
최근 NVIDIA는 개발자가 NVIDIA Jetson 엣지 디바이스를 통해 실제 환경에서 생성형 AI의 무한한 가능성을 탐색할 수 있도록 지원하는 Jetson Generative AI Lab을 공개했습니다. 다른 임베디드 플랫폼과 달리 Jetson은 대규모 언어 모델(LLM), 비전 트랜스포머를 실행할 수 있으며 로컬에서 안정적으로 확산할 수 있습니다. 여기에는 대화형 속도에서 가장 큰 Llama-2-70B 모델이 Jetson AGX Orin에 포함됩니다.
Jetson에서 최신 모델과 애플리케이션을 신속하게 테스트하려면 Jetson Generative AI 랩에서 제공되는 튜토리얼과 리소스를 활용하세요. 이제 물리적 세계에서 생성형 AI의 숨겨진 잠재력을 발견하는 데 집중할 수 있습니다
이 게시물에서는 실험실 튜토리얼에서 포괄적으로 다루고 있는 Jetson 장치에서 실행하고 경험할 수 있는 흥미로운 생성형 AI 애플리케이션을 살펴봅니다.
엣지에서의 생성형 AI
빠르게 진화하는 AI 환경에서 특히 생성형 모델과 다음과 같은 기술이 주목받고 있습니다:
- 사람과 같은 대화를 할 수 있는 대규모 언어 모델(LLM).
- 카메라를 통해 실제 세계를 인식하고 이해할 수 있는 능력을 LLM에 제공하는 비전 언어 모델(VLM).
- 단순한 텍스트 프롬프트를 멋진 시각적 창작물로 변환하는 확산 모델.
이러한 놀라운 AI의 발전은 많은 사람들의 상상력을 사로잡았습니다. 하지만 이러한 최첨단 모델 추론을 지원하는 인프라를 자세히 살펴보면 데이터 센터의 처리 능력에 의존하여 클라우드에 연결되어 있는 경우가 많습니다. 이러한 클라우드 중심 접근 방식은 고대역폭의 저지연 데이터 처리를 필요로 하는 특정 엣지 애플리케이션을 거의 다루지 않고 있습니다.
로컬 환경에서 LLM 및 기타 생성형 모델을 실행하는 새로운 트렌드가 개발자 커뮤니티 내에서 확산되고 있습니다. Reddit의 r/LocalLlama와 같이 번창하는 온라인 커뮤니티는 매니아들이 생성형 AI 기술의 최신 발전과 실제 애플리케이션에 대해 논의할 수 있는 플랫폼을 제공합니다. Medium과 같은 플랫폼에 게시된 수많은 기술 기사에서는 로컬 설정에서 오픈 소스 LLM을 실행할 때의 복잡성에 대해 자세히 다루고 있으며, 그 중 일부는 NVIDIA Jetson을 활용하고 있습니다.
Jetson Generative AI Lab은 최신 생성형 AI 모델 및 애플리케이션을 발견하고 Jetson 장치에서 실행하는 방법을 학습하는 허브 역할을 합니다. 거의 매일 새로운 LLM이 등장하고 양자화 라이브러리의 발전으로 하룻밤 사이에 벤치마크가 재편되는 등 이 분야가 빠른 속도로 진화함에 따라 NVIDIA는 최신 정보와 효과적인 툴을 제공하는 것이 중요하다는 것을 인식하고 있습니다. 따라 하기 쉬운 튜토리얼과 사전 빌드된 컨테이너를 제공합니다.
그 원동력은 Jetson 장치용 컨테이너를 구축하기 위해 세심하게 설계되고 세심하게 유지 관리되는 오픈 소스 프로젝트인 jetson-containers입니다. 이 프로젝트는 GitHub Actions를 사용하여 CI/CD 방식으로 100개의 컨테이너를 구축하고 있습니다. 이를 통해 기본 도구와 라이브러리를 구성하는 번거로움 없이 최신 AI 모델, 라이브러리 및 애플리케이션을 Jetson에서 빠르게 테스트할 수 있습니다.
Jetson Generative AI Lab과 Jetson 컨테이너를 사용하면 Jetson을 통해 실제 환경에서 생성형 AI의 무한한 가능성을 탐색하는 데 집중할 수 있습니다.
단계별 가이드
다음은 Jetson Generative AI lab에서 사용할 수 있는 NVIDIA Jetson 장치에서 실행되는 몇 가지 흥미로운 생성형 AI 애플리케이션입니다.
스테이블 디퓨전 웹이(stable-diffusion-webui)
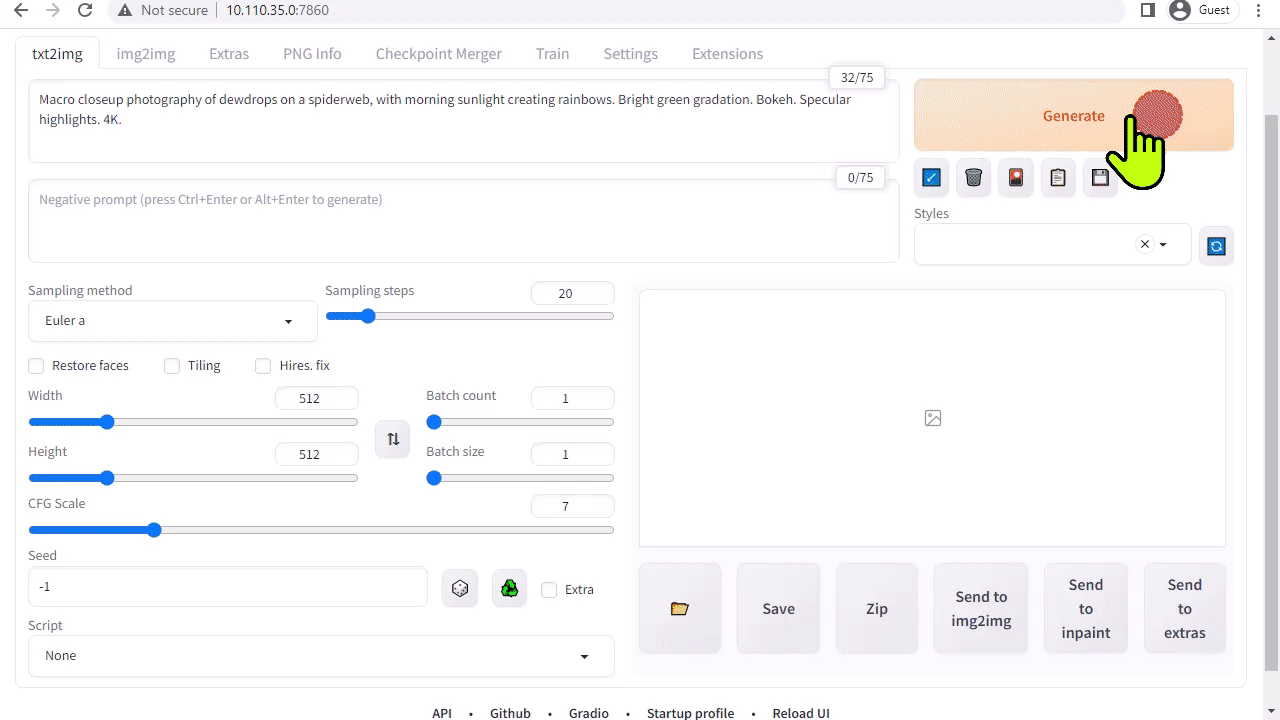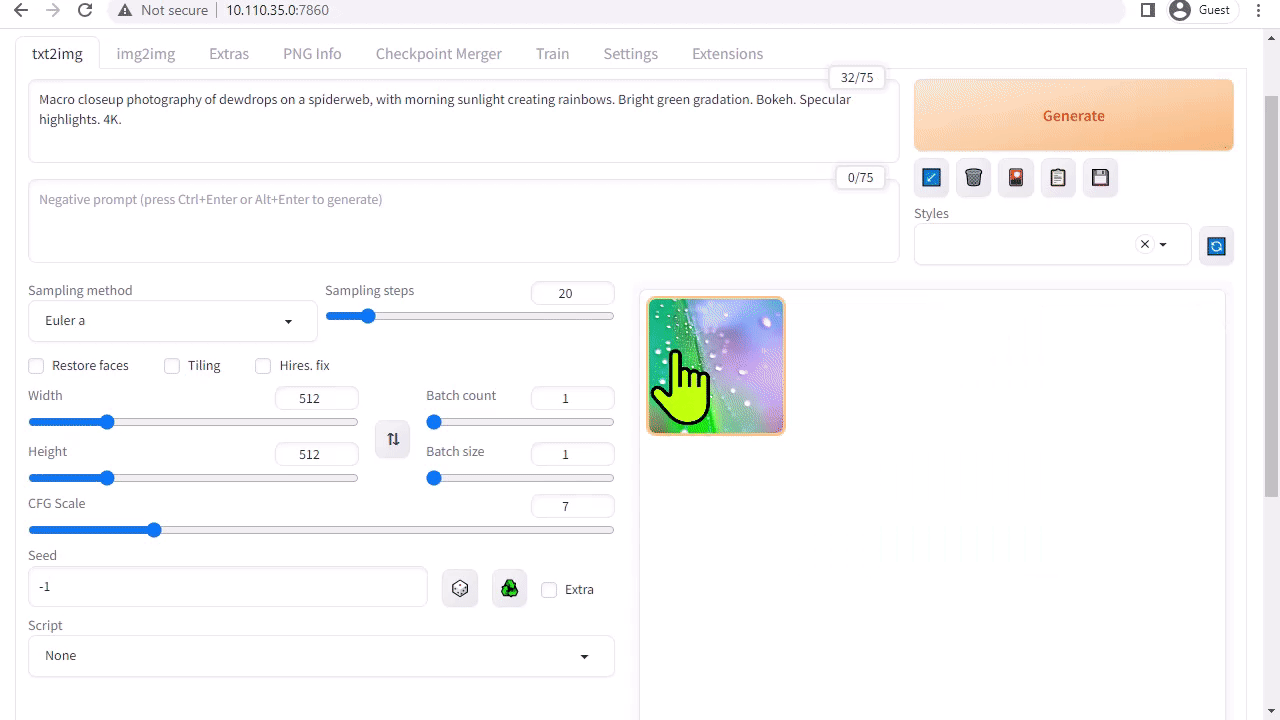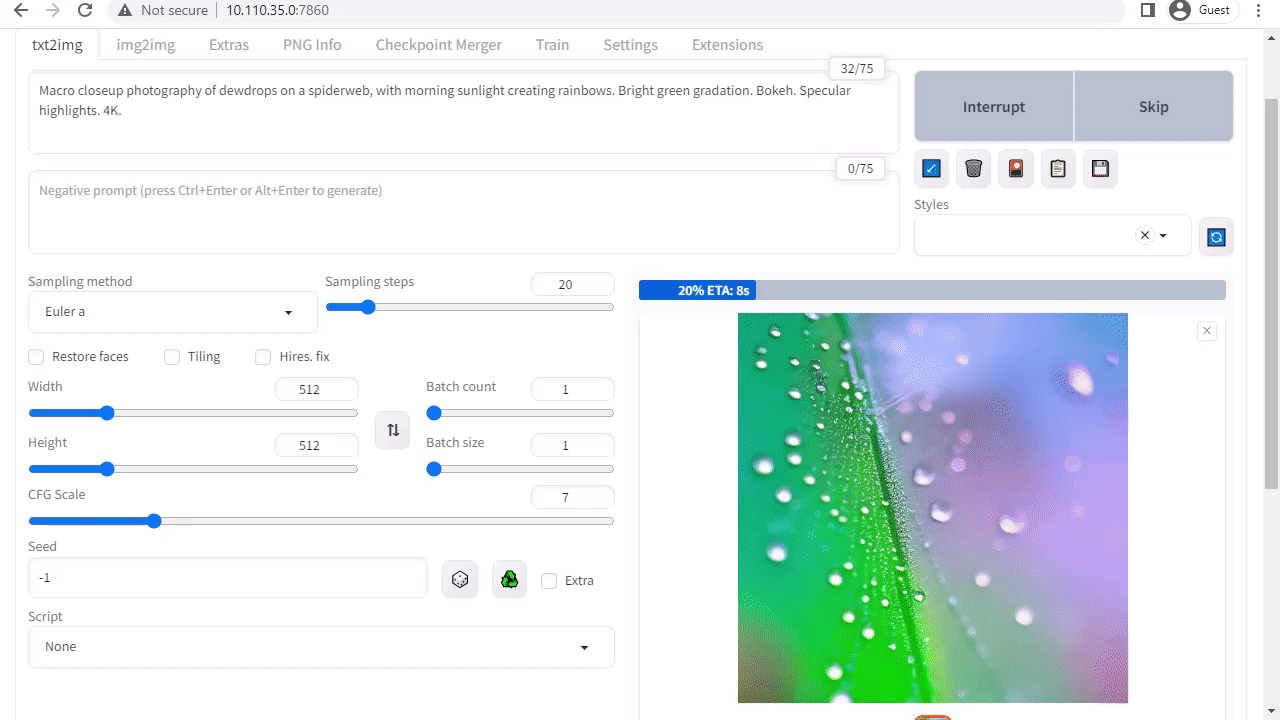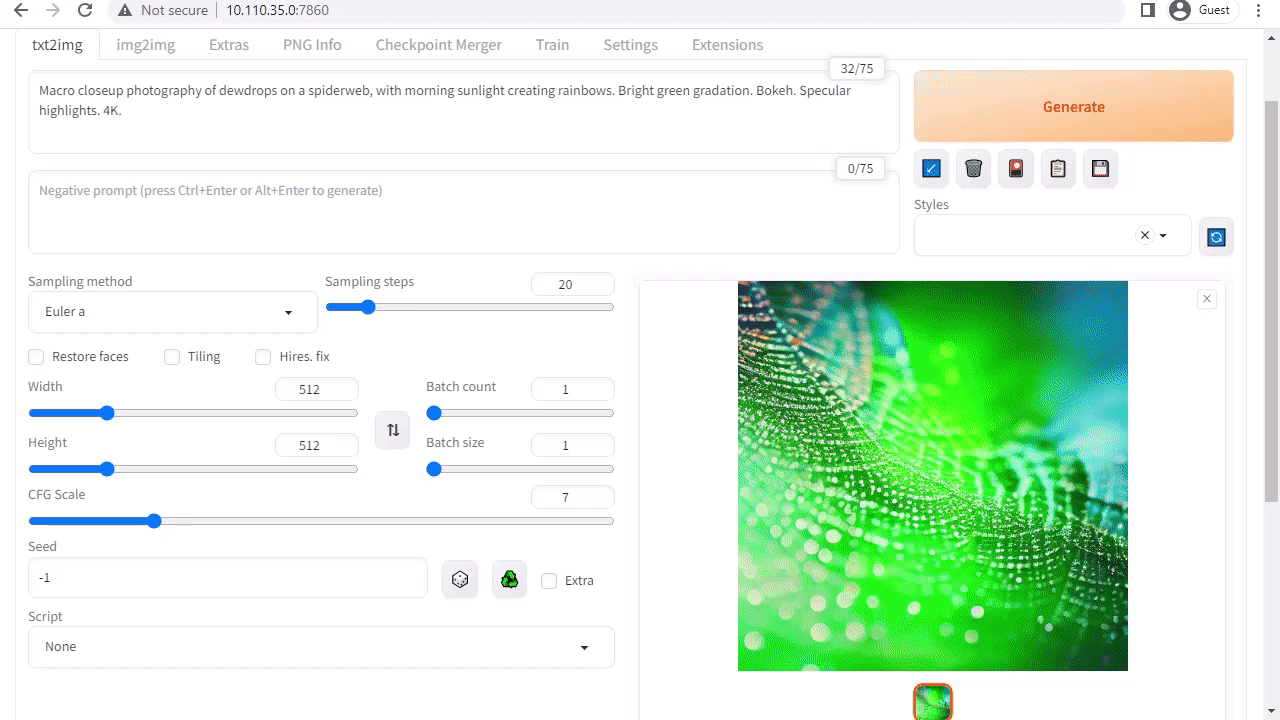
A1111의 stable-diffusion-webui는 Stability AI에서 출시한 Stable Diffusion에 대한 사용자 친화적인 인터페이스를 제공합니다. 이를 통해 다음과 같은 다양한 작업을 수행할 수 있습니다:
Txt2img: 텍스트 프롬프트를 기반으로 이미지를 생성합니다.
img2img: 입력 이미지와 해당 텍스트 프롬프트에서 이미지를 생성합니다.
인페인팅(inpainting): 입력 이미지에서 누락되거나 가려진 부분을 채웁니다.
아웃페인팅(outpainting): 입력 이미지를 원래 테두리 너머로 확장합니다.
웹 앱은 처음 시작할 때 Stable Diffusion v1.5 모델을 자동으로 다운로드하므로 이미지 생성을 바로 시작할 수 있습니다. Jetson Orin 디바이스가 있는 경우 튜토리얼에 설명된 대로 다음 명령을 실행하기만 하면 됩니다.
git clone https://github.com/dusty-nv/jetson-containers
cd jetson-containers
./run.sh $(./autotag stable-diffusion-webui)stable-diffusion-webui 실행에 대한 자세한 내용은 Jetson Generative AI 랩 튜토리얼을 참조하세요. Jetson AGX Orin은 이 게시물 상단에 있는 추천 이미지를 생성한 최신 SDXL(Stable Diffusion XL) 모델도 실행할 수 있습니다.
텍스트 생성 웹이(text-generation-webui)
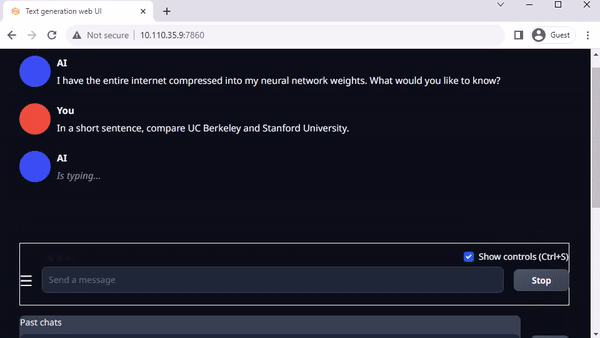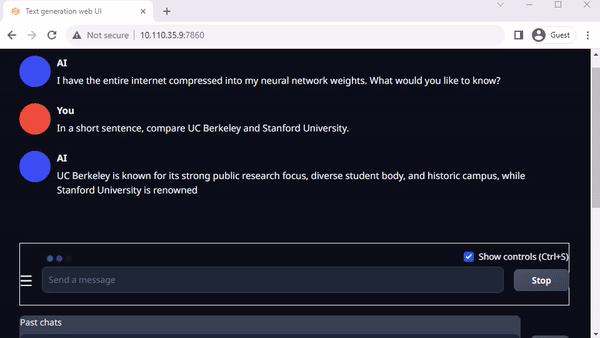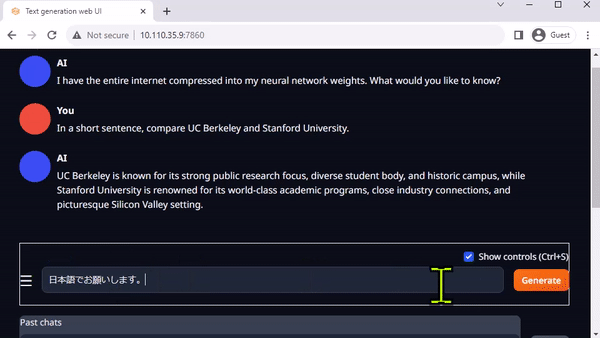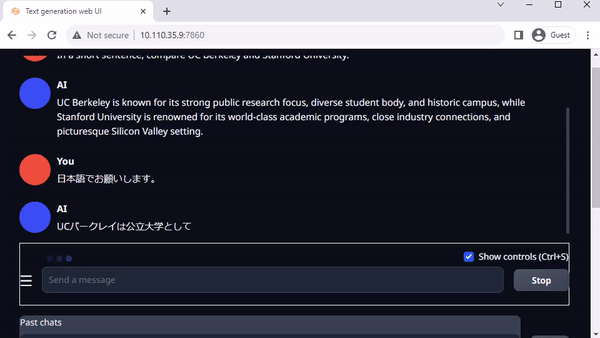
Oobabooga의 텍스트 생성 웹이는 로컬 환경에서 LLM을 실행하기 위한 또 다른 인기 있는 Gradio 기반 웹 인터페이스입니다. 공식 리포지토리에서는 플랫폼용 원클릭 설치 프로그램을 제공하지만, jetson 컨테이너는 훨씬 더 쉬운 방법을 제공합니다.
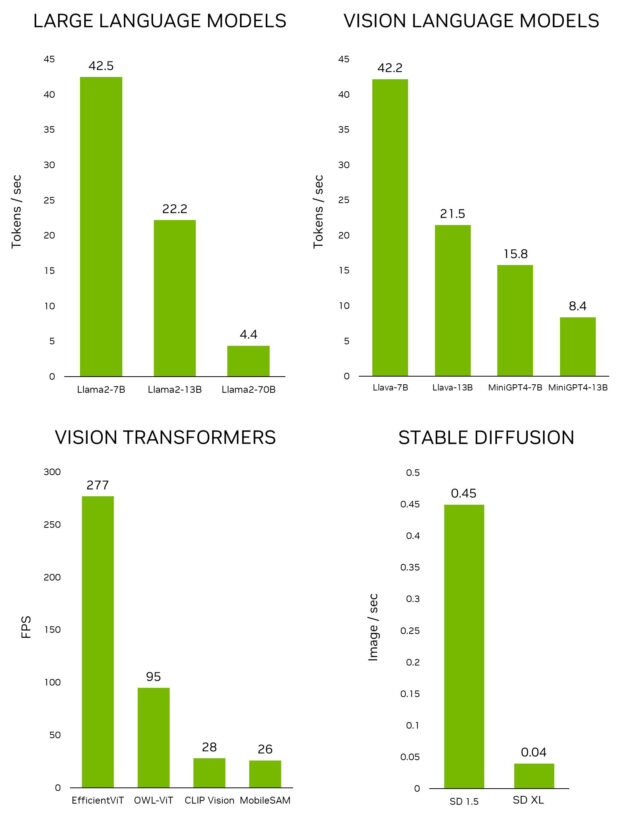
이 인터페이스를 사용하면 허깅 페이스 모델 리포지토리에서 모델을 쉽게 다운로드할 수 있습니다. 4비트 양자화를 사용하면 일반적으로 Jetson Orin Nano는 7B 매개변수 모델을, Jetson Orin NX 16GB는 13B 매개변수 모델을, Jetson AGX Orin 64GB는 무려 70B 매개변수 모델을 실행할 수 있다는 것이 경험상 일반적인 규칙입니다.
현재 많은 사람들이 연구 및 상업적 용도로 무료 제공되는 Meta의 오픈 소스 대규모 언어 모델인 Llama-2를 사용하고 있습니다. 감독형 미세 돌림(SFT) 및 인간 피드백을 통한 강화 학습(RLHF)과 같은 기법을 사용하여 학습된 Llama-2 기반 모델도 있습니다. 일부 벤치마크에서는 라마-2가 GPT-4를 능가한다는 주장도 있습니다.
텍스트 생성 웹비는 확장 기능을 제공하며 사용자가 직접 확장 기능을 개발할 수 있습니다. 나중에 llamaspeak 예제에서 볼 수 있듯이 애플리케이션을 통합하는 데 사용할 수 있습니다. 또한 Llava와 같은 멀티모달 VLM과 이미지에 대한 채팅도 지원합니다.
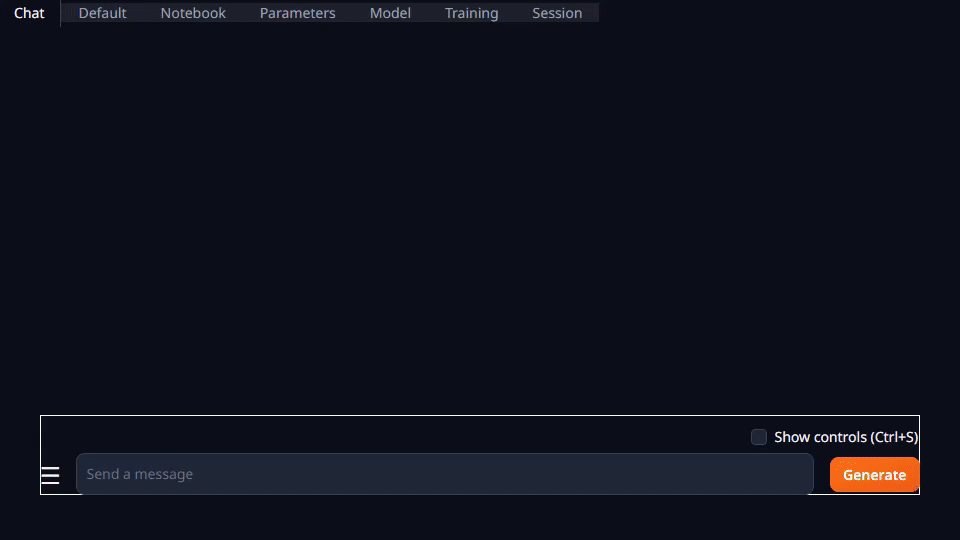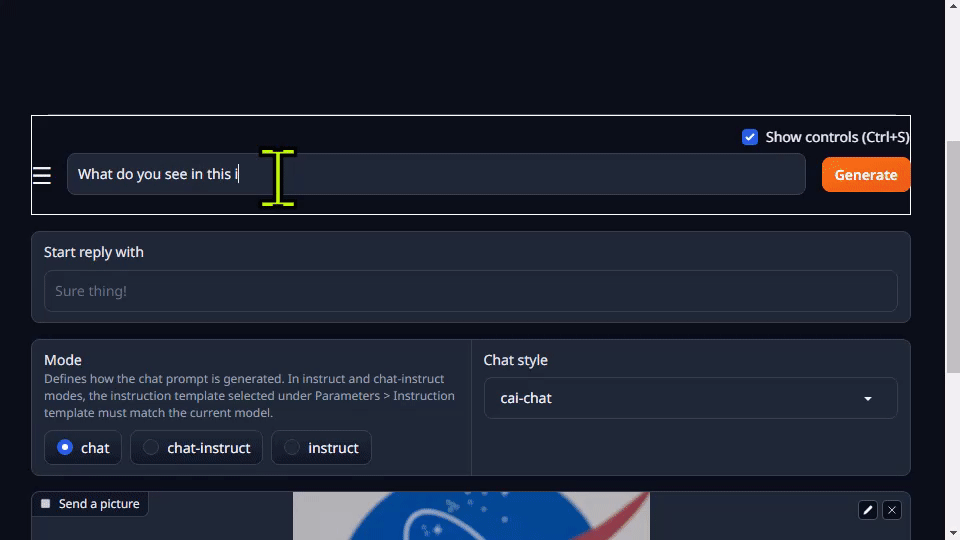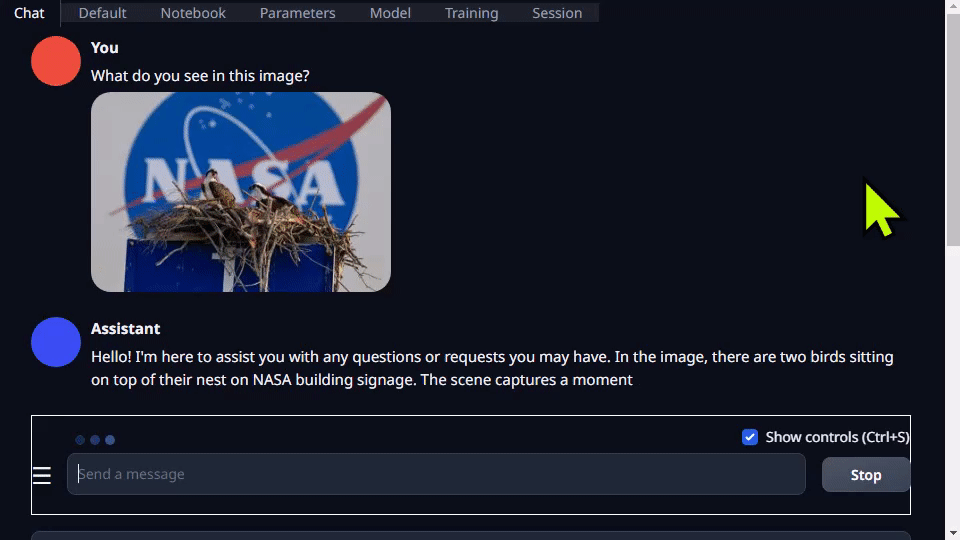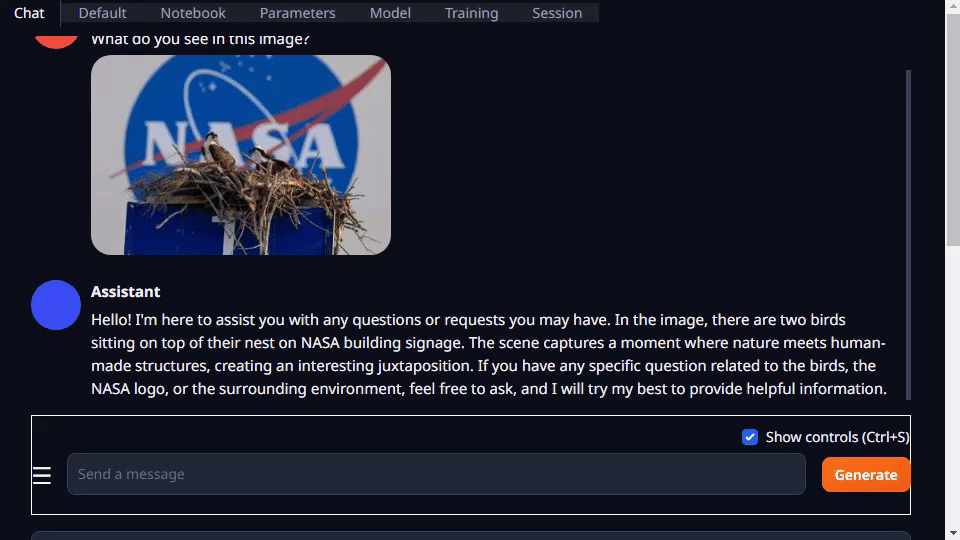
텍스트 생성-웹이 실행에 대한 자세한 내용은 Jetson Generative AI 랩 튜토리얼을 참조하십시오.
llamaspeak
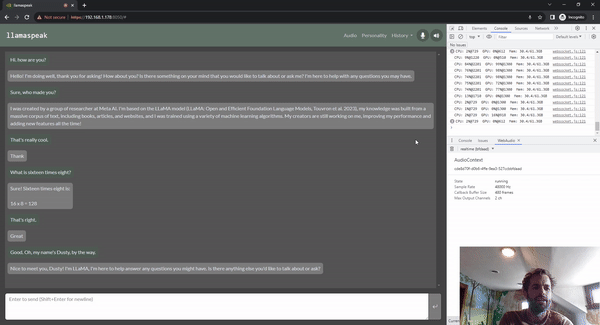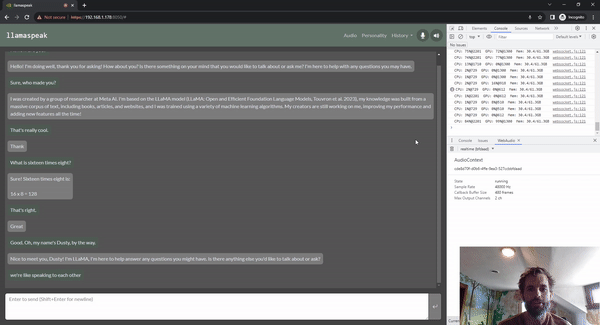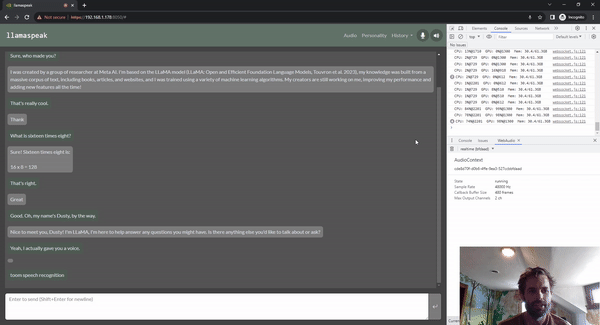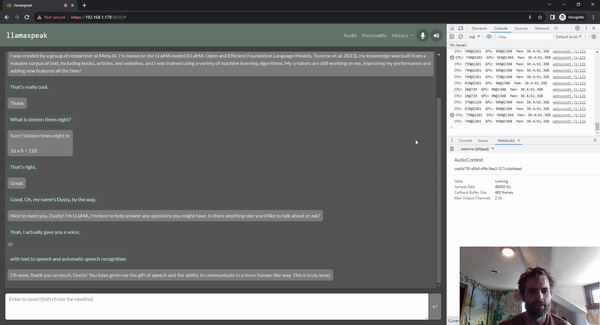
Llamaspeak는 라이브 NVIDIA Riva ASR/TTS를 사용하는 대화형 채팅 애플리케이션으로, 로컬에서 실행 중인 LLM과 음성 대화를 수행할 수 있습니다. 현재 젯슨 컨테이너의 일부로 제공됩니다.
원활하고 끊김 없는 음성 대화를 수행하려면 LLM의 첫 번째 출력 토큰까지 걸리는 시간을 최소화하는 것이 중요합니다. 또한, 대화 중단을 처리하도록 설계되었기 때문에 사용자가 대화를 시작할 수 있으며, llamaspeak가 생성된 응답을 TTS로 처리하는 동안에도 대화를 시작할 수 있습니다. 컨테이너 마이크로서비스는 Riva, LLM, 채팅 서버에 사용됩니다.
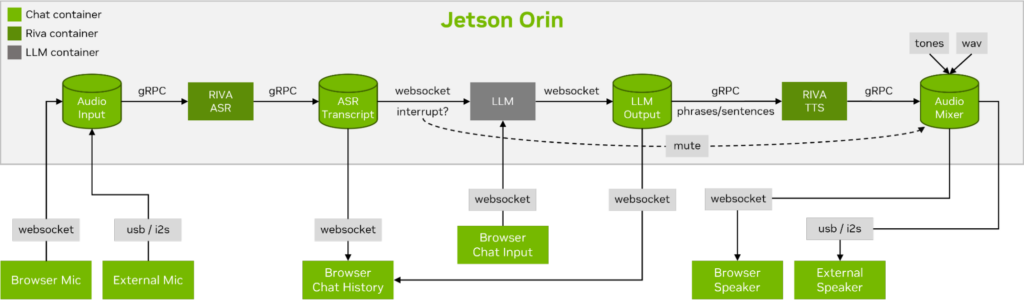
llamaspeak는 브라우저 마이크 또는 Jetson 장치에 연결된 마이크에서 지연 시간이 짧은 오디오 스트리밍을 지원하는 반응형 인터페이스를 갖추고 있습니다. 직접 실행하는 방법에 대한 자세한 내용은 jetson-containers 설명서를 참조하세요.
NanoOWL

비전 트랜스포머를 사용한 오픈 월드 로컬라이제이션(OWL-ViT)은 구글 리서치에서 개발한 개방형 어휘 감지를 위한 접근 방식입니다. 이 모델을 사용하면 해당 객체에 대한 텍스트 프롬프트를 제공하여 객체를 감지할 수 있습니다.
예를 들어 사람과 자동차를 감지하려면 클래스를 설명하는 텍스트를 시스템에 프롬프트합니다:
prompt = “a person, a car”이는 새로운 모델을 학습시킬 필요 없이 새로운 애플리케이션을 빠르게 개발하는 데 매우 유용합니다. 엣지에서 애플리케이션의 잠재력을 발휘하기 위해 유니티 팀은 이 모델을 NVIDIA TensorRT로 최적화하는 프로젝트인 NanoOWL을 개발하여 NVIDIA Jetson Orin 플랫폼에서 실시간 성능을 확보했습니다(Jetson AGX Orin에서 ~95FPS 인코딩 속도). 이 성능은 일반적인 카메라 프레임 속도를 훨씬 뛰어넘는 속도로 OWL-ViT를 실행할 수 있음을 의미합니다.
또한 이 프로젝트에는 새로운 트리 감지 파이프라인이 포함되어 있어 가속화된 OWL-ViT 모델을 CLIP과 결합하여 모든 수준에서 제로 샷 감지 및 분류를 수행할 수 있습니다. 예를 들어 얼굴을 감지하여 행복 또는 슬픔으로 분류하려면 다음 프롬프트를 사용합니다:
prompt = “[a face (happy, sad)]”얼굴을 감지한 다음 각 관심 영역에서 얼굴 특징을 감지하려면 다음 프롬프트를 사용합니다:
prompt = “[a face [an eye, a nose, a mouth]]”이들을 결합합니다:
prompt = “[a face (happy, sad)[an eye, a nose, a mouth]]”목록은 계속 이어집니다. 이 모델의 정확도는 일부 객체나 클래스에 더 적합할 수 있지만, 개발이 쉽기 때문에 다양한 프롬프트를 빠르게 시도해보고 자신에게 적합한지 확인할 수 있습니다. 여러분이 어떤 멋진 애플리케이션을 개발할지 기대됩니다!
무엇이든 세그먼트 모델
메타(Meta)는 이미지의 복잡성이나 컨텍스트에 관계없이 이미지 내의 객체를 정확하게 식별하고 세분화할 수 있도록 설계된 고급 이미지 세분화 모델인 Segment Anything 모델(SAM)을 출시했습니다.
공식 리포지토리에는 모델의 영향을 쉽게 확인할 수 있는 Jupyter 노트북이 있으며, Jetson 컨테이너에는 Jupyter Lab이 내장된 편리한 컨테이너가 제공됩니다.
NanoSAM

SAM(Segment Anything)은 포인트를 세그먼테이션 마스크로 전환할 수 있는 놀라운 모델입니다. 안타깝게도 실시간으로 실행되지 않기 때문에 엣지 애플리케이션에서 유용성이 제한됩니다.
이러한 한계를 극복하기 위해 최근 유니티는 SAM 이미지 인코더를 경량 모델로 추출하는 새로운 프로젝트인 NanoSAM을 출시했습니다. 또한 이 모델은 NVIDIA Jetson Orin 플랫폼에서 실시간 성능을 발휘할 수 있도록 NVIDIA TensorRT로 최적화합니다. 이제 별도의 교육 없이도 기존 바운딩 박스 또는 키포인트 감지기를 인스턴스 세분화 모델로 쉽게 전환할 수 있습니다.
무엇이든 추적 모델
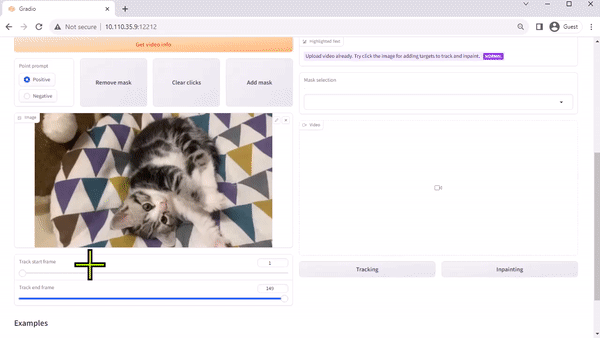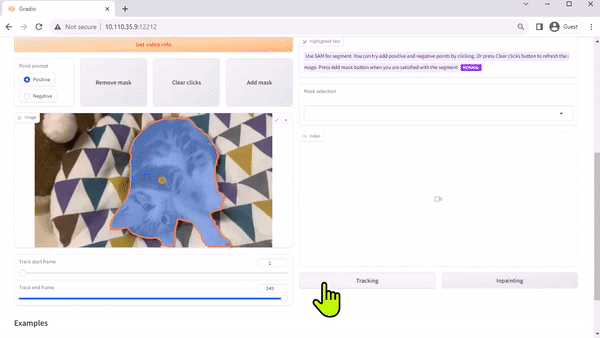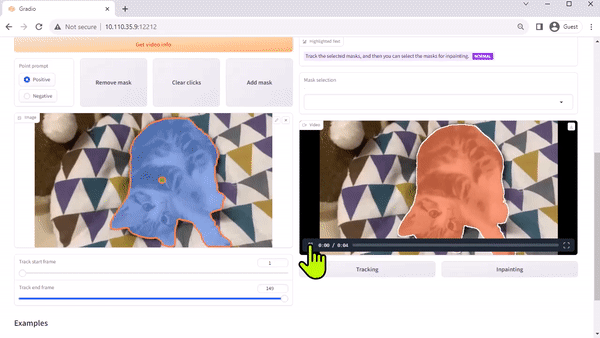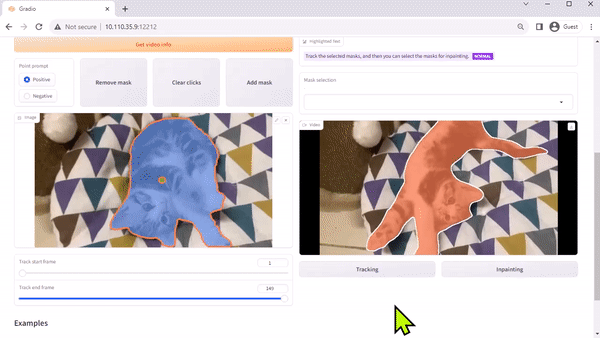
팀의 논문에서 설명한 것처럼, TAM(Track Anything Model)은 “무엇이든 세그먼트와 비디오의 만남”이라고 할 수 있습니다. 오픈 소스인 Gradio 기반 인터페이스를 사용하면 입력된 비디오의 프레임을 클릭하여 추적 및 세그먼트할 항목을 지정할 수 있습니다. 인페인팅을 통해 추적된 개체를 제거하는 추가 기능도 선보입니다.
NanoDB
이러한 벡터 데이터베이스는 엣지에서 데이터를 효과적으로 인덱싱하고 검색하는 것 외에도 내장된 컨텍스트 길이(Llama-2 모델의 경우 4096토큰)를 넘어서는 장기 메모리를 위한 검색 증강 생성(RAG)을 위해 LLM과 함께 사용되는 경우가 많습니다. 비전 언어 모델도 입력과 동일한 임베딩을 사용합니다.
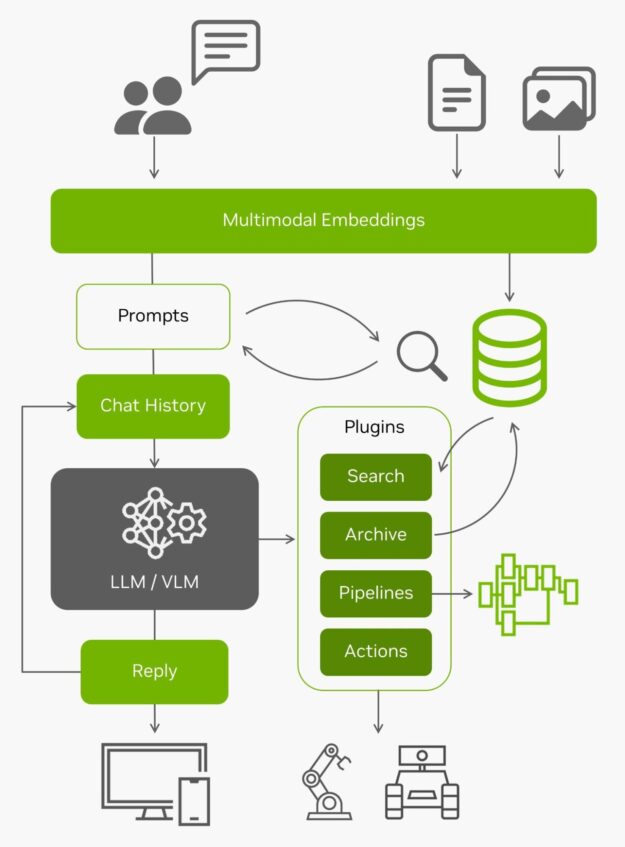
엣지에서 들어오는 모든 라이브 데이터와 이를 이해할 수 있는 기능을 통해 실제 세계와 상호 작용할 수 있는 에이전트가 됩니다. 자체 이미지 및 데이터 세트에 NanoDB를 사용해 실험하는 방법에 대한 자세한 내용은 실습 튜토리얼을 참조하세요.
결론
여기까지입니다! 수많은 흥미로운 생성형 AI 애플리케이션이 등장하고 있으며, 이 튜토리얼을 따라 Jetson Orin에서 쉽게 실행할 수 있습니다. 로컬에서 실행되는 생성형 AI의 놀라운 기능을 직접 확인하려면 Jetson Generative AI Lab을 살펴보세요.
Jetson에서 자체 생성형 AI 애플리케이션을 구축하고 아이디어를 공유하는 데 관심이 있다면 Jetson 프로젝트 포럼에서 제작물을 소개해 주세요.

2023년 11월 7일 화요일 오전 9시(태평양 표준시)에 진행되는 웨비나에 참여하여 이 게시물에서 논의된 여러 주제에 대해 자세히 알아보고 실시간 Q&A를 진행하세요!
- NVIDIA Jetson에서 LLM 및 VLM을 배포하기 위한 가속화된 API 및 양자화 방법
- NVIDIA TensorRT로 비전 트랜스포머 최적화하기
- 멀티모달 에이전트 및 벡터 데이터베이스
- NVIDIA Riva ASR/TTS와의 실시간 대화
관련 리소스
- GTC 세션: Jetson Edge AI 개발자의 날: NVIDIA Jetson 에코시스템으로 더 빠르게 제품 출시
- GTC 세션: Jetson Edge AI 개발자의 날: NVIDIA Nsight 개발자 도구를 사용하여 Jetson Orin 최대한 활용하기
- GTC 세션: 전문가와 소통하기: 자율 머신, 로보틱스 및 인텔리전트 비디오 분석을 위한 엣지에서의 AI
- 웨비나: NVIDIA 이머징 챕터 교육 시리즈 – Jetson AI 기초
- 웨비나: NVIDIA Jetson으로 산업용 엣지 AI 애플리케이션 강화하기
- 웨비나: Jetson의 NVIDIA Triton 추론 서버로 모델 배포를 간소화하고 AI 추론 성능을 극대화하세요.