
NVIDIA は、RAPIDS cuDF が 950 万人の pandas ユーザーに、コードを変更することなく GPU アクセラレーションを提供できるようになったと発表しました。

pandas は、Python 用の柔軟かつパワフルなデータ解析およびデータ操作ライブラリです。API を容易に使用できることから、データ サイエンティストには最高の選択肢と言えます。ただし CPU のみのシステムでは、データセットのサイズが大きくなるほど処理速度と効率が低下します。
RAPIDS は、データ サイエンスと分析パイプラインの向上を目的に設計された GPU アクセラレーテッド Python ライブラリのオープンソース スイートです。RAPIDS cuDF は、データのロード、フィルタリング、操作に使用できる pandas のような API を提供する GPU DataFrame ライブラリです。cuDF の以前のリリースでは、GPU のみの開発ワークフローを対象としていました。
RAPIDS の最新リリース RAPIDS v23.10 では、cuDF は、新しい pandas アクセラレータ モードにより、コードを変更することなく、統合された CPU/GPU ユーザー体験を提供し、pandas ワークフローにアクセラレーテッド コンピューティングをもたらします。現在、オープンソースの RAPIDS v23.10 リリースでオープン ベータ版として提供されており、まもなく NVIDIA AI Enterprise でサポート開始予定です。
この動画では、同一の pandas ワークフローが並列して実行されている様子を視聴することができます。1 つは CPU のみで pandas を使用し、もう 1 つは RAPIDS cuDF の pandas アクセラレータ モードを使用しています。
統合 CPU/GPU エクスペリエンスを pandas ワークフローで実現
cuDF は、pandas のような API を利用して、DataFrame ライブラリでの最高のパフォーマンスをユーザーに常に提供してきました。しかし、cuDF を採用するにあたっては以下のような回避策が必要になる場合があります。
- cuDF で未実装または未サポートの pandas 機能について対処する。
- 異種ハードウェアでの実行が必要なコードベースで CPU と GPU の実行用に別々のコード パスを設計する。
- pandas 用に設計された他の PyData ライブラリまたは組織特化のツールとやり取りさせるときは、cuDF と pandas を手動で切り替える。
cuDF は、RAPIDS v23.10 のリリースから、既存の GPU のみのエクスペリエンスに加えて、上記のような課題に対処する pandas アクセラレータ モードの提供を開始しました。
この機能は、データ サイズがギガバイト単位に増加して pandas のパフォーマンスが低下しても pandas の使用を継続したいデータ サイエンティスト向けに開発されました。cuDF の pandas アクセラレータ モードでは、演算は可能であれば GPU で、そうでない場合は CPU (pandas を使用) で実行され、必要に応じて内部で同期されます。これにより、CPU/GPU エクスペリエンスの統合が実現し、pandas のワークフローに最高クラスのパフォーマンスがもたらされます。
最新リリースで、cuDF は以下の機能を新たに提供します。
- コード変更ゼロのアクセラレーション: cuDF Jupyter Notebook 拡張機能をロードするか、cuDF Python モジュール オプションを使用するだけで利用可能です。
- サードパーティ ライブラリの互換性: pandas アクセラレータ モードは、pandas オブジェクトで動作するほとんどのサードパーティ ライブラリと互換性があります。これらのライブラリ内では pandas の操作も高速化されます。
- CPU/GPU ワークフローの統合: ハードウェアに関係なく、単一のコード パスを使用して実稼働環境で開発、テスト、実行できます。
Jupyter Notebook の pandas ワークフローに GPU アクセラレーションを導入するには、cudf.pandas 拡張機能を読み込みます。
%load_ext cudf.pandas
import pandas as pd Python スクリプトの実行時にアクセスするには、cudf.pandas モジュール オプションを使用します。
python -m cudf.pandas script.pypandas ワークフローに最高のパフォーマンスをもたらす
データ サイズがギガバイト単位の規模になると、パフォーマンスの低下により pandas の使用が困難になることが多く、データ サイエンティストの中には愛用していた pandas API を諦める人もいます。新しい RAPIDS cuDF を使用すると、pandas を主要なツールとして使用し続けることができ、最高のパフォーマンスを獲得できます。
H2o.ai が開発した、一般に使用されている DuckDB データベースに似た Ops ベンチマークの pandas 部分を実行すると、pandas API が実際に動作している様子を確認できます。DuckDB のベンチマーク設定では、データの結合やグループ毎の統計的尺度の計算といった一連の一般的な解析タスクに関して、一般的な CPU ベースの DataFrame エンジンと SQL エンジンを比較します。
データが 5GB になると、pandas のパフォーマンスが最低になり、結合や高度な groupby の一連の操作を実行するのに数分かかります。
これまで、このベンチマークを pandas ではなく cuDF で実行するには、コードを変更し、足りない機能に関する対処を行う必要がありました。cuDF の新しい pandas アクセラレータ モードでは、この問題が解決されました。pandas のベンチマーク コードを変更せずに実行することができ、ワークフローが成功するように GPU を演算の大部分に使用し、CPU をごく一部に使用することで、大幅な高速化が実現します。
結果は素晴らしいものになっています。cuDF の統合された CPU/GPU エクスペリエンスは、コード変更が不要になり、数分間の処理がわずか 1、2 秒に短縮されます (図 1)。
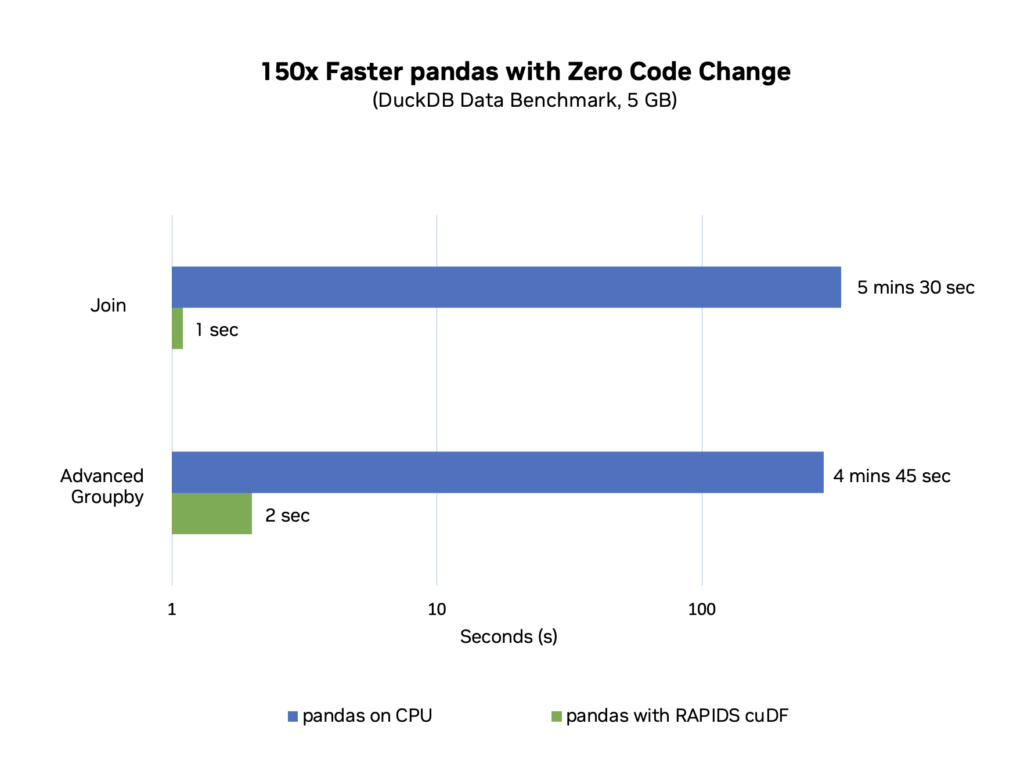
これらのベンチマーク結果とその再現方法の詳細については、cuDF のドキュメントをお読みください。
結論
pandas は Python エコシステムで最もよく使われる DataFrame ライブラリですが、CPU ではデータ サイズが大きくなると速度が低下します。
cuDF の pandas アクセラレータ モードが RAPIDS v23.10 リリースの一環としてオープン ベータ版で利用可能になったことで、コードを変更することなく、pandas ワークフローにアクセラレーテッド コンピューティングを導入できるようになりました。5GB データセットを処理する解析ベンチマークを根拠にすれば、処理時間を 150 倍高速化することができます。
Google Colab の無料 GPU 環境にあるこちらの詳細なウォークスルー ノートブックを使用して、cuDF の新しい pandas アクセラレータ モードをお試しください。詳細については、RAPIDS の Web サイト cuDF pandas アクセラレータ モードのページをご参照ください。
関連情報
- 無料のオンライン トレーニング (自分のペースで学べる DLI オンライン コース): Speed Up DataFrame Operations With RAPIDS cuDF
- GTC セッション: Accelerate Data Science in Python with RAPIDS (2023 年春)
- SDK: RAPIDS
- SDK: DGL Container
- ウェビナー: Accelerating Data Science Workflows with RAPIDS