
CUDA 5의 CUDA 툴킷에 nvprof라는 강력한 새 도구가 추가되었습니다. nvprof는 Linux, Windows 및 OS X에서 사용할 수 있는 명령줄 프로파일러입니다. 언뜻 보면 nvprof는 NVIDIA Visual Profiler 및 NSight Eclipse Edition에서 사용할 수 있는 그래픽 프로파일링 기능에서 GUI만 없는 버전으로 보일 수 있습니다. 하지만 nvprof는 그 이상의 의미가 있습니다. 제가 보기에 nvprof는 다른 도구와는 비교할 수 없는 수준의 경량 프로파일러입니다.
빠른 검사를 위해 nvprof 사용
종종 CUDA 애플리케이션이 예상대로 실행되고 있는지 궁금할 때가 있습니다. 온전히 작동하는지만 확인하면 되는 경우도 있습니다. 앱이 GPU에서 조금이라도 커널을 실행하고 있는가? 과도하게 메모리 복사를 수행하고 있는가? nvprof ./myApp으로 애플리케이션을 실행하면 다음 샘플 출력에서 볼 수 있듯이, 애플리케이션에서 사용된 모든 커널 및 메모리 복사본의 요약을 빠르게 확인할 수 있습니다.
==9261== Profiling application: ./tHogbomCleanHemi
==9261== Profiling result:
Time(%) Time Calls Avg Min Max Name
58.73% 737.97ms 1000 737.97us 424.77us 1.1405ms subtractPSFLoop_kernel(float const *, int, float*, int, int, int, int, int, int, int, float, float)
38.39% 482.31ms 1001 481.83us 475.74us 492.16us findPeakLoop_kernel(MaxCandidate*, float const *, int)
1.87% 23.450ms 2 11.725ms 11.721ms 11.728ms [CUDA memcpy HtoD]
1.01% 12.715ms 1002 12.689us 2.1760us 10.502ms [CUDA memcpy DtoH]nvprof 기본 요약 모드에서는 애플리케이션의 GPU 커널 및 메모리 복사본이 요약적으로 표시됩니다. 이 요약에서는 동일한 커널에 대한 모든 호출이 함께 그룹화되어 커널별 총시간 및 애플리케이션 총시간 대비 비율이 표시됩니다. nvprof에서는 요약 모드 외에도 모든 커널 실행 및 메모리 복사의 전체 목록을 볼 수 있는 GPU 추적 및 API 추적 모드를 지원하며, API 추적 모드의 경우 모든 CUDA API 호출까지 확인할 수 있습니다.
다음은 nvprof –print-gpu-trace를 사용하여 PC의 두 GPU에서 실행되는 nbody 샘플 애플리케이션을 프로파일링하는 예시입니다. 각 커널이 어느 GPU에서 실행했는지뿐만 아니라 각 실행에서 사용된 그리드 차원을 확인할 수 있습니다. 이 기능은 멀티 GPU 애플리케이션이 예상대로 실행되고 있는지 확인하는 데 매우 유용합니다.
nvprof --print-gpu-trace ./nbody --benchmark -numdevices=2 -i=1
...
==4125== Profiling application: ./nbody --benchmark -numdevices=2 -i=1
==4125== Profiling result:
Start Duration Grid Size Block Size Regs* SSMem* DSMem* Size Throughput Device Context Stream Name
260.78ms 864ns - - - - - 4B 4.6296MB/s Tesla K20c (0) 2 2 [CUDA memcpy HtoD]
260.79ms 960ns - - - - - 4B 4.1667MB/s GeForce GTX 680 1 2 [CUDA memcpy HtoD]
260.93ms 896ns - - - - - 4B 4.4643MB/s Tesla K20c (0) 2 2 [CUDA memcpy HtoD]
260.94ms 672ns - - - - - 4B 5.9524MB/s GeForce GTX 680 1 2 [CUDA memcpy HtoD]
268.03ms 1.3120us - - - - - 8B 6.0976MB/s Tesla K20c (0) 2 2 [CUDA memcpy HtoD]
268.04ms 928ns - - - - - 8B 8.6207MB/s GeForce GTX 680 1 2 [CUDA memcpy HtoD]
268.19ms 864ns - - - - - 8B 9.2593MB/s Tesla K20c (0) 2 2 [CUDA memcpy HtoD]
268.19ms 800ns - - - - - 8B 10.000MB/s GeForce GTX 680 1 2 [CUDA memcpy HtoD]
274.59ms 2.2887ms (52 1 1) (256 1 1) 36 0B 4.0960KB - - Tesla K20c (0) 2 2 void integrateBodies(vec4::Type*, vec4::Type*, vec4::Type*, unsigned int, unsigned int, float, float, int) [242]
274.67ms 981.47us (32 1 1) (256 1 1) 36 0B 4.0960KB - - GeForce GTX 680 1 2 void integrateBodies(vec4::Type*, vec4::Type*, vec4::Type*, unsigned int, unsigned int, float, float, int) [257]
276.94ms 2.3146ms (52 1 1) (256 1 1) 36 0B 4.0960KB - - Tesla K20c (0) 2 2 void integrateBodies(vec4::Type*, vec4::Type*, vec4::Type*, unsigned int, unsigned int, float, float, int) [275]
276.99ms 979.36us (32 1 1) (256 1 1) 36 0B 4.0960KB - - GeForce GTX 680 1 2 void integrateBodies(vec4::Type*, vec4::Type*, vec4::Type*, unsigned int, unsigned int, float, float, int) [290]
Regs: Number of registers used per CUDA thread.
SSMem: Static shared memory allocated per CUDA block.
DSMem: Dynamic shared memory allocated per CUDA block.무엇이든지 프로파일링할 수 있는 nvprof
CUDA 런타임 API 또는 드라이버 API를 사용하여 실행되기만 하면, nvprof는 작성 언어와 관계없이 NVIDIA GPU에서 실행되는 모든 CUDA 커널을 프로파일링할 수 있습니다. 즉 nvprof를 사용하면 명시적 커널이 없는 OpenACC 프로그램이나 내부적으로 PTX 어셈블리 커널을 생성하는 프로그램까지도 프로파일링할 수 있습니다. Mark Ebersole은 CUDA Python을 다룬 최근의 CUDACast(에피소드 10)에서 이러한 활용의 훌륭한 예를 보여 주었습니다. 그는 이 에피소드에서 NumbaPro 컴파일러(Continuum Analytics)를 사용하여 Python 함수를 JIT 컴파일링하고 GPU에서 병렬로 실행했습니다.
OpenACC 또는 CUDA Python 프로그램을 처음 구현하는 동안 함수가 GPU 또는 CPU에서 실행되고 있는지 명확하지 않을 수 있습니다(특히 시간 타이밍을 설정하지 않는 경우). 에피소드에서 다룬 예시에서 Mark는 nvprof에 내장된 Python 인터프리터를 실행하여 애플리케이션의 CUDA 함수 호출 및 커널 실행 기록을 캡처하여 커널이 실제로 GPU에서 실행 중이라는 사실뿐만 아니라 CPU에서 GPU로 데이터를 전송하는 데 cudaMemcpy 호출이 사용되었음을 보여줍니다. 이는 nvprof와 같은 경량 명령줄 GPU 프로파일러가 보유한 온전성 확인 기능을 보여주는 훌륭한 사례입니다.
원격 프로파일링에 nvprof 사용
데스크톱 시스템이 아닌 시스템에 배포하는 경우가 종종 있습니다. 예를 들어, GPU 클러스터나 Amazon EC2와 같은 클라우드 시스템을 사용하는 경우, 터미널을 통해서만 시스템에 액세스할 수 있습니다. 이러한 상황에서도 nvprof를 매우 유용합니다. ssh 등을 사용하여 원격 시스템에 연결하고 nvprof에서 애플리케이션을 실행하기만 하면 됩니다.
–output-profile 명령줄 옵션을 사용하면 나중에 가져오기를 위해 데이터 파일을 nvprof 또는 NVIDIA Visual Profiler로 출력할 수 있습니다. 즉, 원격 시스템에서 프로필을 캡처한 다음 데스크톱의 Visual Profiler에서 결과를 시각화하고 분석할 수 있습니다(자세한 내용은 “원격 프로파일링” 참조).
nvprof는 Visual Profiler의 “가이드 분석” 모드에 필요한 모든 GPU 메트릭을 캡처할 수 있는 편리한 옵션(–analysis-metrics)을 제공합니다. 아래의 스크린샷은 커널의 병목 현상을 파악하기 위해 시각 프로파일러를 사용하고 있음을 보여줍니다. 이 분석의 데이터는 아래 명령줄을 사용하여 캡처되었습니다.
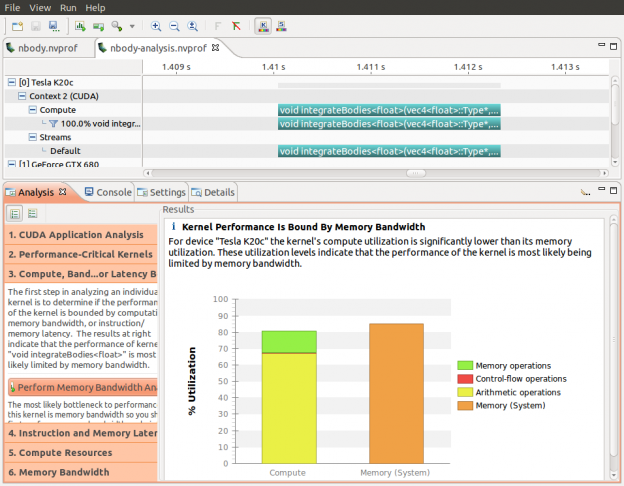
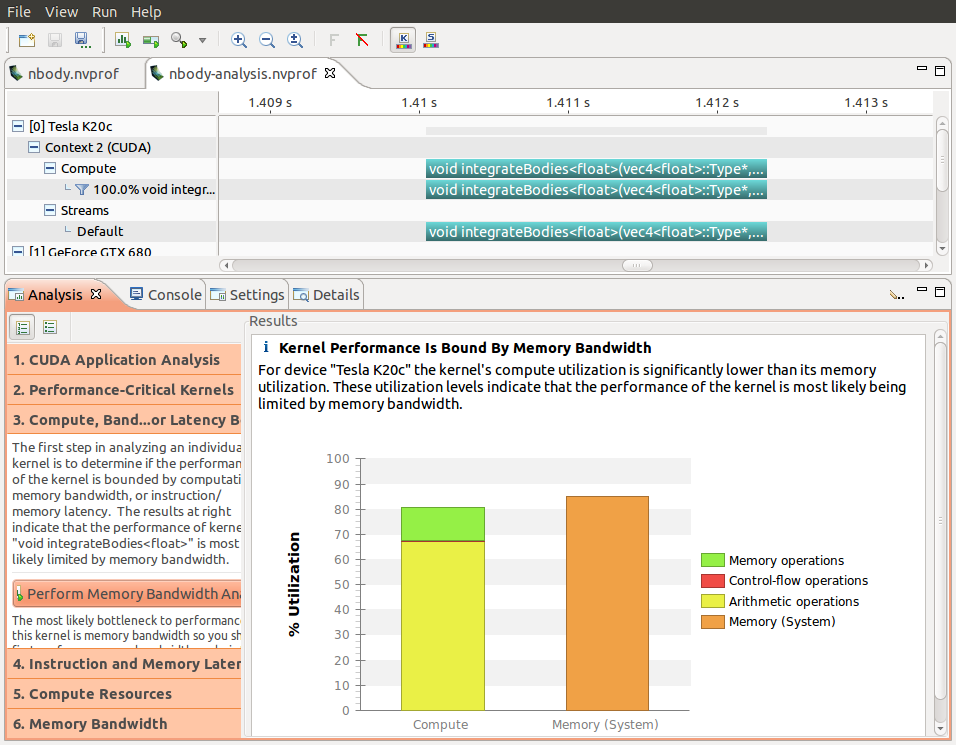{kind=link}
매우 편리한 도구
명령줄 도구를 즐겨 사용하는 사용자라면 nvprof가 많은 도움이 될 것입니다. NVIDIA Visual Profiler에서 분석을 위한 프로파일링 메트릭을 수집하는 등 여기에서 다루지 못한 수많은 기능을 nvprof에서 수행할 수 있습니다. 자세한 내용은 nvprof 문서를 참조하세요.
이 게시물을 읽고 nvprof을 일상적으로 활용해 보시기 바랍니다.
이 블로그에 열거된 SDK의 대부분의 독점 액세스, 얼리 액세스, 기술 세션, 데모, 교육 과정, 리소스는 NVIDIA 개발자 프로그램 회원은 무료로 혜택을 받으실 수 있습니다. 지금 무료로 가입하여 NVIDIA의 기술 플랫폼에서 구축하는 데 필요한 도구와 교육에 액세스하시고 여러분의 성공을 가속화 하세요.