
NVIDIA’s new Turing GPU unleashed real-time ray-tracing in a consumer GPU for the first time. Since then, much virtual ink has been spilled discussing ray tracing in DirectX 12. However, many developers want to embrace a more open approach using Vulkan, the low-level API supported by the Khronos Group. Vulkan enables developers to target many different platforms, including Windows and Linux, allowing for broader distribution of 3D-accelerated applications. NVIDIA’s 411.63 driver release now enables an experimental Vulkan extension that exposes NVIDIA’s RTX technology for real-time ray tracing through the Vulkan API.
This extension, called VK_NVX_raytracing, is a developer preview of our upcoming vendor extension for ray tracing on Vulkan. The extension targets developers who want to familiarize themselves with API concepts and start testing the functionality. As denoted by the ‘NVX’ prefix, this API is not yet final and could undergo some minor changes before the final release.
Evolution of Ray Tracing APIs
At NVIDIA, GPU-accelerated ray tracing has been a topic of research for over a decade.
GPUs evolved to become powerful rasterization machines. Adding programmability to our architecture enabled complex rasterization-based algorithms to be built. This programmability enabled GPUs to handle more complex computational problems and eventually led to the launch of CUDA, our GPU computing platforms. NVIDIA’s GPU-accelerated ray tracing efforts focused on exposing ray tracing through the CUDA programming model.
One of the first visible results of these efforts was OptiX, a general-purpose SDK for accelerating ray casting applications. Our 2010 SIGGRAPH paper (https://dl.acm.org/citation.cfm?id=1778803) details the API design work that was done for OptiX, and includes the key building blocks that we use today for real-time ray tracing APIs. Figure 1 shows an excerpt from the paper.

Our efforts around OptiX, and in particular the R&D work that we’ve done towards making it more and more efficient and scalable, eventually culminated in NVIDIA’s RTX. The product of 10+ years of work in algorithms, computer graphics, and GPU architectures, RTX enables real-time ray tracing applications to run on NVIDIA’s GPUs. RTX leverages all of our research work and hardware improvements and is the underlying foundation upon which real-time ray tracing APIs are built.
Adding Ray Tracing to Vulkan
The key design principle behind our Vulkan ray tracing extension (“VKRay” for short) is to leverage our prior work on ray tracing APIs. VKRay builds on proven and field-tested API concepts; flexible enough to enable a wide variety of applications while still providing a level of abstraction that allows applications to leverage future R&D work in this area.
Vulkan is a hardware-agnostic API, and we’ve made sure VKRay is hardware agnostic as well. The entire API can be implemented on top of existing Vulkan compute functionality. We’ve also gone to great lengths to make sure that the extension fits well with existing Vulkan API concepts. Memory allocation, resource handling, and shader language/bytecode are handled in the same way that the core Vulkan API prescribes.
The Ray Tracing Pipeline
The flow of data through the ray tracing pipeline differs from the traditional raster pipeline. Figure 2 shows an overview of the two pipelines for comparison.
Gray blocks are considered to be non-programmable (fixed-function and/or hardware). These evolve and improve over time as the underlying implementation matures. White blocks represent fully programmable stages. Diamond-shaped stages are where scheduling of work happens.
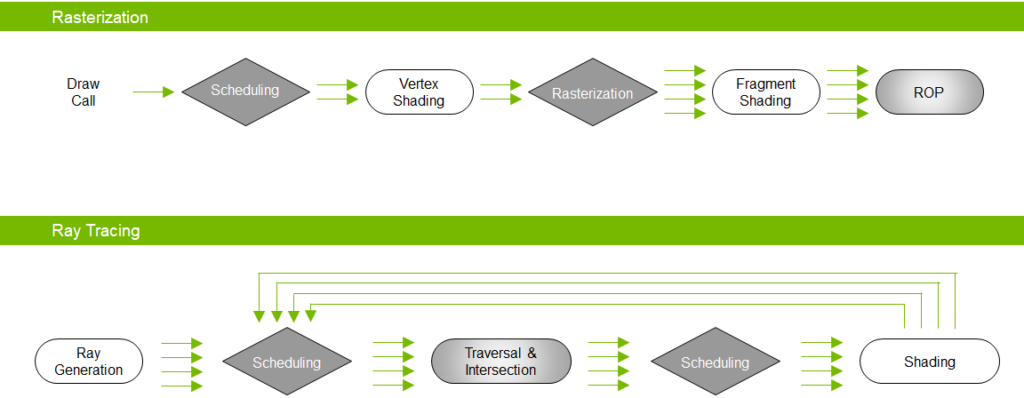
Unlike rasterization, the number of “units” (rays) of work performed depends on the outcome of previous work units. This means that new work can be spawned by programmable stages and fed directly back into the pipeline.
Four key components make up our ray tracing API:
- Acceleration Structures
- New shader domains for ray tracing
- Shader Binding Table
- Ray tracing pipeline objects
Acceleration Structures
Traditional rasterization involves processing each geometric primitive independently. In contrast, ray tracing requires testing each ray against all scene primitives, which can be prohibitively expensive.
Most ray tracers implement some form of acceleration structure to enable fast rejection of primitives, and our API exposes this as a first-class citizen. The acceleration structure is an object that holds geometric information for primitives in the scene, preprocessed in such a way as to enable trivial rejection of potential ray-primitive intersections. This is the API primitive that rays can be traced against.
The acceleration structure (AS) is exposed as an opaque, implementation-defined data structure with no dependence on any underlying algorithm or culling method. It is modeled as a two-level structure: bottom level AS nodes contain geometry data while top-level AS nodes contain a list of references to bottom level nodes together with associated transform and shading information. Figure 3 outlines the relationships between these structures.
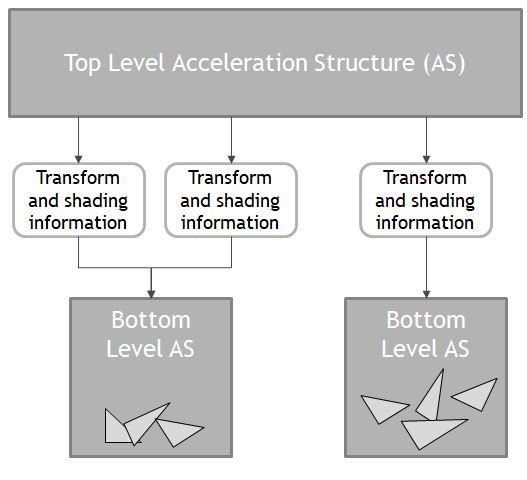
Acceleration structures can be built out of existing geometry in VkBuffer objects. Building an AS is a two-step process: creating bottom level nodes first, then generating the top level node.
All of the build/update operations happen on the GPU, diagrammed in figure 4. In this context, “build” means creating a new object from scratch (e.g., when initially setting up the scene) while “update” means that we’re updating an existing object with some new data (e.g., when a character moves in an existing scene). While both build and update operations are designed to be very efficient, updates in particular have some restrictions to guarantee maximum efficiency.
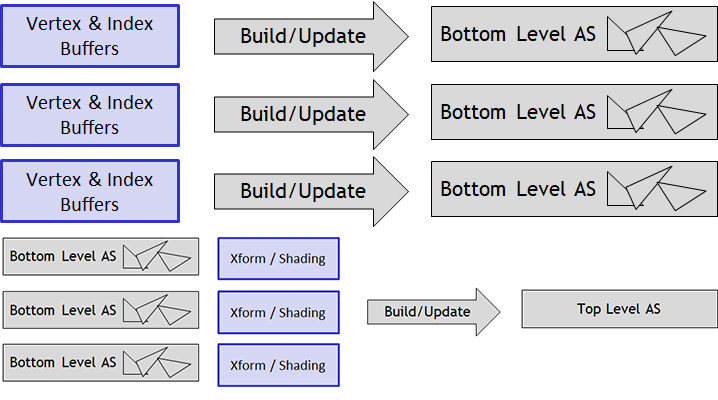
At the API level, we define a new Vulkan object type: VkAccelerationStructureNVX. Each instance of this object encapsulates either a top-level or a bottom-level AS node. We also define a new resource descriptor type, VK_DESCRIPTOR_TYPE_ACCELERATION_STRUCTURE_NVX, for binding AS objects to shaders.
Object creation and destruction follows the usual Vulkan paradigm: an acceleration structure node is created with a call to vkCreateAccelerationStructureNVX, which returns an opaque handle. This handle can then be used with vkGetAccelerationStructureMemoryRequirementsNVX to obtain information on what kind of and how much memory this acceleration structure will need. Memory can then be allocated with vkAllocateMemory and bound to the object by calling vkBindAccelerationStructureMemoryNVX.
Managing Acceleration Structure Memory
Acceleration structure build / update operations require some amount of temporary “scratch” memory to work with. This memory can be queried by calling vkGetAccelerationStructureScratchMemoryRequirementsNVX.
The scratch memory takes the form of a regular VkBuffer object, allocated based on the memory requirements returned by the implementation. This is passed in as an argument to the build / update commands.
The amount of memory required by the AS object depends on the specific geometry data that is passed in. The data returned by vkGetAccelerationStructureMemoryRequirementsNVX is therefore an upper bound for the amount of memory that will be required by a particular object. Once the structure is built, the vkCmdWriteAccelerationStructurePropertiesNVX command can be used to cause the GPU to write out the compacted size of a given AS object into a Vulkan query object, which can then be read on the CPU. This can then be used to allocate a separate AS object with the exact amount of memory required, and vkCmdCopyAccelerationStructureNVX can be used to compact the original AS object into the new AS object.
Acceleration Structure Build / Update Execution
AS build/update commands execute on the GPU and can be submitted to either graphics or compute queues. The API allows the implementation to parallelize successive build/update commands, in order to maximize GPU utilization.
Care should be taken when reusing scratch buffers across build/update commands, as their execution may overlap. Barrier synchronization is required for correctness, using the new memory access flag bits VK_ACCESS_ACCELERATION_STRUCTURE_READ_BIT_NVX and VK_ACCESS_ACCELERATION_STRUCTURE_WRITE_BIT_NVX: they should be used in buffer memory barriers on the scratch buffer before reusing the same buffer region for another operation and on global memory barriers to ensure the AS build/update has completed before the AS object is used for tracing rays.
In order to maximize overlap, it is recommended to allocate enough scratch buffer memory for multiple build/update operations, and assign each consecutive operation distinct memory regions. How much memory to allocate depends on how sensitive the application is to acceleration structure build performance, as well as how many acceleration structures will be used.
For more detailed information on the acceleration structure API, consult the Acceleration Structure section of the Vulkan specification: https://www.khronos.org/registry/vulkan/specs/1.1-extensions/html/vkspec.html#resources-acceleration-structures
Ray Tracing shader domains
In order to expose ray tracing functionality to the Vulkan API, we’re defining a new set of shader domains, along with primitives for inter-shader communication. Figure 5 shows the flow.
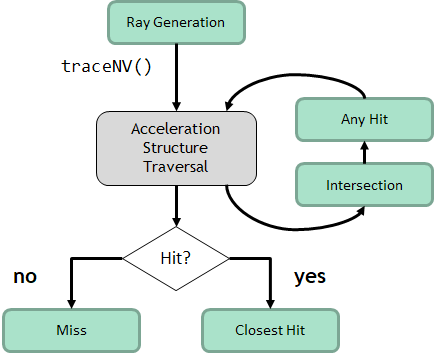
Ray Generation
Ray generation shaders (“raygen”) begin all ray tracing work. A raygen shader runs on a 2D grid of threads, much like a compute shader, and is the starting point for tracing rays into the scene. It is also responsible for writing the final output from the ray tracing algorithm out to memory.
Intersection Shaders
Intersection shaders implement arbitrary ray-primitive intersection algorithms. They are useful to allow applications to intersect rays with different kinds of primitives (e.g., spheres) that do not have built-in support. Triangle primitives have built-in support and don’t require an intersection shader.
Hit Shaders
Hit shaders are invoked when a ray-primitive intersection is found. They are responsible for computing the interactions that happen at an intersection point (e.g., light-material interactions for graphics applications) and can spawn new rays as needed.
There are two kinds of hit shaders: any-hit shaders are invoked on all intersections of a ray with scene primitives, in an arbitrary order, and can reject intersections in addition to computing shading data. Closest-hit shaders invoke only on the closest intersection point along the ray.
Miss Shaders
Miss shaders are invoked when no intersection is found for a given ray.
Inter-shader communication
During the execution of a ray tracing call, the various shader stages need to pass data between each other. Intersection shaders need to output intersection data, hit shaders need to consume intersection data and modify some arbitrary result data, and raygen shaders need to consume the final result data and output it to memory.
The ray payload is an arbitrary, application-defined data structure that stores information being accumulated along the path of the ray. It is initialized by the shader that initiates a ray query operation (usually the raygen shader), and can be read and modified by the hit shaders. It’s typically used to output material properties accumulated along the path of the ray, which the raygen shader will then write out to memory.
Ray attributes comprise a set of values passed back from the intersection shader to the hit shaders, containing whatever data the application needs to emit from the intersection test. They get encapsulated in an application-defined structure which is written by the intersection shader and read by the hit shaders invoked on that intersection. For the built-in ray-triangle intersection shader, the ray attributes are a vec2 containing the barycentric coordinates of the intersection point along the triangle.
GLSL Language Mappings
Relatively few shading language changes are required to enable ray tracing in Vulkan.
The API defines five new shader stages for building GLSL shaders: rgen for raygen shaders, rint for intersection shaders, rchit for closest-hit shaders, rahit for any-hit shaders, and rmiss for miss shaders.
Several new built-in variables now exist, depending on shader stage, and contain information on various parameters. These include the current raygen thread ID, the raygen launch grid size, primitive and instance ID values, current ray origin and direction in world and object space, and the T value for the current intersection being processed along the ray, among others.
A new opaque resource type is defined for acceleration structure resource bindings, accelerationStructureNVX. Acceleration structures are bound to the shader pipeline the same way as other resource types. Note that several acceleration structures can be used within the same shader, enabling hierarchical traversal of distinct sets of geometry data within the shader.
We also defined a few new storage qualifiers for user-defined types: rayPayloadNVX, rayPayloadInNVX, and hitAttributeNVX which declare the ray payload (and define which shader stage owns the storage for a given payload) and hit attribute types to be used. A new layout qualifier, shaderRecordNVX, which declares a SSBO as being bound to the shader binding table (more on that later) has been added.
Finally, a handful of new built-in functions have been added. These include traceNVX(), which launches a ray into the scene, ignoreIntersectionNVX() to discard a given intersection point, and terminateRayNVX() to stop processing a ray at a given hit.
Ray Payload Structure Matching
The ray tracing shader API allows for any application-defined structure to be used as the ray payload. This payload is declared in a shader stage that can spawn rays (typically raygen), and is passed in by reference to the hit shader stages that will modify it.
Because GLSL does not feature type-polymorphism, we can’t define the traceNVX() call as being type-polymorphic. This means that we cannot pass arbitrary types as arguments. To work around this, we designed a solution that matches data types based on the location layout qualifier.
Each ray payload structure is declared with the rayPayloadNVX qualifier plus a location layout qualifier that associates it with an integer value. This integer value essentially becomes a numeric identifier for the payload variable that is then passed in to the traceNVX() call in place of a reference to the actual variable. Hit shaders need to declare the same data type as a variable with the rayPayloadInNVX qualifier, enabling the ray tracing infrastructure to treat that variable as a reference to the incoming payload data.
To illustrate this mechanism, consider the following code fragment from a simple raygen shader as an example:
layout (location = 1) rayPayloadNVX primaryPayload {
vec4 color;
};
void main()
{
color = vec4(0.0, 0.0, 0.0, 0.0);
traceNVX(scene, // acceleration structure
...
1); // payload location index
imageStore(framebufferImage, gl_GlobalInvocationIDNV.xy,
color);
}
You can see that primaryPayload is our ray payload. It is assigned a location index of 1 in the declaration, and that index is passed in as the last parameter to traceNVX().
The corresponding closest hit shader might look something like this:
rayPayloadInNVX primaryPayload {
vec4 color;
}
layout(set = 3, binding = 0) sampler3D solidMaterialSampler;
void main()
{
vec3 pos = gl_WorldRayOriginNVX +
gl_HitTNVX * gl_WorldRayDirectionNVX;
color = texture(solidMaterialSampler, pos);
}
The same payload structure is declared using the rayPayloadInNVX keyword. Only a single rayPayloadInNVX variable in the shader may exist (and only hit and miss shaders can declare them), so no layout qualifier is required. Note that there exists no static validation for matching payload types; mismatching types will lead to undefined behavior. Also note that the payload value in the traceNVX() call must be a compile-time immediate value.
For more information on the GLSL language mappings, please consult the extension specification for GLSL.
Shader Binding Table
The final new concept introduced to the API is the shader binding table (SBT). This is a VkBuffer containing a set of uniform-sized records and consisting of shader handles followed by application-defined data. The shader handles determine which shaders to run for a given SBT record while the application-defined data in the record is made available to the shaders as an SSBO.
Each SBT instance has a fixed record size. Within each record, a series of indexing rules determine how the ray tracing infrastructure will obtain the handles and SSBO data for the next shader to execute.
The SSBO data in the SBT is intended to specify which resources (textures, uniform buffers, etc) each shader will use. The intended usage pattern is for all potentially accessible resources to be bound to the pipeline via descriptor sets, using resource arrays. The SBT will then contain indices into these arrays indicating which specific resources should be used for a given set of shaders. That said, the SBT is “just data” from the point of view of the shader — it can contain other kinds of information as well.
For more information on the shader binding table, consult the Vulkan specification on the topic.
Ray Tracing Pipeline
The last piece required is the ray tracing pipeline state object. Ray tracing pipelines consist of just a (potentially very large!) collection of raygen, intersection, hit and miss shaders, together with a couple of ray tracing specific parameters (such as the maximum ray recursion depth).
Since a single ray tracing PSO can contain many shaders, compilation times may be very high. We mitigated this cost by adding an interface to allow the application to control compilation for individual shaders. At PSO creation time, a new flag, VK_PIPELINE_CREATE_DEFER_COMPILE_BIT_NVX, instructs the driver to avoid compiling shaders immediately. The application must then call vkCompileDeferredNVX for each shader in order to trigger the compilation work. This can be parallelized across threads to minimize compilation times.
Once created, ray tracing pipeline objects can be bound to a graphics or compute queue using standard Vulkan calls with a new pipeline bind point, VK_PIPELINE_BIND_POINT_RAYTRACING_NVX.
You can read more about ray tracing pipeline creation in the Vulkan specification.
Launching Work
Once the acceleration structure is built, the shader binding table is created, and a raytracing PSO has been created and bound, it’s time to start tracing rays.
A single Vulkan command initiates ray tracing work: vkCmdTraceRaysNVX. The arguments to this command specify the 2D thread grid dimensions, as well as the VkBuffer that contains the SBT to be used and the offsets within that SBT for the various data elements required (raygen shader handle and SSBO data offsets, initial hit shader handle and SSBO data offsets, as well as the offsets for the miss shader handle and corresponding SSBO data).
More information on vkCmdTraceRaysNVX is available here.
Conclusion
We’ve released VK_NVX_raytracing as a developer preview to enable developers to acquaint themselves with RTX-based ray tracing in Vulkan. This can be used together with the latest Vulkan SDK from LunarG, which features support for all of our Turing extensions, to develop ray tracing applications using Vulkan.
We believe Vulkan provides a good base for this functionality; the extensibility built in to the API means we can leverage most existing mechanisms and infrastructure, enabling seamless integration with the existing rasterization functionality.
We strongly believe in Vulkan’s core goal of providing a vendor- and hardware-agnostic API. NVIDIA remains committed to working within Khronos on multi-vendor standardization efforts for ray tracing functionality in Vulkan, and we’ve offered our extension as one starting point for discussion.