NVIDIA는 1조 9천억 개의 합성 생성 데이터를 포함하여 매우 정확한 거대 언어 모델(LLM)의 사전 학습을 위한 6조 3천억 개의 토큰으로 구성된 영어 커먼 크롤(Common Crawl) 데이터 세트인 Nemotron-CC의 출시를 발표하게 되었습니다. 최첨단 LLM을 훈련하는 데 있어 핵심 중 하나는 고품질의 사전 훈련 데이터 세트이며, 최근 Meta Llama 시리즈와 같은 최고의 LLM은 15조 개의 토큰으로 구성된 방대한 양의 데이터로 훈련되었습니다.
그러나 이 15조 개의 토큰의 정확한 구성에 대해서는 알려진 바가 거의 없습니다. Nemotron-CC는 이 문제를 해결하고 더 많은 커뮤니티가 매우 정확한 LLM을 훈련할 수 있도록 하는 것을 목표로 합니다. 일반적으로 인터넷 크롤링 데이터, 일반적으로 커먼 크롤링에서 제공하는 것이 토큰의 가장 큰 소스입니다. FineWeb-Edu와 DCLM과 같은 최근의 개방형 커먼 크롤 데이터 세트는 비교적 짧은 토큰 범위에서 벤치마크 정확도를 크게 향상시키는 방법을 보여주었습니다. 그러나 이는 데이터의 90%를 제거하고 달성한 것입니다. 이로 인해 Llama 3.1의 15조 토큰과 같이 긴 토큰 지평 훈련에는 적합성하지 않습니다.
Nemotron-CC는 이러한 격차를 메우고 분류기 조합, 합성 데이터 재구문, 휴리스틱 필터에 대한 의존도 감소를 통해 일반 크롤링 데이터를 LLM 훈련에 적합한 고품질 데이터 세트로 변환하는 방법을 보여줌으로써 Llama 3.1 8B보다 더 나은 LLM을 훈련할 수 있습니다.
결과
그림 1은 1조 개의 토큰에 대해 8B 파라미터 모델을 훈련할 때, 훈련 데이터의 73%에 해당하는 영어 공통 크롤링 부분만 변경했을 때의 MMLU 점수입니다. 선도적인 개방형 영어 커먼 크롤링 데이터 세트인 DCLM과 비교했을 때, 고품질 하위 집합인 Nemotron-CC-HQ는 MMLU를 +5.6까지 증가시킵니다.
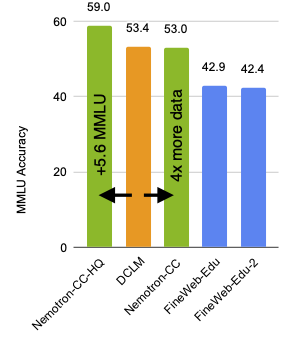
또한 6조 3천억 개의 전체 토큰 데이터 세트는 MMLU의 DCLM과 일치하지만, 4배 더 많은 고유한 실제 토큰을 포함하고 있습니다. 따라서 긴 토큰 기간 동안 효과적인 학습이 가능합니다. 15조 개의 토큰에 대해 학습된 80억 개의 파라미터 모델(이 중 7조 2천억 개는 Nemotron-CC에서 제공)이 Llama 3.1 8B 모델보다 더 우수합니다: MMLU에서 +5, ARC-Challenge에서 +3.1, 10개의 다양한 작업에서 평균 +0.5를 기록했습니다.
주요 인사이트
이러한 결과를 이끌어낸 몇 가지 주요 인사이트는 다음과 같습니다:
- 다양한 모델 기반 분류기를 조합하면 더 크고 다양한 고품질의 토큰 세트를 선택할 수 있습니다.
- 재구문을 통해 품질이 낮은 데이터의 노이즈와 오류를 효과적으로 줄이고 고품질 데이터에서 새로운 고유 토큰으로 다양한 변형을 생성하여 다운스트림 작업에서 더 나은 결과를 얻을 수 있습니다.
- 고품질 데이터에 대해 기존의 비학습 휴리스틱 필터를 비활성화하면 정확도를 해치지 않으면서도 고품질 토큰 수율을 더욱 높일 수 있습니다.
데이터 큐레이션 단계
NVIDIA NeMo Curator를 사용하여 커먼 크롤링에서 데이터를 추출하고 정리한 다음:
- 영어에 맞게 필터링
- 글로벌 퍼지 중복 제거와 정확한 하위 문자열 중복 제거를 수행했습니다.
- 품질 분류를 위해 DCLM, fineweb-edu와 같은 모델 기반 필터를 활용했습니다.
- 다양한 휴리스틱 및 난해성 필터를 적용하여 품질이 낮은 데이터를 추가로 제거했습니다.
또한, 합성 데이터 생성 파이프라인을 활용하여 약 2조 개의 합성 데이터를 생성했습니다.
합성 데이터 생성 파이프라인을 포함한 전체 레시피는 곧 NVIDIA/NeMo-Curator GitHub 리포지토리에 병합될 예정입니다. 업데이트를 받으려면 리포지토리를 구독하세요.
결론
Nemotron-CC는 개방형 대규모 고품질 영어 공통 크롤링 데이터셋으로, 짧은 토큰과 긴 토큰 범위 모두에서 매우 정확한 LLM을 사전 훈련할 수 있습니다. 향후에는 특수 수학 사전 훈련 데이터 세트와 같이 최첨단 LLM 사전 훈련의 핵심 요소인 더 많은 데이터 세트를 공개할 예정입니다.
- 커먼 크롤에서 데이터 세트를 다운로드하세요.
- NeMo 큐레이터를 사용해 나만의 데이터 세트를 큐레이션하세요.
- 기술적 세부 사항에 대한 자세한 내용은 Nemotron-CC에서 확인하세요: 일반 크롤링을 정교한 롱호라이즌 사전 학습 데이터세트로 변환하기에서 자세히 알아보세요.
감사의 말
데이터 세트를 호스팅해 주신 Common Crawl Foundation에 감사드립니다. 백서를 개선하는 데 도움이 되는 귀중한 피드백을 제공해 주신 Pedro Ortiz Suarez와 데이터 서식과 레이아웃을 개선하는 데 도움을 주신 Greg Lindahl에게도 감사드립니다.
관련 리소스
- GTC 세션: 효율적인 거대 언어 모델(LLM) 사용자 맞춤화
- GTC 세션: NVIDIA NeMo 및 AWS를 사용한 LLM 훈련 최적화
- GTC 세션: 클라우드에서 LLM 수명 주기 가속화하기
- NGC 컨테이너: Nemotron-4-340b-instruct
- NGC 컨테이너: Llama-3.1-Nemotron-70B-Instruct
- NGC 컨테이너: Nemotron-4-340B-Reward