NVIDIA NeMo Curator for Developers
NVIDIA NeMo™ Curator improves generative AI model accuracy by processing text, image, and video data at scale for training and customization. It also provides prebuilt pipelines for generating synthetic data to customize and evaluate generative AI systems.
With NeMo Curator, part of the NVIDIA NeMo software suite for managing the AI agent lifecycle, developers can curate high-quality data and train highly accurate generative AI models for various industries, including finance, retail, manufacturing and telecommunications.
NeMo Curator, along with NeMo microservices enables developers to create data flywheels and continuously optimize generative AI agents, enhancing the overall experience for end users.
How NVIDIA NeMo Curator Works
NeMo Curator streamlines data-processing tasks, such as data downloading, extraction, cleaning, quality filtering, deduplication, and blending or shuffling, providing them as Pythonic APIs, making it easier for developers to build data-processing pipelines. High-quality data processed from NeMo Curator enables you to achieve higher accuracy with less data and faster model convergence, reducing training time.
NeMo Curator supports the processing of text, image, and video modalities and can scale up to 100+ PB of data.
NeMo Curator provides a customizable and modular interface, allowing you to select the building blocks for your data processing pipelines. Please refer to the architecture diagrams below to see how you can build data processing pipelines.
Text Data Processing
This architecture diagram shows the various features available for processing text. At a high level, a typical text processing pipeline begins with downloading data from public sources or private repositories and performing cleaning steps, such as fixing Unicode characters. Next, heuristic filters—such as word count—are applied, followed by deduplication, advanced quality filtering using classifier models for quality and domain, and finally, data blending.
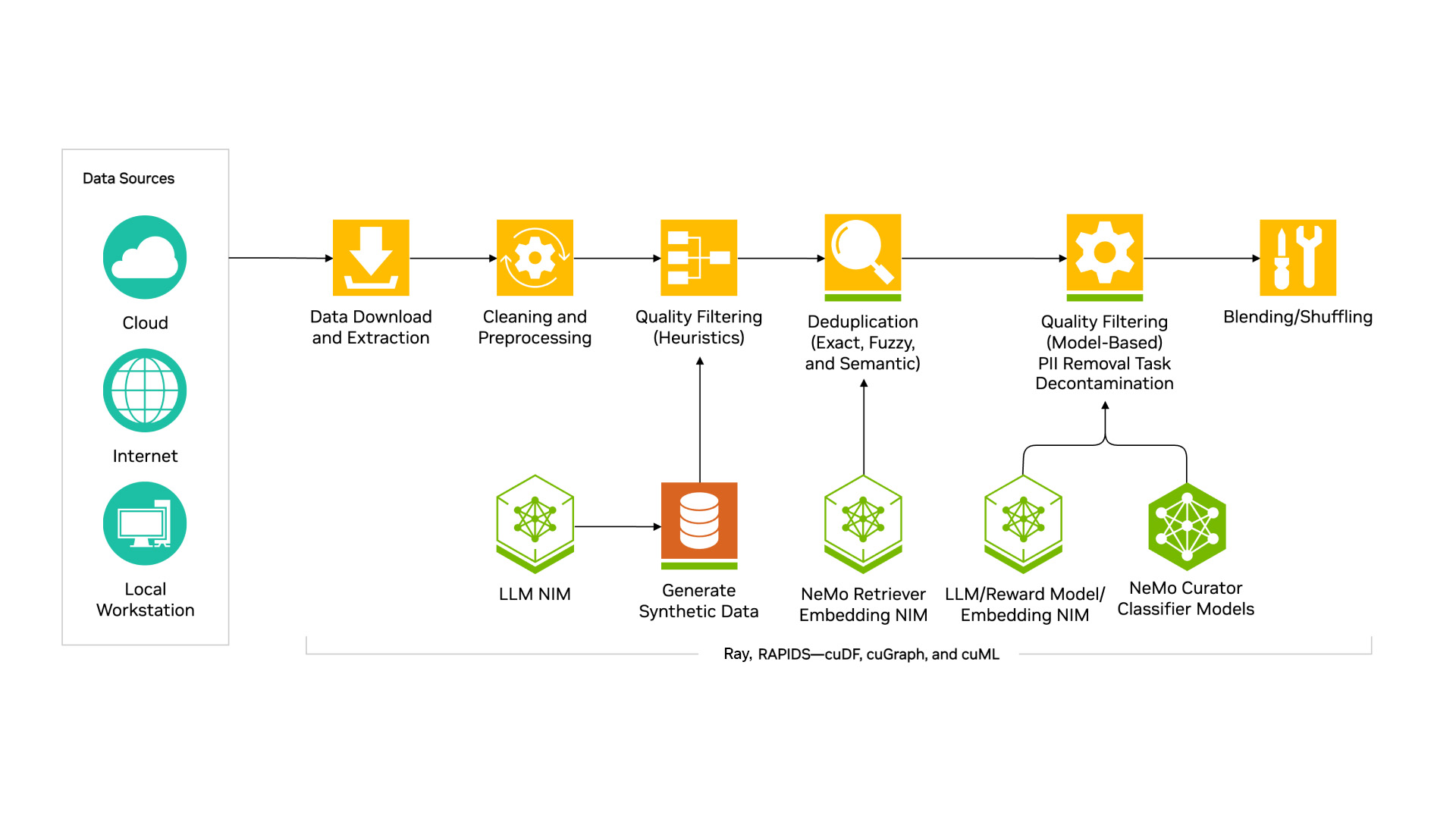
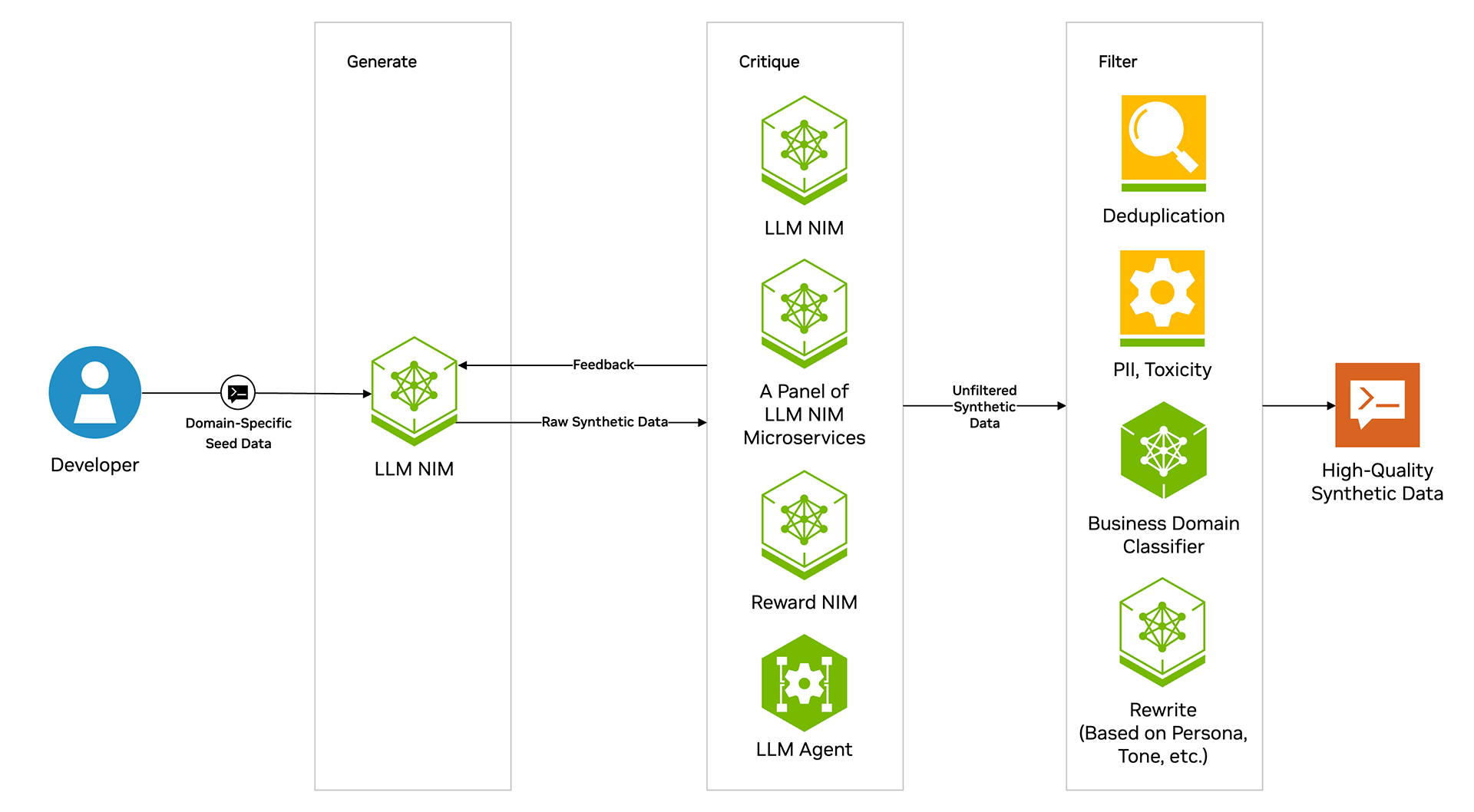
Synthetic Data Generation
NeMo Curator has a simple, easy-to-use set of tools that let you use pre-built synthetic data generation pipelines or build your own. Any model inference service that uses the OpenAI API is compatible with the synthetic data generation module, allowing you to generate your data from any model.
NeMo Curator provides pre-built pipelines for several use cases to help you get started easily, including evaluating and customizing embedding models, prompt generation (open Q&A, closed Q&A, writing, math/coding), synthetic two-turn prompt generation, dialogue generation, and entity classification.
Video Data Processing
This architecture diagram illustrates the various features available through the early access program for processing high-quality videos.
A typical pipeline has the following steps
- Video decoding and splitting: Decode long videos and split them into semantically shorter clips.
Transcoding: Convert all the short videos to a consistent format.
Captioning: Caption videos using domain-specific state-of-the-art vision language models (VLMs) to describe the clips in detail.
- Text embedding: Create embeddings of text captions for downstream semantic search and deduplication.
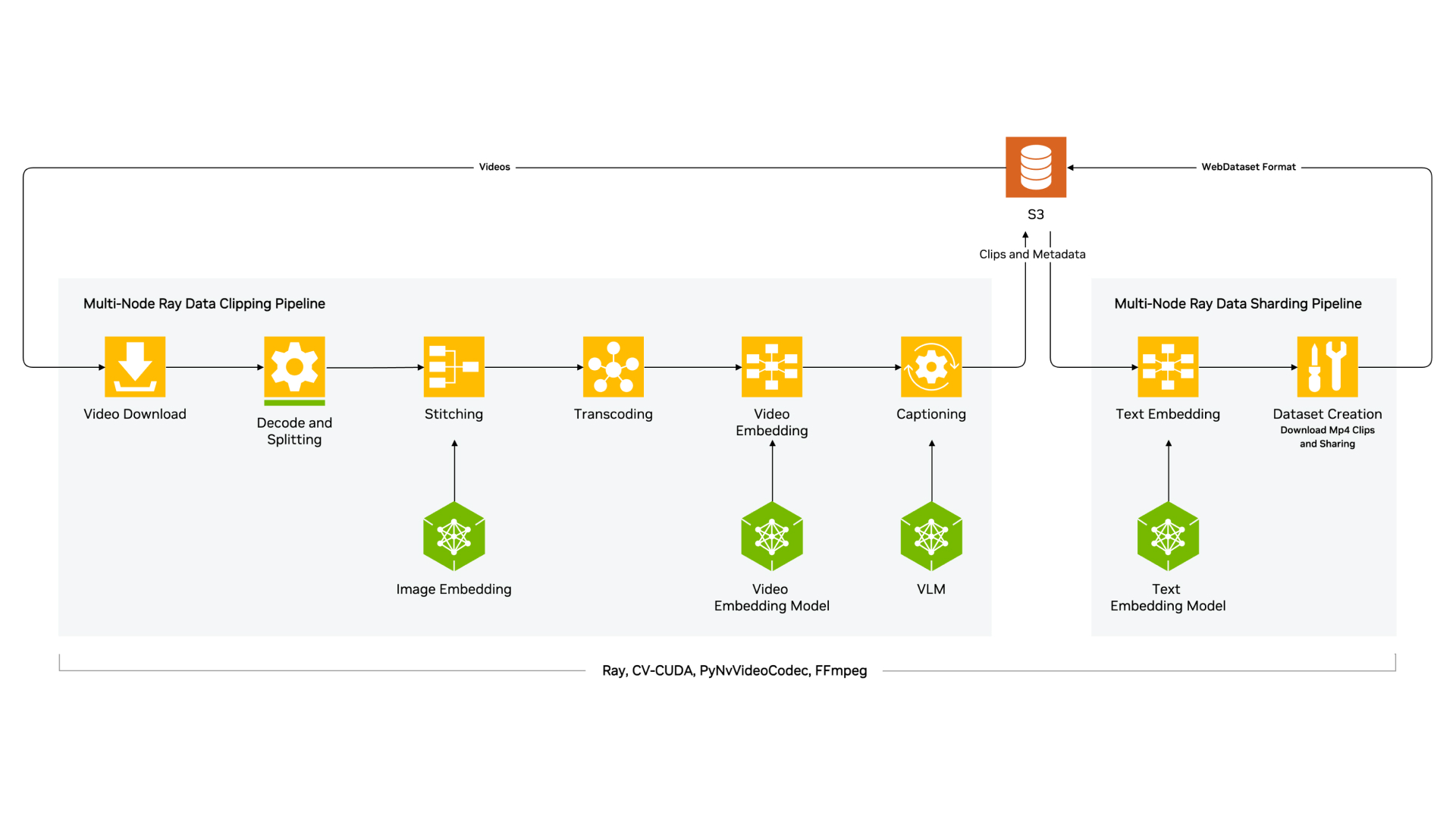
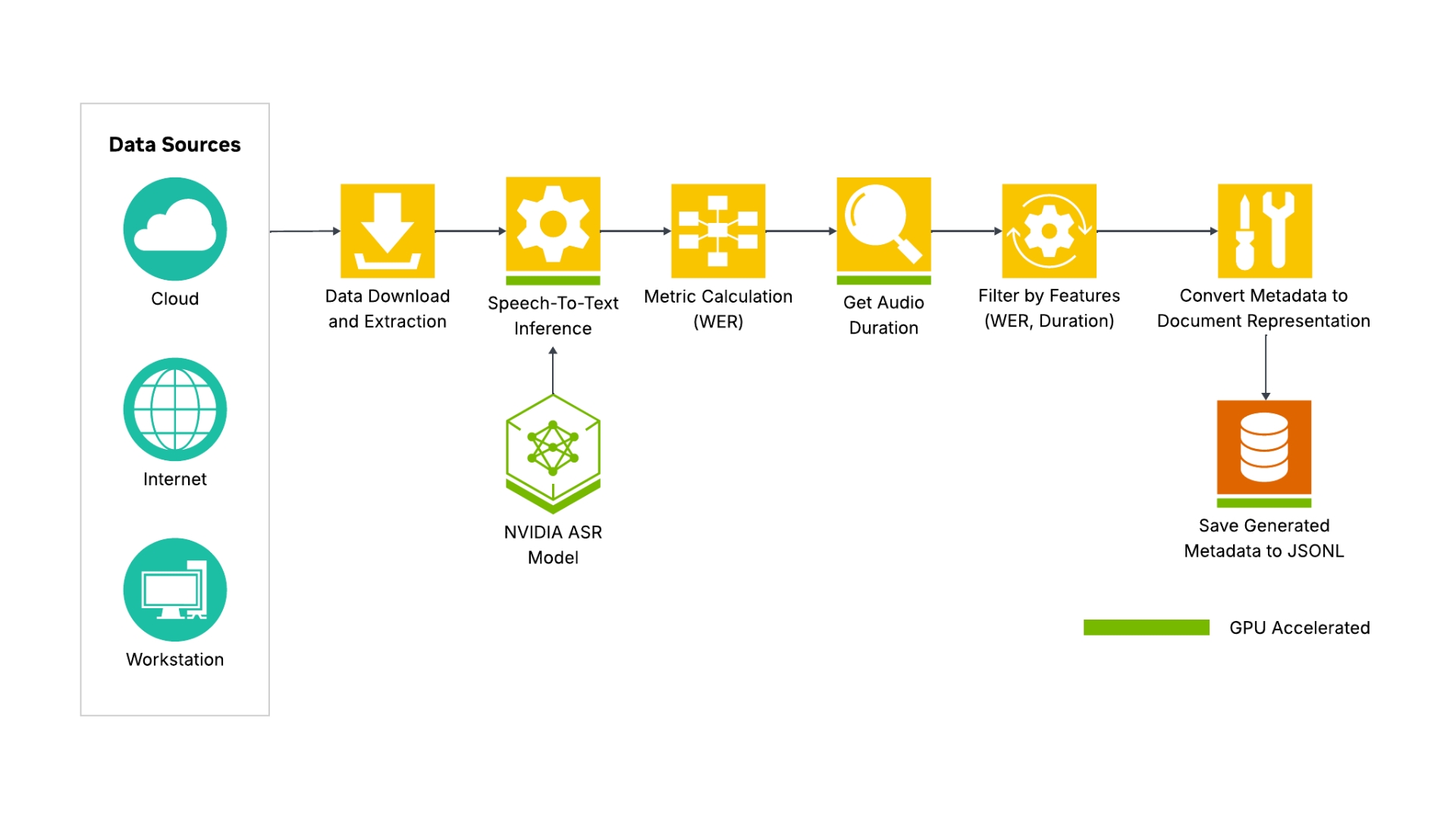
Audio Data Processing
This architecture diagram shows the various features available for processing audio.
A typical pipeline has the following steps
Data download and extraction: Fetch audio files from cloud, internet, or local disk sources.
Speech-to-text inference: Transcribe audio with a NeMo ASR model, using GPU acceleration for speed.
Metric calculation (WER): Compute Word Error Rate to assess transcription accuracy.
Get audio duration: Extract duration metadata for each file.
Feature-based filtering: Filter samples by WER and duration thresholds.
Metadata conversion: Transform curated outputs to document format and export as JSONL.
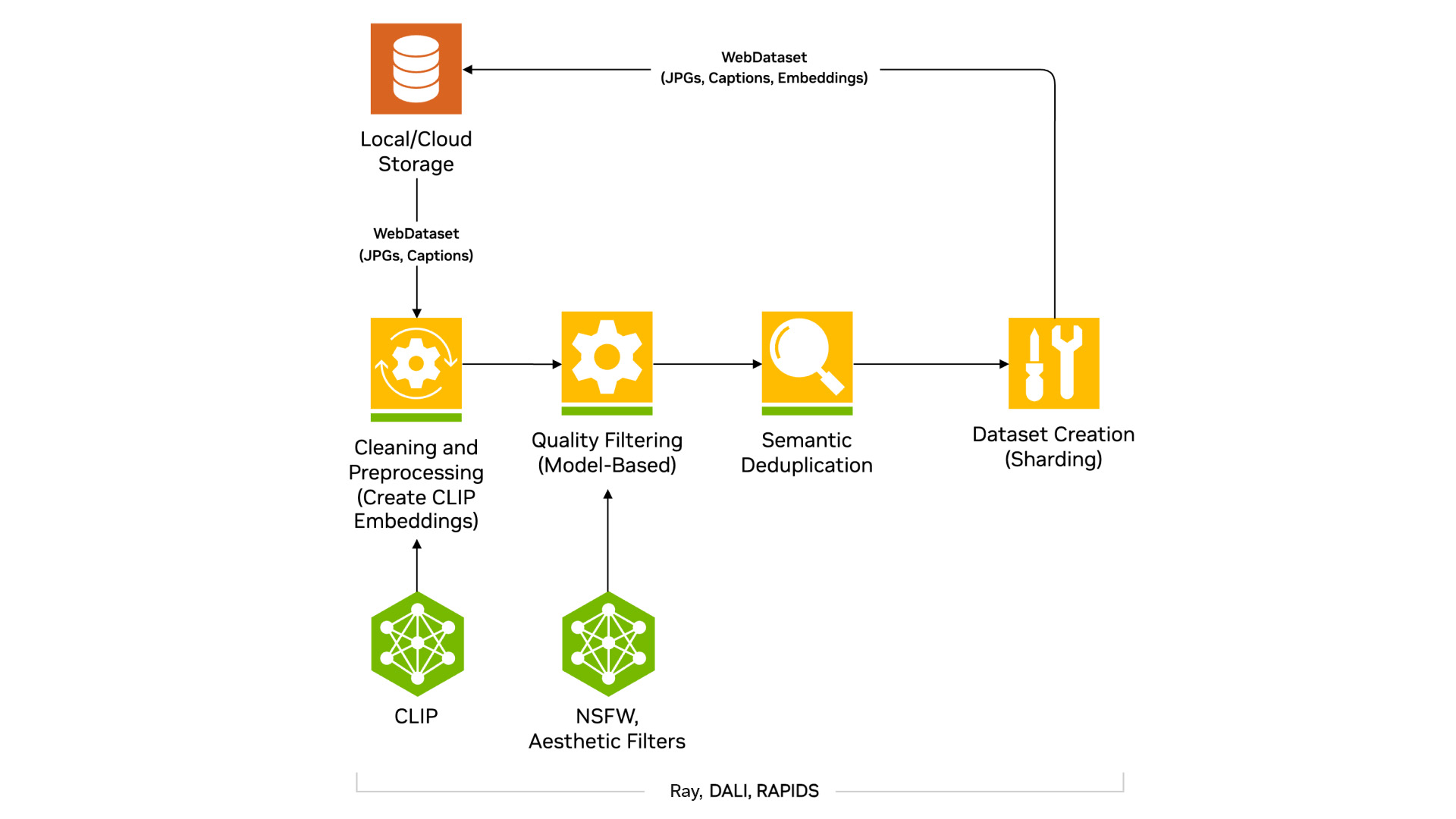
Image Data Processing
This architecture diagram shows the various features available for processing images.
A typical pipeline begins with downloading the dataset in a WebDataset format, followed by creating CLIP embeddings. Next, the images are filtered for high quality using the NSFW and Aesthetic filters. Duplicate images are then removed using semantic deduplication, and finally, a high-quality dataset is created.
Introductory Resources
Introductory Blog
Learn about the various features NeMo Curator offers for processing high-quality data in this introductory blog.
Tutorials
These tutorials provide the coding foundation for building applications that consume the data that NeMo Curator curates.
Introductory Webinar
Explore how to easily build scalable data-processing pipelines to create high-quality datasets for training and customization.
Documentation
These docs provide an in-depth overview of the various features supported, best practices, and tutorials.
Ways to Get Started With NVIDIA NeMo Curator
Use the right tools and technologies to generate high-quality datasets for large language model (LLM) training.
Download
For those looking to use the NeMo framework for development, the container is available to download for free on the NVIDIA NGC™ catalog.
Pull ContainerAccess
To use the latest pre-release features and source code, NeMo Curator is available as an open-source project on GitHub.
Performance
NeMo Curator leverages NVIDIA RAPIDS™ libraries like cuDF, cuML, and cuGraph along with Ray to scale workloads across multi-node, multi-GPU environments, significantly reducing data processing time. For video processing, it uses a combination of a hardware decoder (NVDEC) and a hardware encoder (NVENC) as well as Ray to avoid bottlenecks and ensure high performance. With NeMo Curator, developers can achieve 16x faster processing for text and 89x faster processing for video when compared to alternatives. Refer to the charts below for more details.
Accelerate Video Processing From Years to Days With NeMo Curator
Processing time for 20 million hours of video.

16x Faster Text Processing Time With NeMo Curator
Processing time for fuzzy duplication of the RedPajama-v2 subset (8 TB).

“Off” : Data processed with a leading alternative library on CPUs
Starter Kits
Start developing your generative AI application with NeMo Curator by accessing tutorials, best practices, and documentation for various use cases.
Text Processing
Process high-quality text data with features such as deduplication, quality filtering, and synthetic data generation.
Image Processing
Process high-quality image data with features such as semantic deduplication, CLIP image embedding, NSFW, and aesthetic filters.
Audio Processing
Process high-quality audio data with features such as splitting, transcoding, filtering, annotation, and semantic deduplication.
Video Processing
Process high-quality video data with features such as splitting, transcoding, filtering, annotation, and semantic deduplication.
NVIDIA NeMo Curator Learning Library
NVIDIA NeMo Curator Customers
More Resources


Ethical AI
NVIDIA’s platforms and application frameworks enable developers to build a wide array of AI applications. Consider potential algorithmic bias when choosing or creating the models being deployed. Work with the model’s developer to ensure that it meets the requirements for the relevant industry and use case; that the necessary instruction and documentation are provided to understand error rates, confidence intervals, and results; and that the model is being used under the conditions and in the manner intended.
Get started with NVIDIA NeMo Curator.