
로봇 에이전트가 주변 환경의 오브젝트와 상호 작용하려면 주변 오브젝트의 위치와 방향을 알아야 합니다. 이 정보는 3D 공간에서 강체의 6가지 자유도(DOF) 포즈를 설명하며, 이동 및 회전 상태를 자세히 설명합니다.
특정 방식으로 물체를 잡거나 배치하기 위해 로봇 팔의 방향을 결정하는 데는 정확한 포즈 추정이 필요합니다. 사용 사례에는 픽 앤 플레이스(pick-and-place) 작업을 위한 로봇 조작이 포함되며, 특히 박스 포장, 부품 적재, 식품 포장과 같은 작업을 위한 창고 시나리오에 적용할 수 있습니다. 물체의 포즈를 파악하는 것은 로봇과 사람 간의 핸드오프에도 중요하며 의료, 소매 및 가정 시나리오에서 유용합니다.
NVIDIA는 물체의 6가지 DOF 포즈를 찾기 위해 딥 오브젝트 포즈 추정(DOPE)을 개발했습니다. 이 게시물에서는 오브젝트에 대한 DOPE 모델을 훈련하기 위해 합성 데이터를 생성하는 방법을 보여줍니다.
딥 오브젝트 포즈 추정
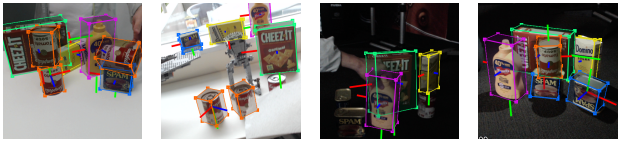
DOPE는 환경에서 오브젝트를 로봇으로 조작할 수 있도록 RGB 이미지에서 관심 있는 오브젝트의 6가지 DOF 포즈를 추정하는 NVIDIA에서 개발한 원샷 DNN입니다. 합성 데이터로만 훈련되며 텍스처가 있는 3D 모델이 필요합니다. 2cm의 허용 오차로 실제 잡기 및 그리퍼 조작에 충분한 정확도를 제공합니다.
DOPE는 인스턴스 수준 모델이므로 클래스 내의 각 객체 유형에 대해 DOPE 모델을 특별히 훈련해야 합니다. 예를 들어, 모든 유형의 의자를 감지하기 위해 하나의 DOPE 모델을 훈련할 수 없으며 대신 의자 유형별로 하나의 모델을 훈련해야 합니다.
또 다른 예로, 애플리케이션이 서로 다른 색상의 기하학적으로 유사한 상자 4개를 감지하는 경우 추론을 위해서는 각 색상의 상자에 대해 특별히 훈련된 DOPE 모델 인스턴스 4개가 필요합니다.
DOPE의 장점
- 합성 데이터로만 훈련할 수 있어 데이터 수집 및 주석 비용을 절감할 수 있습니다.
- 오브젝트 오클루전(object occlusion)을 처리합니다.
- 훈련을 위해 도메인 무작위 합성 데이터와 사실적인 합성 데이터를 결합하여 현실과 괴리 문제를 줄입니다.
- 퍼스펙티브 앤 포인트(PnP) 알고리즘을 사용하여 재훈련 없이도 다양한 카메라 내부에서 작동합니다.
- DOPE는 GPU 가속화된 오브젝트 포즈 추정을 제공하기 위해 NVIDIA Isaac ROS에서 지원됩니다.
현실과의 격차 문제
합성 데이터로만 훈련된 네트워크는 실제 데이터에서 성능이 떨어지는 경우가 많습니다. 미세 조정 또는 도메인 무작위화와 같은 기술은 성능 향상에 도움이 됩니다.
도메인 무작위화는 시뮬레이션 환경에서 장면 조명, 스케일, 포즈, 색상, 오브젝트의 텍스처와 같은 매개변수를 다양하게 변경하는 방법입니다. 이는 신경망에 충분히 다양한 도메인 파라미터를 제공하여 실제 환경에 대한 일반화를 개선하기 위해 수행됩니다. 이렇게 하면 실제 데이터가 네트워크의 또 다른 변형으로 나타납니다.
DOPE는 훈련을 위해 도메인 무작위 데이터와 사실적인 합성 데이터를 결합하여 현실과의 격차를 해소하고 실제 사용 사례에 잘 일반화합니다.
아키텍처
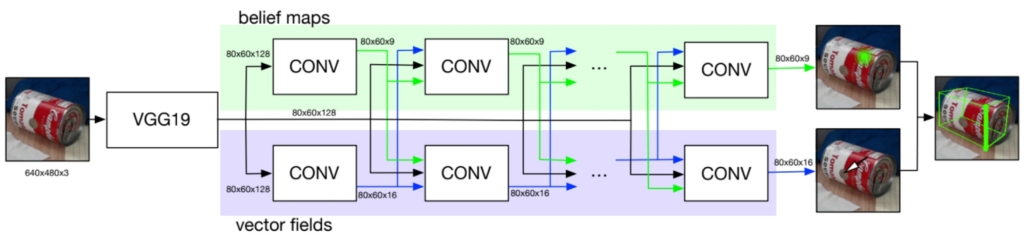
DOPE는 컨볼루션 포즈 머신(CPM)과 다인칭 포즈 추정기에서 영감을 얻은 원샷 완전 컨볼루션 신경망입니다. 이 아키텍처는 추가 컨볼루션 레이어가 있는 VGG19 또는 RESNET과 같은 표준 CNN으로 구성됩니다.
DOPE 아키텍처와 데이터 생성 파이프라인에 대한 포괄적인 이해는 가정용 객체의 시맨틱 로봇 파악을 위한 딥 오브젝트 포즈 추정을 참조하세요.
데이터 세트
NVIDIA는 NVIDIA 포즈 추정을 위한 가정용 오브젝트(HOPE) 데이터 세트에서 훈련된 사전 훈련된 DOPE 모델을 제공합니다. 이 데이터 세트는 다양한 환경에 있는 28개의 장난감 식료품 오브젝트 모음으로, 6D 오브젝트 포즈 추정을 위한 벤치마크의 일부입니다.
인스턴스 수준이기 때문에 DOPE는 애플리케이션과 관련된 관심 오브젝트를 대상으로 하는 데이터 세트로 훈련해야 합니다. DOPE를 훈련하기 위한 데이터 세트를 생성하려면 객체의 3D 모델이 필요합니다. 3D 오브젝트 모델은 BundleSDF를 사용하여 생성할 수 있습니다. NVIDIA에서 개발한 이 방법은 단안 RGBD 카메라를 사용하므로 고가의 3D 센서가 필요하지 않습니다.
데이터 생성
도메인 무작위화를 위해 NVIDIA Isaac Sim을 사용하여 DOPE용 합성 데이터를 생성할 수 있습니다. 당사에서는 MESH와 DOME이라는 두 가지 데이터 세트에 중점을 두고 NViSII 백서에서 이러한 데이터 세트에 대해 표시된 것과 유사한 무작위화 기법을 구현합니다.
이러한 데이터 세트는 관심 대상 주변의 장면에 날아다니는 방해 요소를 추가하고 조명 조건, 방해 요소의 색상 및 재질을 무작위화합니다. DOME은 메시보다 더 적은 수의 방해 요소를 사용하며 더 사실적인 배경을 제공합니다.

Isaac Sim을 사용하여 DOPE용 훈련 데이터를 생성하는 방법에 대한 정보는 NVIDIA 문서에서 확인할 수 있습니다.
각 유형(MESH 및 DOME)별로 생성할 이미지의 수를 지정할 수 있습니다. 좋은 MESH / DOME 분할은 사용 사례에 따라 다릅니다. 실험을 통해 모델에 적합한 휴리스틱을 찾아보세요(예: MESH/DOME 25/75). 단일 객체에 대해 데이터를 생성하고 DOPE를 훈련하는 경우 일반적으로 약 2만 개의 이미지로 구성된 훈련 데이터 세트면 충분합니다.
생성된 데이터 세트에는 이미지와 주석이 달린 JSON 파일이 포함됩니다. 각 JSON 파일에는 객체 클래스, 위치, 방향, 해당 이미지의 가시성 등 객체에 대한 정보가 포함되어 있습니다. 가시성은 객체가 얼마나 보이는지(오클루전의 경우)를 나타내며, 학습을 위해 이미지를 필터링하는 데 사용할 수 있습니다.
Isaac Sim을 사용한 이 데이터 생성 방법은 YCB 비디오 데이터세트와 유사한 형식으로 데이터를 작성하여 다른 6D 포즈 추정 모델을 훈련하는 데 사용할 수 있습니다.
오브젝트 대칭성
DOPE는 관심 물체를 묶는 직육면체 모서리에 대해 훈련됩니다. 이 오브젝트의 회전 대칭은 픽셀 단위로 동일하지만 다른 직육면체 모서리로 표시된 여러 프레임을 생성할 수 있습니다.
자세한 내용은 GitHub에서 딥 오브젝트 포즈 비디오를 시청하세요.
현재 Isaac Sim 데이터 생성 방법은 회전 대칭을 명시적으로 처리하지 않습니다. 하지만 NVIDIA는 대칭을 처리할 수 있는 NViSII를 사용한 합성 데이터 생성 스크립트도 제공합니다.
DOPE 훈련
훈련 데이터 세트를 생성한 후 NVIDIA는 DOPE를 훈련하기 위한 스크립트를 제공합니다. 스크립트에서 훈련 데이터를 가리키고 모델을 훈련할 배치 크기와 에포크 수를 지정할 수 있습니다.
스크립트는 유용한 훈련 정보(손실 그래프 및 믿음 맵 포함)를 저장하며, 이를 TensorBoard를 사용하여 확인할 수 있습니다.
추론 및 평가
DOPE 모델을 훈련한 후에는 테스트 데이터 세트에서 추론을 실행할 수 있습니다. 테스트 데이터의 이미지에 따라 제공된 구성 파일에서 구성 매개변수를 지정하거나 직접 작성할 수 있습니다.
객체 구성 파일에 관심 객체의 물리적 치수를 포함합니다(온라인에서 3D 뷰어를 사용하여 3D 모델을 로드하고 치수를 찾았음). 추론 워크플로우에서는 이러한 치수를 사용하여 감지된 객체 주위에 바운딩 박스가 있는 결과를 생성합니다.

추론을 실행한 후에는 모델의 성능을 정량적으로 평가할 수 있는 평가 워크플로를 제공합니다. 평가를 위해서는 추론 단계에서 예측된 실측 데이터와 관심 대상의 3D 모델(.obj 형식)이 필요합니다. 오브젝트의 3D 모델을 렌더링하여 실측 데이터와 예측 결과 간의 3D 오차를 계산합니다.
오차 계산에는 ADD 메트릭이 사용되며 두 가지 옵션이 제공됩니다:
- 평균 거리(ADD)는 예측된 포즈와 기준점 포즈 사이의 가장 가까운 지점 거리를 사용하여 계산한 평균 거리입니다.
- 직육면체(Cuboid) 거리는 3D 모델(실측 기준점)과 예측된 직육면체 점의 8개의 직육면체 점을 사용하여 평균 거리를 계산합니다. 이 방법은 ADD보다 계산 속도가 빠르지만 정확도는 떨어집니다.
임의의 물체에 대한 도메인 무작위 데이터만 사용했을 때 관찰된 가장 높은 곡선 아래 면적(AUC)은 300만 개의 이미지에서 66.64였습니다. 600만 장의 실사 이미지로 구성된 데이터 세트만 사용했을 때는 62.94의 AUC가 관찰되었습니다. 도메인 무작위 이미지와 사실적인 합성 이미지를 결합했을 때 정확도가 가장 높았습니다(77.00 AUC).
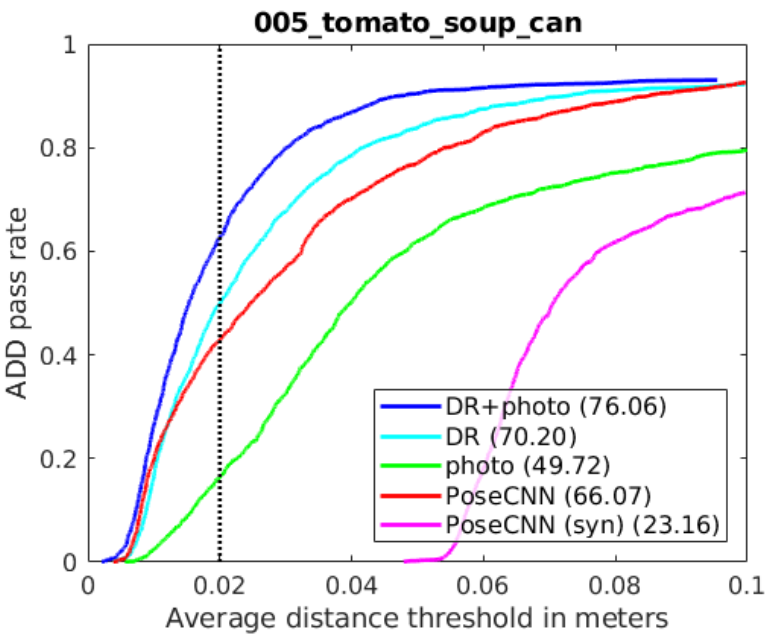
DOPE는 합성 이미지에 대해서만 훈련되었습니다. 하지만 다른 카메라로 촬영한 장면에서, 심지어 폐색과 극심한 조명 변화가 있는 경우에도 여전히 우수한 성능을 발휘합니다. 실제 데이터 또는 합성 데이터와 실제 데이터의 조합으로 훈련된 PoseCNN과 BB8보다 성능이 더 뛰어납니다.
직접 비교를 위해 YCB 데이터세트에서 5개의 오브젝트를 선택했는데, 5개의 오브젝트 중 4개의 오브젝트에 대해 DOPE가 PoseCNN보다 더 높은 AUC를 달성했습니다.
자세한 내용은 DOPE 백서에서 확인할 수 있습니다. 추론 및 평가에 대한 자세한 내용은 GitHub에서 확인하세요.
Isaac ROS 포즈 추정 사용
Isaac ROS는 DOPE를 사용한 포즈 추정을 위한 ROS 2 패키지를 제공합니다. 이 패키지는 NVIDIA Triton 또는 NVIDIA TensorRT를 사용하여 GPU 가속 추론과 Isaac ROS DNN 추론을 수행합니다.
DOPE 모델을 훈련한 후, 이 패키지를 사용하여 NVIDIA Jetson 또는 NVIDIA GPU가 탑재된 시스템에서 추론을 실행할 수 있습니다.
카메라 스트림의 라이브 이미지에서 추론을 수행할 수도 있지만, 이는 컴퓨팅 집약적인 작업입니다. 포즈 추정은 카메라 입력 속도보다 낮은 프레임 속도로 수행됩니다. 당사의 DOPE 그래프는 Isaac ROS 벤치마크 워크플로우를 기준으로 NVIDIA Jetson AGX Orin에서 39.8 FPS, NVIDIA RTX 4060 Ti-에서 89.2 FPS로 실행됩니다.
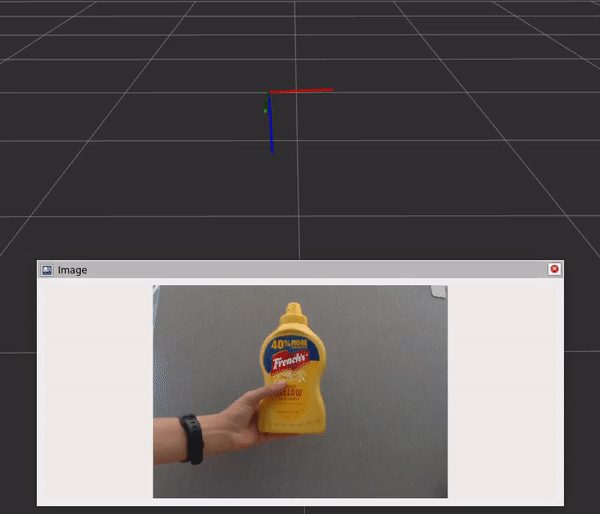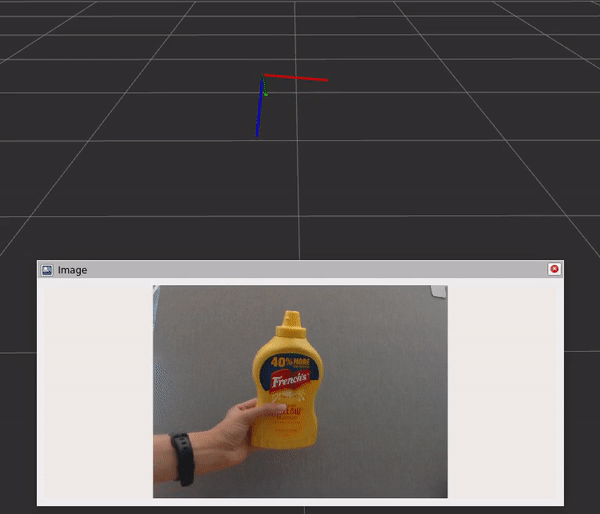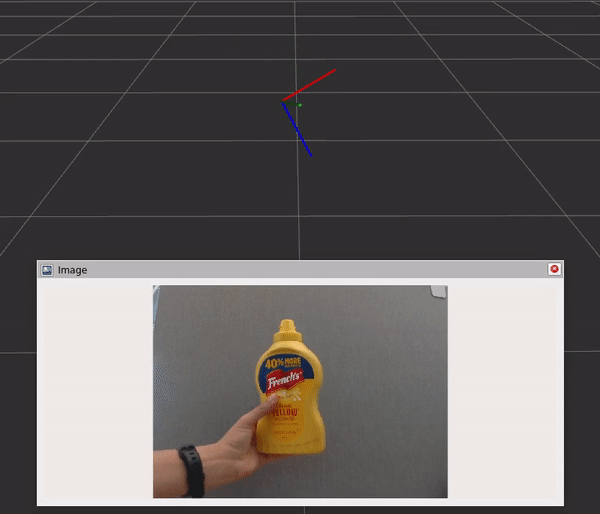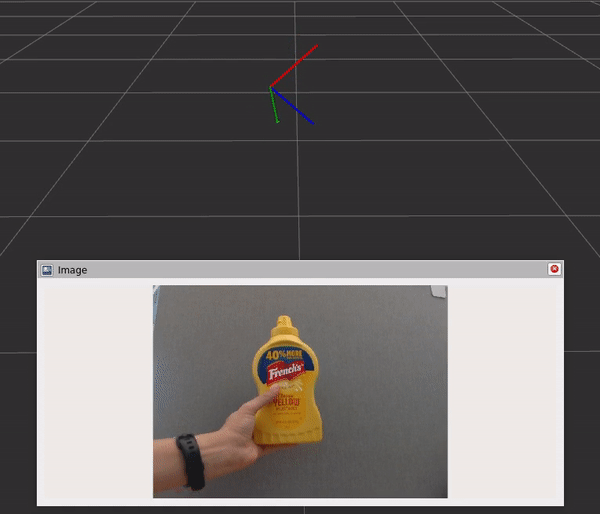
그래프에는 세 가지 구성 요소와 단계가 포함되어 있습니다:
- DNN 이미지 인코더 노드는 원시 이미지를 크기가 조정되고 정규화된 텐서로 변환합니다.
- TensorRT 노드는 입력 텐서를 신뢰도 맵의 텐서로 변환합니다.
- DOPE 디코더 노드는 신뢰도 맵을 포즈 배열로 변환합니다.
성능 요약에서 다양한 Isaac ROS 패키지의 성능과 벤치마킹 방법론에 대해 자세히 알아보세요.
관련 리소스
GTC 세션: Jetson의 AI 기반 6D 객체 포즈 추정: NVIDIA 에코시스템 내 엔드투엔드 트레이닝 및 배포
NGC 컨테이너: Isaac ML 3D 포즈
SDK: Isaac SDK
웨비나: Isaac 개발자 밋업 #2 – NVIDIA Isaac 리플리케이터 및 NVIDIA TAO로 AI 기반 로봇 제작하기
웨비나: Jetson의 vSLAM을 사용한 핀포인트, 250fps, ROS 2 로컬라이제이션
웨비나: NVIDIA Jetson에서 NITROS로 나만의 CUDA ROS 노드 사용하기