
AI 워크로드가 확장되면서 GPU 간 빠르고 안정적인 통신은 학습뿐 아니라 대규모 추론 환경에서도 필수 요소로 자리잡고 있습니다. NVIDIA Collective Communications Library(NCCL)는 NVIDIA GPU와 PCIe, NVLink, Ethernet(RoCE), InfiniBand(IB) 등 다양한 인터커넥트를 지원하며, AllReduce, Broadcast, Reduce, AllGather, ReduceScatter와 같은 집단 연산을 고성능으로 처리합니다.
NCCL은 통신과 연산을 단일 커널로 통합해 지연 시간을 최소화하고, 분산 학습과 실시간 추론 시나리오 모두에 적합한 아키텍처를 제공합니다. 동적 토폴로지 감지 기능과 간결한 C 기반 API 덕분에, 개발자는 하드웨어 구성에 관계없이 손쉽게 노드 간 확장이 가능합니다.
이번 글에서는 추론 지연 시간 개선, 학습 안정성 강화, 개발자 가시성 향상 등을 포함한 최신 NCCL 2.27 릴리스의 주요 기능을 소개합니다. 자세한 내용은 NVIDIA/nccl GitHub 리포지토리에서 확인하실 수 있습니다.
새로운 성능 수준 실현
NCCL 2.27은 GPU 간 집단 통신의 지연 시간, 대역폭 효율성, 확장성 문제를 전반적으로 개선했습니다. 이러한 개선 사항은 학습과 추론 모두를 지원하며, 실시간 추론 파이프라인에 요구되는 초저지연과, 장애가 발생해도 안정적으로 운영 가능한 학습 환경을 지원하는 것이 특징입니다.
주요 릴리스 하이라이트로는 대칭 메모리를 사용하는 저지연 커널, NIC 직접 지원, NVLink 및 InfiniBand SHARP 지원이 포함됩니다.
대칭 메모리 기반 저지연 커널
이번 릴리스에서는 GPU 간 버퍼가 동일한 가상 주소에 매핑될 경우, NCCL은 대칭 메모리(symmetric memory)를 활용한 최적화된 커널을 실행해 집단 연산의 지연 시간을 크게 줄입니다. 이 커널은 모든 메시지 크기에 대해 지연 시간을 크게 줄이며, 작은 메시지의 경우 최대 7.6배까지 지연 시간을 감소시킵니다(그림 1 참조).
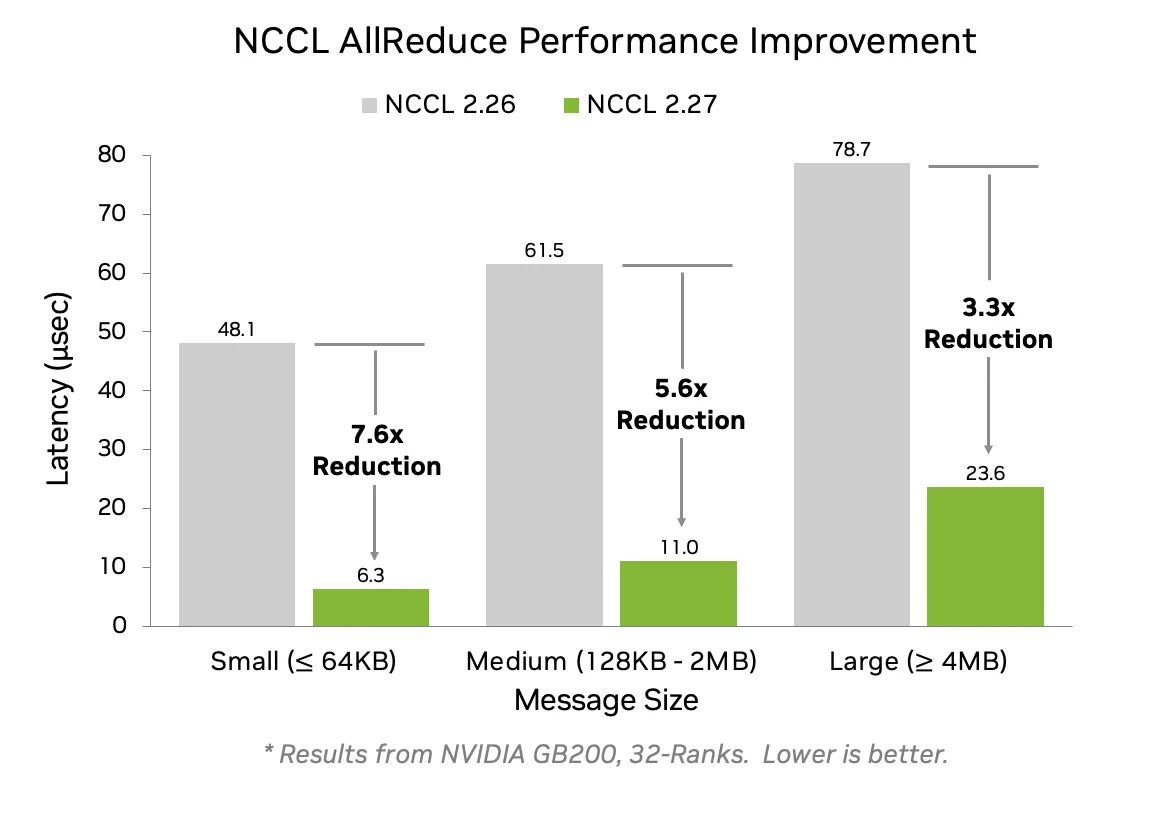
축소 연산은 FP32 누산기(FP8의 경우 NVLink Switch(NVLS) 시스템에서 FP16)를 사용하여 수행되며, AllReduce, AllGather, ReduceScatter와 같은 연산에서 정확성과 연산 결정성을 향상합니다.
대칭 메모리는 단일 NVLink 도메인 내에서의 NVLink 통신을 지원합니다. 이는 NVIDIA GB200 및 GB300 시스템의 최대 NVL72(72개 GPU) 또는 NVIDIA DGX 및 HGX 시스템의 NVL8(8개 GPU)까지 확장 가능합니다. NVL8 도메인 환경에서도 소형에서 중형 메시지 크기에 대해 최대 2.5배 향상된 성능을 확인할 수 있습니다. 테스트 방법에 대한 자세한 내용은 NCCL-Test 리포지토리를 참조하세요.
Direct NIC 지원
NCCL 2.27은 Direct NIC 구성을 지원하여 GPU 간 통신 확장 시 전체 네트워크 대역폭을 최대한 활용할 수 있도록 합니다. Grace Blackwell 플랫폼의 CX8 NIC와 NVIDIA Blackwell GPU는 PCIe Gen6 x16을 통해 최대 800 Gb/s의 네트워크 대역폭을 지원합니다. 반면 Grace CPU는 PCIe Gen5까지만 지원되어 최대 400 Gb/s로 제한됩니다.
이를 해결하기 위해 CX8 NIC는 두 개의 가상 PCIe 트리를 제공합니다. 하나의 트리에서는 NVIDIA CX8 NIC 데이터 직통 기능(PF)이 PCIe Gen6 x16 링크를 통해 GPU PF와 직접 연결되어 CPU를 우회하며 대역폭 병목 현상을 피할 수 있습니다(그림 2 참조). 다른 트리에서는 일반 NIC PF가 CPU 루트 포트에 연결됩니다.
이 구성은 GPUDirect RDMA 및 관련 기술이 CPU와 GPU 간 대역폭을 포화시키지 않고도 최대 800 Gb/s의 대역폭을 달성할 수 있도록 하며, 하나의 CPU에 여러 GPU가 연결된 환경에서 특히 중요합니다. Direct NIC는 고처리량 추론 및 학습 워크로드에 필요한 고속 네트워킹을 가능하게 하는 핵심 요소입니다.

NVLink 및 InfiniBand SHARP 지원
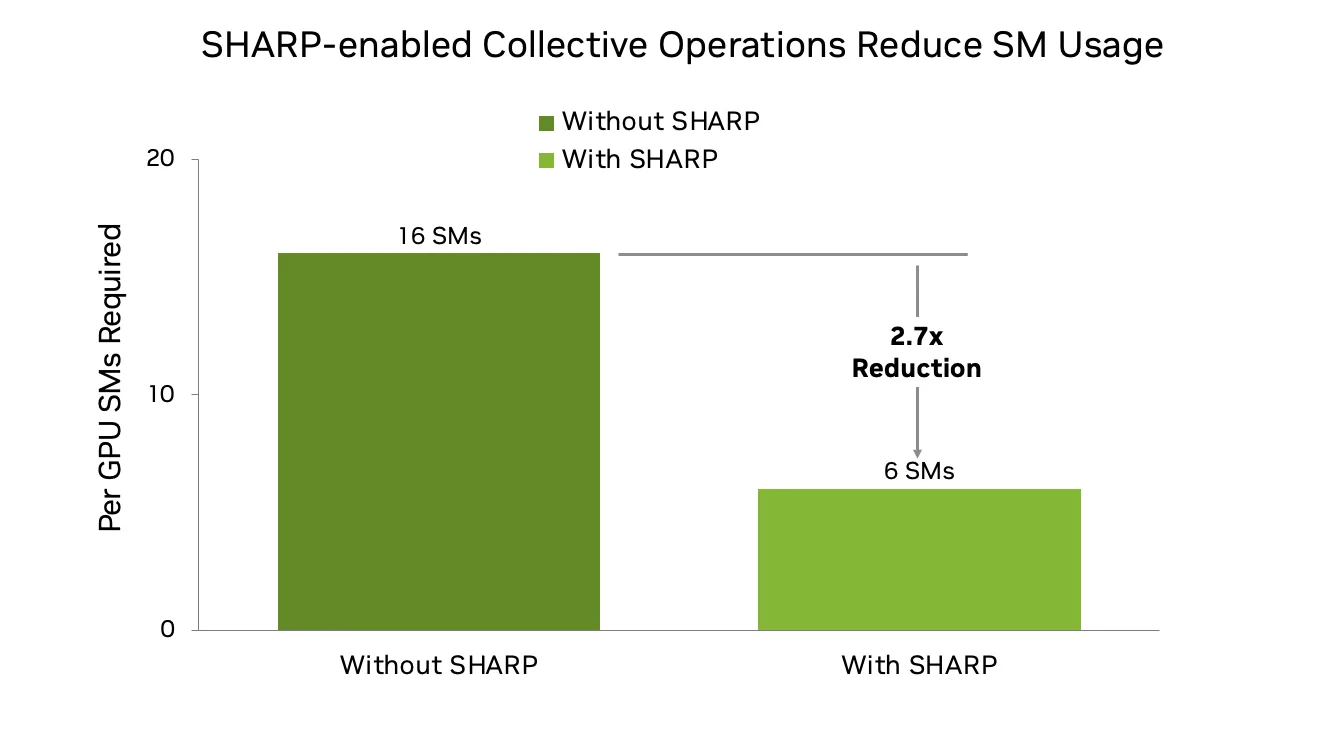
NCCL 2.27은 NVLink 및 InfiniBand(IB) 패브릭 모두에서 SHARP(Scalable Hierarchical Aggregation and Reduction Protocol)를 지원하며, 연산 집약적인 축소 작업을 네트워크 수준으로 오프로드할 수 있습니다. 이번 릴리스에서는 AllGather(AG)와 ReduceScatter(RS) 연산에 SHARP 지원이 추가되어 NVLink SHARP와 IB SHARP를 함께 사용하는 경우, GPU에서 네트워크로 연산을 직접 수행할 수 있습니다.
이 기능은 특히 대규모 LLM 학습에 유리하며, AG와 RS는 연산과 통신 간 오버랩을 극대화할 수 있기 때문에 AllReduce보다 더 선호되는 방식입니다. 기존의 링 기반 구현에서는 16개 이상의 SM을 사용하는 반면, NVLink 및 IB SHARP를 활용할 경우 필요한 SM 수를 6개 이하로 줄일 수 있어, 모델 연산에 더 많은 자원을 할당하고 전체 학습 효율을 향상시킬 수 있습니다. 그 결과, 1,000개 이상의 GPU를 사용하는 환경에서도 더 나은 확장성과 성능을 실현할 수 있습니다.
대규모 학습에서의 복원력 향상: NCCL Shrink
NCCL 2.27은 Communicator Shrink 기능을 도입하여 분산 학습 환경에서 GPU 장애 발생 시에도 학습을 중단하지 않고 유연하게 대응할 수 있도록 지원합니다. 이 기능은 학습 중 오류가 발생한 GPU나 더 이상 필요하지 않은 GPU를 동적으로 제외할 수 있으며, 다음 두 가지 모드를 제공합니다:
- 기본 모드(Default mode): 계획된 재구성을 위한 모드로, 모든 연산이 완료된 이후 토폴로지를 수정할 수 있습니다.
- 오류 모드(Error mode): 예기치 않은 장치 오류 발생 시 현재 진행 중인 연산을 자동으로 중단하고 통신기를 재구성합니다.
NCCL Shrink는 개발자에게 다음과 같은 이점을 제공합니다:
- 통신기를 동적으로 재구성하여 학습을 중단 없이 지속할 수 있습니다.
- 구성 가능한 자원 공유 기능을 통해 기존 자원을 재사용할 수 있습니다.
- 장치 오류를 최소한의 중단으로 우아하게 처리할 수 있습니다.
계획된 재구성과 오류 복구 시나리오에서의 NCCL Shrink 사용 예시는 다음과 같습니다:
// Planned reconfiguration: exclude a rank during normal operation
NCCLCHECK(ncclGroupStart());
for (int i = 0; i < nGpus; i++) {
if (i != excludedRank) {
NCCLCHECK(ncclCommShrink(
comm[i], &excludeRank, 1,
&newcomm[i], NULL, NCCL_SHRINK_DEFAULT));
}
}
NCCLCHECK(ncclGroupEnd());
// Error recovery: exclude a rank after a device failure
NCCLCHECK(ncclGroupStart());
for (int i = 0; i < nGpus; i++) {
if (i != excludedRank) {
NCCLCHECK(ncclCommShrink(
comm[i], &excludeRank, 1,
&newcomm[i], NULL, NCCL_SHRINK_ABORT));
}
}
NCCLCHECK(ncclGroupEnd());
개발자를 위한 추가 기능
이번 릴리스에서는 개발자를 위한 기능으로 대칭 메모리 API와 향상된 프로파일링 기능이 포함되어 있습니다.
대칭 메모리 API
대칭 메모리는 NCCL 2.27의 핵심 기능 중 하나로, 고성능 저지연 집합 연산을 가능하게 합니다. 모든 rank에서 메모리 버퍼가 동일한 가상 주소에 할당될 경우, NCCL은 최적화된 커널을 실행하여 동기화 오버헤드를 줄이고 대역폭 효율성을 향상시킬 수 있습니다.
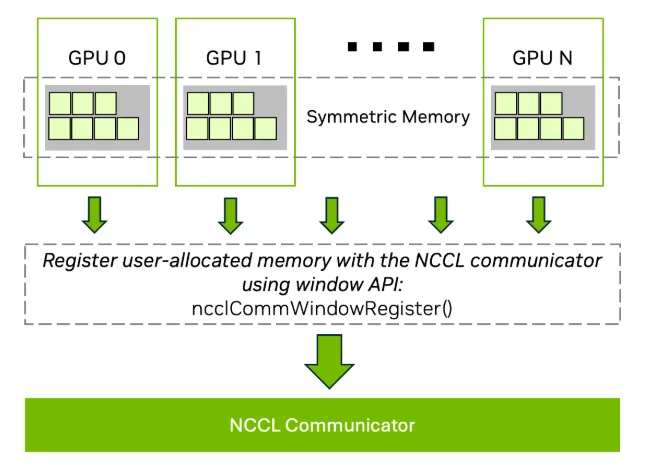
이를 지원하기 위해, NCCL은 대칭 메모리를 집합적으로 등록할 수 있는 window API를 도입하였습니다.
ncclCommWindowRegister(ncclComm_t comm, void* buff, size_t size,
ncclWindow_t* win, int winFlags);
ncclCommWindowDeregister(ncclComm_t comm, ncclWindow_t win);
ncclCommWindowRegister는 사용자가 할당한 메모리를 NCCL 통신기에 등록하는 함수입니다. 해당 메모리는 반드시 CUDA Virtual Memory Management(VMM) API를 사용하여 할당되어야 합니다.symmetric kernel최적화를 활성화하려면winFlags에NCCL_WIN_COLL_SYMMETRIC플래그를 포함해야 합니다.- 모든 rank는 동일한 오프셋을 갖는 버퍼를 제공해야 하며, 이를 통해 대칭 주소 공간을 보장합니다.
- 등록 해제(
ncclCommWindowDeregister)는 로컬 연산이며, 관련된 모든 집합 연산이 완료된 이후에만 호출되어야 합니다.
ncclCommWindowRegister는 집합적이고(blocking) 동기적인 연산이므로, 하나의 스레드에서 여러 GPU를 제어하는 경우 ncclGroupStart와 ncclGroupEnd로 감싸야 합니다.
대칭 메모리를 사용하지 않으려면 NCCL_WIN_ENABLE=0으로 설정하여 해당 기능을 완전히 비활성화할 수 있습니다.
그림 4는 NCCL window API를 사용하여 여러 GPU에 걸쳐 대칭 메모리를 등록하는 과정을 보여줍니다. 가상 주소를 정렬함으로써, NCCL은 저지연 최적화 커널을 활용하여 집합 연산의 성능을 향상시킬 수 있습니다.
향상된 프로파일링
NCCL 2.27은 통신 성능 진단을 위한 정밀하고 효율적인 계측 기능을 제공하기 위해 프로파일링 인프라를 대폭 강화하였습니다.
프록시 이벤트의 통합
기존에는 네트워크 프록시 스레드의 진행 상황을 추적하기 위해 ncclProfileProxyOp와 ncclProfileProxyStep 이벤트를 함께 사용하였습니다. 이 이벤트들은 서로 다른 수준의 세분성을 제공했지만, 계측 지점이 중복되는 문제가 있었습니다. NCCL 2.27에서는 이러한 모델을 간소화하고 일관성 있게 정리하여, 중복된 ProxyOp 상태를 제거하고 ncclProfilerProxyOpInProgress_v4라는 통합 상태를 도입하였습니다. 이를 통해 세부 정보를 유지하면서도 프로파일러의 오버헤드를 줄이고, 통신 진행 상황을 더 명확하게 파악할 수 있도록 하였습니다.
또한, 송신 rank가 수신자의 clear-to-send 신호를 기다리는 시간을 나타내는 새로운 ProxyStep 이벤트 상태인 ncclProfilerProxyStepPeerWait_v4가 추가되었습니다. 이 상태는 기존 기능을 통합하면서 중복을 최소화합니다.
GPU 커널 이벤트 정확도 향상
타이밍 정확도를 높이기 위해 NCCL은 이제 GPU의 내부 글로벌 타이머를 사용한 GPU 타임스탬프 전파를 지원합니다. 이전에는 GPU 작업 카운터를 기반으로 한 호스트 측 이벤트 타이밍에 의존했으며, 이는 지연이나 커널 압축 등의 아티팩트에 취약했습니다. 이제 GPU 자체가 시작 및 종료 시점을 기록하고 내보내므로, 프로파일러 도구는 GPU로부터 직접 커널 실행 시간을 정밀하게 파악할 수 있습니다. 단, CPU 시간으로 변환하려면 보정 또는 보간 처리가 필요합니다.
네트워크 플러그인 이벤트 업데이트
NCCL 프로파일러 인터페이스는 이제 recordEventState를 통해 네트워크 정의 이벤트의 상태 업데이트를 지원합니다. 이 기능은 재전송 신호나 혼잡 지표 등 실시간 네트워크 피드백을 성능 타임라인에 반영하는 데 유용합니다.
기타 향상 사항
- 프로파일러 초기화: 통신기 이름, ID, 노드 수, rank 수, 디버그 수준 등 메타데이터를 보고합니다.
- 채널 리포팅: 실제 사용된 채널 수를 기준으로 보고하며, P2P 연산도 포함됩니다.
- 통신기 태깅:
ncclConfig_t에 통신기 이름 필드를 추가하여, 프로파일된 연산과 해당 통신기 간의 연관성을 높였습니다.
이러한 기능들은 NCCL 프로파일러 플러그인 인터페이스의 정확도를 높이며, 대규모 AI 워크로드의 진단 및 최적화를 위한 통신 구조, GPU 타이밍, 네트워크 동작에 대한 인사이트를 강화합니다.
자세한 내용은 NVIDIA/nccl GitHub 리포지토리에서 확인할 수 있습니다.
향후 지원 예정 기능
향후 다음과 같은 기능들이 제공될 예정입니다.
- 데이터센터 간 통신: 지리적으로 분산된 데이터센터 간 집합 연산을 위한 초기 지원 제공
- 다중 NIC 플러그인 가시성: 여러 네트워크 구성을 동시에 활용 가능
NCCL 2.27 시작하기
NCCL 2.27의 새로운 기능을 활용하여 분산 추론 및 학습 워크플로우를 더욱 낮은 지연 시간, 향상된 장애 복원력, 심화된 관찰 가능성으로 개선할 수 있습니다.
자세한 문서, 소스 코드, 기술 지원 정보는 NVIDIA/nccl GitHub 저장소를 참고하시기 바랍니다. 아키텍처에 맞춘 NCCL 설정 방법은 NCCL 공식 문서를 참조하십시오.
관련 자료
- GTC 세션: NCCL – 멀티 GPU AI를 구현하는 GPU 간 통신 라이브러리
- GTC 세션: LLM 학습 고도화 – NeMo를 통한 안정적인 학습 구현
- GTC 세션: 양날의 검 – 양자화, 가지치기, 지식 증류를 활용한 비용 효율적인 LLM 추론
- NGC 컨테이너: NVIDIA MLPerf 추론 환경
- SDK: NCCL
- 웨비나: NVIDIA AI Enterprise를 활용한 컨택센터 AI 워크플로우 가속화



