NVIDIA は、CUDA Toolkit ソフトウェアの最新リリースである 12.0 を発表しました。このリリースは、数年ぶりのメジャー リリースで、新しいプログラミング モデルと新しいハードウェア機能による CUDA アプリケーションの高速化に焦点を当てています。
詳細は、YouTube Premiere ウェビナー、CUDA 12.0: New Features and Beyond (CUDA 12.0: 新機能とその先) をご覧ください。
CUDA カスタム コード、拡張ライブラリ、および開発者ツールを使って、NVIDIA Hopper および NVIDIA Ada Lovelace アーキテクチャのアーキテクチャ固有の機能と命令を対象にアプリケーションをビルドできるようになりました。
CUDA 12.0 には、メジャーなものからマイナーなものまで、多くの変更点が含まれています。すべての変更点がこちらの記事に記載されているわけではありませんが、主な機能の概要をご紹介します。
概要
- 新しい PTX 命令や、ハイレベルな C および C++ API による公開など、すべての GPU のプログラミング モデルの強化が追加された新しい NVIDIA Hopper および NVIDIA Ada Lovelace アーキテクチャの機能をサポート
- 刷新された CUDA の動的な並列化 API をサポートし、従来の API と比較して大幅な性能向上を実現
- CUDA Graphs API の機能強化:
- ビルトイン関数を呼び出すことで、GPU デバイス側のカーネルから、グラフの起動をスケジュールできるようになりました。この機能により、カーネル内のユーザー コードはグラフの起動を動的にスケジュールすることができ、CUDA Graphs の柔軟性が大幅に向上します。
cudaGraphInstantiate APIがリファクタリングされ、未使用のパラメーターが削除されました。
- GCC 12 ホスト コンパイラのサポート
- C++20 を サポート
- JIT LTO のための CUDA Toolkit の新しい
nvJitLinkライブラリ - ライブラリの最適化およびパフォーマンスの改善
- Nsight Compute と Nsight Systems 開発者向けツールのアップデート
- 最新の Linux バージョンに対応したアップデート
詳しくは、CUDA Toolkit 12.0 リリース ノートをご覧ください。CUDA Toolkit 12.0 は、ダウンロード可能です。
NVIDIA Hopper および NVIDIA Ada Lovelace アーキテクチャのサポート
CUDA アプリケーションは、新しい GPU ファミリのストリーミング マルチプロセッサ (SM) 数の増加、メモリ帯域幅の拡大、クロック レートの向上の恩恵をすぐに受けることができます。CUDA と CUDA ライブラリを通して、GPU ハードウェア アーキテクチャの強化に基づく新しいパフォーマンスの最適化が可能になりました。
CUDA 12.0 の、NVIDIA Hopper および NVIDIA Ada Lovelace アーキテクチャの多くの機能に対するプログラマブルな機能のご紹介:
- 多くのテンソル演算が公開された PTX で利用可能:
- TMA 演算
- TMA バルク演算
- 32x Ultra xMMA (FP8 と FP16 を含む)
- NVIDIA Hopper GPU の起動パラメーターによる
membarドメインの制御 - C++ および PTX での非同期バリアのサポート
- CGA (Cooperative Grid Array) のバリアに対する C 組み込み関数のサポート
- プログラムによる L2 キャッシュから SM へのマルチキャストのサポート (NVIDIA Hopper GPU のみ)
- SIMT コレクティブの公開された PTX をサポート:
elect_one - NVIDIA Hopper GPU で Genomics と DPX 命令が利用可能になり、より高速な数学演算の組み合わせが可能 (三方比較による max、融合された add+max 演算など)
遅延ロード
遅延ロードは、カーネルと CPU 側モジュールの両方の読み込みを、アプリケーションによる読み込みが必要になるまで遅延させる手法です。デフォルトでは、ライブラリが最初に初期化された時に全てのモジュールを事前に読み込みます。これにより、デバイスやホストのメモリだけでなく、アルゴリズムのエンドツーエンドの実行時間も大幅に短縮することができます。
遅延ロードは 11.7 リリース以来、CUDA の一部となっています。その後の CUDA のリリースで、この機能の強化と拡張が続けられています。アプリケーション開発の観点からは、遅延ロードを選択するために特別なことは何も必要ありません。既存のアプリケーションは、そのまま遅延ロードで動作します。
特に遅延に敏感な操作がある場合は、アプリケーションのプロファイリングを行うことができます。遅延ロードのトレードオフは、関数が最初に読み込まれるアプリケーションのポイントでの遅延が最小になることです。これは、遅延ロードを行わない場合の合計の遅延よりも全体的に低くなっています。
| 指標 | 基準 | CUDA 11.7 | CUDA 11.8+ | 向上 |
| エンドツーエンドの実行時間 [s] | 2.9 | 1.7 | 0.7 | 4 倍 |
| バイナリ読み込み時間 [s] | 1.6 | 0.8 | 0.01 | 118 倍 |
| デバイス メモリ フットプリント [MB] | 1245 | 435 | 435 | 3 倍 |
| ホスト メモリ フットプリント [MB] | 1866 | 1229 | 60 | 31 倍 |
遅延ロードで使用されるすべてのライブラリは、11.7+ でビルドされていることが条件となります。
このリリースでは、CUDA スタックで遅延ロードがデフォルトで有効になっていません。ご自身のアプリケーションで評価するには、環境変数 CUDA_MODULE_LOADING=LAZY を設定して実行してください。
互換性
CUDA マイナー バージョンの互換性は、11.x で導入された機能で、同じメジャー リリース内の CUDA Toolkit の任意のマイナー バージョンに対してアプリケーションを動的にリンクさせる柔軟性を提供します。コードを 1 回コンパイルすれば、CUDA Toolkit の同じメジャー バージョン内の任意のマイナー バージョンのライブラリ、CUDA ランタイム、およびユーザーモード ドライバーに対して動的にリンクすることが可能です。
例えば、11.6 アプリケーションは 11.8 ランタイムに対してリンクすることができ、その逆も可能です。これは、ライブラリ ファイル内の API または ABI の一貫性によって実現されます。詳細については、CUDA の互換性を参照してください。
マイナー バージョンの互換性は CUDA 12.x でも引き継がれていますが、12.0 は新しいメジャー リリースのため、互換性はリセットされます。11.x でマイナー バージョンの互換性を使用していたアプリケーションは、12.0 に対してリンクする際に問題が発生する可能性があります。12.0 に対してアプリケーションを再コンパイルするか、11.x 内の必要なライブラリに静的にリンクして、開発の継続性を確保してください。
同様に、12.0 で再コンパイルまたはビルドされたアプリケーションは、12.x の将来のバージョンにリンクしますが、CUDA Toolkit 11.x での動作は保証されません。
JIT LTO 対応
CUDA 12.0 Toolkit は、JIT LTO サポートのために新しい nvJitLink ライブラリを導入しています。NVIDIA は、この機能のドライバー版のサポートを非推奨としています。詳細については、非推奨の機能を参照してください。
C++20 コンパイラ対応
CUDA Toolkit 12.0 では、C++20 標準のサポートが追加されました。C++20 は、以下のホスト コンパイラとその最小バージョンで必要です。
- GCC 10
- Clang 11
- MSVC 2022
- NVC++ 22.x
- Arm C/C++ 22.x
機能の詳細については、対応するホスト コンパイラのドキュメントを参照してください。
C++20 の機能の大半はホストとデバイスの両方のコードで利用可能ですが、一部は制限されています。
モジュール対応
C++20 では、翻訳単位間でエンティティをインポートおよびエクスポートする新しい方法として、モジュールが導入されています。
CUDA デバイス コンパイラとホスト コンパイラの間で複雑な相互作用を必要とするため、CUDA C++ では、ホスト コードでもデバイス コードでもモジュールはサポートされていません。モジュールおよび export キーワード、import キーワードの使用はエラーとして診断されます。
コルーチン対応
コルーチンは実行の再開をサポートする関数です。実行を中断することができ、その場合は、制御が呼び出し元に戻されます。その後のコルーチンの呼び出しは、中断された時点から再開されます。
コルーチンは、ホスト コードではサポートされていますが、デバイス コードではサポートされていません。デバイス関数のスコープ内で co_await、co_yield、co_return キーワードを使用すると、デバイスのコンパイル時にエラーとして診断されます。
三方比較演算子
三方比較演算子 <=> は、コンパイラが他の関係演算子を合成できるようにする新しい種類の関係演算子です。
標準テンプレート ライブラリのユーティリティ関数と密接に結合しているため、ホスト関数が暗黙的に呼び出される場合、デバイス コードでの使用は制限されます。
この演算子が直接呼び出され、暗黙の呼び出しを必要としない使用が有効になります。
Nsight Developer Tools
Nsight Developer Tools は、CUDA Toolkit 12.0 と同時にアップデートが行われています。
NVIDIA Nsight Systems 2022.5 では、InfiniBand スイッチのメトリクス サンプリングのプレビューを導入しています。NVIDIA Quantum InfiniBand スイッチは、高帯域幅、低遅延の通信を提供します。Nsight Systems のタイムラインでスイッチ メトリクスを表示すると、アプリケーションのネットワーク使用状況をよりよく理解することができます。この情報を利用して、アプリケーションのパフォーマンスを最適化することができます。

Nsight ツール郡は復数のツールで協調して利用できるように作られています。Nsight Systems の性能分析は、Nsight Compute でカーネルの活動をより深く掘り下げる情報となることがよくあります。
このプロセスを効率化するため、Nsight Compute 2022.4 では Nsight Systems との統合を導入しています。この機能により、システム トレース アクティビティを起動し、Nsight Compute インターフェイスでレポートを表示することができます。その後、コンテキスト メニューからレポートを確認し、カーネル プロファイリングを開始することができます。
このワークフローでは、2 つの異なるアプリケーションを実行する必要がなく、すべて 1 つのアプリケーションで実行することができます。
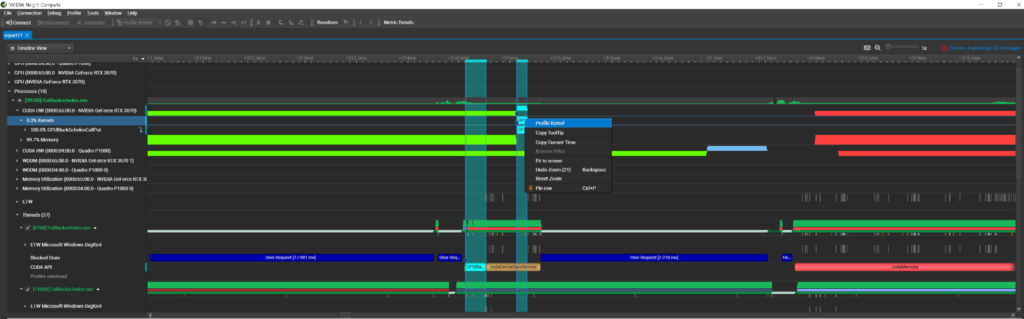
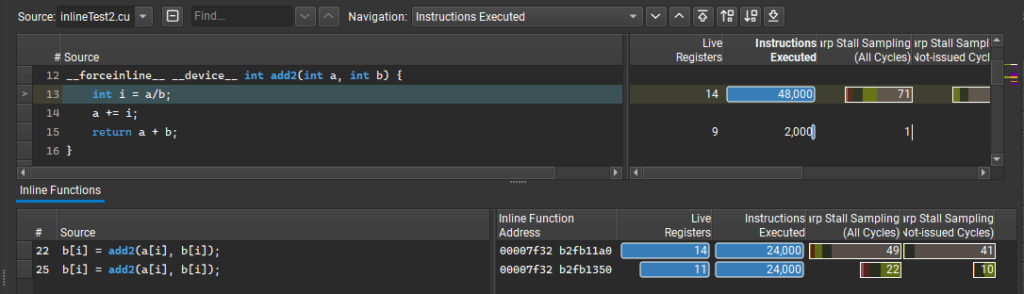
Nsight Compute 2022.4 では、複数のインライン展開された関数ごとにパフォーマンス メトリクスを提供する新しいインライン関数テーブルも導入されています。この要望の多い機能により、ある関数が一般的にパフォーマンスの問題を抱えているのか、それとも特定のインライン展開されたケースにのみ問題があるのかを理解することができます。
また、このレベルの詳細が得られない場合に混乱に陥ることがよくありますが、Nsight Compute 2022.4 ではインライン展開がどこで行われているかを把握することができます。メイン ソース ビューでは、引き続き行単位でメトリクスの集計が表示され、テーブルには関数がインライン化された複数の場所と各場所のパフォーマンス メトリクスが一覧表示されます。
また、Acceleration Structure ビューアーは、NVIDIA OptiX カーブ プロファイリングのサポートを含む、様々な最適化と改善が施されています。
詳細については、NVIDIA Nsight Compute、NVIDIA Nsight Systems、Nsight Visual Studio Code Edition をご覧ください。
数学ライブラリのアップデート
ライブラリに追加されたすべての最適化と機能は、通常バイナリ サイズという形で、コストを伴います。これまで、各ライブラリのバイナリ サイズは、徐々に増加してきました。NVIDIA は、性能を犠牲にすることなくこれらのバイナリを縮小するために多大な努力をしてきました。cuFFT では、CUDA Toolkit 11.8 と 12.0 の間で 50% 以上ものサイズ縮小が見られました。
また、特筆すべきライブラリ固有の機能もいくつかあります。
cuBLAS
cuBLASLt は、新しい FP8 データ型による混合精度乗算演算に対応します。これらの演算は、BF16 および FP16 バイアス融合と、FP8 入出力データ型を持つ GEMM の FP16 バイアスと GELU 活性化関数の融合もサポートしています。
性能については、FP8 GEMM は A100 の BF16 と比較して、H100 PCIe では最大 3 倍、SXM では最大 4.5 倍高速化することができます。CUDA Math API は、新しい FP8 行列乗算演算を容易に使用するために、FP8 変換を提供します。
cuBLAS 12.0 は、64 ビット整数を用いた問題サイズ、leading dimension、およびベクトル要素ストライドの設定をサポートするために API を拡張しました。これらの新しい関数は、名前に _64 が末尾に付き、対応するパラメーターを int64_t として宣言する以外は、32 ビット整数の対応する関数と同じ API を持っています。
cublasStatus_t cublasIsamax(cublasHandle_t handle, int n, const float *x, int incx, int *result);対応する 64 ビット整数は以下の通りです。
cublasStatus_t cublasIsamax_64(cublasHandle_t handle, int64_t n, const float *x, int64_t incx, int64_t *result);cuBLAS は性能に重点を置いています。64 ビット整数 API に渡された引数が 32 ビット範囲に収まる場合、ライブラリは 32 ビット整数 API を呼び出した場合と同じカーネルを使用します。新しい API を試すには、int32_t 値から int64_t への C/C++ 自動変換のおかげで、cuBLAS 関数に _64 を末尾に追加するだけで簡単に移行できるはずです。
cuFFT
プランの初期化時に cuFFT は、どのカーネルが使用されるか、また、カーネル モジュールのロードを決定するために、ヒューリスティックを含む一連のステップを実施します。
CUDA 12.0 以降、cuFFT はバイナリ形式ではなく、CUDA Parallel Thread eXecutionm (PTX) アセンブリ形式を使用して、カーネルの大部分を提供します。
cuFFT カーネルの PTX コードは、cuFFT プランが初期化されるときに、ランタイムで CUDA デバイス ドライバーによってロードされ、バイナリ コードにコンパイルされます。新しい実装による改善は、NVIDIA Maxwell、NVIDIA Pascal、NVIDIA Volta、およびNVIDIA Turing アーキテクチャでの多くの新しい高速化されたカーネルの利用を実現するでしょう。
cuSPARSE
疎行列の乗算 (SpGEMM: Sparse-Sparse Matrix Multiplication) に必要なワークスペースを削減するために、NVIDIA はメモリ使用量の少ない 2 つの新しいアルゴリズムをリリースしています。最初のアルゴリズムは中間積の数を厳密に制限して計算し、2 番目のアルゴリズムは計算を復数のチャンクで分割するのを可能にします。これらの新しいアルゴリズムは、メモリ容量が小さいデバイスをお使いのお客様にとっては、有益なものです。
INT8 のサポートが、cusparseGather、cusparseScatter、と cusparseCsr2cscEx2 に追加されました。
最後に、SpSV と SpSM では、前処理時間が平均 2.5 倍に改善されます。実行段階では、SpSV は平均 1.1 倍、SpSM は平均 3.0 倍向上されました。
Math API
新しい NVIDIA Hopper アーキテクチャには、三方比較による max、融合された add+max 演算などの複合演算をより高速に計算するための新しい Genomics 命令と DPX 命令が備わっています。
新しい DPX 命令により、動的プログラミング アルゴリズムが A100 GPU に比べて最大 7 倍高速化されます。動的プログラミングは、複雑な再帰的問題をより単純なサブ問題に分解して解決するアルゴリズム技術です。より良いユーザー体験のために、これらの命令は現在、Math API を通じて公開されています。
例としては、三方比較による max + ReLU の演算、max(max(max(a, b), c), 0) が挙げられます。
int __vimax3_s32_relu ( const int a, const int b, const int c )詳細については、Boosting Dynamic Programming Performance Using NVIDIA Hopper GPU DPX Instructions (NVIDIA Hopper GPU DPX 命令を使用した動的プログラミングの性能向上) を参照してください。
画像処理アップデート: nvJPEG
nvJPEG の実装が改善され、GPU メモリ フットプリントが大幅に削減されました。これは、ゼロコピー メモリ操作、カーネルの融合、およびインプレースの色空間変換の使用によって実現されます。
まとめ
私たちは、研究者、科学者、開発者が、簡素化されたプログラミング モデルを通じて、世界で最も複雑な AI/機械学習やデータ サイエンスの課題を解決できるよう、引き続き注力していきます。
この CUDA 12.0 リリースは、数年ぶりのメジャー リリースであり、次世代 NVIDIA GPU を利用してアプリケーションを加速するのを支援するための基礎となるものです。NVIDIA Hopper および NVIDIA Ada Lovelace アーキテクチャの新しいアーキテクチャ固有の機能と命令が、CUDA カスタム コード、拡張ライブラリ、および開発者ツールで利用できるようになりました。
CUDA Toolkit を使用すると、GPU で加速された組込みシステム、デスクトップ ワークステーション、エンタープライズ データ センター、クラウドベースのプラットフォーム、および HPC スーパーコンピューターでアプリケーションを開発、最適化、および展開することができます。このツールキットには、GPU アクセラレーション ライブラリ、デバッグおよび最適化ツール、C/C++ コンパイラ、ランタイム ライブラリ、および多くの高度な C/C++ および Python ライブラリへのアクセスが含まれています。
詳細は、以下の資料をご覧ください。
- NVIDIA CUDA Toolkit
- NVIDIA Hopper アーキテクチャと NVIDIA Ada Lovelace アーキテクチャ
- CUDA Compatibility (CUDA との互換性)
- NVIDIA Releases Open-Source GPU Kernel Modules (NVIDIA、オープンソースの GPU カーネル モジュールを公開)
- GPU-Accelerated Libraries (GPU 対応ライブラリ)
- NVIDIA Nsight Compute と NVIDIA Nsight Systems
翻訳に関する免責事項
この記事は、「CUDA Toolkit 12.0 Released for General Availability」の抄訳で、お客様の利便性のために機械翻訳によって翻訳されたものです。NVIDIA では、翻訳の正確さを期すために注意を払っておりますが、翻訳の正確性については保証いたしません。翻訳された記事の内容の正確性に関して疑問が生じた場合は、原典である英語の記事を参照してください。