
거대 언어 모델(LLM)은 방대한 양의 텍스트로 학습하여 다양한 작업 및 분야에 대해 유창하고 일관된 텍스트를 생성하는 기능으로 자연어 처리(NLP)를 혁신했습니다. 그러나 LLM을 맞춤화하는 것은 까다로운 작업이며, 시간과 연산 비용이 많이 드는 훈련 프로세스 일체가 필요한 경우가 많습니다. 또한 LLM을 훈련하려면 다양하고 대표성 있는 데이터세트가 필요한데, 이를 확보하고 선별하기가 어려울 수 있습니다.
기업은 어떻게 전체 훈련 비용을 지불하지 않고 LLM의 성능을 활용할 수 있을까요? 유망한 솔루션 중 하나는 LoRA(Low-Rank Adaptation)입니다. 다양한 NLP 작업 및 도메인에서 파인 튜닝하는 것과 비슷하거나 더 나은 성능을 달성하면서 훈련 가능한 매개 변수의 수, 메모리 요구 사항 및 훈련 시간을 크게 줄일 수 있는 파인 튜닝 방법입니다.
이 게시물에서는 LoRA의 기본 원리와 구현에 대해 설명하고 몇 가지 애플리케이션 및 이점을 살펴봅니다. 또한 LoRA를 지도 파인 튜닝 및 프롬프트 엔지니어링과 비교하고 각각의 장점과 한계를 논의합니다. LoRA 조정 모델의 훈련 및 추론에 대한 실용적인 지침을 간략하게 설명합니다. 마지막으로 NVIDIA TensorRT-LLM을 사용하여 NVIDIA GPU에서 LoRA 모델의 배포를 최적화하는 방법을 보여줍니다.
튜토리얼 사전 요건
이 튜토리얼을 최대한 활용하려면 LLM 훈련 및 추론 파이프라인에 대한 기본 지식과 더불어 다음 사항이 필요합니다.
- 선형 대수에 대한 기본 지식
- Hugging Face 등록 사용자 액세스 및 트랜스포머 라이브러리에 대한 전반적인 지식
- NVIDIA/TensorRT-LLM 최적화 라이브러리
- TensorRT-LLM 백엔드가 포함된 NVIDIA Triton 추론 서버
LoRA란 무엇인가요?
LoRA는 LLM 아키텍처의 각 계층에 저계수 행렬을 도입하고 이러한 행렬만 훈련하면서 원본 LLM 가중치를 동결 상태로 유지하는 파인 튜닝 방법입니다. NVIDIA NeMo에서 지원되는 LLM 맞춤화 도구 중 하나입니다(그림 1).
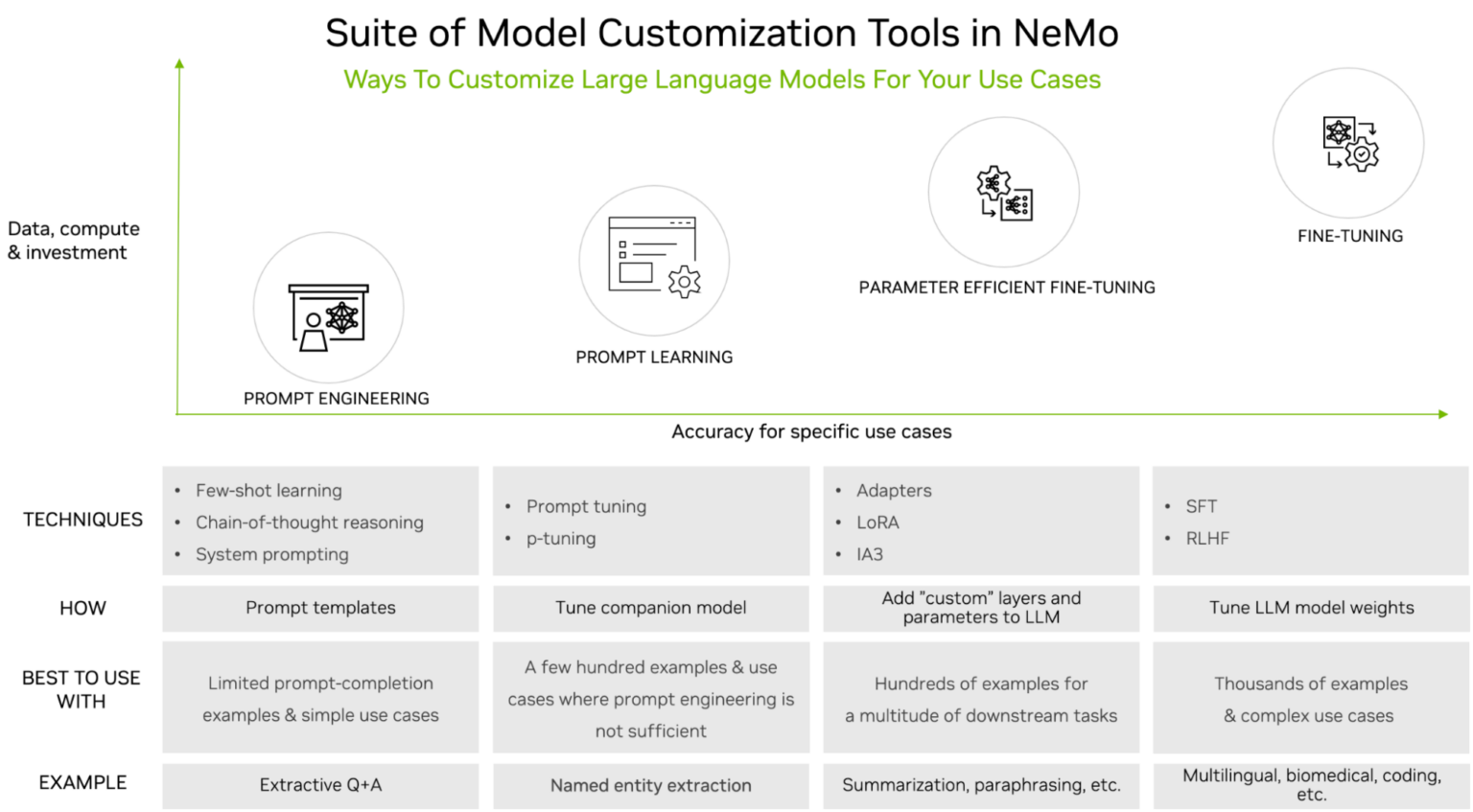
LLM은 강력하지만 특히 엔터프라이즈 또는 도메인별 사용 사례에 사용되는 경우 맞춤화가 필요한 경우가 많습니다. 단순 프롬프트 엔지니어링부터 지도 파인 튜닝(SFT)까지 다양한 조정 옵션이 있습니다. 조정 옵션의 선택은 일반적으로 필요한 데이터세트의 크기(프롬프트 엔지니어링의 경우 최소, SFT의 경우 최대) 및 연산 가용성을 기반으로 합니다.
LoRA 조정은 매개 변수 효율적 파인 튜닝(PEFT)이라는 조정 제품군의 한 유형입니다. 이러한 기술은 중간쯤에 있는 접근법입니다. 프롬프트 엔지니어링에 비해 더 많은 훈련 데이터와 연산을 필요로 하지만 정확도가 훨씬 높습니다. 공통된 테마는 원본 LLM을 변경하지 않고 유지하면서 소수의 매개 변수 또는 계층을 도입한다는 것입니다.
PEFT는 더 적은 데이터와 연산 리소스를 사용하면서 SFT에 필적하는 정확도를 달성하는 것으로 입증되었습니다. 다른 조정 기술에 비해 LoRA에는 몇 가지 장점이 있습니다. 새 매개 변수만 몇 개 추가할 뿐 계층을 추가하지 않으므로 연산 및 메모리 비용이 줄어듭니다. 이는 멀티태스킹 학습을 지원하여 관련 파인 튜닝된 LoRA 변형을 온디맨드로 배포하고, 필요할 때만 저계수 행렬을 로드하여 단일 베이스 LLM을 다양한 작업에 사용할 수 있도록 지원합니다.
마지막으로, LLM이 새 데이터를 학습하면 이전에 학습한 정보를 갑자기 잊어버리는 자연적인 경향인 치명적 망각을 방지합니다. LoRA: Low-Rank Adaptation of Large Language Models에서 볼 수 있듯이, 정량적으로 LoRA는 프롬프트 조정 및 어댑터와 같은 대체 조정 기술을 사용하는 모델보다 더 나은 성능을 제공합니다.
LoRA 이면의 수학
LoRA 이면의 수학은 저계수 분해를 기반으로 합니다. 저계수 분해는 더 작은 두 저계수 행렬의 곱으로 행렬의 근사치를 추정하는 방법입니다. 행렬 계수는 행렬에서 선형으로 독립적인 행 또는 열의 수입니다. 저계수 행렬은 최대 계수 행렬보다 자유도가 적고 더 간결하게 표현될 수 있습니다.
LoRA는 일반적으로 매우 크고 밀도가 높은 LLM의 가중치 행렬에 저계수 분해를 적용합니다. 예를 들어 LLM의 숨겨진 크기가 1,024이고 어휘 크기가 50,000인 경우 출력 가중치 행렬![]() 에는 1024 x 50,000 = 51,200,000개의 매개 변수가 있습니다.
에는 1024 x 50,000 = 51,200,000개의 매개 변수가 있습니다.
LoRA는 이 행렬을 ![]() 두 개의 더 작은 행렬인 1024 x
두 개의 더 작은 행렬인 1024 x ![]() 모양의
모양의 ![]() 행렬과
행렬과 ![]() x 50,000 모양의
x 50,000 모양의 ![]() 행렬로 분해합니다. 여기서
행렬로 분해합니다. 여기서 ![]() 은(는) 분해 계수를 제어하는 하이퍼 매개 변수입니다. 이 두 행렬의 곱은 원래 행렬과 모양이 같지만 매개 변수는 1024 x
은(는) 분해 계수를 제어하는 하이퍼 매개 변수입니다. 이 두 행렬의 곱은 원래 행렬과 모양이 같지만 매개 변수는 1024 x ![]() +
+ ![]() x 50,000 = 51,200,000~50,000 x (1024 –
x 50,000 = 51,200,000~50,000 x (1024 – ![]() )뿐입니다.
)뿐입니다.
하이퍼 매개 변수 ![]() 은(는) 올바르게 설정하는 데 매우 중요합니다. 더 작은
은(는) 올바르게 설정하는 데 매우 중요합니다. 더 작은 ![]() 을(를) 선택하면 많은 매개 변수와 메모리를 절약하고 더 빠른 훈련을 달성할 수 있습니다. 그러나
을(를) 선택하면 많은 매개 변수와 메모리를 절약하고 더 빠른 훈련을 달성할 수 있습니다. 그러나 ![]() 이(가) 작으면 저계수 행렬에서 포착되는 작업별 정보가 잠재적으로 감소할 수 있습니다.
이(가) 작으면 저계수 행렬에서 포착되는 작업별 정보가 잠재적으로 감소할 수 있습니다. ![]() 이(가) 클수록 과적합이 발생할 수 있습니다. 따라서 실험을 통해 특정 작업 및 데이터에 대한 정확도와 성능의 이상적 균형을 달성하는 것이 중요합니다.
이(가) 클수록 과적합이 발생할 수 있습니다. 따라서 실험을 통해 특정 작업 및 데이터에 대한 정확도와 성능의 이상적 균형을 달성하는 것이 중요합니다.
LoRA는 이러한 저계수 행렬을 LLM의 각 계층에 삽입하고 원본 가중치 행렬에 추가합니다. 원본 가중치 행렬은 사전 훈련된 LLM 가중치로 초기화되며 훈련 중에 업데이트되지 않습니다. 저계수 행렬은 무작위로 초기화되며 훈련 중에 업데이트되는 유일한 매개 변수입니다. 또한 LoRA는 원본 행렬과 저계수 행렬의 합에 계층 정규화를 적용하여 훈련을 안정화합니다.
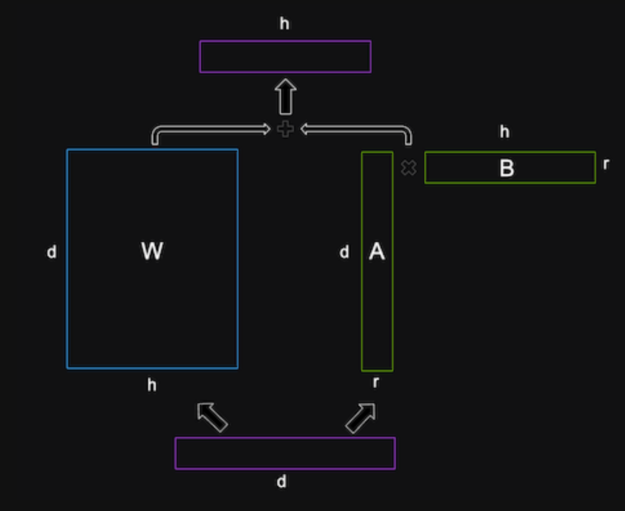
다중 LoRA 배포
LLM을 배포할 때의 한 가지 과제는 수백 또는 수천 개의 조정된 모델에 효율적으로 서비스를 제공하는 방법입니다. 예를 들어 Llama 2와 같은 단일 기본 LLM에는 언어 또는 로케일마다 LoRA 조정 변형이 여러 개 있을 수 있습니다. 이 경우 표준 시스템이 모든 모델을 독립적으로 로드해야 하며 많은 메모리 용량을 차지하게 됩니다. LoRA 설계를 활용해 단일 기본 모델을 LoRA 조정된 각 변형에 대한 저계수 행렬 A 및 B와 함께 로드하여 모델당 더 작은 저계수 행렬의 모든 정보를 캡처합니다. 이러한 방식으로 수천 개의 LLM을 저장하고 동적으로 최소한의 GPU 메모리 공간 내에서 효율적으로 실행할 수 있습니다.
LoRA 조정
LoRA 조정을 위해서는 일반적으로 프롬프트 템플릿을 사용하여 특정 형식의 훈련 데이터세트를 준비해야 합니다. 프롬프트를 형성할 때는 패턴을 결정하고 따라야 하며, 이는 사용 사례에 따라 자연스럽게 달라집니다. 질문과 답변의 예는 아래와 같습니다.
{
"taskname": "squad",
"prompt_template": "<|VIRTUAL_PROMPT_0|> Context: {context}\n\nQuestion: {question}\n\nAnswer:{answer}",
"total_virtual_tokens": 10,
"virtual_token_splits": [10],
"truncate_field": "context",
"answer_only_loss": True,
"answer_field": "answer",
}프롬프트의 시작 부분에는 10개의 가상 토큰이 모두 포함되어 있으며, 그 뒤로 컨텍스트, 질문, 답변이 이어집니다. 훈련 데이터 JSON 개체의 해당 필드가 이 프롬프트 템플릿에 매핑되어 완전한 훈련 예제를 형성합니다.
LLM을 맞춤화하는 데 사용할 수 있는 여러 플랫폼이 있습니다. NVIDIA NeMo 또는 Hugging Face PEFT와 같은 도구를 사용할 수 있습니다. NeMo를 사용하여 PubMed 데이터세트에서 LoRA를 조정하는 방법의 예시는 Llama 2를 사용한 NeMo 프레임워크 PEFT를 참조하세요.
이 게시물에서는 Hugging Face의 사전 조정된 LLM을 사용하므로 조정할 필요가 없습니다.
LoRA 추론
TensorRT-LLM으로 LoRA 조정 LLM을 최적화하려면 아키텍처를 이해하고 가장 유사한 공통 기본 아키텍처를 파악해야 합니다. 이 튜토리얼에서는 Llama 2 13B 및 Llama 2 7B를 기본 모델로 사용하며, Hugging Face에서 사용할 수 있는 여러 LoRA 조정 변형을 사용합니다.
첫 번째 단계는 이 디렉터리의 컨버터 및 빌드 스크립트를 사용하여 모든 모델을 컴파일하고 하드웨어 가속화를 위해 준비하는 것입니다. 그런 다음 명령줄과 Triton 추론 서버를 모두 사용한 배포 예시를 보여드리겠습니다.
토크나이저는 TensorRT-LLM에서 직접 처리되지 않습니다. 하지만 런타임과 Triton의 전처리 및 후처리 단계 설정을 위해 정의된 토크나이저 제품군 내에서 이를 분류할 수 있어야 합니다.
TensorRT-LLM 설정 및 구축
먼저 NVIDIA/TensorRT-LLM 라이브러리를 복제 및 구축합니다. TensorRT-LLM을 구축하고 모든 종속성을 검색하는 가장 쉬운 방법은 포함된 Dockerfile을 사용하는 것입니다. 이러한 명령은 기본 컨테이너를 풀링하고 컨테이너 내부에 TensorRT-LLM에 필요한 모든 종속성을 설치합니다. 그런 다음 컨테이너에 TensorRT-LLM 자체를 구축하고 설치합니다.
git lfs install
git clone https://github.com/NVIDIA/TensorRT-LLM.git
cd TensorRT-LLM
git submodule update --init --recursive
make -C docker release_build모델 가중치 가져오기
Hugging Face에서 기본 모델 및 LoRA 모델을 다운로드합니다.
git-lfs clone https://huggingface.co/meta-llama/Llama-2-13b-hf
git-lfs clone https://huggingface.co/hfl/chinese-llama-2-lora-13b모델 컴파일
엔진을 구축하고 --use_lora_plugin 및 --hf_lora_dir을 설정합니다. LoRA에 별도의 lm_head 및 임베딩이 있는 경우, 이는 기본 모델의 lm_head 및 임베딩을 대체합니다.
python convert_checkpoint.py --model_dir /tmp/llama-v2-13b-hf \
--output_dir ./tllm_checkpoint_2gpu_lora \
--dtype float16 \
--tp_size 2 \
--hf_lora_dir /tmp/chinese-llama-2-lora-13b
trtllm-build --checkpoint_dir ./tllm_checkpoint_2gpu_lora \
--output_dir /tmp/new_lora_13b/trt_engines/fp16/2-gpu/ \
--gpt_attention_plugin float16 \
--gemm_plugin float16 \
--lora_plugin float16 \
--max_batch_size 1 \
--max_input_len 512 \
--max_output_len 50 \
--use_fused_mlp모델 실행
추론 중에 모델을 실행하려면 lora_dir 명령줄 인수를 설정합니다. LoRA 조정 모델의 어휘 크기가 더 크므로 LoRA 토크나이저를 사용해야 합니다.
mpirun -n 2 python ../run.py --engine_dir "/tmp/new_lora_13b/trt_engines/fp16/2-gpu/" \
--max_output_len 50 \
--tokenizer_dir "chinese-llama-2-lora-13b/" \
--input_text "今天天气很好,我到公园的时后," \
--lora_dir "chinese-llama-2-lora-13b/" \
--lora_task_uids 0 \
--no_add_special_tokens \
--use_py_session
Input: "今天天气很好,我到公园的时后,"
Output: "发现公园里人很多,有的在打羽毛球,有的在打乒乓球,有的在跳绳,还有的在跑步。我和妈妈来到一个空地上,我和妈妈一起跳绳,我跳了1"제거 테스트를 실행하여 LoRA 조정 모델의 기여도를 직접 확인할 수 있습니다. LoRa가 있는 경우와 없는 경우의 결과를 쉽게 비교하려면 –lora_task_uids-1을 사용하여 UID를 -1로 설정하기만 하면 됩니다. 이 경우 모델은 LoRA 모듈을 무시하며 결과는 기본 모델만을 기반으로 합니다.
mpirun -n 2 python ../run.py --engine_dir "/tmp/new_lora_13b/trt_engines/fp16/2-gpu/" \
--max_output_len 50 \
--tokenizer_dir "chinese-llama-2-lora-13b/" \
--input_text "今天天气很好,我到公园的时后," \
--lora_dir "chinese-llama-2-lora-13b/" \
--lora_task_uids -1 \
--no_add_special_tokens \
--use_py_session
Input: "今天天气很好,我到公园的时后,"
Output: "我看见一个人坐在那边边看书书,我看起来还挺像你,可是我走过过去问了一下他说你是你吗,他说没有,然后我就说你看我看看你像你,他说说你看我像你,我说你是你,他说你是你,"여러 LoRA 조정 모델로 기본 모델 실행
또한 TensorRT-LLM은 여러 LoRA 조정 모듈로 단일 기본 모델을 동시에 실행하도록 지원합니다. 여기서는 두 개의 LoRA 체크포인트를 예로 들어 설명합니다. 두 체크포인트의 LoRA 모듈의 ![]() 계수가 8이므로, LoRA 플러그인의 메모리 요구 사항을 줄이기 위해
계수가 8이므로, LoRA 플러그인의 메모리 요구 사항을 줄이기 위해 --max_lora_rank를 8로 낮출 수 있습니다.
이 예시에서는 중국어 데이터세트 luotuo-lora-7b-0.1에서 파인 튜닝된 LoRA 체크포인트와 일본어 데이터세트 Japanese-Alpaca-LoRA-7b-v0에서 파인 튜닝된 LoRA 체크포인트를 사용합니다. TensorRT-LLM이 여러 체크포인트를 로드하도록 하려면 --lora_dir "luotuo-lora-7b-0.1/" "Japanese-Alpaca-LoRA-7b-v0/"을 통해 모든 LoRA 체크포인트의 디렉토리를 전달합니다. TensorRT-LLM은 이러한 체크포인트에 lora_task_uid를 할당합니다. lora_task_uids -1은 기본 모델에 해당하는 사전 정의된 값입니다. 예를 들어 lora_task_uids 0 1을 전달하면 첫 번째 문장에서 첫 번째 LoRA 체크포인트를 사용하고 두 번째 문장에서 두 번째 LoRA 체크포인트를 사용합니다.
정확성을 확인하기 위해 동일한 중국어 입력 美国的首都在哪里? \n答案:을 3회 전달하고, 또 동일한 일본어 입력인 アメリカ合衆国の首都はどこですか? \n答え:를 3회 전달합니다. (두 입력은 모두 “미국의 수도는 어디입니까? \n답변”을 의미합니다.) 그런 다음 기본 모델인 luotuo-lora-7b-0.1 및 Japanese-Alpaca-LoRA-7b-v0에서 각각 실행합니다.
git-lfs clone https://huggingface.co/qychen/luotuo-lora-7b-0.1
git-lfs clone https://huggingface.co/kunishou/Japanese-Alpaca-LoRA-7b-v0
BASE_LLAMA_MODEL=llama-7b-hf/
python convert_checkpoint.py --model_dir ${BASE_LLAMA_MODEL} \
--output_dir ./tllm_checkpoint_1gpu_lora_rank \
--dtype float16 \
--hf_lora_dir /tmp/Japanese-Alpaca-LoRA-7b-v0 \
--max_lora_rank 8 \
--lora_target_modules "attn_q" "attn_k" "attn_v"
trtllm-build --checkpoint_dir ./tllm_checkpoint_1gpu_lora_rank \
--output_dir /tmp/llama_7b_with_lora_qkv/trt_engines/fp16/1-gpu/ \
--gpt_attention_plugin float16 \
--gemm_plugin float16 \
--lora_plugin float16 \
--max_batch_size 1 \
--max_input_len 512 \
--max_output_len 50
python ../run.py --engine_dir "/tmp/llama_7b_with_lora_qkv/trt_engines/fp16/1-gpu/" \
--max_output_len 10 \
--tokenizer_dir ${BASE_LLAMA_MODEL} \
--input_text "美国的首都在哪里? \n答案:" "美国的首都在哪里? \n答案:" "美国的首都在哪里? \n答案:" "アメリカ合衆国の首都はどこですか? \n答え:" "アメリカ合衆国の首都はどこですか? \n答え:" "アメリカ合衆国の首都はどこですか? \n答え:" \
--lora_dir "luotuo-lora-7b-0.1/" "Japanese-Alpaca-LoRA-7b-v0/" \
--lora_task_uids -1 0 1 -1 0 1 \
--use_py_session --top_p 0.5 --top_k 0결과는 아래와 같습니다.
Input [Text 0]: "<s> 美国的首都在哪里? \n答案:"
Output [Text 0 Beam 0]: "Washington, D.C.
What is the"
Input [Text 1]: "<s> 美国的首都在哪里? \n答案:"
Output [Text 1 Beam 0]: "华盛顿。
"
Input [Text 2]: "<s> 美国的首都在哪里? \n答案:"
Output [Text 2 Beam 0]: "Washington D.C.'''''"
Input [Text 3]: "<s> アメリカ合衆国の首都はどこですか? \n答え:"
Output [Text 3 Beam 0]: "Washington, D.C.
Which of"
Input [Text 4]: "<s> アメリカ合衆国の首都はどこですか? \n答え:"
Output [Text 4 Beam 0]: "华盛顿。
"
Input [Text 5]: "<s> アメリカ合衆国の首都はどこですか? \n答え:"
Output [Text 5 Beam 0]: "ワシントン D.C."luotuo-lora-7b-0.1은 첫 번째 문장과 다섯 번째 문장(중국어)에서 정답을 생성합니다. Japanese-Alpaca-LoRA-7b-v0은 여섯 번째 문장(일본어)에서 정답을 생성합니다.
중요 참고 사항: LoRA 모듈 중 하나에 파인 튜닝된 임베딩 테이블 또는 logit GEMM이 포함된 경우, 사용자는 모델의 모든 인스턴스가 파인 튜닝된 동일한 임베딩 테이블 또는 logit GEMM을 사용할 수 있도록 보장해야 합니다.
Triton 및 인플라이트 배치 처리를 통한 LoRA 조정 모델 배포
이 섹션에서는 Triton 추론 서버에서 진행 중인 배치를 사용하여 LoRA 조정 모델을 배포하는 방법을 알아봅니다. Triton 추론 서버 설정 및 실행에 대한 구체적인 지침은 NVIDIA TensorRT-LLM 및 NVIDIA Triton을 활용한 AI 코딩 도우미 배포를 참조하세요.
이전과 마찬가지로, 우선 LoRA가 활성화된 모델을 컴파일합니다. 이번에는 기본 모델 Llama 2 7B로 컴파일합니다.
BASE_MODEL=llama-7b-hf
python3 tensorrt_llm/examples/llama/build.py --model_dir ${BASE_MODEL} \
--dtype float16 \
--remove_input_padding \
--use_gpt_attention_plugin float16 \
--enable_context_fmha \
--use_gemm_plugin float16 \
--output_dir "/tmp/llama_7b_with_lora_qkv/trt_engines/fp16/1-gpu/" \
--max_batch_size 128 \
--max_input_len 512 \
--max_output_len 50 \
--use_lora_plugin float16 \
--lora_target_modules "attn_q" "attn_k" "attn_v" \
--use_inflight_batching \
--paged_kv_cache \
--max_lora_rank 8 \
--world_size 1 --tp_size 1다음으로, 각 요청과 함께 Triton에 전달될 LoRA 텐서를 생성합니다.
git-lfs clone https://huggingface.co/qychen/luotuo-lora-7b-0.1
git-lfs clone https://huggingface.co/kunishou/Japanese-Alpaca-LoRA-7b-v0
python3 tensorrt_llm/examples/hf_lora_convert.py -i Japanese-Alpaca-LoRA-7b-v0 -o Japanese-Alpaca-LoRA-7b-v0-weights --storage-type float16
python3 tensorrt_llm/examples/hf_lora_convert.py -i luotuo-lora-7b-0.1 -o luotuo-lora-7b-0.1-weights --storage-type float16그런 다음 Triton 모델 리포지토리를 만들고 앞서 설명한 대로 Triton 서버를 시작합니다.
마지막으로 클라이언트에서 여러 동시 요청을 실행하여 다중 LoRA 예제를 실행합니다. 인플라이트 배처는 동일한 배치의 여러 LoRA를 사용하여 혼합 배치를 실행합니다.
INPUT_TEXT=("美国的首都在哪里? \n答案:" "美国的首都在哪里? \n答案:" "美国的首都在哪里? \n答案:" "アメリカ合衆国の首都はどこですか? \n答え:" "アメリカ合衆国の首都はどこですか? \n答え:" "アメリカ合衆国の首都はどこですか? \n答え:")
LORA_PATHS=("" "luotuo-lora-7b-0.1-weights" "Japanese-Alpaca-LoRA-7b-v0-weights" "" "luotuo-lora-7b-0.1-weights" "Japanese-Alpaca-LoRA-7b-v0-weights")
for index in ${!INPUT_TEXT[@]}; do
text=${INPUT_TEXT[$index]}
lora_path=${LORA_PATHS[$index]}
lora_arg=""
if [ "${lora_path}" != "" ]; then
lora_arg="--lora-path ${lora_path}"
fi
python3 inflight_batcher_llm/client/inflight_batcher_llm_client.py \
--top-k 0 \
--top-p 0.5 \
--request-output-len 10 \
--text "${text}" \
--tokenizer-dir /home/scratch.trt_llm_data/llm-models/llama-models/llama-7b-hf \
${lora_arg} &
done
wait예시 출력은 아래와 같습니다.
Input sequence: [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901]
Input sequence: [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901]
Input sequence: [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901]
Input sequence: [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901]
Input sequence: [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901]
Input sequence: [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901]
Got completed request
Input: アメリカ合衆国の首都はどこですか? \n答え:
Output beam 0: ワシントン D.C.
Output sequence: [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901, 29871, 31028, 30373, 30203, 30279, 30203, 360, 29889, 29907, 29889]
Got completed request
Input: 美国的首都在哪里? \n答案:
Output beam 0: Washington, D.C.
What is the
Output sequence: [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901, 7660, 29892, 360, 29889, 29907, 29889, 13, 5618, 338, 278]
Got completed request
Input: 美国的首都在哪里? \n答案:
Output beam 0: Washington D.C.
Washington D.
Output sequence: [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901, 7660, 360, 29889, 29907, 29889, 13, 29956, 7321, 360, 29889]
Got completed request
Input: アメリカ合衆国の首都はどこですか? \n答え:
Output beam 0: Washington, D.C.
Which of
Output sequence: [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901, 7660, 29892, 360, 29889, 29907, 29889, 13, 8809, 436, 310]
Got completed request
Input: アメリカ合衆国の首都はどこですか? \n答え:
Output beam 0: Washington D.C.
1. ア
Output sequence: [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901, 7660, 360, 29889, 29907, 29889, 13, 29896, 29889, 29871, 30310]
Got completed request
Input: 美国的首都在哪里? \n答案:
Output beam 0: 华盛顿
W
Output sequence: [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 1결론
인기 있는 여러 LLM 아키텍처에 대한 기본 지원을 통해 TensorRT-LLM을 사용하면 다양한 코드 LLM을 쉽게 배포, 실험 및 최적화할 수 있습니다. NVIDIA TensorRT-LLM과 NVIDIA Triton 추론 서버는 함께 LLM을 효율적으로 최적화, 배포 및 실행하는 데 필수적인 툴킷을 제공합니다. LoRA 조정 모델 지원을 통해 TensorRT-LLM은 맞춤형 LLM을 효율적으로 배포하여 메모리 및 연산 비용을 크게 줄여줍니다.
시작하려면 NVIDIA/TensorRT-LLM 오픈 소스 라이브러리를 다운로드 및 설정하고 다양한 예제 LLM으로 실험해 보세요. NVIDIA NeMo를 사용하여 자체 LLM을 조정할 수 있습니다. 예를 들어 NeMo Framework PEFT with Llama 2를 참조하세요. 대안으로 NeMo 프레임워크 추론 컨테이너를 사용하여 배포할 수도 있습니다.