
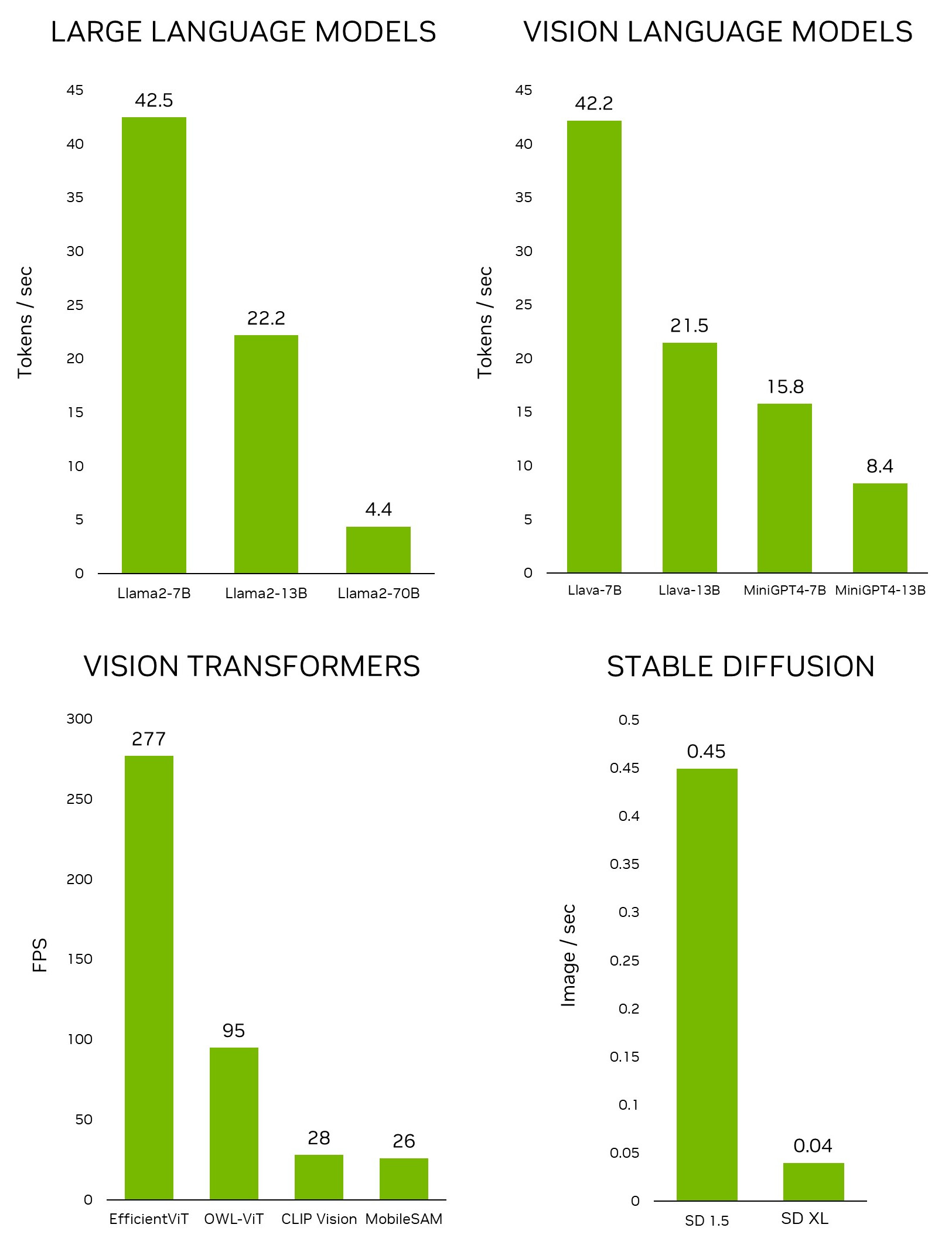
Recently, NVIDIA unveiled Jetson Generative AI Lab, which empowers developers to explore the limitless possibilities of generative AI in a real-world setting with NVIDIA Jetson edge devices. Unlike other embedded platforms, Jetson is capable of running large language models (LLMs), vision transformers, and stable diffusion locally. That includes the largest Llama-2-70B model on Jetson AGX Orin at interactive rates.
To swiftly test the latest models and applications on Jetson, use the tutorials and resources provided on the Jetson Generative AI lab. Now you can focus on uncovering the untapped potential of generative AIs in the physical world.
In this post, we explore the exciting generative AI applications that you can run and experience on Jetson devices, all of which are comprehensively covered in the lab tutorials.
Generative AI at the edge
In the rapidly evolving landscape of AI, the spotlight shines brightly on generative models and the following in particular:
- LLMs that are capable of engaging in human-like conversations.
- Vision language models (VLMs) that provide LLMs with the ability to perceive and understand the real world through a camera.
- Diffusion models that can transform simple text prompts into stunning visual creations.
These remarkable AI advancements have captured the imagination of many. However, if you delve into the infrastructure supporting this cutting-edge model inference, you would often find them tethered to the cloud, reliant on data centers for their processing power. This cloud-centric approach leaves certain edge applications, requiring high-bandwidth low-latency data processing, largely unexplored.
The emerging trend of running LLMs and other generative models in local environments is gaining momentum within developer communities. Thriving online communities, like r/LocalLlama on Reddit, provide a platform for enthusiasts to discuss the latest developments in generative AI technologies and their real-world applications. Numerous technical articles published on platforms like Medium delve into the intricacies of running open-source LLMs in local setups, with some taking advantage of NVIDIA Jetson.
The Jetson Generative AI Lab serves as a hub for discovering the latest generative AI models and applications and learning how to run them on Jetson devices. As the field evolves at a rapid pace, with new LLMs emerging almost daily and advancements in quantization libraries reshaping benchmarks overnight, NVIDIA recognizes the importance of offering the most up-to-date information and effective tools. We offer easy-to-follow tutorials and prebuilt containers.
The enabling force is jetson-containers, an open-source project thoughtfully designed and meticulously maintained to build containers for Jetson devices. Using GitHub Actions, it is building 100 containers in CI/CD fashion. These empower you to quickly test the latest AI models, libraries, and applications on Jetson without the hassle of configuring underlying tools and libraries.
The Jetson Generative AI lab and jetson-containers enable you to focus on exploring the limitless possibilities of generative AI in real-world settings with Jetson.
Walkthrough
Here are some of the exciting generative AI applications that run on the NVIDIA Jetson device available in the Jetson Generative AI lab.
stable-diffusion-webui
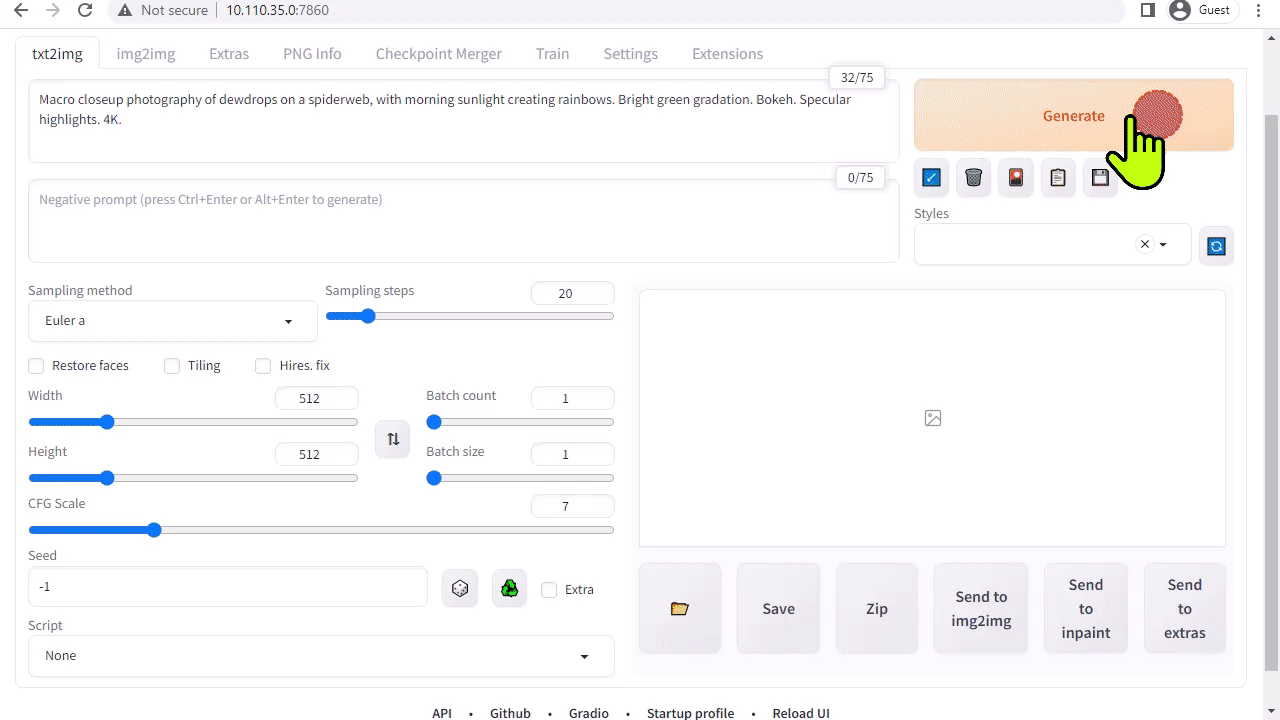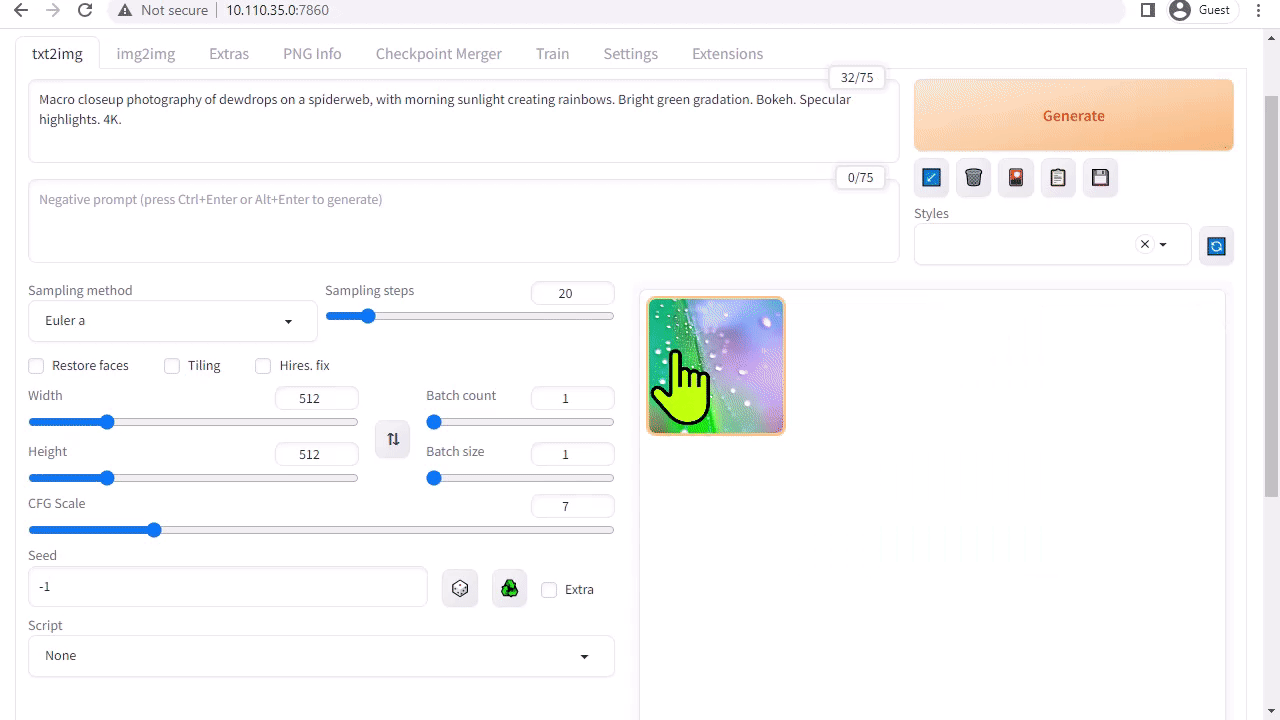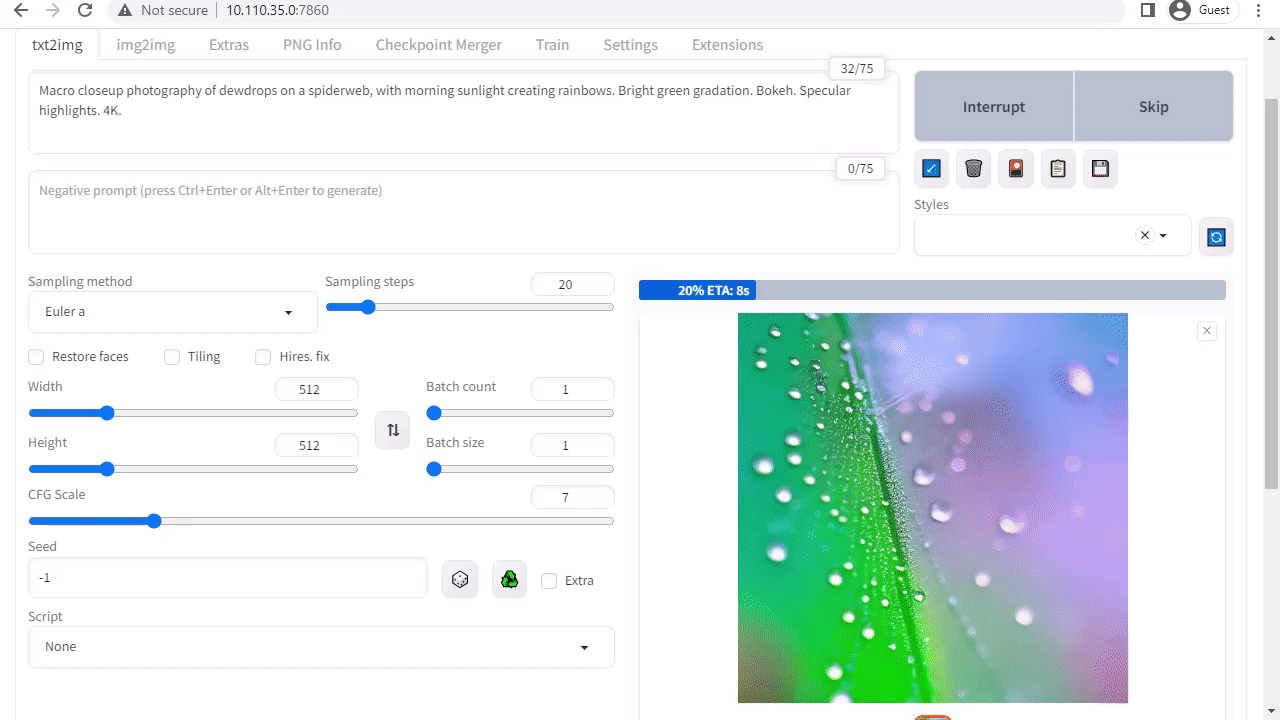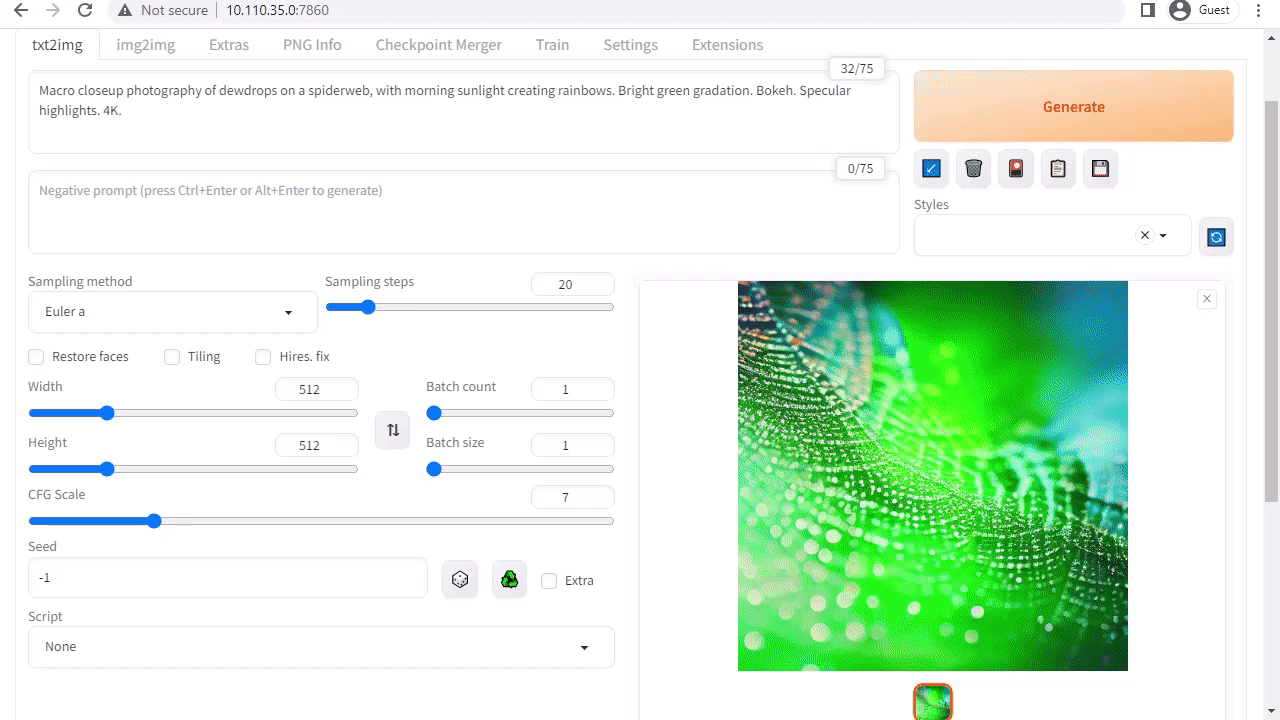
A1111’s stable-diffusion-webui provides a user-friendly interface to Stable Diffusion released by Stability AI. It enables you to perform many tasks, including the following:
- Txt2img: Generates an image based on a text prompt.
- img2img: Generates an image from an input image and a corresponding text prompt.
- inpainting: Fills in the missing or masked parts of the input image.
- outpainting: Expands the input image beyond its original borders.
The web app downloads the Stable Diffusion v1.5 model automatically during the first start, so you can start generating your image right away. If you have a Jetson Orin device, it is as easy as executing the following commands, as explained in the tutorial.
git clone https://github.com/dusty-nv/jetson-containers
cd jetson-containers
./run.sh $(./autotag stable-diffusion-webui)
For more information about running stable-diffusion-webui, see the Jetson Generative AI lab tutorial. Jetson AGX Orin is also capable of running the newer Stable Diffusion XL (SDXL) models, which generated the featured image at the top of this post.
text-generation-webui
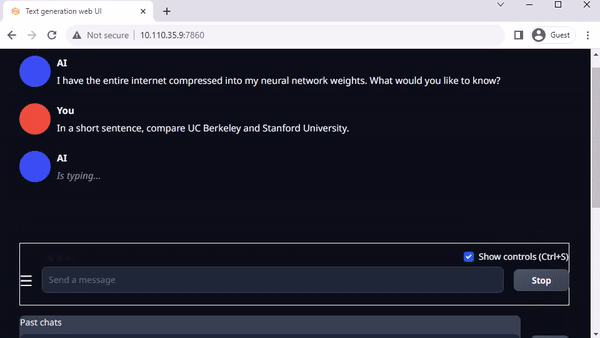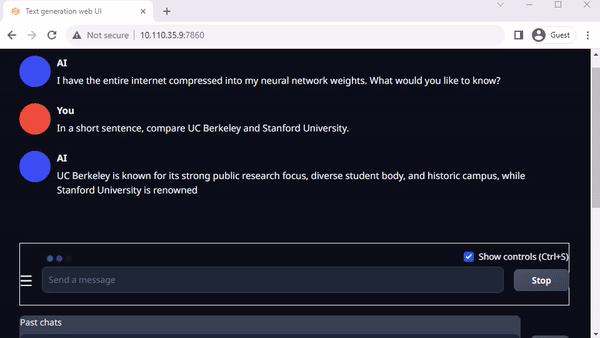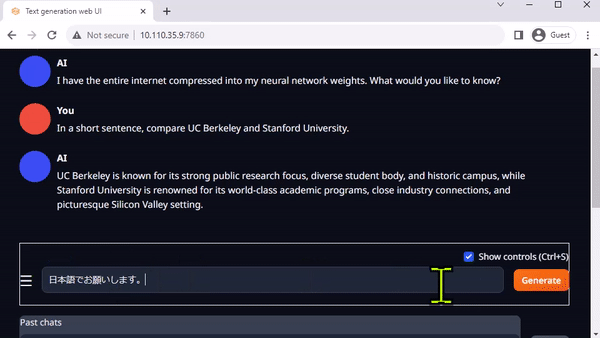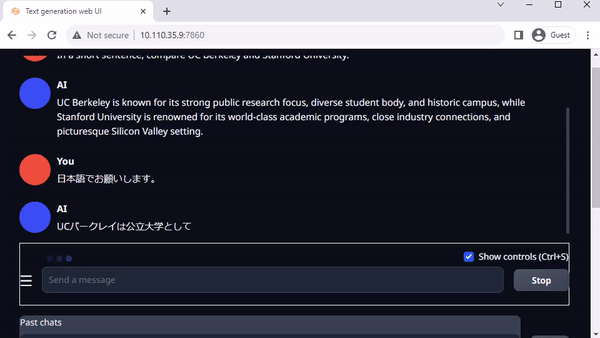
Oobabooga’s text-generation-webui is another popular Gradio-based web interface for running LLMs in a local environment. The official repository provides one-click installers for platforms, but jetson-containers offer an even easier method.
Using the interface, you can easily download a model from the Hugging Face model repository. With 4-bit quantization, the rule of thumb is that Jetson Orin Nano can generally accommodate a 7B parameter model, Jetson Orin NX 16GB can run a 13B parameter model, and Jetson AGX Orin 64GB can run whopping 70B parameter models.
Many people are now working on Llama-2, Meta’s open-source large language model, available for free for research and commercial use. There are Llama-2–based models also trained using techniques like supervised fine-turning (SFT) and reinforcement learning from human feedback (RLHF). Some even claim that it is surpassing GPT-4 on some benchmarks.
Text-generation-webui provides extensions and enables you to develop your own extensions. This can be used to integrate your application as you later see in the llamaspeak example. It also has support for multimodal VLMs like Llava and chatting about images.
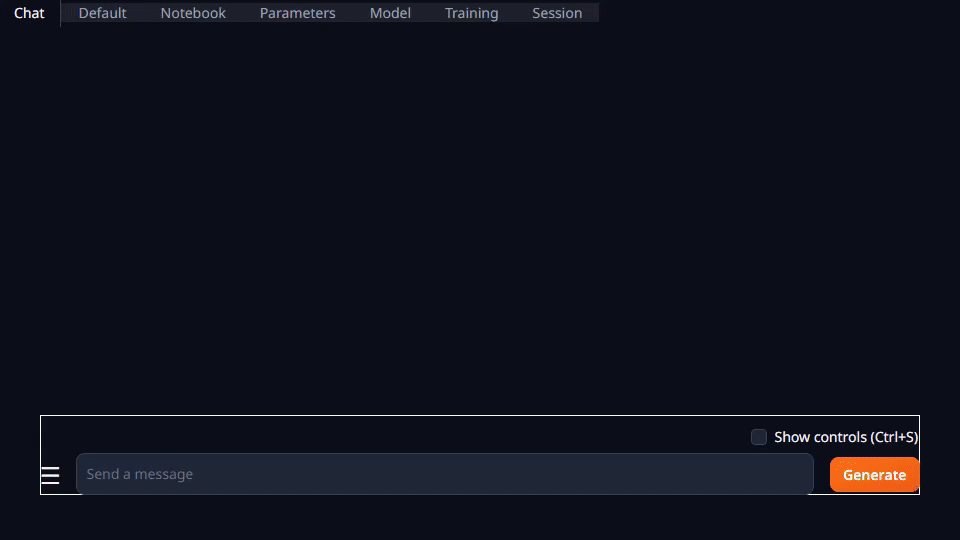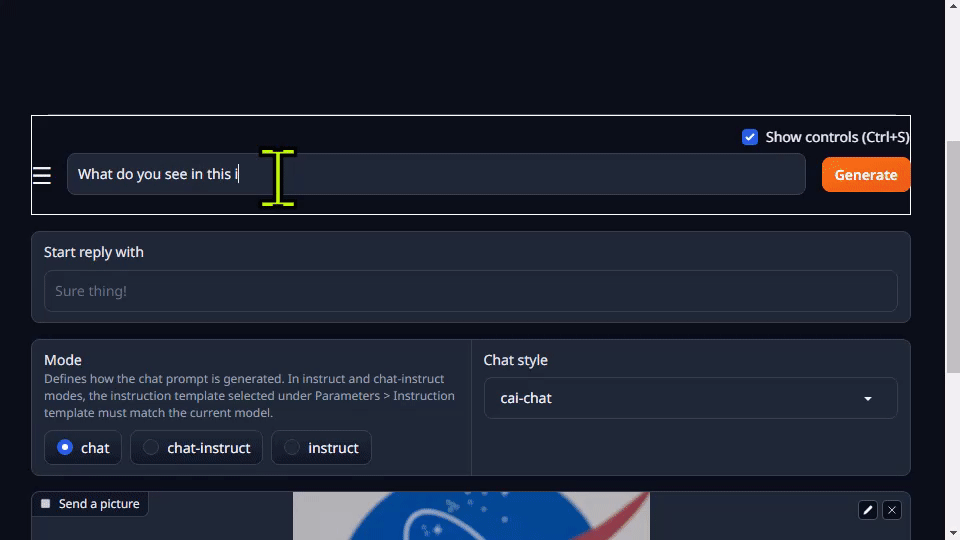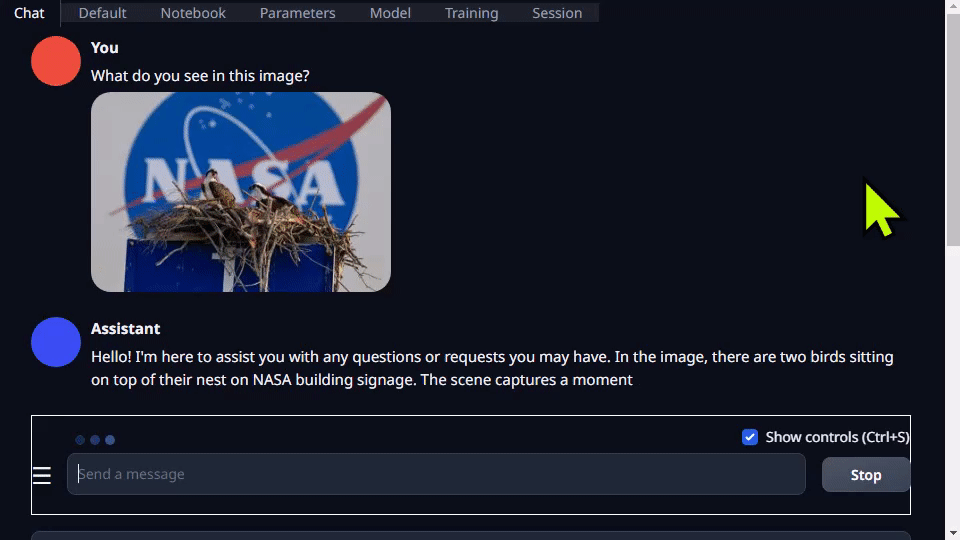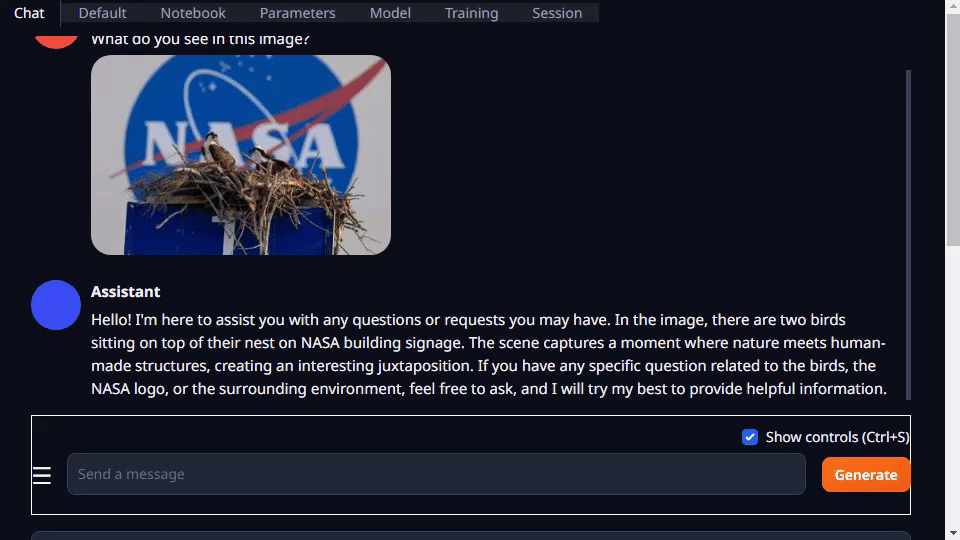
For more information about running text-generation-webui, see the Jetson Generative AI lab tutorial.
llamaspeak
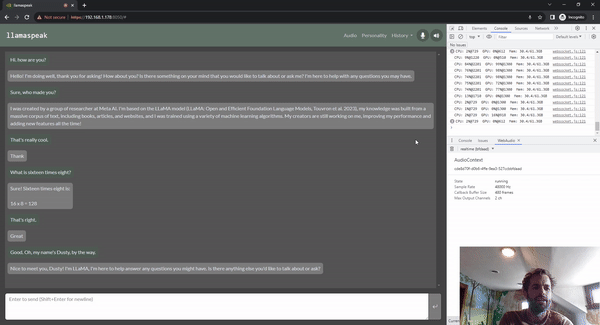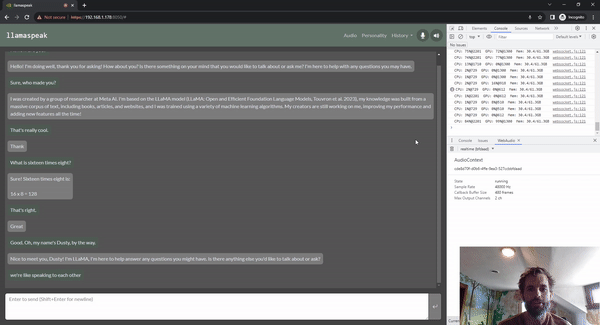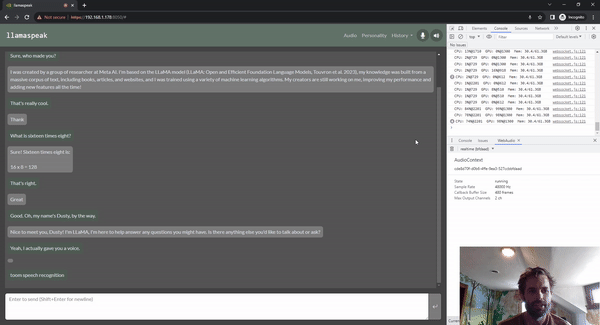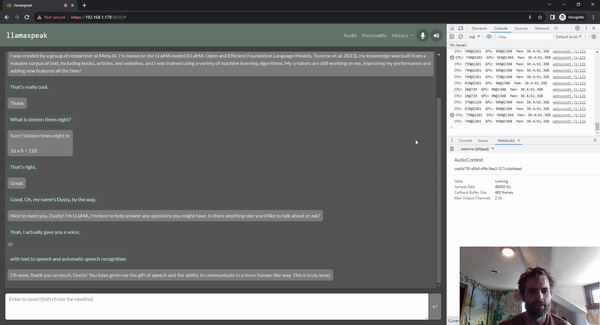
Llamaspeak is an interactive chat application that employs live NVIDIA Riva ASR/TTS to enable you to carry out verbal conversations with a LLM running locally. It is currently offered as a part of jetson-containers.
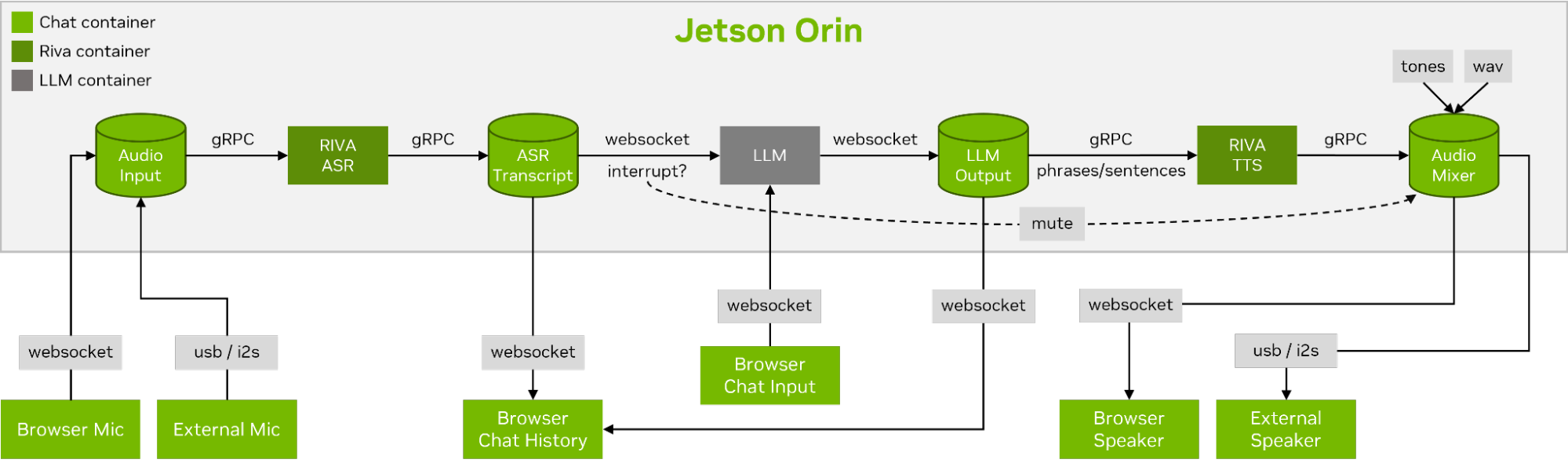
To carry out a smooth and seamless voice conversation, minimizing the time to the first output token of an LLM is critical. On top of that, llamaspeak is designed to handle conversational interruption so that you can start talking while llamaspeak is still TTS-ing the generated response. Container microservices are used for Riva, the LLM, and the chat server.
llamaspeak has a responsive interface with low-latency audio streaming from browser microphones or a microphone connected to your Jetson device. For more information about running it yourself, see the jetson-containers documentation.
NanoOWL

Open World Localization with Vision Transformers (OWL-ViT) is an approach for open-vocabulary detection, developed by Google Research. This model enables you to detect objects by providing text prompts for those objects.
For example, to detect people and cars, prompt the system with text describing the classes:
prompt = “a person, a car”
This is incredibly valuable for rapidly developing new applications, without needing to train a new model. To unlock applications at the edge, our team developed a project, NanoOWL, which optimizes this model with NVIDIA TensorRT to obtain real-time performance on NVIDIA Jetson Orin Platforms (~95FPS encoding speed on Jetson AGX Orin). This performance means that you can run OWL-ViT well above the common camera frame rates.
The project also contains a new tree detection pipeline that enables you to combine the accelerated OWL-ViT model with CLIP to enable zero-shot detection and classification at any level. For example, to detect faces and classify them as happy or sad, use the following prompt:
prompt = “[a face (happy, sad)]”
To detect faces and then detect facial features in each region of interest, use the following prompt:
prompt = “[a face [an eye, a nose, a mouth]]”
Combine them:
prompt = “[a face (happy, sad)[an eye, a nose, a mouth]]”
The list goes on. While the accuracy of this model may be better for some objects or classes than others, the ease of development means you can quickly try different prompts and find out if it works for you. We look forward to seeing what amazing applications that you develop!
Segment Anything Model
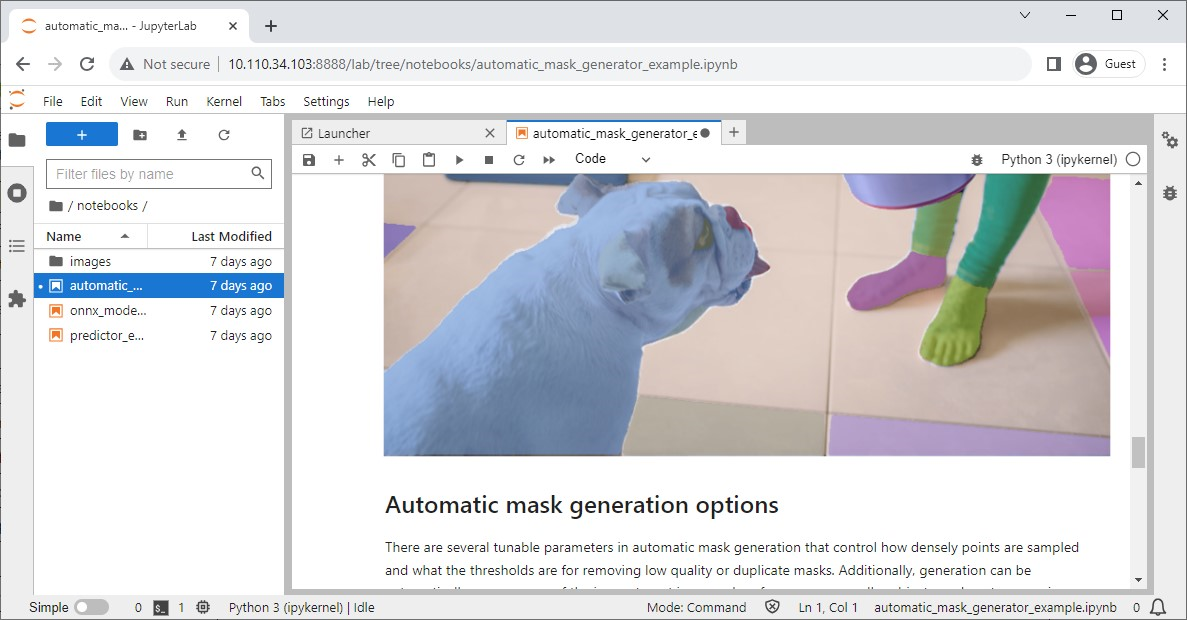
Meta released the Segment Anything model (SAM), an advanced image segmentation model designed to precisely identify and segment objects within images regardless of their complexity or context.
Their official repository also has Jupyter notebooks to easily check the impact of the model, and jetson-containers offer a convenient container that has Jupyter Lab built in.
NanoSAM

Segment Anything (SAM) is an incredible model that is capable of turning points into segmentation masks. Unfortunately, it does not run in real time, which limits its usefulness in edge applications.
To get past this limitation, we’ve recently released a new project, NanoSAM, which distills the SAM image encoder into a lightweight model. It also optimizes the model with NVIDIA TensorRT to enable real-time performance on NVIDIA Jetson Orin platforms. Now, you can easily turn your existing bounding box or keypoint detector into an instance segmentation model, without any training required.
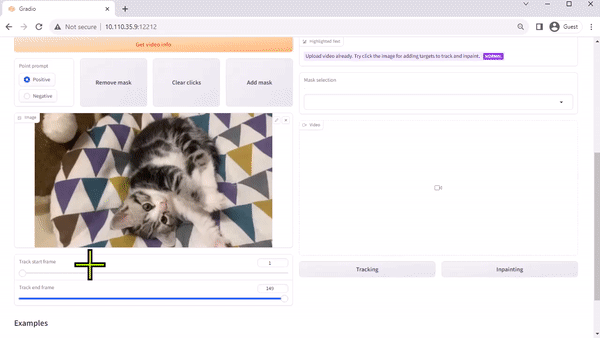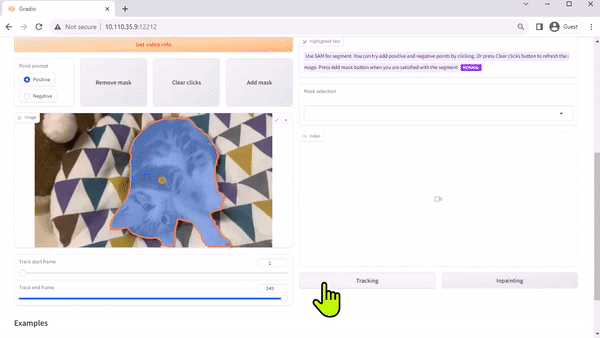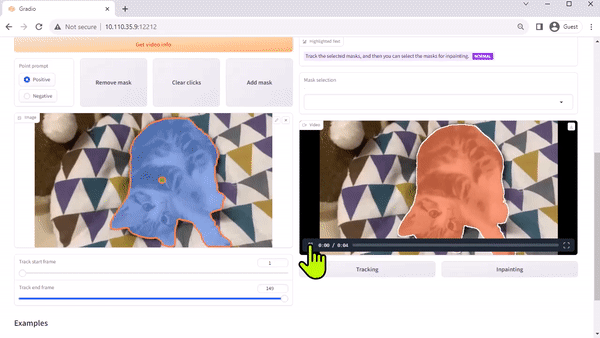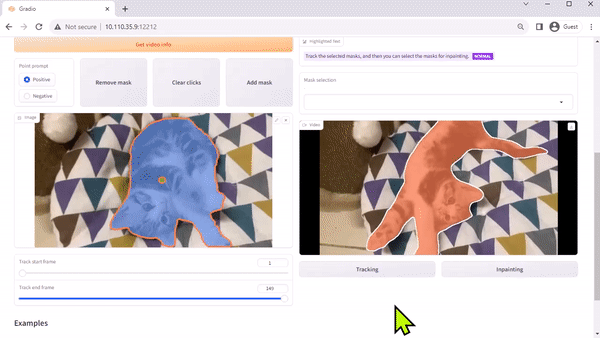
Track Anything Model
The Track Anything Model (TAM) is, as the team’s paper explains, “Segment Anything meets videos.” Their open-sourced, Gradio-based interface enables you to click on a frame of an input video to specify anything to track and segment. It even showcases an additional capability of removing the tracked object by inpainting.
NanoDB
In addition to effectively indexing and searching your data at the edge, these vector databases are often used in tandem with LLMs for retrieval-augmented generation (RAG) for long-term memory beyond their built-in context length (4096 tokens for Llama-2 models). Vision-language models also use the same embeddings as inputs.
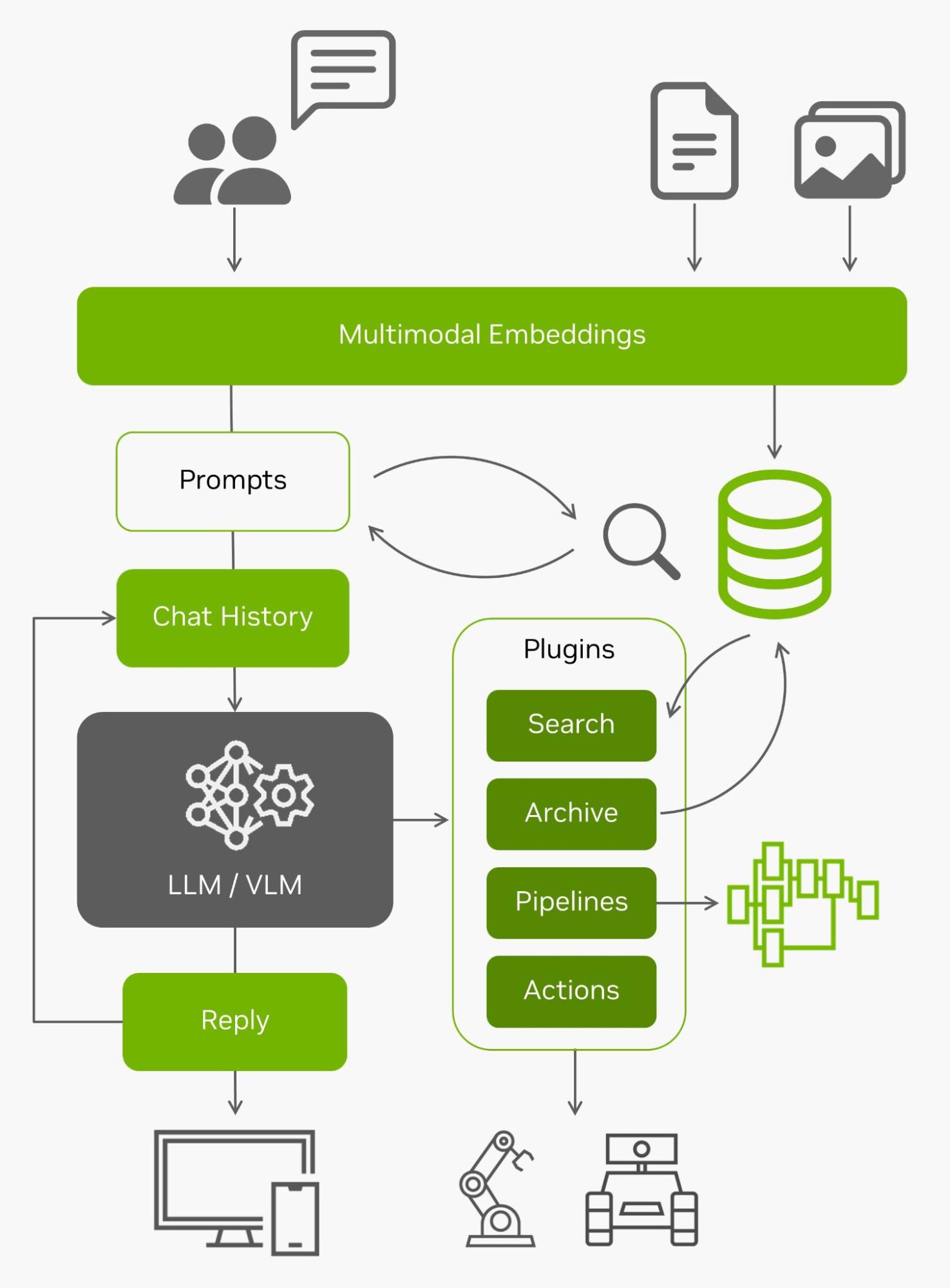
With all that incoming live data from the edge and the ability to understand it, they become agents capable of interacting with the real world. For more information about experimenting with using NanoDB on your own imagery and dataset, see the lab tutorial.
Conclusion
There you have it! Numerous exciting generative AI applications are emerging, and you can easily run them on Jetson Orin following these tutorials. To witness the incredible capabilities of generative AIs running locally, explore the Jetson Generative AI lab.
If you build your own generative AI application on Jetson and are interested in sharing your ideas, be sure to showcase your creation on the Jetson Projects forum.

Join us Tuesday, November 7, 2023 at 9 a.m. PT for a webinar diving even deeper into many of the topics discussed in this post, along with a live Q&A!
- Accelerated APIs and quantization methods for deploying LLMs and VLMs on NVIDIA Jetson
- Optimizing vision transformers with NVIDIA TensorRT
- Multimodal agents and vector databases
- Live conversations with NVIDIA Riva ASR/TTS
