
거대 언어 모델(LLM)로 구동되는 AI 에이전트는 조직이 반복적인 수작업을 간소화하고 업무량을 줄이는 데 큰 도움을 줍니다. 이 에이전트들은 다단계 반복 추론 과정을 통해 문제를 분석하고 해결책을 고안하며, 다양한 도구를 사용해 작업을 실행합니다. 기존 챗봇과 달리 LLM 기반 에이전트는 정보를 효과적으로 이해하고 처리할 수 있어 복잡한 작업을 자동화할 수 있습니다. 다만, 특정 애플리케이션에서 발생할 수 있는 잠재적인 위험을 방지하려면 자율 AI 에이전트와 작업할 때 반드시 사람의 감독을 유지하는 것이 중요합니다.
이 포스팅에서는 NVIDIA의 AI 추론에 최적화된 가속화된 API인 NVIDIA NIM 마이크로서비스를 사용해 휴먼 인 더 루프(Human-in-the-Loop) AI 에이전트를 설계하고 구축하는 방법을 안내합니다. 소셜 미디어 사용 사례를 통해 이 다목적 AI 에이전트가 복잡한 작업을 손쉽게 처리하는 모습을 보여줍니다. NIM 마이크로서비스를 활용하면 고급 LLM을 워크플로우에 원활히 통합할 수 있어 AI 기반 작업에 필요한 확장성과 유연성을 제공합니다. 이 튜토리얼은 프로모션 콘텐츠 제작이나 복잡한 워크플로우를 자동화하는 작업을 보다 효율적으로 수행하는 데 큰 도움이 될 것입니다.
데모 보기: NVIDIA NIM으로 5분 만에 간단한 AI 에이전트 구축하기
개인화된 소셜 미디어 콘텐츠를 위한 AI 에이전트 구축
오늘날 마케터들에게 가장 큰 과제 중 하나는 다양한 플랫폼에서 고품질의 창의적인 프로모션 콘텐츠를 제작하는 일입니다. 작업의 목표는 소셜 미디어에 게시할 수 있는 홍보 메시지와 아트웍을 생성하는 것입니다.
일반적으로 프로젝트 리더는 이러한 작업을 콘텐츠 작가나 디지털 아티스트 같은 전문가에게 맡깁니다. 하지만 AI 에이전트를 활용해 이 과정을 훨씬 더 효율적으로 처리할 수 있다면 어떨까요?
이 사용 사례에서는 콘텐츠 크리에이터 에이전트와 디지털 아티스트 에이전트라는 두 종류의 AI 에이전트가 함께 작업합니다. 이들 에이전트는 홍보 콘텐츠를 생성한 뒤, 최종 승인을 위해 인간 의사결정권자에게 결과물을 제출합니다. 이를 통해 크리에이티브 프로세스에서 인간이 여전히 핵심적인 통제와 감독 역할을 유지할 수 있습니다.
인간-에이전트 의사 결정 워크플로우 설계하기
이러한 휴먼 인 더 루프 시스템을 구축하려면 AI 에이전트가 특정 작업을 지원하고 최종 의사 결정은 사람이 수행하는 인지 워크플로우를 만들어야 합니다. 그림 1은 인간 의사 결정권자와 에이전트 간의 상호 작용을 간략하게 보여줍니다.
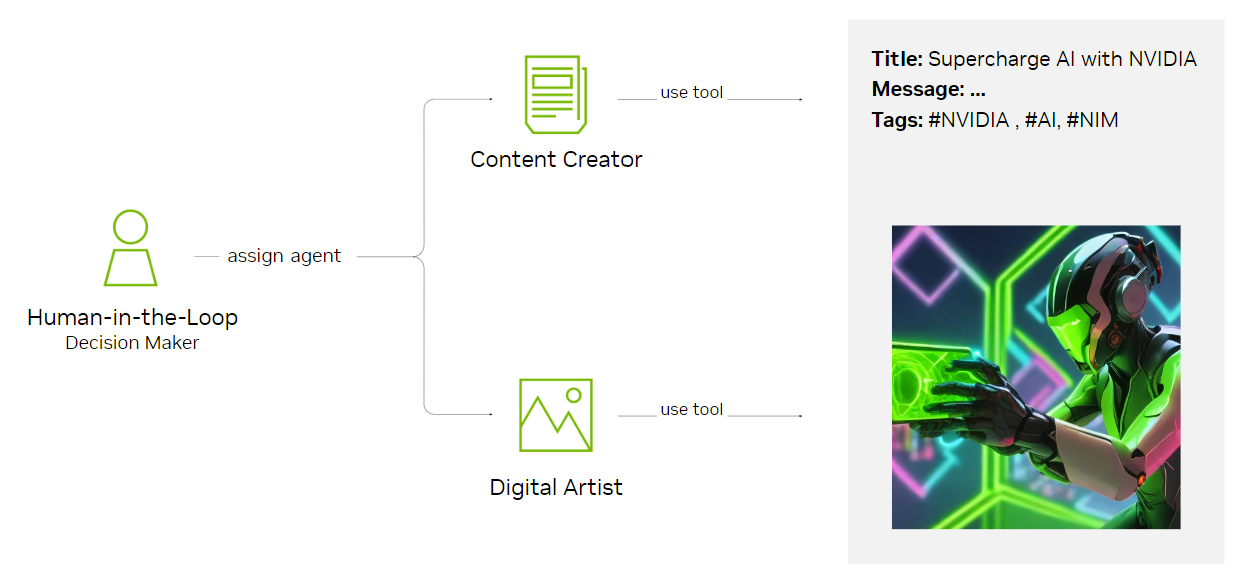
콘텐츠 크리에이터 에이전트는 NVIDIA LLM NIM 마이크로서비스로 가속화된 Llama 3.1 405B 모델을 사용합니다. 안정적이고 체계적인 결과를 보장하기 위해 NIM 함수 호출과 구조화된 출력을 지원하는 LangChain ChatNVIDIA가 통합되어 있습니다. ChatNVIDIA는 NVIDIA가 LangChain 프로젝트에 기여한 오픈 소스 Python 라이브러리로, 개발자가 NVIDIA NIM과 손쉽게 연결할 수 있도록 설계되었습니다. 이러한 기능은 LangChain 런처블 체인(LCEL) 표현식으로 통합되어 강력한 에이전트 워크플로우를 생성합니다.
콘텐츠 크리에이터 에이전트 구축하기
먼저, 콘텐츠 크리에이터 에이전트를 구축하세요. 이 에이전트는 특정 포맷 가이드라인에 따라 NVIDIA API 카탈로그 미리 보기 API 엔드포인트를 활용해 프로모션 메시지를 생성합니다. 또한, NVIDIA AI Enterprise 고객은 NIM 엔드포인트를 로컬 환경에 다운로드해 실행할 수도 있습니다.
시작하려면 아래 Python 코드를 사용하세요:
from langchain_nvidia_ai_endpoints import ChatNVIDIA
from langchain import prompts, chat_models, hub
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field, validator
from typing import Optional, List
## 1. construct the system prompt ---------
prompt_template = """
### [INST]
You are an expert social media content creator.
Your task is to create a different promotion message with the following
Product Description :
------
{product_desc}
------
The output promotion message MUST use the following format :
'''
Title: a powerful, short message that dipict what this product is about
Message: be creative for the promotion message, but make it short and ready for social media feeds.
Tags: the hash tag human will nomally use in social media
'''
Begin!
[/INST]
"""
prompt = PromptTemplate(
input_variables=['produce_desc'],
template=prompt_template,
)
## 2. provide seeded product_desc text
product_desc="Explore the latest community-built AI models with an API optimized and accelerated by NVIDIA, then deploy anywhere with NVIDIA NIM™ inference microservices."
## 3. structural output using LMFE
class StructureOutput(BaseModel):
Title: str = Field(description="Title of the promotion message")
Message : str = Field(description="The actual promotion message")
Tags: List[str] = Field(description="Hashtags for social media, usually starts with #")
## 4. A powerful LLM
llm_with_output_structure=ChatNVIDIA(model="meta/llama-3.1-405b-instruct").with_structured_output(StructureOutput)
## construct the content_creator agent
content_creator = ( prompt | llm_with_output_structure )
out=content_creator.invoke({"product_desc":product_desc})디지털 아티스트 에이전트 사용
다음으로 NVIDIA sdXL-turbo 텍스트-이미지 변환 모델을 사용하여 홍보 텍스트를 창의적인 비주얼로 변환하는 디지털 아티스트 에이전트를 소개합니다. 이 에이전트는 입력 쿼리를 다시 작성하고 소셜 미디어 프로모션 캠페인을 위해 디자인된 고품질 이미지를 생성합니다. 다음 코드는 에이전트가 어떻게 통합되는지 보여주는 예시입니다:
import requests
import base64, io
from PIL import Image
import requests, json
def generate_image(prompt :str) -> str :
"""
generate image from text
Args:
prompt: input text
"""
## re-writing the input promotion title in to appropriate image_gen prompt
gen_prompt=llm_rewrite_to_image_prompts(prompt)
print("start generating image with llm re-write prompt:", gen_prompt)
invoke_url = "https://ai.api.nvidia.com/v1/genai/stabilityai/sdxl-turbo"
headers = {
"Authorization": f"Bearer {nvapi_key}",
"Accept": "application/json",
}
payload = {
"text_prompts": [{"text": gen_prompt}],
"seed": 0,
"sampler": "K_EULER_ANCESTRAL",
"steps": 2
}
response = requests.post(invoke_url, headers=headers, json=payload)
response.raise_for_status()
response_body = response.json()
## load back to numpy array
print(response_body['artifacts'][0].keys())
imgdata = base64.b64decode(response_body["artifacts"][0]["base64"])
filename = 'output.jpg'
with open(filename, 'wb') as f:
f.write(imgdata)
im = Image.open(filename)
img_location=f"the output of the generated image will be stored in this path : {filename}"
return img_location다음 Python 스크립트를 사용하여 사용자 입력 쿼리를 이미지 생성 프롬프트로 재작성합니다:
from langchain_nvidia_ai_endpoints import ChatNVIDIA
from langchain import prompts, chat_models, hub
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, PromptTemplate
def llm_rewrite_to_image_prompts(user_query):
prompt = prompts.ChatPromptTemplate.from_messages(
[
(
"system",
"Summarize the following user query into a very short, one-sentence theme for image generation, MUST follow this format : A iconic, futuristic image of , no text, no amputation, no face, bright, vibrant",
),
("user", "{input}"),
]
)
model = ChatNVIDIA(model="mistralai/mixtral-8x7b-instruct-v0.1")
chain = ( prompt | model | StrOutputParser() )
out= chain.invoke({"input":user_query})
#print(type(out))
return out}그런 다음 이미지 생성을 선택한 LLM에 바인딩하고 LCEL로 래핑하여 디지털 아티스트 에이전트를 생성합니다:
## bind image generation as tool into llama3.1-405b llm
llm=ChatNVIDIA(model="meta/llama-3.1-405b-instruct")
llm_with_img_gen_tool=llm.bind_tools([generate_image],tool_choice="generate_image")
## use LCEL to construct Digital Artist Agent
digital_artist = (
llm_with_img_gen_tool
| output_to_invoke_tools
)휴먼 인 더 루프와 의사 결정권자의 역할 통합
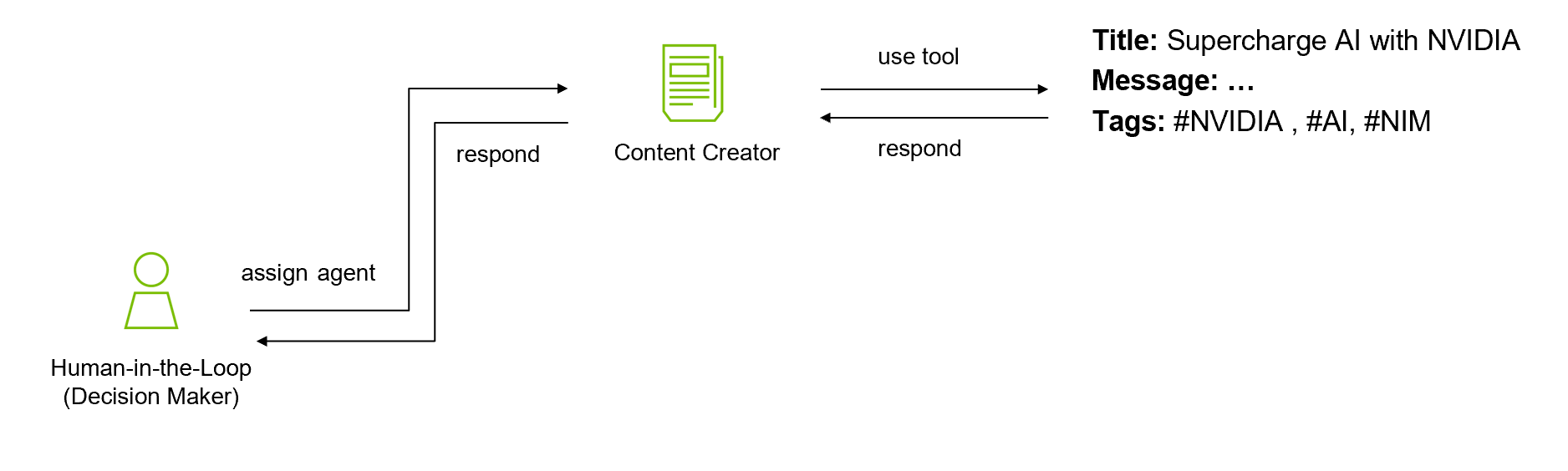
사람의 감독을 유지하기 위해, 에이전트는 최종 승인을 받기 위해 결과물을 공유합니다. 의사결정권자는 콘텐츠 크리에이터 에이전트가 생성한 텍스트와 디지털 아티스트 에이전트가 제작한 아트워크를 모두 검토합니다.
이러한 상호작용은 반복 과정을 거치며, 이를 통해 홍보 메시지와 이미지가 충분히 다듬어져 배포 준비가 완료되었는지 확인할 수 있습니다.
에이전트 로직은 사람을 의사 결정자의 중심에 두고 각 작업에 적합한 에이전트를 할당합니다. LangGraph는 에이전트 인지 아키텍처를 조율하는 데 사용됩니다.
여기에는 사람의 입력을 요청하는 기능이 포함됩니다:
# Or you can directly instantiate the tool
from langchain_community.tools import HumanInputRun
from langchain.agents import AgentType, load_tools
from langchain.agents import AgentType, initialize_agent, load_tools
def get_human_input() -> str:
""" Put human as decision maker, human will decide which agent is best for the task"""
print("You have been given 2 agents. Please select exactly _ONE_ agent to help you with the task, enter 'y' to confirm your choice.")
print("""Available agents are : \n
1 ContentCreator \n
2 DigitalArtist \n
Enter 1 or 2""")
contents = []
while True:
try:
line = input()
if line=='1':
tool="ContentCreator"
line=tool
elif line=='2':
tool="DigitalArtist"
line=tool
else:
pass
except EOFError:
break
if line == "y":
print(f"tool selected : {tool} ")
break
contents.append(line)
return "\n".join(contents)
# You can modify the tool when loading
ask_human = HumanInputRun(input_func=get_human_input)다음으로, 그래프 노드 역할을 할 두 개의 Python 함수를 추가로 생성하여 LangGraph가 워크플로우 내의 단계 또는 작업을 표현하는 데 사용합니다. 이러한 노드를 사용하면 에이전트가 특정 작업을 순차적으로 또는 병렬로 실행하여 유연하고 구조화된 프로세스를 만들 수 있습니다:
from langgraph.graph import END, StateGraph
from langgraph.prebuilt import ToolInvocation
from colorama import Fore,Style
# Define the functions needed
def human_assign_to_agent(state):
# ensure using original prompt
inputs = state["input"]
input_to_agent = state["input_to_agent"]
concatenate_str = Fore.BLUE+inputs+ ' : '+Fore.CYAN+input_to_agent + Fore.RESET
print(concatenate_str)
print("---"*10)
agent_choice=ask_human.invoke(concatenate_str)
print(Fore.CYAN+ "choosen_agent : " + agent_choice + Fore.RESET)
return {"agent_choice": agent_choice }
def agent_execute_task(state):
inputs= state["input"]
input_to_agent = state["input_to_agent"]
print(Fore.CYAN+input_to_agent + Fore.RESET)
# choosen agent will execute the task
choosen_agent = state['agent_choice']
if choosen_agent=='ContentCreator':
structured_respond=content_creator.invoke({"product_desc":input_to_agent})
respond='\n'.join([structured_respond.Title,structured_respond.Message,''.join(structured_respond.Tags)])
elif choosen_agent=="DigitalArtist":
respond=digital_artist.invoke(input_to_agent)
else:
respond="please reselect the agent, there are only 2 agents available: 1.ContentCreator or 2.DigitalArtist"
print(Fore.CYAN+ "agent_output: \n" + respond + Fore.RESET)
return {"agent_use_tool_respond": respond} 마지막으로 노드와 에지를 연결하여 모든 것을 통합하여 휴먼 인 더 루프 멀티 에이전트 워크플로우를 구성합니다. 계속 진행할 준비가 되면 그래프가 컴파일됩니다.:
from langgraph.graph import END, StateGraph
# Define a new graph
workflow = StateGraph(State)
# Define the two nodes
workflow.add_node("start", human_assign_to_agent)
workflow.add_node("end", agent_execute_task)
# This means that this node is the first one called
workflow.set_entry_point("start")
workflow.add_edge("start", "end")
workflow.add_edge("end", END)
# Finally, we compile it!
# This compiles it into a LangChain Runnable,
# meaning you can use it as you would any other runnable
app = workflow.compile()휴먼 에이전트 워크플로우 시작하기
이제 앱을 실행합니다. 주어진 작업에 사용 가능한 에이전트 중 한 명을 배정하라는 메시지가 표시됩니다.
프로모션 텍스트 작성을 위한 프롬프트
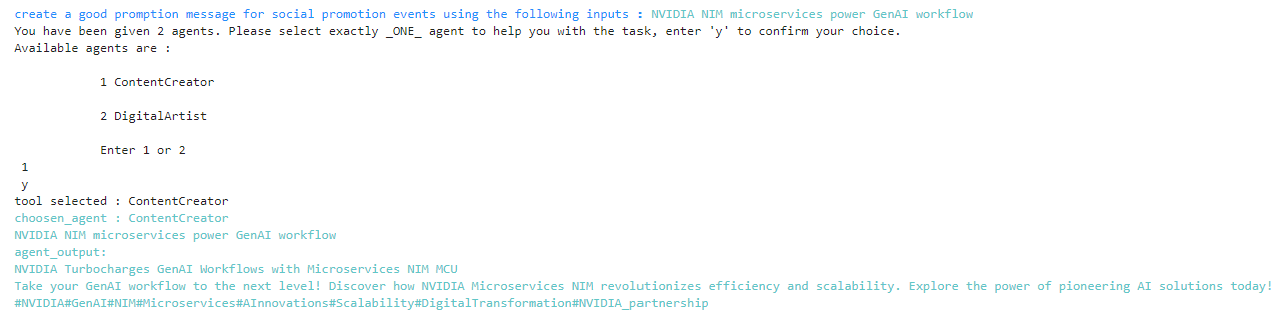
먼저 콘텐츠 크리에이터 에이전트에게 제목, 메시지 및 소셜 미디어 해시태그를 포함한 프로모션 텍스트를 작성하도록 요청합니다(그림 2). 결과가 만족스러울 때까지 이 과정을 반복합니다.
Python 코드 샘플입니다:
my_query="create a good promotional message for social promotion events using the following inputs"
product_desc="NVIDIA NIM microservices power GenAI workflow"
respond=app.invoke({"input":my_query, "input_to_agent":product_desc})사람이 작업에 대해 1 = 콘텐츠 제작자 에이전트를 선택합니다. 에이전트는 그림 3과 같이 agent_output 을 실행하고 반환합니다.
일러스트를 만들기 위한 프롬프트
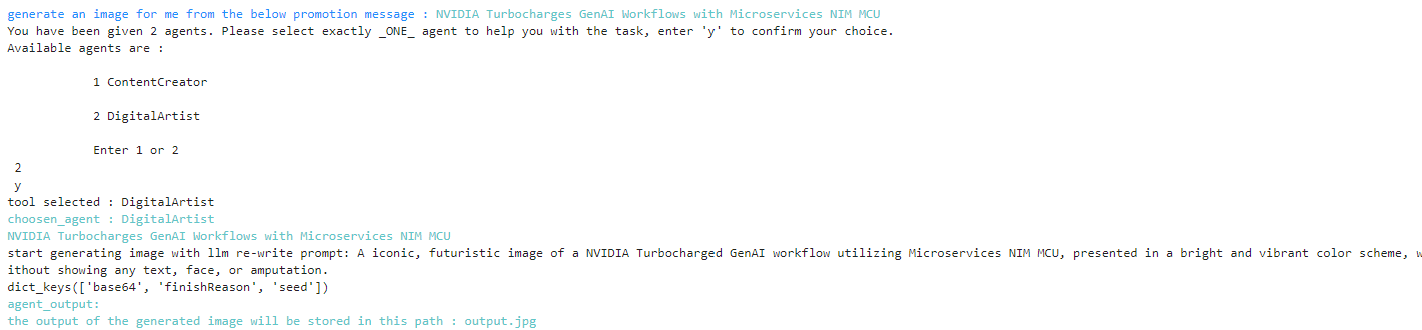
결과가 만족스러우면 디지털 아티스트 에이전트에게 소셜 미디어 홍보용 아트웍을 만들도록 요청합니다(그림 4).
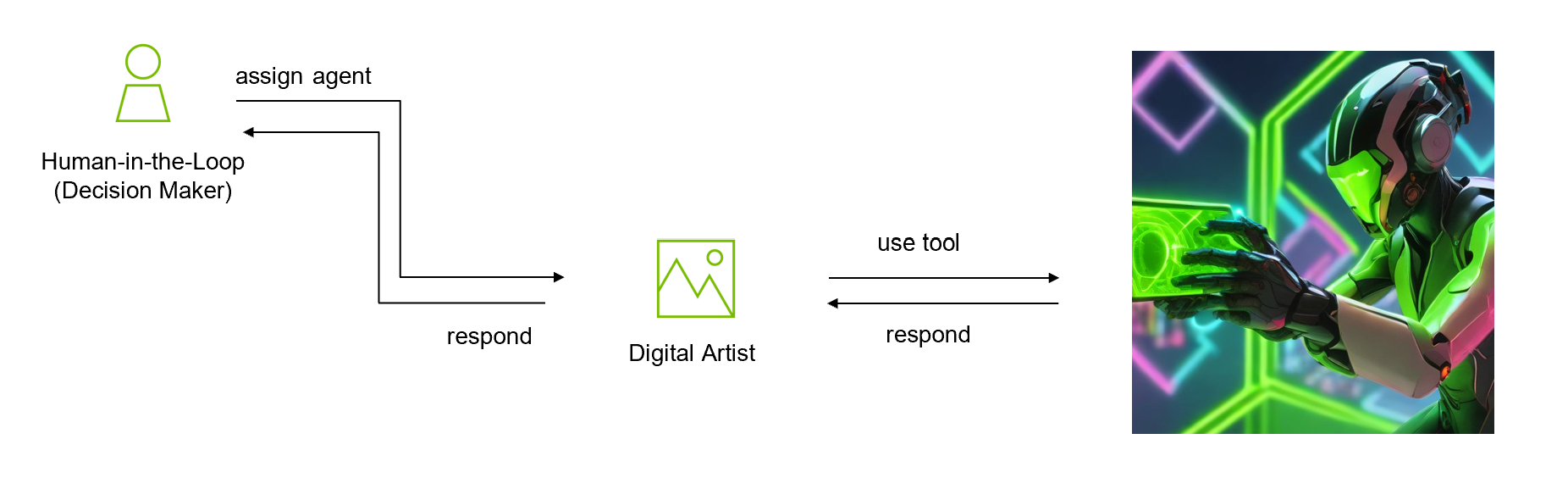
다음 Python 코드 샘플은 콘텐츠 크리에이터 에이전트가 생성한 제목을 이미지 프롬프트의 입력으로 사용합니다:
## taken the output from the Title from the output of Content Creator Agent
prompt_for_image=respond['agent_use_tool_respond'].split('\n')[0].split(':')[-1].strip()
## Human decision maker give instruction to the agent workflow app
input_query="generate an image for me from the below promotion message"
respond2=app.invoke({"input":input_query, "input_to_agent":prompt_for_image})생성된 이미지는 output.jpg로 저장됩니다.
고품질 결과물을 위한 반복 작업
생성된 이미지를 반복하여 원하는 결과를 얻기 위해 다양한 아트웍의 변형을 얻을 수 있습니다(그림 6). 콘텐츠 크리에이터 에이전트의 입력 프롬프트를 약간 조정하면 디지털 아티스트 에이전트에서 다양한 이미지를 얻을 수 있습니다.

최종 결과물 다듬기
마지막으로 후처리를 수행하고 두 에이전트의 결합된 결과물을 다듬어 최종 시각적 검토를 위해 마크다운 형식으로 서식을 지정합니다(그림 7).

NVIDIA NIM 마이크로서비스 및 AI 툴로 AI 에이전트 강화하기
이 블로그 게시물에서는 콘텐츠 제작 워크플로우를 간소화하기 위해 NVIDIA NIM 마이크로서비스와 LangChain의 LangGraph를 사용하여 휴먼 인 더 루프 AI 에이전트를 구축하는 방법에 대해 알아보았습니다. 워크플로우에 AI 에이전트를 통합하면 콘텐츠 제작 속도를 높이고, 수작업을 줄이며, 크리에이티브 프로세스를 완벽하게 제어할 수 있습니다.
NVIDIA NIM 마이크로서비스를 사용하면 AI 기반 작업을 효율적이고 유연하게 확장할 수 있습니다. 홍보 메시지를 제작하든 비주얼을 디자인하든, 휴먼 인 더 루프 AI 에이전트는 워크플로우를 최적화하고 생산성을 높일 수 있는 강력한 솔루션을 제공합니다.
추가 리소스를 통해 자세히 알아보세요:
- NVIDIA NIM 마이크로서비스 및 LangChain으로 AI 에이전트 구축하기
- LangGraph를 사용하여 에이전트 로직에 휴먼 인 더 루프 통합하기
- 노트북용 환경 구축
- Llama 3.1 405B NIM 마이크로서비스 지시하기
관련 리소스
- NGC 컨테이너: 아이 컨택
- NGC 컨테이너: ASR Parakeet CTC Riva 1.1b
- NGC 컨테이너: Mistral-Nemo-12B-Instruct
- SDK: Llama3 70B Instruct NIM
- SDK: NVIDIA Tokkio
- SDK: BioNeMo 서비스