
GPU는 초기에 비디오 게임에서 3D 그래픽을 렌더링하는 데 특화되어 있었으며 주로 선형 대수 계산을 가속화했습니다. 오늘날 GPU는 AI 혁명의 중요한 구성 요소가 되었습니다.
이제 우리는 이러한 기계에 의존하여 딥 러닝 워크로드를 처리하고, 방대하고 복잡한 반구조화된 데이터세트를 고속으로 처리할 수 있습니다.
그러나 AI 기반 솔루션의 수요가 급증함에 따라 하이엔드 GPU에 액세스하기가 점점 더 어려워지고 있습니다. 자체 사용 사례를 위해 솔루션을 설정하고 구성하는 데 드는 투자 또한 마찬가지입니다.
NVIDIA DGX Cloud
NVIDIA DGX Cloud는 AI 훈련의 필요성을 해결하기 위해 사용자가 인프라를 직접 소싱, 설정, 구성하는 번거로움 없이 액세스할 수 있는 최첨단 가속 컴퓨팅 리소스를 제공합니다. 이는 딥 러닝 패러다임으로 수행할 수 있는 작업의 한계를 확장하려는 AI 팀에게 중요한 전환점이 됩니다.
단순히 클라우드에서 AI 슈퍼컴퓨팅에 액세스하는 것 외에도 AI 애플리케이션의 효율성 및 성능을 향상시키도록 코드를 구성하고 이를 중심으로 컴퓨팅해야 합니다. NVIDIA의 경험에 의하면 이를 수행하는 가장 좋은 방법은 인프라, 코드, 데이터, 모델의 교차점인 AI 오케스트레이션을 사용하는 것입니다.
Flyte 워크플로우를 NVIDIA DGX Cloud와 통합할 수 있는 Union의 NVIDIA DGX Agent를 소개합니다. GPU 사용량이 많은 워크로드의 복잡성과 비용을 관리하려는 팀을 위해 프로덕션 AI 워크플로우를 대중화하는 것이 협업의 목표입니다.
Union의 멀티 클라우드 패브릭과 Flyte라는 핵심 오픈 소스 오케스트레이터를 사용하여 AI 워크플로우에서 컨테이너화, 프로덕션화, 반복 작업으로 인한 골치 아픈 문제를 코드의 한 줄 구성 변경으로 바꾸는 방법을 보여 드리겠습니다.
워크플로우가 중요한 이유
Union은 ML 엔지니어와 데이터 사이언티스트가 데이터의 가치를 제공하는 데 집중할 수 있도록 프로덕션급 AI 오케스트레이션 중 낮은 수준의 세부 사항을 단순화하고 추상화하는 데 중점을 둡니다.
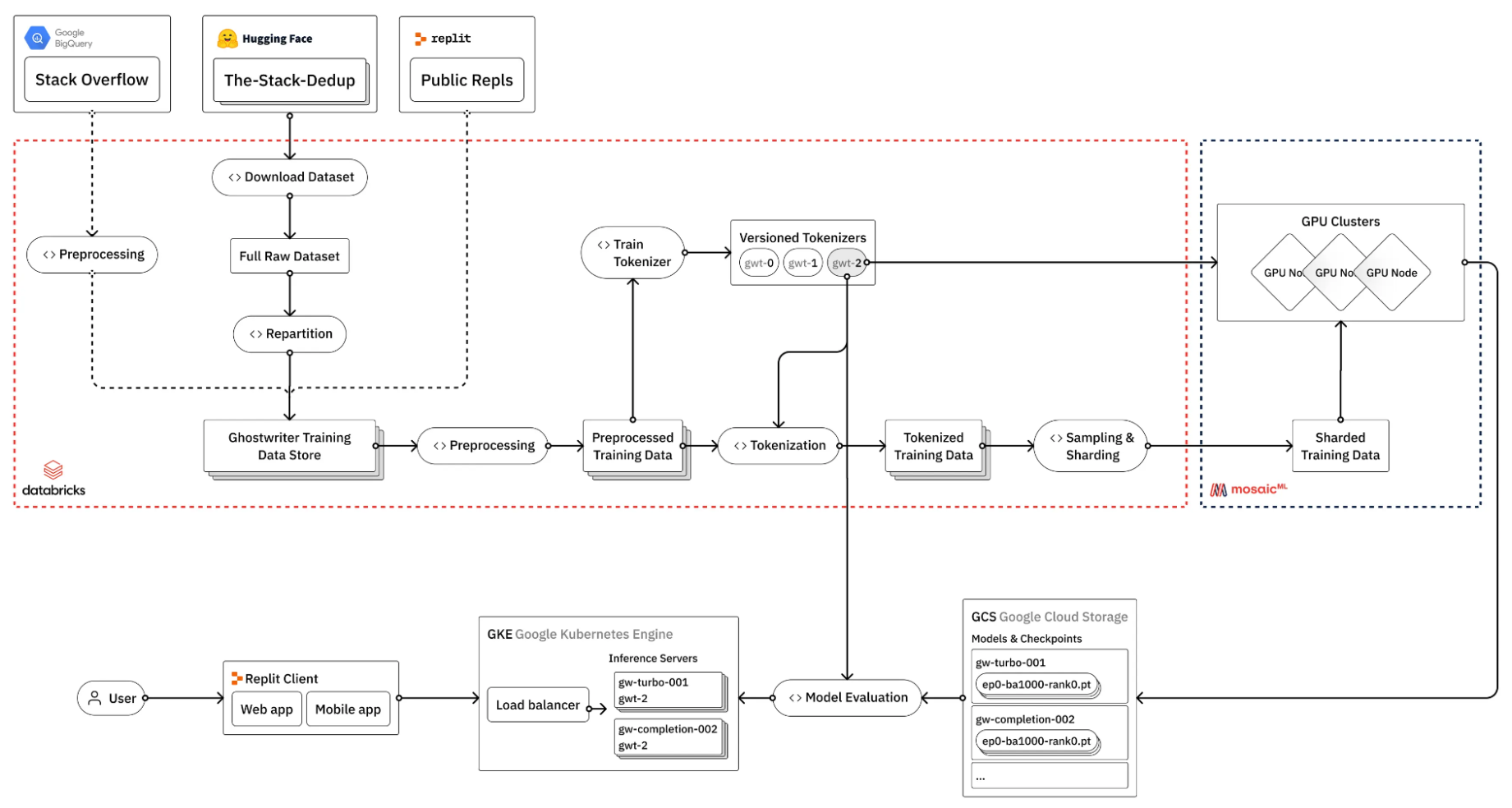
그림 1에 표시된 것처럼 Repl.it이 코딩 전문가 모델에 맞게 LLM을 미세 조정하기 위해 수행하는 작업을 살펴보세요.
(출처: 거대 언어 모델(LLM)을 직접 훈련하는 방법)
그림 1은 LLM을 미세 조정하는 프로세스에 많은 단계가 포함되며, 그중 많은 단계에서 GPU가 반드시 필요한 것은 아님을 보여줍니다. 그렇다면 이러한 파이프라인의 복잡성은 어떻게 관리할 수 있을까요?
AI 모델 개발에서 워크플로우는 데이터 및 모델 관리의 복잡성을 관리하기 위한 표준이 되었습니다.
Union 공동 창립자가 Lyft에서 Linux Foundation 오픈 소스 프로젝트로 시작한 Flyte는 데이터 및 머신 러닝 파이프라인의 재현 및 확장을 돕는 것을 목표로 합니다. 이를 가능하게 하는 몇 가지 핵심 기능은 다음과 같습니다.
- 작업: 작업을 데이터 또는 머신 러닝 파이프라인의 개별 단계로 생각하세요. 각 단계에는 자체 입력 및 출력이 있습니다. 여기에는 훈련, 데이터 변환, 예측 등이 포함됩니다.
- 워크플로우: 이러한 단계를 함께 연결하면 워크플로우가 됩니다. 워크플로우는 각 작업이 적시에 추가되어야 하는 재료인 레시피와 같습니다.
- 선언적 리소스 관리: 좀 더 기술적인 부분으로 각 작업에는 자체 리소스 요구 사항이 있습니다. Flyte에게 “이 작업을 수행하는 데 이 정도의 컴퓨팅 성능이 필요합니다.”라고 말하는 것과도 같습니다.
- 에이전트: 에이전트는 Flyte를 DGX Cloud와 같은 외부 서비스에 연결하여 Flyte의 핵심 기능 외부의 서비스를 쉽게 호출할 수 있는 중재자입니다.
다음 코드 예제에서는 이러한 요소가 모두 높은 수준에서 함께 상호작용을 하는 방식을 보여줍니다.
from collections import NamedTuple
import pandas as pd
import torch.nn as nn
from flytekit import task, workflow, Resources
from flytekit.extras.accelerators import T4
from flytekitplugins.spark import Databricks
@task(task_config=Databricks(...))
def create_data() -> pd.DataFrame:
...
@task(requests=Resources(gpu="4"), accelerator=T4)
def train_model(data: pd.DataFrame) -> nn.Module:
...
@workflow
def model_training_pipeline() -> nn.Module:
train_data, test_data = get_data()
model = train_model(data=train_data)
return model이 예제에서는 Databricks 작업 구성을 사용하여 훈련 데이터를 생성하는 동시에 Flyte의 기본 가속기 선언 구문을 사용하는 4개의 NVIDIA T4 Tensor 코어 GPU를 사용하여 Databricks 클러스터에서 create_data 작업을 실행합니다.
Flyte에서 Repl.it 미세 조정 파이프라인은 다음과 같습니다.
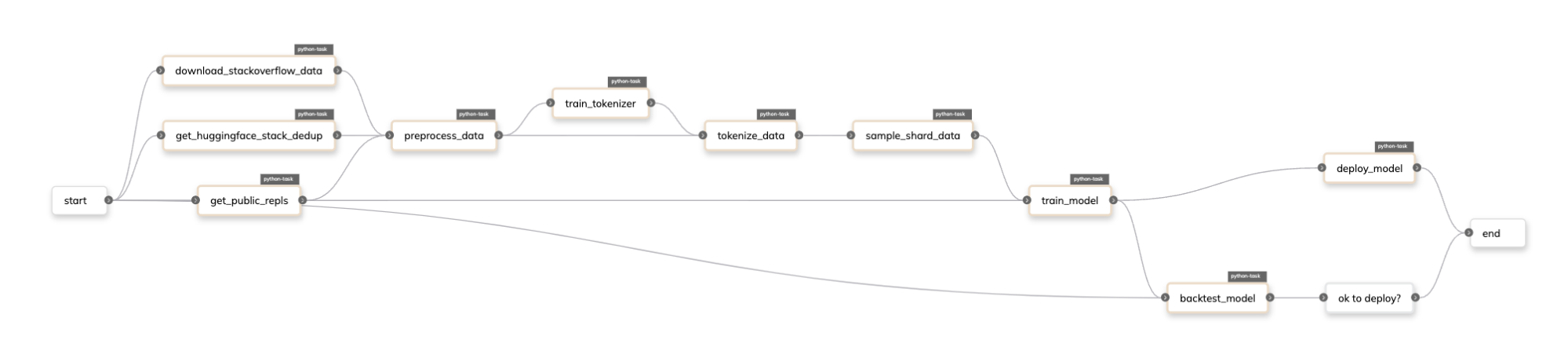
Union의 NVIDIA DGX Agent 소개
Mixtral 8x7b 모델을 미세 조정한다고 가정해 보겠습니다. Flyte는 워크로드를 위해 GPU를 프로비저닝할 수 있지만, Amazon Web Service, Google Cloud Platform 및 Microsoft Azure와 같은 기존 클라우드 제공업체에서는 특정 GPU 유형의 가용성이 부족하여 여전히 제약이 있을 수 있습니다.
DGX Cloud를 활용하여 이 제약을 해결하려면 다음을 수행해야 합니다.
- 로컬 또는 클라우드 기반 IDE에서 모델 훈련 파이프라인을 개발합니다.
- 코드 및 종속성을 컨테이너화합니다.
- 이미지를 NVIDIA 컨테이너 레지스트리에 푸시합니다.
- 클라우드에서 문제가 발생할 가능성이 있는 경우 코드를 디버깅합니다.
- 2단계로 돌아가 오류를 해결하고 이 과정을 반복합니다.
Union을 사용하면 이러한 어려운 작업을 훨씬 원활하게 할 수 있습니다. NVIDIA는 한 줄 구성 코드로 DGX Cloud의 기능을 손쉽게 활용하여 복잡한 작업을 간단한 프로세스로 전환할 수 있는 도구를 제공합니다.
Mixtral 8x7B 모델을 미세 조정하는 fine_tune이라는 Flyte 작업이 있다고 가정해 보겠습니다.
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
BitsAndBytesConfig,
TrainingArguments,
)
from trl import SFTTrainer
@task
def fine_tune(dataset_name: str, output_dir: str):
# load model, tokenizer, and dataset
model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mixtral-8x7B-v0.1",
quantization_config=BitsAndBytesConfig(load_in_4bit=True),
device_map="auto",
torch_dtype=torch.bfloat16,
)
tokenizer = AutoTokenizer.from_pretrained(
"mistralai/Mixtral-8x7B-v0.1",
use_fast=True
)
dataset = load_dataset(dataset_name, split="train")
# configer training arguments and trainer
training_args = TrainingArguments(...)
trainer = SFTTrainer(...)
# train and save the model
trainer.train()
trainer.save_model(output_dir)Flyte 및 Union의 NVIDIA DGX Agent를 사용하려면 에이전트 플러그인과 함께 제공되는 dgx_image_spec 파일에 필요한 DGXConfig 작업 구성 및 종속성을 추가합니다.
from flytekitpligins.dgx import DGXConfig, dgx_image_spec
fine_tuning_image_spec = dgx_image_spec.with_packages([
"accelerate", "datasets", "torch", "transformers", "trl",
])
@task(
task_config=DGXConfig(instance="dgxa100.80g.8.norm"),
container_image=fine_tuning_image_spec,
)
def fine_tune(dataset_name: str, output_dir: str):
... 코드 예제에서는 훈련에 사용할 수 있는 8개의 NVIDIA A100 Tensor 코어 GPU가 포함된 단일 노드인 dgxa100.80g.8.norm 인스턴스를 사용합니다. 멀티 노드 훈련의 경우, 에이전트 플러그인은 워크로드를 더욱 확장할 수 있는 DGXTorchElastic 구성 클래스도 제공합니다.
또한 Union의 NVIDIA DGX Agent는 클라우드 기반 blob 스토리지(Amazon S3, GCS, Azure Blob Storage)의 데이터를 DGX Cloud의 blob 스토리지 시스템으로 이동하기 위한 유틸리티도 제공합니다. Flyte의 캐싱 기능과 함께 데이터 이그레스 비용을 관리하여 비용을 제어할 수 있습니다. 자세한 내용은 Union AI 플랫폼에 대한 Union 문서를 확인하세요.
지금 최첨단 가속 컴퓨팅에 액세스하세요!
AI를 개발하면서 GPU 부족이나 설정 문제로 어려움을 겪고 있다면 Union의 멀티 클라우드 패브릭을 조금 더 자세히 살펴보는 것이 좋습니다. 획득 프로세스를 단순화하도록 설계되었기 때문에 하드웨어 또는 클라우드 서비스를 관리하는 데 드는 과정을 줄이고 개발에 더 집중할 수 있습니다.
AI 프로젝트를 간소화할 준비가 되셨나요? Union 팀에 연락하여 코드를 자세히 살펴보고 업무를 간소화하세요. 적합한 도구를 사용하여 이러한 AI 문제를 정면 돌파하세요.