모델을 배포합니다.
- PeopleNet: 사람, 얼굴 및 가방을 식별할 수 있는 개체 감지 모델
- DashCamNet: 자동차, 사람, 도로 표지판, 자전거의 네 가지 클래스로 개체를 식별할 수 있는 모델
자세한 내용은 NGC의 모델 카드를 참조하세요.
하드웨어 가속화
모델은 NVIDIA 딥 러닝 가속기(DLA)를 사용하여 실시간으로 실행됩니다. 특히 DLA0(DLA Core 0)의 PeopleNet과 DLA1의 DashCamNet을 배포하게 됩니다.
두 가속기에 모델을 분산하면 파이프라인의 총 처리량을 늘릴 수 있습니다.또한 DLA는 GPU보다 전력 효율이 훨씬 더 높습니다.그 결과 시스템은 가장 높은 클럭 설정의 전체 부하 내에서 최대 10W 정도만 소비합니다. 마지막으로 이 구성에서 Jetson GPU는 Jetson NX에서 사용 가능한 384개의 CUDA 코어로 더 많은 작업을 가속화할 수 있습니다.
다음 코드 예제는 현재 지원되는 모델/가속기 조합의 목록을 보여줍니다.
pipeline = CameraPipelineDNN(
# ...
models=[
models.PeopleNet.DLA0,
models.PeopleNet.DLA1,
models.PeopleNet.GPU,
models.DashCamNet.DLA0,
models.DashCamNet.DLA1,
models.DashCamNet.GPU
]
# ...
)영상 저장
다음 두 인수는 인코딩된 영상을 저장할지 여부를 지정하고 저장에 사용되는 폴더를 정의합니다.
save_video=True,
save_video_folder="/home/nx/logs/videos",영상 표시
마지막 초기화 단계로, 디버깅 목적으로 화면에 영상 출력을 표시하는 파이프라인을 구성합니다.
display=True기본 루프
마지막으로 기본 루프를 정의합니다. 런타임 동안 이미지는 pipeline.images에서, 감지 결과는 pipeline.detections에서 이용할 수 있습니다.
while pipeline.running():
arr = pipeline.images[0] # np.array with shape (1080, 1920, 3)
dets = pipeline.detections[0] # Detections from the DNNs
time.sleep(1/30)다음 코드 예제에서는 감지 결과를 보여줍니다. 감지할 때마다 다음 사항이 포함된 사전이 제공됩니다.
- 개체 클래스
- 픽셀 좌표에서 [왼쪽, 너비, 상단, 높이]로 정의된 개체 위치
- 감지 신뢰도
>>> pipeline.detections[0]
[
# ...
{
"class": "person",
"position": [1092.72 93.68 248.01 106.38], # L-W-T-H
"confidence": 0.91
},
#...
]맞춤형 로직을 통한 AI 파이프라인 확장
마지막 단계로 기본 루프를 확장하여 DNN 출력을 사용해 맞춤형 로직을 구축할 수 있습니다. 특히 카메라의 감지 출력을 사용하여 로봇에 기본적인 사람 따르기 로직을 구현할 수 있습니다. 소스 코드는 NVIDIA-AI-IOT/jetson-multicamera-pipelines GitHub 리포지토리에서 이용 가능합니다.
- 따를 사람을 찾으려면 pipeline.detections 출력을 파싱합니다. 이 로직은 find_closest_human 함수에서 구현됩니다.
- dets2steer 내의 바운딩 박스 위치를 기준으로 로봇의 조향 각도를 계산합니다.
- 사람이 좌측 이미지에 있는 경우 최대한 좌측으로 돕니다.
- 사람이 우측 이미지에 있는 경우 최대한 우측으로 돕니다.
- 사람이 가운데 이미지에 있는 경우 바운딩 박스 중앙의 X 좌표에 비례하여 돕니다.
결과 영상은 초기화 중에 정의한 대로 /home/nx/logs/video에 저장됩니다.
솔루션 개요
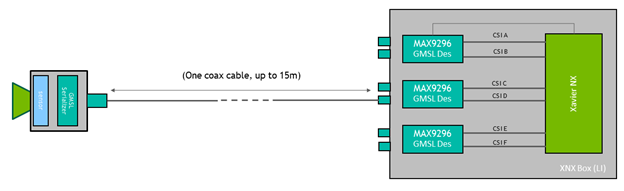
jetmulticam의 작동 방식을 간략하게 살펴보겠습니다. 이 패키지는 애플리케이션에 필요한 카메라 수와 함께 GStreamer 파이프라인을 동적으로 생성하고 시작합니다. 그림 4는 기본 GStreamer 파이프라인이 사람 따르기 예제와 같이 구성된 경우 어떤 모습인지 보여줍니다. 보시다시피 녹색 상자로 표시된 시스템의 모든 중요 작업은 하드웨어 가속의 이점을 누릴 수 있습니다.
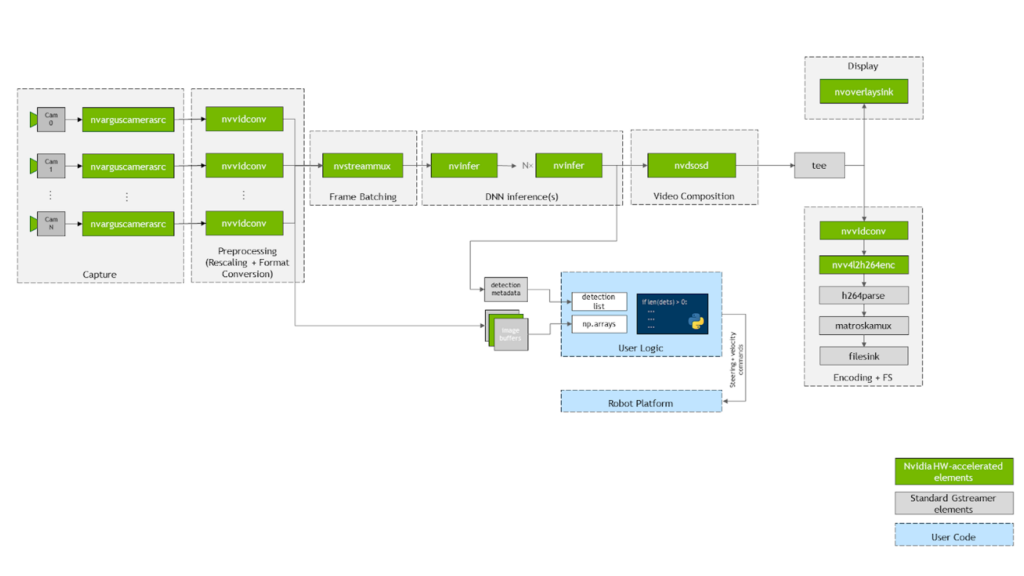
먼저 영상은 다이어그램의 nvarguscamerasrc 요소를 사용하여 여러 CSI 카메라로 캡처됩니다. 각 버퍼는 nvvidconv 또는 nvvideoconvert를 통해 다시 스케일링되고 RGBA 형식으로 변환됩니다. 다음으로 프레임은 DeepStream SDK에서 제공하는 구성 요소를 사용하여 배치 처리됩니다. 기본적으로 배치 크기는 시스템의 카메라 수와 같습니다.
DNN 모델을 배포하려면 nvinfer 요소를 활용합니다. 이 데모에서는 Jetson Xavier NX에서 사용 가능한 두 개의 가속기인 DLA core 1과 DLA core 2에 PeopleNet 및 DashCamNet이라는 두 개의 모델을 배포했습니다. 하지만 필요한 경우 더 많은 모델을 추가할 수 있습니다.
결과 바운딩 박스가 nvosd 요소에 의해 오버레이된 후 nvoverlaysink를 사용해 이를 HDMI 디스플레이에 표시하고 하드웨어 가속 H264 인코더로 영상 스트림을 인코딩합니다. .mkv 파일로 저장합니다.
Python 코드에서 사용할 수 있는 이미지(예: pipeline.images[0])는 각 영상 변환기 요소에 등록되어 콜백 함수 또는 probe에 의해 numpy 배열로 파싱됩니다. 마찬가지로, 메타데이터를 사용자 친화적인 감지 목록으로 파싱하는 마지막 nvinfer 요소의 싱크패드에 다른 콜백 함수가 등록됩니다. 소스 코드 또는 개별 구성 요소 구성에 대한 자세한 내용은 create_pipeline 함수를 참조하세요.
결론
NVIDIA Jetson 플랫폼에서 사용할 수 있는 하드웨어 가속화와 NVIDIA SDK를 결합하여 뛰어난 실시간 성능을 달성할 수 있습니다. 예를 들어 사람 따르기 예시에서는 3개의 카메라 스트림에서 실시간으로 2개의 개체 감지 뉴럴 네트워크를 실행하지만 CPU 사용률은 20% 미만으로 유지됩니다.
이 게시물에서 소개한 Jetmulticam 패키지는 Python에서 자체 하드웨어 가속 파이프라인을 구축하고 감지에 맞춤형 로직을 포함하도록 지원합니다.
이 블로그에 열거된 SDK의 대부분의 독점 액세스, 얼리 액세스, 기술 세션, 데모, 교육 과정, 리소스는 NVIDIA 개발자 프로그램 회원은 무료로 혜택을 받으실 수 있습니다. 지금 무료로 가입하여 NVIDIA의 기술 플랫폼에서 구축하는 데 필요한 도구와 교육에 액세스하시고 여러분의 성공을 가속화 하세요.