Modern graphics APIs, such as Direct3D 12 and Vulkan, are designed to provide relatively low-level access to the GPU and eliminate the GPU driver overhead associated with API translation. This low-level interface allows applications to have more control over the system and provides the ability to manage pipelines, shader compilation, memory allocations, and resource descriptors in a way that is best for each application.
On the other hand, this closer-to-the-hardware access to the GPU means that the application must manage these things on its own, instead of relying on the GPU driver. A basic “hello world” program that draws a single triangle using these APIs can grow to a thousand lines of code or more. In a complex renderer, managing the GPU memory, descriptors, and so on, can quickly become overwhelming if not done in a systematic way.
If an application or an engine must work with more than one graphics API, it can be done in two ways:
- Duplicate the rendering code to work with each API separately. This approach has an obvious drawback of having to develop and maintain multiple independent implementations.
- Implement an abstraction layer over the graphics APIs that provides the necessary functionality in a common interface. This has a different drawback of the development and maintenance of the abstraction layer. Most major game engines implement the second approach.
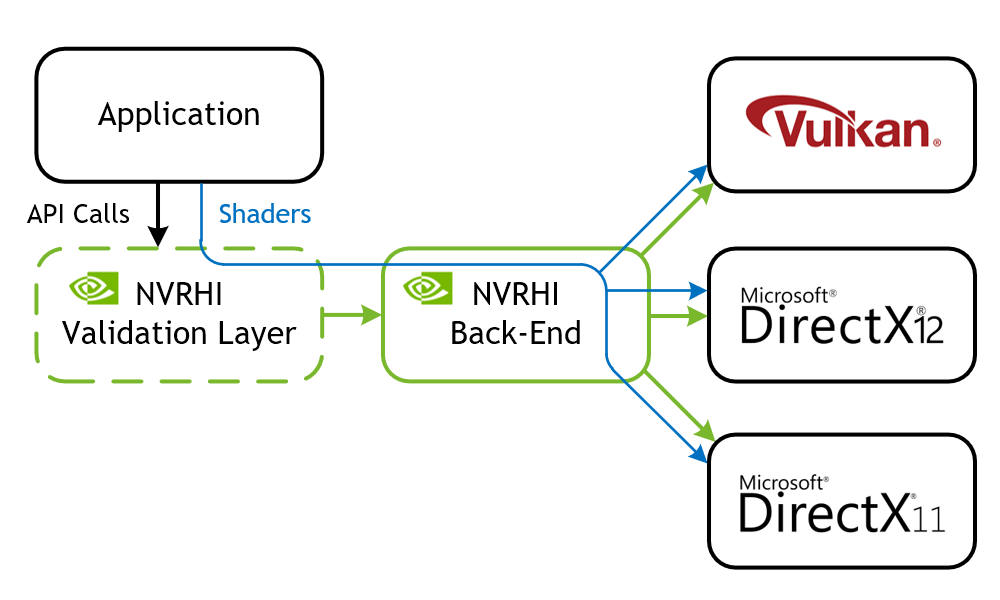
NVIDIA Rendering Hardware Interface (NVRHI) is a library that handles these drawbacks. It defines a custom, higher-level graphics API that maps well to the three supported native graphics APIs: Vulkan, D3D12, and D3D11. It manages resources, pipelines, descriptors, and barriers in a safe and automatic way that can be easily disabled or bypassed when necessary to reduce CPU overhead. On top of that, NVRHI provides a validation layer that ensures that the application’s use of the API is correct, similar to what the Direct3D debug runtime or the Vulkan validation layers do, but on a higher level.
There are some features related to portability that NVRHI doesn’t provide. First, it doesn’t compile shaders at run time or read shader reflection data to bind resources dynamically. In fact, NVRHI doesn’t process shaders at run time at all. The application provides a platform-specific shader binary, that is, a DXBC, DXIL or SPIR-V blob. NVRHI passes that directly to the underlying graphics API. Matching the binding layouts is left up to the application and is validated by the underlying graphics API. Secondly, NVRHI doesn’t create graphics devices or windows. That is also left up to the application or other libraries, such as GLFW.
In this post, I go over the main features of NVRHI and explain how each feature helps graphics engineers be more productive and write safer code.
- Resource lifetime management
- Binding layouts and binding sets
- Automatic resource state tracking
- Upload management
- Interaction with graphics APIs
- Shader permutations
Resource lifetime management
In Vulkan and D3D12, the application must take care to destroy only the device resources that the GPU is no longer using. This can be done with little overhead if the resource usage is planned carefully, but the problem is in the planning.
NVRHI follows the D3D11 resource lifetime model almost exactly. Resources, such as buffers, textures, or pipelines, have a reference count. When a resource handle is copied, the reference count is incremented. When the handle is destroyed, the reference count is decremented. When the last handle is destroyed and the reference count reaches zero, the resource object is destroyed, including the underlying graphics API resource. But that’s what D3D12 does as well, right? Not quite.
NVRHI also keeps internal references to resources that are used in command lists. When a command list is opened for recording, a new instance of the command list is created. That instance holds references to each resource it uses. When the command list is closed and submitted for execution, the instance is stored in a queue along with a fence or semaphore value that can be used to determine if the instance has finished executing on the GPU. The same command list can be reopened for recording immediately after that, even while the previous instance is still executing on the GPU.
The application should call the nvrhi::IDevice::runGarbageCollection method occasionally, at least one time per frame. This method looks at the in-flight command list instance queue and clears the instances that have finished executing. Clearing the instance automatically removes the internal references to the resources used in the instance. If a resource has no other references left, it is destroyed at that time.
This behavior can be shown with the following code example:
{
// Create a buffer in a scope, which starts with reference count of 1
nvrhi::BufferHandle buffer = device->createBuffer(...);
// Creates an internal instance of the command list
commandList->open();
// Adds a buffer reference to the instance, which increases reference count to 2
commandList->clearBufferUInt(buffer, 0);
commandList->close();
// The local reference to the buffer is released here, decrements reference count to 1
}
// Puts the command list instance into the queue
device->executeCommandList(commandList);
// Likely doesn't do anything with the instance
// because it's just been submitted and still executing on the GPU
device->runGarbageCollection();
device->waitForIdle();
// This time, the buffer should be destroyed because
// waitForIdle ensures that all command list instances
// have finished executing, so when the finished instance
// is cleared, the buffer reference count is decremented to zero
// and it can be safely destroyed
device->runGarbageCollection();
The “fire and forget” pattern shown here, when the application creates a resource, uses it, and then immediately releases it, is perfectly fine in NVRHI, unlike D3D12 and Vulkan.
You might wonder whether this type of resource tracking becomes expensive if the application performs many draw calls with lots of resources bound for each draw call. Not really. Draw calls and dispatches do not deal with individual resources. Textures and buffers are grouped into immutable binding sets, which are created, hold permanent references to their resources, and are tracked as a single object.
So, when a certain binding set is used in a command list, the command list instance only stores a reference to the binding set. And that store is skipped if the binding set is already bound, so that repeated draw calls with the same bindings do not add tracking cost. I explain binding sets in more detail in the next section.
Another thing that can help reduce the CPU overhead imposed by resource lifetime tracking is the trackLiveness setting that is available on binding sets and acceleration structures. When this parameter is set to false, the internal references are not created for that particular resource. In this case, the application is responsible for keeping its own reference and not releasing it while the resource is in use.
Binding layouts and binding sets
NVRHI features a unique resource binding model designed for safety and runtime efficiency. As mentioned earlier, various resources that are used by graphics or compute pipelines are grouped into binding sets.
Put simply, a binding set is an array of resource views that are bound to particular slots in a pipeline. For example, a binding set may contain a structured buffer SRV bound to slot t1, a UAV for a single texture mip level bound to slot u0, and a constant buffer bound to slot b2. All the bindings in a set share the same visibility mask (which shader stages will see that binding) and register space, both dictated by the binding layout.
Binding layouts are the NVRHI version of D3D12 root signatures and Vulkan descriptor set layouts. A binding layout is like a template for a binding set. It declares what resource types are bound to which slots, but does not tell which specific resources are used.
Like the root signatures and descriptor set layouts, NVHRI binding layouts are used to create pipelines. A single pipeline may be created with multiple binding layouts. These can be useful to bin resources into different groups according to their modification frequency, or to bind different sets of resources to different pipeline stages.
The following code example shows how a basic compute pipeline can be created with one binding layout:
auto layoutDesc = nvrhi::BindingLayoutDesc() .setVisibility(nvrhi::ShaderType::All) .addItem(nvrhi::BindingLayoutItem::Texture_SRV(0)) // texture at t0 .addItem(nvrhi::BindingLayoutItem::ConstantBuffer(2)); // constants at b2 // Create a binding layout. nvrhi::BindingLayoutHandle bindingLayout = device->createBindingLayout(layoutDesc); auto pipelineDesc = nvrhi::ComputePipelineDesc() .setComputeShader(shader) .addBindingLayout(bindingLayout); // Use the layout to create a compute pipeline. nvrhi::ComputePipelineHandle computePipeline = device->createComputePipeline(pipelineDesc);
Binding sets can only be created from a matching binding layout. Matching means that the layout must have the same number of items, of the same types, bound to the same slots, in the same order. This may look redundant, and the D3D12 and Vulkan APIs have less redundancy in their descriptor systems. This redundancy is useful: it makes the code more obvious, and it allows the NVRHI validation layer to catch more bugs.
auto bindingSetDesc = nvrhi::BindingSetDesc() // An SRV for two mip levels of myTexture. // Subresource specification is optional, default is the entire texture. .addItem(nvrhi::BindingSetItem::Texture_SRV(0, myTexture, nvrhi::Format::UNKNOWN, nvrhi::TextureSubresourceSet().setBaseMipLevel(2).setNumMipLevels(2))) .addItem(nvrhi::BindingSetItem::ConstantBuffer(2, constantBuffer)); // Create a binding set using the layout created in the previous code snippet. nvrhi::BindingSetHandle bindingSet = device->createBindingSet(bindingSetDesc, bindingLayout);
Because the binding set descriptor contains almost all the information necessary to create the binding layout as well, it is possible to create both with one function call. That may be useful when creating some render passes that only need one binding set.
#include <nvrhi/utils.h> ... nvrhi::BindingLayoutHandle bindingLayout; nvrhi::BindingSetHandle bindingSet; nvrhi::utils::CreateBindingSetAndLayout(device, /* visibility = */ nvrhi::ShaderType::All, /* registerSpace = */ 0, bindingSetDesc, /* out */ bindingLayout, /* out */ bindingSet); // Now you can create the pipeline using bindingLayout.
Binding sets are immutable. When you create a binding set, NVRHI allocates the descriptors from the heap on D3D12 or creates a descriptor set on Vulkan and populates it with the necessary resource views.
Later, when the binding set is used in a draw or dispatch call, the binding operation is lightweight and translates to the corresponding graphics API binding calls. There is no descriptor creation or copying happening at render time.
Automatic resource state tracking
Explicit barriers that change resource states and introduce dependencies in the graphics pipelines are an important part of both D3D12 and Vulkan APIs. They allow applications to minimize the number of pipeline dependencies and bubbles and to optimize their placement. They reduce CPU overhead at the same time by removing that logic from the driver. That’s relevant mostly to tight render loops that draw lots of geometry. Most of the time, especially when writing new rendering code, dealing with barriers is just annoying and bug-prone.
NVHRI implements a system that tracks the state of each resource and, optionally, subresource per command list. When a command interacts with a resource, the resource is transitioned into the state required for that command, if it’s not already in that state. For example, a writeTexture command transitions the texture into the CopyDest state, and a subsequent draw operation that reads from the texture transitions it into the ShaderResources state.
Special handling is applied when a resource is in the UnorderedAccess state for two consecutive commands: there is no transition involved, but a UAV barrier is inserted between the commands. It is possible to disable the insertion of UAV barriers temporarily, if necessary.
I said earlier that NVRHI tracks the state of each resource per command list. An application may record multiple command lists in any order or in parallel and use the same resource differently in each command list. Therefore, you can’t track the resource states globally or per-device because the barriers need to be derived while the command lists are being recorded. Global tracking may not happen in the same order as actual resource usage on the device command queue when the command lists are executed.
So, you can track resource states in each command list separately. In a sense, this can be viewed as a differential equation. You know how the state changes inside the command list, but you don’t know the boundary conditions, that is, which state each resource is in when you enter and exit the command list in their order of execution.
The application must provide the boundary conditions for each resource. There are two ways to do that:
- Explicit: Use the
beginTrackingTextureStateandbeginTrackingBufferStatefunctions after opening the command list and thesetTextureStateandsetBufferStatefunctions before closing it. - Automatic: Use the
initialStateandkeepInitialStatefields of theTextureDescandBufferDescstructures when creating the resource. Then, each command list that uses the resource assumes that it’s in the initial state upon entering the command list, and transition it back into the initial state before leaving the command list.
Here, you might wonder about avoiding the CPU overhead of resource state tracking, or manually optimizing barrier placement. Well, you can! The command lists have the setEnableAutomaticBarriers function that can completely disable automatic barriers. In this mode, use the setTextureState and setBufferState functions where a barrier is necessary. It still uses the same state tracking logic but potentially at a lower frequency.
Upload management
NVRHI automates another aspect of modern graphics APIs that is often annoying to deal with. That’s the management of upload buffers and the tracking of their usage by the GPU.
Typically, when some texture or buffer must be updated from the CPU on every frame or multiple times per frame, a staging buffer is allocated whose size is multiple times larger than the resource memory requirements. This enables multiple frames in-flight on the GPU. Alternately, portions of a large staging buffer are suballocated at run time. It is possible to implement the same strategy using NVRHI, but there is a built-in implementation that works well for most use cases.
Each NVRHI command list has its own upload manager. When writeBuffer or writeTexture is called, the upload manager tries to find an existing buffer that is no longer used by the GPU that can fit the necessary data. If no such buffer is available, a new buffer is created and added to the upload manager’s pool. The provided data is copied into that buffer, and then a copy command is added to the command list. The tracking of which buffers are used by the GPU is performed automatically.
ConstantBufferStruct myConstants; myConstants.member = value; // This is all that's necessary to fill the constant buffer with data and have it ready for rendering. commandList->writeBuffer(constantBuffer, myConstants, sizeof(myConstants));
The upload manager never releases its buffers, nor shares them with other command lists. Perhaps an application is doing a significant number of uploads, such as during scene loading, and then switching to a less upload-intensive mode of operation. In that case, it’s better to create a separate command list for the uploading activity and release it when the uploads are done. That releases the upload buffers associated with the command list.
It’s not necessary to wait for the GPU to finish copying data from the upload buffers. The resource lifetime tracking system described earlier does not release the upload buffers until the copies are done.
Interaction with graphics APIs
Sometimes, it is necessary to escape the abstraction layers and do something with the underlying graphics API directly. Maybe you have to use some feature that is not supported by NVRHI, demonstrate some API usage in a sample application, or make the portable rendering code work with a native resource coming from elsewhere. NVRHI makes it relatively easy to do these things.
Every NVRHI object has a getNativeObject function that returns an underlying API resource of the necessary type. The expected type is passed to that function, and it only returns a non-NULL value if that type is available, to provide some type safety.
Supported types include interfaces like ID3D11Device or ID3D12Resource and handles like vk::Image. In addition, the NVRHI texture objects have a getNativeView function that can create and return texture views, such as SRV or UAV.
For example, to issue some native D3D12 rendering commands in the middle of an NVRHI command list, you might use code like the following example:
ID3D12GraphicsCommandList* d3dCmdList = nvrhiCommandList->getNativeObject(
nvrhi::ObjectTypes::D3D12_GraphicsCommandList);
D3D12_CPU_DESCRIPTOR_HANDLE d3dTextureRTV = nvrhiTexture->getNativeView(
nvrhi::ObjectTypes::D3D12_RenderTargetViewDescriptor);
const float clearColor[4] = { 0.f, 0.f, 0.f, 0.f };
d3dCmdList->ClearRenderTargetView(d3dTextureRTV, clearColor, 0, nullptr);
Shader permutations
The final productivity feature to mention here is the batch shader compiler that comes with NVRHI. It is an optional feature, and NVRHI can be completely functional without it. NVRHI accepts shaders compiled through other means. Still, it is a useful tool.
It is often necessary to compile the same shader with multiple combinations of preprocessor definitions. However, the native tools that Visual Studio provides for shader compilation, for example, do not make this task easy at all.
The NVRHI shader compiler solves exactly this problem. Driven by a text file that lists the shader source files and compilation options, it generates option permutations and calls the underlying compiler (DXC or FXC) to generate the binaries. The binaries for different versions of the same shader are then packaged into one file of a custom chunk-based format that can be processed using the functions declared in <nvrhi/common/shader-blob.h>.
The application can load the file with all the shader permutations and pass it to nvrhi::utils::createShaderPermutation or nvrhi::utils::createShaderLibraryPermutation, along with the list of preprocessor definitions and their values. If the requested permutation exists in the file, the corresponding shader object is created. If it doesn’t, an error message is generated.
In addition to permutation processing, the shader compiler has other nice features. First, it scans the source files to build a tree of headers included in each one. It detects if any of the headers have been modified, and whether a particular shader must be rebuilt. Second, it can build all the outdated shaders in parallel using all available CPU cores.
Conclusion
In this post, I covered some of the most important features of NVRHI that, in my opinion, make it a pleasure to use. For more information about NVHRI, see the NVIDIAGameWorks/nvrhi GitHub repo, which includes a tutorial and a more detailed programming guide. The Donut Examples repository on GitHub has several complete applications written with NVRHI.
If you have questions about NVRHI, post an issue on GitHub or send me a message on Twitter (@more_fps).