
오늘날 AI 및 고성능 컴퓨팅(HPC)의 수요가 증가하면서 GPU 간 고속 통신과 함께 더욱 빠르고 확장 가능한 인터커넥트의 필요성도 함께 커지고 있습니다.
3세대 NVIDIA NVSwitch는 이러한 통신 필요성에 부응하기 위해 설계되었습니다. 이 최신 NVSwitch와 H100 Tensor Core GPU는 NVIDIA에서 개발한 최신 고속 점대점 인터커넥트인 4세대 NVLink를 사용합니다.
3세대 NVIDIA NVSwitch는 NVLink Switch System을 대상으로 노드 내에서, 혹은 노드 외부에 있는 GPU에 연결할 목적으로 설계되었습니다. 또한 멀티캐스트와 NVIDIA SHARP(Scalable Hierarchical Aggregation and Reduction Protocol) 네트워크 내 감소를 사용해 집합 연산이 가능한 하드웨어 가속 기능도 탑재되어 있습니다.
NVIDIA NVSwitch는 NVLink Switch 네트워킹 어플라이언스에서 NVIDIA H100 Tensor Core GPU를 최대 256개까지 연결하여 클러스터를 형성할 뿐만 아니라 올-투-올 대역폭을 57.6TB/s까지 높이는 데 핵심적인 역할을 합니다. 이에 따라 어플라이언스가 NVIDIA Ampere Architecture GPU에서 HDR InfiniBand를 사용했을 때와 비교하여 9배 높은 이분 대역폭을 제공합니다.
높은 대역폭과 GPU 호환 연산
AI 및 HPC 워크로드의 성능이 멈추지 않고 빠르게 증가하면서 멀티-노드, 멀티-GPU 시스템을 향한 확장 필요성도 점차 높아지고 있습니다.
우수한 성능을 대규모로 제공하려면 모든 GPU 사이에 고대역폭 통신이 필요하며, NVIDIA NVLink 사양은 NVIDIA GPU를 사용해 필요한 성능과 확장성을 구현할 수 있는 상승 효과를 고려하여 설계되었습니다.
예를 들어 NVIDIA GPU는 스레드-블록 실행 구조로 되어 있어서 병렬 방식의 NVLink 아키텍처를 효율적으로 유지합니다. 또한 NVLink-Port 인터페이스는 GPU L2 캐시의 데이터 교환 의미가 최대한 일치할 수 있도록 설계되었습니다.
PCIe보다 빠른 속도
NVLink의 주요 이점은 PCIe를 크게 능가하는 대역폭에 있습니다. 4세대 NVLink는 레인 1개당 대역폭이 100Gbps로 PCIe Gen5의 대역폭인 32Gbps와 비교해 3배가 넘습니다. 또한 다수의 NVLink를 결합하면 총 레인 수가 증가하여 처리량을 더욱 높일 수 있습니다.
기존 네트워크보다 낮은 오버헤드
NVLink는 GPU를 서로 연결하기 위해 특별히 고속 점대점 링크로 설계되어 기존 네트워크와 비교해 발생하는 오버헤드가 낮습니다.
늘어난 포트 수에 맞게 엔드-투-엔드 재시도, 적응형 라우팅, 패킷 순서 변경 등 기존 네트워크에서 볼 수 있는 복합 네트워킹 기능도 대부분 지원합니다.
네트워크 인터페이스가 크게 간소화되어 애플리케이션 계층, 프레젠테이션 계층, 세션 계층 기능을 CUDA에 직접 삽입할 수 있기 때문에 통신 오버헤드가 크게 줄어듭니다.
NVLink 세대
NVLink는 NVIDIA P100 GPU에 처음 도입된 이후 NVIDIA GPU 아키텍처와 함께 발전을 거듭하면서 아키텍처가 새롭게 설계될 때마다 새로운 세대의 NVLink가 적용되었습니다
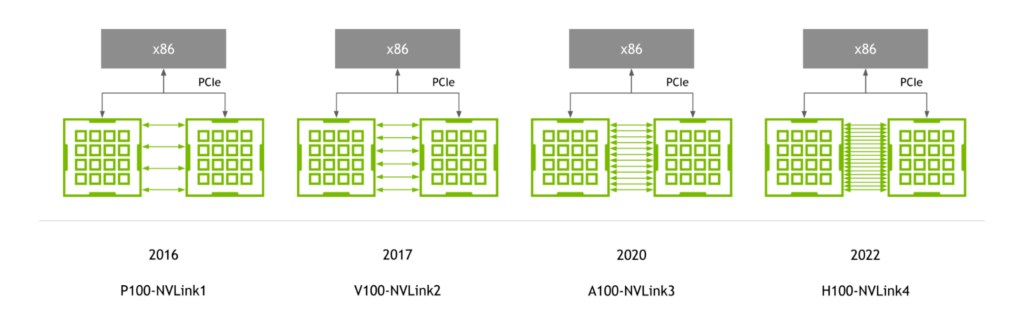
4세대 NVLink는 GPU 1개당 900GB/s의 양방향 대역폭을 제공하여 이전 세대와 비교하여 무려 1.5배 높고, 3세대 NVLink와 비교하여 5.6배 높습니다.
NVLink가 지원되는 서버 세대
NVIDIA NVSwitch는 NVIDIA V100 Tensor Core GPU와 2세대 NVLink와 함께 처음 도입되어 서버에 탑재되는 GPU 사이에서 높은 대역폭과 올-투-올 연결을 지원하기 시작했습니다.
NVIDIA A100 Tensor Core GPU에 와서 3세대 NVLink와 2세대 NVSwitch가 도입되면서 GPU 1개당 대역폭은 물론이고 감소 대역폭까지 2배로 높아졌습니다.
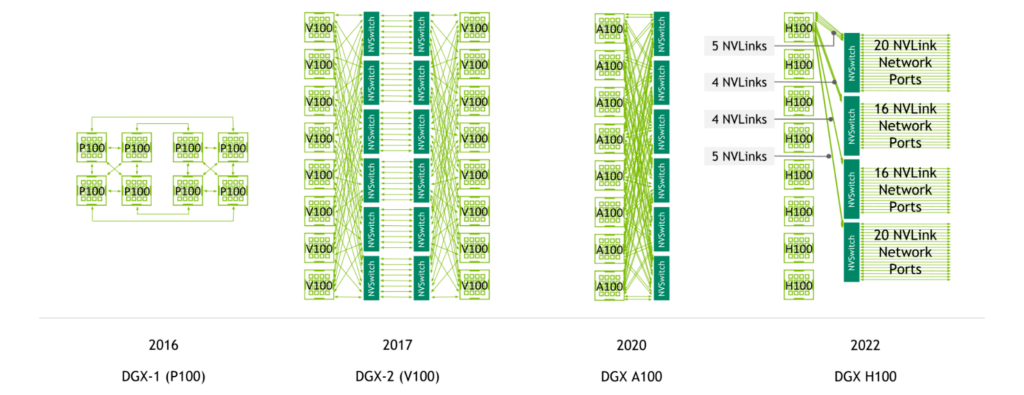
4세대 NVLink 및 3세대 NVSwitch와 함께 NVIDIA H100 Tensor Core GPU 8개로 구성되는 시스템은 3.6TB/s의 이분 대역폭과 450GB/s의 축소 연산 대역폭이 특징입니다. 두 대역폭은 이전 세대와 비교하여 각각 1.5배와 3배 높습니다.
또한 4세대 NVLink와 3세대 NVSwitch에 더하여 외장형 NVIDIA NVLink Switch까지 추가하면 다수의 서버에서 NVLink 속도로 멀티-GPU 통신까지 가능합니다.
현재까지 최대 용량과 최고 속도를 자랑하는 스위치 칩
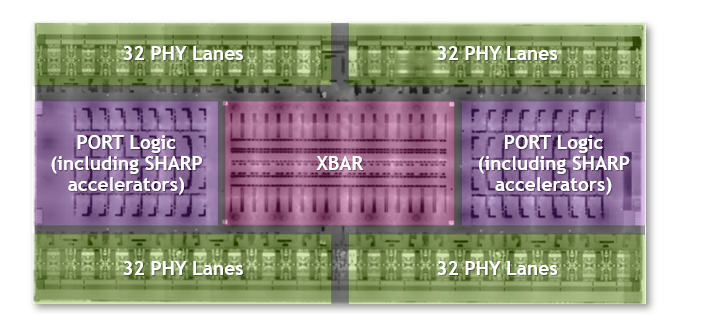
3세대 NVSwitch는 현재까지 용량이 가장 많은 NVSwitch입니다. 또한 NVIDIA에 최적화된 TSMC 4N 프로세스를 사용해 설계되었습니다. 다이에 집적되는 트랜지스터 수는 251억 개로 NVIDIA V100 Tensor Core GPU보다 많은 트랜지스터가 많으며, 다이 크기는 294제곱mm입니다. 패키지 크기는 50 x 50mm이고, 솔더 볼 수는 총 2,645개입니다.
NVLink 네트워크 지원
3세대 NVSwitch는 NVLink Switch System에서 여러 노드의 GPU들을 NVLink 속도로 연결할 수 있다는 점에서 매우 중요한 역할을 합니다.
여기에는 400Gbps Ethernet 및 InfiniBand 연결을 지원하는 물리적(PHY) 전기 인터페이스도 탑재됩니다. 기본적으로 제공되는 관리 컨트롤러는 케이지 1개당 NVLink가 4개 탑재되는 OSFP(Octal Small Formfactor Pluggable) 모듈 연결을 지원합니다. 그 밖에 맞춤 펌웨어로 액티브 케이블까지 지원할 수 있습니다.
또한 순방향 오류 제어(FEC) 모드가 추가되어 NVLink 네트워크 성능과 안정성을 개선할 수 있습니다.
보안 프로세서도 추가되어 데이터와 칩 구성 정보를 공격자에게서 보호합니다. 칩이 분할 기능을 제공하기 때문에 포트의 하위 세트를 서로 분리된 NVLink 네트워크로 격리할 수 있습니다. 그 밖에도 확장 원격 측정 기능으로 InfiniBand 스타일을 모니터링할 수 있습니다.
두 배 높은 대역폭
3세대 NVSwitch는 현재까지 대역폭이 가장 높은 NVSwitch입니다.
디퍼렌셜 페어마다 50Gbaud PAM4 신호 처리를 사용해 대역폭이 100Gbps에 이르는 3세대 NVSwitch는 NVLink 포트 64개(NVLink 1개당 x2)에서 3.2TB/s의 전이중 대역폭을 제공합니다. 따라서 이전 세대와 비교했을 때 NVSwitch 칩 수가 줄어들고 시스템 대역폭은 더욱 늘어났습니다. 3세대 NVSwitch의 포트는 모두 NVLink 네트워크를 지원합니다.
SHARP 집합 연산 및 멀티캐스트 지원
3세대 NVSwitch에는 SHARP 가속화를 위해 새로운 하드웨어 블록들이 많이 포함되어 있습니다.
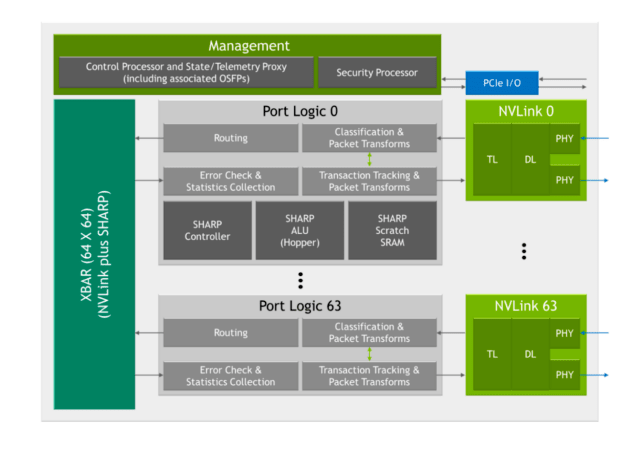
- SHARP 컨트롤러
- NVIDIA Hopper 아키텍처의 하드웨어 블록에서 주로 이용되는 SHARP ALU
- SHARP 연산을 지원하기 위한 임베디드 SRAM
임베디드 ALU는 최대 400GFLOPS의 FP32 처리량을 제공하며, 시스템에 탑재된 GPU가 아닌 NVSwitch에서 직접 축소 연산을 실행할 목적으로 추가되었습니다.
이러한 ALU는 논리, 최소/최대, 더하기 등 다양한 연산자를 비롯해 유부호/무부호 정수, FP16, FP32, FP64, BF16 같은 데이터 형식도 지원합니다.
3세대 NVSwitch에는 SHARP 컨트롤러도 포함되어 SHARP 그룹을 최대 128개까지 동시에 관리할 수 있습니다. 또한 칩의 크로스바 대역폭도 높아져서 SHARP 관련 데이터 교환까지 추가로 실행할 수 있습니다.
all-reduce 연산 호환성
NVIDIA SHARP에서 가장 눈에 띄는 사용 사례는 AI 훈련 시 흔히 사용되는 all-reduce 연산입니다. 다수의 GPU를 사용해 네트워크를 훈련할 때 배치가 더욱 작은 단위의 하위 배치로 분할되어 각 GPU로 할당됩니다.
각 GPU는 네트워크 파라미터를 통해 개별적으로 할당된 하위 배치를 처리하여 로컬 기울기로도 알려진 파라미터의 잠재적 변화를 계산합니다. 이렇게 계산된 로컬 기울기를 집계하여 글로벌 기울기를 산출하고, 각 GPU는 산출된 글로벌 기울기를 파라미터 테이블에 적용합니다. 이러한 평균화 과정을 all-reduce 연산이라고 합니다.
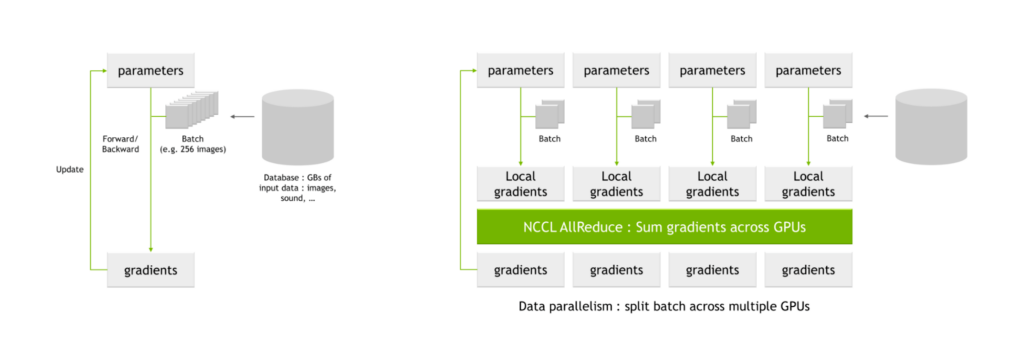
NVIDIA Magnum IO는 멀티-GPU 및 멀티-노드 통신 속도를 높일 목적으로 데이터 센터 IO에 사용되는 아키텍처입니다. HPC, AI 등 다양한 과학 응용 분야에서 이 아키텍처를 기반으로 NVLink와 NVSwitch를 사용해 GPU 클러스터를 새롭게 확장하여 성능을 높일 수 있습니다.
Magnum IO에는 NCCL(NVIDIA Collective Communication Library)가 포함되어 있으며, 이 라이브러리에서 all-reduce를 포함해 멀티-GPU 및 멀티-노드 집합 연산을 구현합니다.
NCCL AllReduce는 로컬 기울기를 입력값으로 사용하여 하위 집합으로 분할한 다음 일정 수준에 부합하는 하위 집합을 모두 수집하여 각 GPU에 할당합니다. GPU는 모든 GPU의 로컬 기울기 값을 합산하는 등 하위 집합에 대한 조정 프로세스를 실행합니다.
조정 프로세스가 끝나면 글로벌 기울기 집합이 산출되어 나머지 모든 GPU로 분산됩니다.
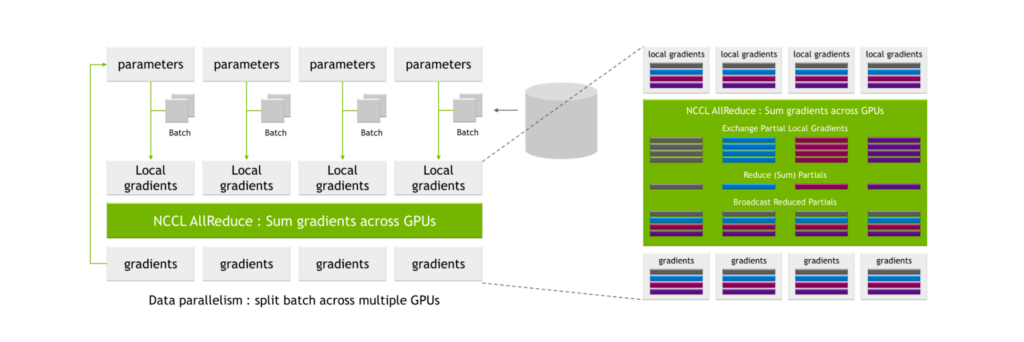
위의 프로세스는 지나치게 통신 집약적이다 보니 여기에서 발생하는 통신 오버헤드가 전체 훈련 시간을 크게 지연시킬 수 있습니다.
하지만 NVIDIA A100 Tensor Core GPU, 3세대 NVLink, 2세대 NVSwitch를 사용하면 분할된 집합들을 전송하고 수신하는 프로세스의 읽기 횟수는 2N이 됩니다(여기에서 N은 GPU 수를 의미합니다). 또한 결과를 브로드캐스팅하는 프로세스에서는 2N 읽기에 대한 2N 쓰기와 각 GPU 인터페이스의 2N 쓰기를 더하여 총 4N 연산이 이루어집니다.
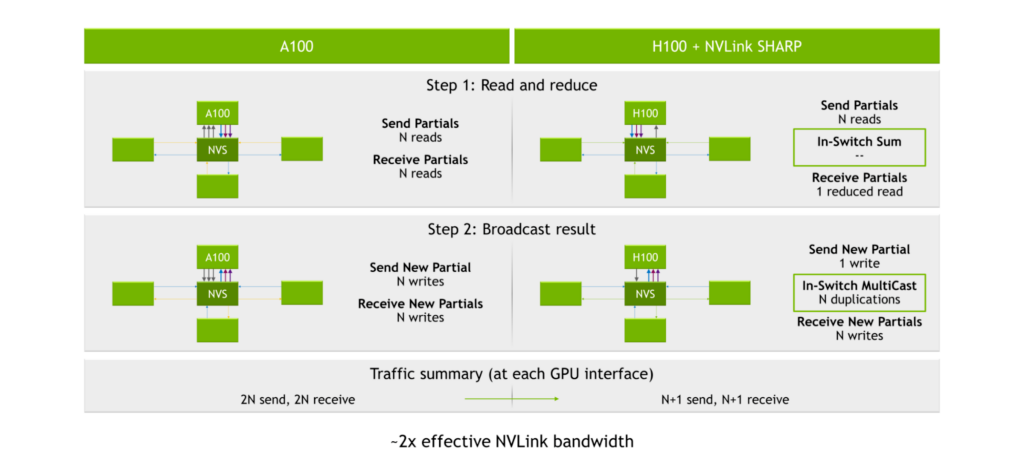
SHARP 엔진은 3세대 NVSwitch 내부에 탑재됩니다. GPU가 분산 수신된 데이터를 가지고 연산을 실행하지 않고 데이터를 3세대 NVSwitch 칩으로 보냅니다. 그러면 칩이 연산을 실행하여 결과를 다시 보냅니다. 따라서 총 연산 횟수는 2N+2가 되고, all-reduce 연산에 필요한 읽기/쓰기 연산 횟수의 절반 정도로 줄어듭니다.
대규모 모델에 대한 성능 개선
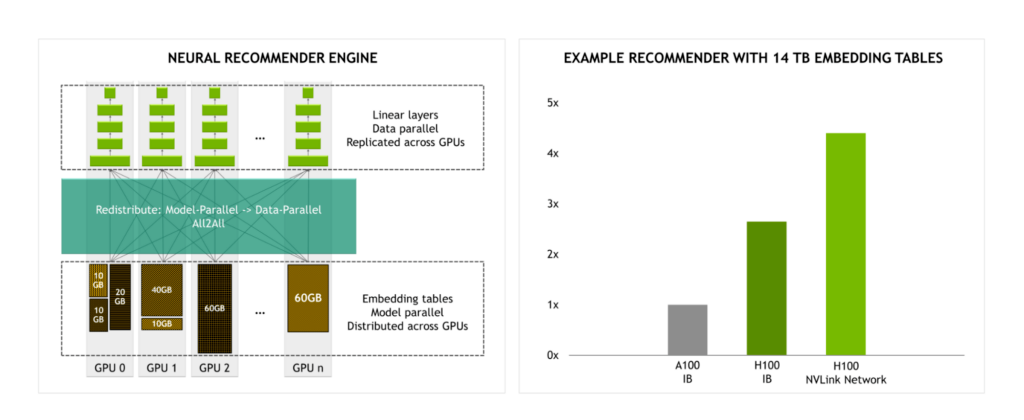
NVLink Switch System은 InfiniBand와 비교해 4.5배 높은 대역폭을 제공하기 때문에 대규모 모델을 훈련하는 데 더욱 실용적입니다.
예를 들어 임베딩 테이블 용량이 14TB인 추천 엔진을 훈련한다고 가정할 경우 H100에 InfiniBand가 아닌 NVLink Switch System을 사용했을 때 성능이 크게 향상되는 것을 기대할 수 있습니다.
NVLink 네트워크
이전 세대의 NVLink에서는 각 서버마다 NVLink를 통해 서로 통신할 때 GPU에서 사용하는 로컬 주소 공간이 따로 있었습니다. NVLink 네트워크에서는 각 서버마다 GPU가 네트워크를 통해 데이터를 전송할 때 사용하는 주소 공간이 따로 있어서 데이터 공유 시 격리가 용이하고 보안을 강화하는 효과도 있습니다. 이 기술은 최신 NVIDIA Hopper GPU 아키텍처에 탑재된 기능을 이용합니다.
NVLink가 시스템 부팅 과정에서 연결을 설정할 때 소프트웨어에서 런타임 API를 호출하여 NVLink 네트워크 연결이 설정됩니다. 따라서 다수의 서버가 온라인 상태로 전환되거나, 사용자가 들어오고 나갈 때 네트워크를 빠르게 재구성할 수 있습니다.
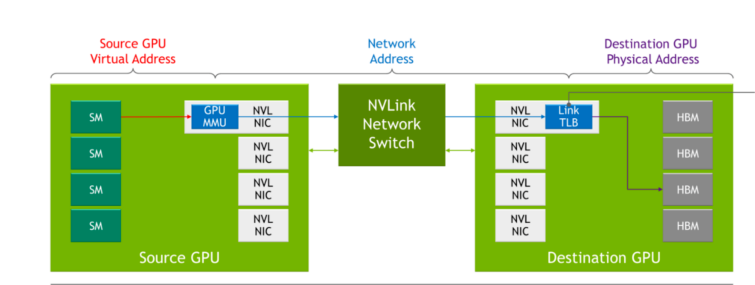
표 1은 기존 네트워킹 개념과 NVLink 네트워크 개념의 연관성을 나타낸 것입니다.
| 개념 | 기존 예 | NVLink 네트워크 |
| 물리적 계층 | 400G 전기/광학 미디어 | 맞춤형-FW OSFP |
| 데이터 링크 계층 | 이더넷 | NVLink 맞춤형 온-칩 HW 및 FW |
| 네트워크 계층 | IP | 새로운 NVLink 네트워크 주소 지정 및 관리 프로토콜 |
| 전송 계층 | TCP | NVLink 맞춤형 온-칩 HW 및 FW |
| 세션 계층 | 소켓 | SHARP groupsCUDA 데이터 구조의 네트워크 주소 내보내기 |
| 프레젠테이션 계층 | TSL/SSL | 라이브러리 추상화(예: NCCL, NVSHMEM) |
| 애플리케이션 계층 | HTTP/FTP | AI 프레임워크 또는 사용자 앱 |
| NIC | PCIe NIC(카드 또는 칩) | GPU 및 NVSwitch에 삽입되는 함수 |
| RDMA 오프로드 | NIC 오프로드 엔진 | GPU-내부 복제 엔진 |
| 집합 연산 오프로드 | NIC/스위치 오프로드 엔진 | NVSwitch 내장형 SHARP 엔진 |
| 보안 오프로드 | NIC 보안 기능 | GPU-내부 암호화 및 “TLB” 방화벽 |
| 미디어 제어 | NIC 케이블 적용 | NVSwitch-내부 OSFP 케이블 컨트롤러 |
DGX H100
NVIDIA DGX H100은 최신 NVIDIA H100 Tensor Core GPU 기반 DGX 시스템 계열 중에서 가장 최근에 출시된 제품으로 구성은 다음과 같습니다.
- 총 GPU 메모리가 640GB인 NVIDIA H100 Tensor Core GPU 8개
- 3세대 NVIDIA NVSwitch 챕 4개
- NVLink Network OSFP 18개
- NVLink 72개에서 제공하는 전이중 NVLink 네트워크 대역폭 3.6TB/s
- NVIDIA ConnectX-7 Ethernet/InfiniBand 포트 8개
- 듀얼 포트 BlueField-3 DPU 2개
- 듀얼 Sapphire Rapids CPU
- PCIe Gen 5 지원
풀 대역폭 서버 내 NVLlink
DGX H100 내부에서 H100 Tensor Core GPU 8개가 3세대 NVSwitch 칩 4개에 연결됩니다. 트래픽이 서로 다른 스위치 플레인 4개로 전송되어 링크 집계를 통해 시스템의 GPU 사이에서 완전한 올-투-올 대역폭을 구현할 수 있습니다.
하프 대역폭 NVLink 네트워크
NVLink 네트워크에서는 서버에 탑재되는 NVIDIA H100 Tensor Core GPU 8개가 모두 다른 서버의 H100 Tensor Core GPU로 연결되는 NVLink 18의 하프 대역폭을 구독할 수 있습니다.
또한 서버에 탑재되는 NVIDIA H100 Tensor Core GPU 4개가 다른 서버의 H100 Tensor Core GPU로 연결되는 NVLink 18의 풀 대역폭을 구독할 수도 있습니다. 이러한 2:1 테이퍼 형태가 상쇄 작용으로 대역폭과 서버 복잡성 및 비용 사이에 균형을 유지하여 기술을 구현합니다.
SHARP에서는 전송 대역폭이 풀-대역폭 AllReduce와 동일합니다.
멀티-레일 이더넷
서버 내부에서 GPU 8개가 각각 전용 400GB NIC를 통해 RDMA를 개별적으로 지원합니다. NVLink 네트워크가 아닌 디바이스까지 총 800GB/s의 전이중 대역폭이 가능합니다.
DGX H100 SuperPOD
DGX H100은 DGX H100 SuperPOD의 빌딩 블록입니다.
- 컴퓨팅 랙 8개에 DGX H100 서버가 각각 4개씩 설치됩니다.
- 총 32개의 DGX H100 노드에 NVIDIA H100 Tensor Core GPU가 256개 탑재됩니다.
- 최대 1엑사플롭까지 AI 컴퓨팅을 제공합니다.
NVLink 네트워크는 전체 GPU 256개를 통틀어 57.6TB/s의 이분 대역폭을 제공합니다. 또한 DGX 32개와 여기에 연결된 InfiniBand 스위치까지 모두 포괄하는 ConnectX-7이 SuperPOD 내에서 사용하거나, 혹은 다수의 SuperPOD를 스케일아웃할 수 있도록 25.6TB/s의 전이중 대역폭을 제공합니다.
NVLink Switch
DGX H100 SuperPOD에서 중요한 역할을 하는 것은 3세대 NVSwitch 칩을 기반으로 새롭게 추가된 NVLink Switch입니다. DGX H100 SuperPOD에는 NVLink Switch가 18개 내장됩니다.
NVLink Switch는 주로 InfiniBand 스위치 설계를 이용하여 표준 1U 19인치 폼 팩터에 적합하며, OSFP 케이지가 32개 포함됩니다. 각 스위치마다 3세대 NVSwitch 칩 2개가 탑재되어 4세대 NVLink 포트를 128개 제공하기 때문에 전이중 대역폭이 총 6.4TB/s에 달합니다.
NVLink Switch는 대역 외 관리 통신을 비롯해 패시브 구리 등 다양한 케이블 옵션을 지원합니다. 여기에 맞춤 펌웨어를 사용하면 액티브 구리와 광학 OSFP 케이블도 지원됩니다.
NVLink 네트워크를 통한 스케일업
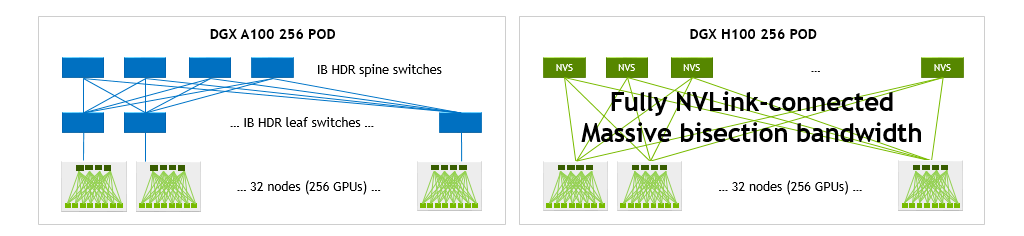
H100 SuperPOD를 NVLink 네트워크와 함께 사용하면 DGX A100 SuperPOD를 DGX A100 GPU 256개와 함께 사용할 때와 비교하여 이분 대역폭과 축소 연산 대역폭을 크게 높일 수 있습니다.
DGX H100 1개와 DGX A100 1개를 서로 비교하면 DGX H100의 이분 대역폭이 1.5배, 그리고 축소 연산 대역폭이 3배 높습니다. 이러한 가속도는 32개로 구성되는 DGX 시스템에서 GPU 수가 총 256개로 늘어나 9배와 4.5배까지 증가합니다.
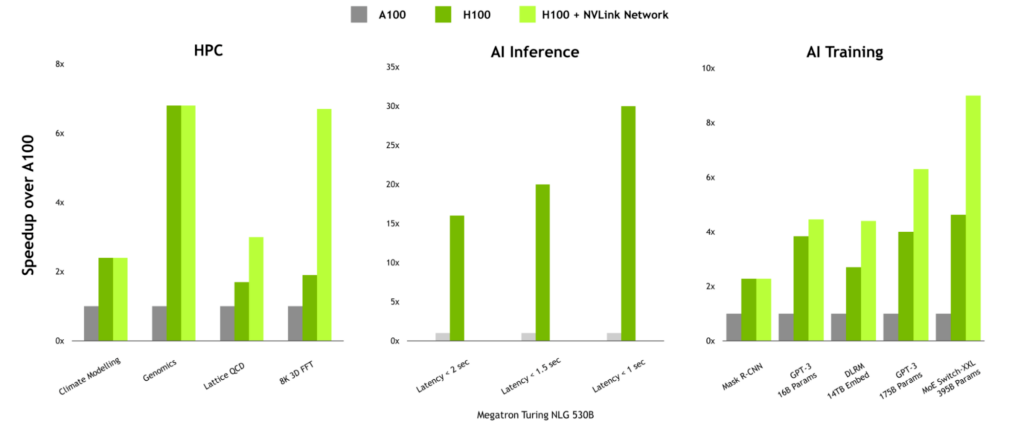
통신 집약적 워크로드를 위한 성능 이점
통신 집약도가 높은 워크로드에서는 NVLink 네트워크의 성능 이점이 큰 힘을 발휘할 수 있습니다. Lattice QCD, 8K 3D FFT 같은 HPC 워크로드를 예로 들면 멀티-노드 스케일링이 HPC SDK 및 Magnum IO 내부 통신 라이브러리에 맞게 설계되어 커다란 이점이 기대됩니다.
대규모 언어 모델, 혹은 임베딩 테이블 크기가 높은 추천자 모델을 훈련할 때도 NVLink 네트워크가 성능을 크게 높일 수 있습니다.
대규모 성능 제공
AI 및 HPC 워크로드에서 성능을 극대화하려면 데이터 센터 규모의 풀 스택 혁신이 필요합니다. 이러한 대규모 성능 혁신에서 반드시 필요한 것이 바로 높은 대역폭과 낮은 지연 시간을 지원하는 인터커넥트 기술입니다.
3세대 NVSwitch는 차세대 혁신 기술을 바탕으로 서버에 탑재되는 GPU 간 통신에서 높은 대역폭과 낮은 지연 시간을 지원할 뿐만 아니라 서버 노드 사이에서도 NVLink 속도를 극대화하여 올-투-올 GPU 통신을 구현합니다.
Magnum IO는 CUDA와 HPC SDK, 그리고 거의 모든 딥 러닝 프레임워크와 완전하게 호환됩니다. 대규모 언어 모델, 추천 시스템, 과학 응용 분야(3D FFT 등) 같은 AI 소프트웨어가 NVLink Switch System을 사용해 멀티-노드, 멀티 GPU로 확장할 수 있는 이유도 이러한 IO 아키텍처에 있습니다.
자세한 내용은 NVIDIA NVLink와 NVSwitch를 참조하세요.
이 블로그에 열거된 SDK의 대부분의 독점 액세스, 얼리 액세스, 기술 세션, 데모, 교육 과정, 리소스는 NVIDIA 개발자 프로그램 회원은 무료로 혜택을 받으실 수 있습니다. 지금 무료로 가입하여 NVIDIA의 기술 플랫폼에서 구축하는 데 필요한 도구와 교육에 액세스하시고 여러분의 성공을 가속화 하세요