
This post was updated substantially in March 2020. The original post was about the experimental NVX extension, while the current post is about the production NV version.
We are releasing the VK_NV_device_generated_commands (DGC) Vulkan extension, which allows GPU generation of the most frequent rendering commands. This extension offers an improved design over the experimental NVX extension.
Vulkan now has functionality like the DirectX12 ExecuteIndirect function. However, we added the ability to change shaders (ShaderGroups) on the GPU as well. This marks the first time that an open graphics API has provided functionality to create compact command buffer streams on the device, avoiding the worst-case state setup of previous indirect drawing methods.
Motivation
With general advances in programmable shading, the GPU can take on an ever-increasing set of responsibilities for rendering, by computing supplemental data and allowing a greater variety of rendering algorithms to be implemented. However, when it comes to setting up state for draw calls, the decisions must primarily be made on the CPU. Therefore, explicit synchronization or working from past frame’s results was necessary. Device-generated commands remove this readback latency and overcome existing inefficiencies.
Another trend is the development towards global scene representations on the GPU. For example, in ray tracing (VK_NV/KHR_ray_tracing), the GPU stores geometry and instance information for the scene. Recent API developments (VK_VERSION_1_2, or VK_EXT_descriptor_indexing and VK_EXT_buffer_device_address) allow the GPU to use bindless resources. This extension supplements such representations and allows you to determine the subset of objects to be rasterized on the device by modifying buffer contents before the command generation.
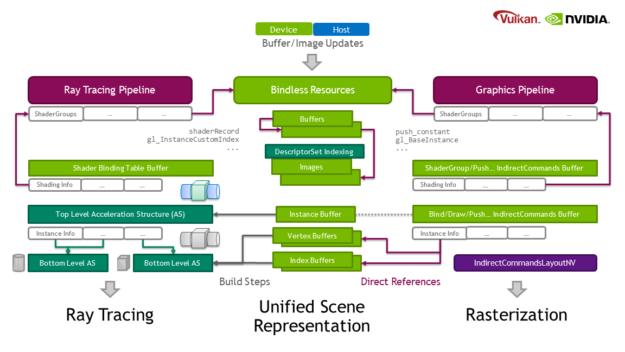
In Figure 1, the center represents the scene resources and bindings stored in buffers. With this extension, both ray tracing and rasterization have similar setups to provide geometry and shading information in buffers and pipelines. In both cases, the decision of what work to perform can be done on the GPU: what rays to shoot, or which objects to rasterize and which shading to use.
Some usage scenarios that may benefit from the functionality of this extension are:
- Occlusion culling: Use custom shader-based culling techniques to obtain greater accuracy with easy access to the latest depth-buffer information.
- Object sorting: In forward shading-limited scenarios, sort the objects front to back to achieve greater performance.
- Level of detail: Influence the shaders or geometry used for an object depending on its screen-space footprint.
- Work distribution: Bucket arbitrary workloads for improved coherency in their resource usage, for example, by using more specialized shaders that have compile-time optimizations applied.
Evolution of GPU Work Creation
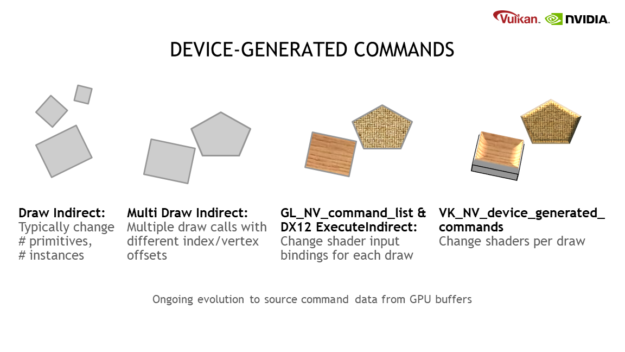
Over the years, GPU work creation has evolved. First, Draw Indirect provided the ability to source basic parameters for a draw call (number of primitives, instances, etc.) from GPU buffers that can be written by shaders.
Next came the popular Multi Draw Indirect feature that is practical for both CPU time reasons, including approaching zero driver overhead (AZDO) as well as GPU culling or level-of-detail algorithms.
Following this, our OpenGL GL_NV_command_list extension added the ability to do basic state changes (for example, vertex/index/uniform-buffers) using tokens stored in regular GPU buffers. Similar functionality was later exposed in DirectX 12 Execute Indirect, and we are now introducing this to Vulkan with DGC.
One problem with existing indirect techniques is that the command buffer must be prepared for the worst-case scenario on the CPU. You may also require more memory than necessary for the distribution of indirect commands, given that it is not known which state buckets they will end up in. To solve these problems, this extension adds further capabilities, such as the ability to switch between different shaders.
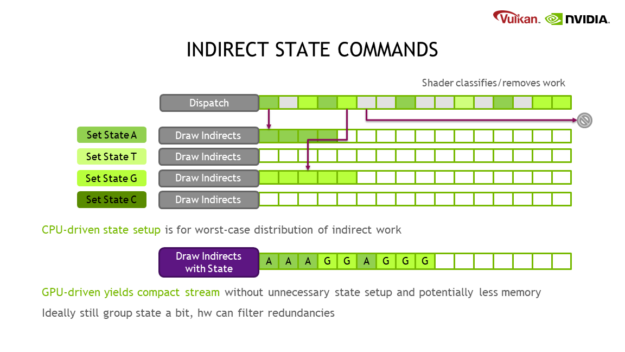
Principal usage
To leverage this new functionality, there are a few additions to the Vulkan API. You need to express what commands to generate, make shaders bindable from the device, and run the actual generation and execution.
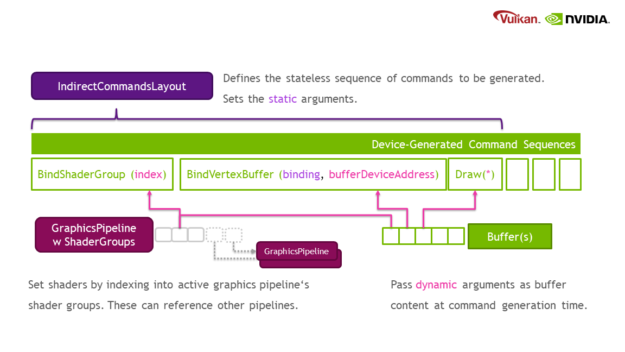
A new Vulkan object type is introduced:
VkIndirectCommandsLayoutNV: The layout encodes the sequence of commands to be generated and where the data is found in the input streams. In addition to the command tokens and predefined functional arguments (binding units, variable sizes, etc.), additional usage flags that affect the generation can also be provided.
Graphics pipeline creation is extended by adding shader groups:
VkGraphicsPipelineShaderGroupsCreateInfoNV: As part ofVkGraphicsPipelineCreateInfo, you can define multiple shader groups within the pipeline. By default, every pipeline has one group. The shader groups are bound through an index either coming from an indirect command or the newvkCmdBindPipelineShaderGroupNV. It is also possible to append shader groups by referencing existing compatible graphics pipelines, which eases integration.VkGraphicsShaderGroupCreateInfoNV: A shader group can override a subset of the pipeline’s base graphics state. This includes the ability to change shaders, as well as the vertex or tessellation setup.
The following steps generate commands on the device:
- Define a sequence of commands to be generated, using a
VkIndirectCommandsLayoutNVobject. - For the ability to change shaders, create the graphics pipelines with
VK_PIPELINE_CREATE_INDIRECT_BINDABLE_BIT_NVand then create an aggregate graphics pipeline that imports those pipelines as graphics shader groups usingVkGraphicsPipelineShaderGroupsCreateInfoNV, which extendsVkGraphicsPipelineCreateInfo. - Create a preprocess buffer based on sizing information acquired using
vkGetGeneratedCommandsMemoryRequirementsNV. - Fill the input buffers for the generation step and set up the
VkGeneratedCommandsInfoNVstruct accordingly. It is used in preprocessing as well as execution. Some commands require buffer addresses, which can be acquired usingvkGetBufferDeviceAddress. - (Optional) Use a separate preprocess step using
vkCmdPreprocessGeneratedCommandsNV. - Run the execution using
vkCmdExecuteGeneratedCommandsNV.
Key design choices
Compared to the approach of GL_NV_command_list or DirectX12 ExecuteIndirect, this extension uses some different design choices:
- Graphics Shader Groups: Like ray tracing, a graphics pipeline contains a collection of shader groups that can be accessed from the device.
- Stateless Command Sequences: While the new design also uses command tokens, these tokens define a stateless sequence. The
GL_NV_command_listextension encoded a serial token stream, which allowed you to resolve redundant state setup and create compact streams. However, the serial token stream design was not as portable or parallel-processing friendly as the traditional stateless design ofMDIorExecuteIndirect. Not all command types must be generated, although stateful commands must be defined before work-provoking ones.
|
VkIndirectCommandsTokenTypeNV |
Equivalent vkCmd |
Input buffer data |
|
VK_INDIRECT_COMMANDS_TOKEN_TYPE_SHADER_GROUP_NV |
vkCmdBindPipelineShaderGroup |
ShaderGroup index |
|
VK_INDIRECT_COMMANDS_TOKEN_TYPE_STATE_FLAGS_NV |
– |
vkFrontFace state |
|
VK_INDIRECT_COMMANDS_TOKEN_TYPE_INDEX_BUFFER_NV |
vkCmdBindIndexBuffer |
VkDeviceAddress and VkIndexType |
|
VK_INDIRECT_COMMANDS_TOKEN_TYPE_VERTEX_BUFFER_NV |
vkCmdBindVertexBuffers |
VkDeviceAddress and stride |
|
VK_INDIRECT_COMMANDS_TOKEN_TYPE_PUSH_CONSTANT_NV |
vkCmdPushConstant |
Raw values |
|
VK_INDIRECT_COMMANDS_TOKEN_TYPE_DRAW_INDEXED_NV |
vkCmdDrawIndexedIndirect |
Draw arguments |
|
VK_INDIRECT_COMMANDS_TOKEN_TYPE_DRAW_NV |
vkCmdDrawIndirect |
Draw arguments |
|
VK_INDIRECT_COMMANDS_TOKEN_TYPE_DRAW_TASKS_NV |
vkCmdDrawMeshTasksIndirectNV |
Draw arguments |
- Optional Explicit Preprocessing: This extension optionally allows some preprocessing to be done separately. This way, you can asynchronously overlap preparation of new draw calls with the drawing of a previous batch.
- Explicit Resource Control: To fit into Vulkan’s explicit design, the memory requirements for command generation are exposed and managed directly through buffers by you.

- Multiple Input Streams: Previous approaches only allowed a single input buffer stream.
MDIandExecuteIndirectare designed to use an array of structures (AoS) layout, which makes partial updates less cache-efficient.DGClets you define how many input streams are used and where tokens are stored. This way, you can choose to use a structure of arrays (SoA) layout for compact, cache-friendly streams, or use a hybrid layout to easily separate dynamic from static content.
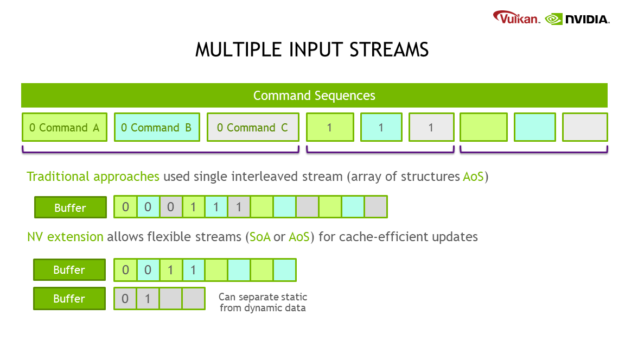
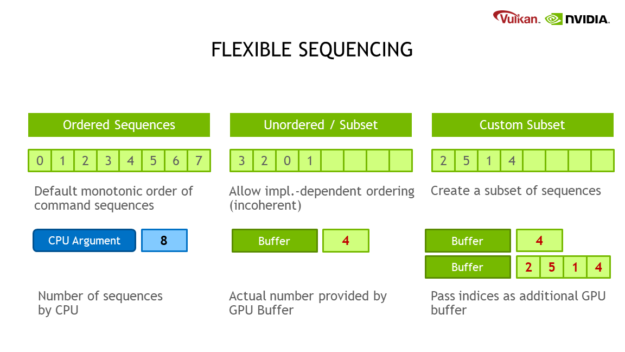
- Relaxed Ordering: By default, all sequences are processed in linear order. You can relax the ordering requirement to be implementation-dependent, which speeds up processing.
- Sequence Count & Index Buffer: The number of sequences, as well as the subset, can be provided by additional buffers containing count and index values. This allows for easy sorting or filtering of draw calls without having to change the input data.
What’s the catch?
No feature is free of trade-offs. A device-generation approach means that some driver-side optimizations may not apply. Furthermore, the generation process can add to the overall frame time, in cases where the CPU is able to record commands without affecting the GPU time. Finally, it requires additional GPU memory.
In summary, the goal of this extension is primarily to reduce the amount of actual work done on the GPU, by making decisions on the device about what and how work is generated. It is not about off-loading command generation from CPU to the GPU in general.
Sample and availability
A new open-source sample is available on GitHub. This extension is exposed in our beta driver first, and will be available in production drivers later.
Special thanks to Nia Bickford, Matthew Rusch, Mathias Schott, Daniel Koch, James Helferty, and Markus Tavenrath who contributed to the posts.
