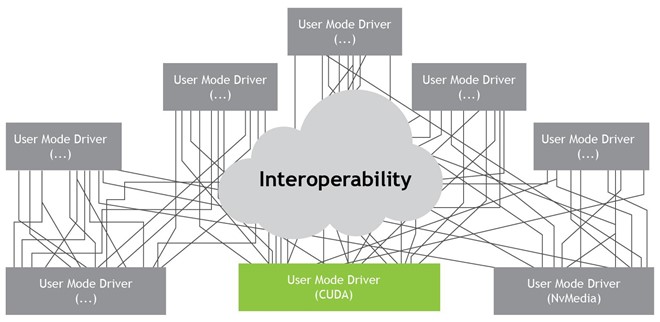
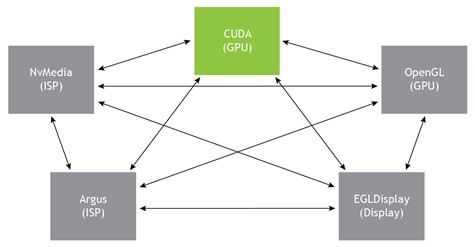
There is a growing need among embedded and HPC applications to share resources and control execution for pipelined workflows spanning multiple hardware engines and software applications. The following diagram gives an insight into the number of engines that can be supported on NVIDIA-embedded platforms.
In addition to GPUs, this includes image processing units like image signal processors (ISP) and accelerators like deep learning accelerators (DLA) or programmable vision accelerators (PVA). Each of these engines in turn has one or more user-mode drivers (UMDs) to expose functionality, including the following:
- GPU: CUDA ,OpenGL, Vulkan
- ISP: NvMedia, Argus
- DLA: NvMedia, TensorRT
This post introduces the new features introduced in CUDA 10.2: Interoperability with NvSciSync and NvSciBuf designed to provide uniform interoperability solutions. These solutions are safe, secure, and robust enough to be used in safety-critical applications, such as the NVIDIA DRIVE AGX platform.
What is interoperability?
Here’s an example: A typical machine-learning algorithm like gesture recognition can employ ISPs for image input, DLAs for inference, and GPUs for executing image processing algorithms like stitching, cropping, scaling, and displaying. Figure 2 shows that such workflows usually execute in a pipelined manner, with output from one workflow serving as input for the next.
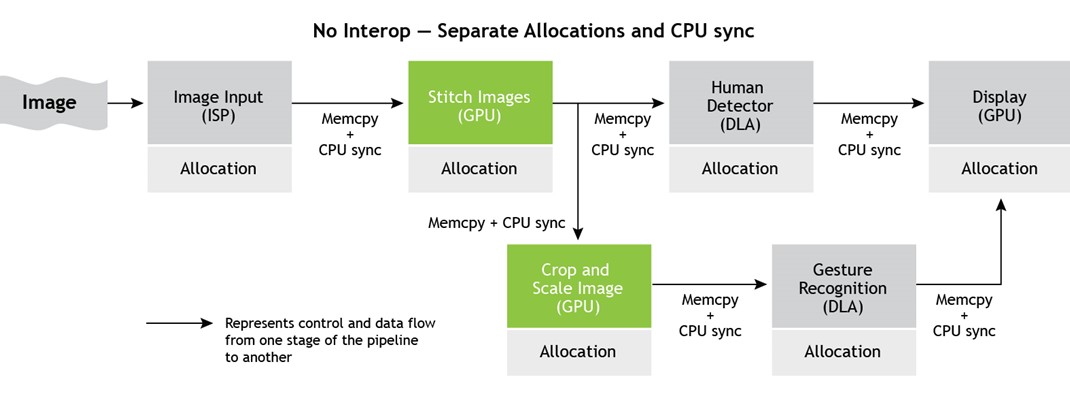
A mechanism of sharing resources across engines and drivers over processes and systems avoids engine-specific UMD memory allocators and data migration and synchronization across engines using the host or CPU as an intermediary. This mechanism provides interoperability to share memory and synchronization primitives.
Evolution of CUDA interoperability
Traditionally, CUDA has supported one-to-one interops with other NVIDIA-supported GPU drivers like OpenGL or DirectX like CUDA-OpenGL so that OpenGL-allocated memory could be accessed by CUDA.
Such one-to-one interops failed to scale up for embedded systems due to the sheer maintainability cost of sustaining so many interops, not to mention the developer overhead of understanding and using new interops for each set of UMDs.
The need of the hour is to adapt to common interops that can be plugged in to support multiple drivers and hardware units.

EGLStream and EGLImage are some of the common interops supported by CUDA and are widely used on NVIDIA platforms.
Motivation for NvSciBuf and NvSciSync
NvSciBuf and NvSciSync were developed to address the following requirements:
- Allow sharing of memory and sync primitives across engines and UMDs.
- Allow sharing across threads, processes, and VM partitions.
- Enable cache coherence for data stored in an engine’s local caches.
- Synchronize to ensure ordered access and provide control flow in pipelined applications.
- Allow the usage of driver-specific data types.
You may ask why you can’t just use the existing EGL interoperability? While NVIDIA continues to support EGL, there are several reasons to use a different interop:
- Allocation APIs exposed by the EGLStream producer fail to take into consideration the engine restrictions of the EGLStream consumer and often result in mapping failure on the consumer side.
- EGL interfaces were not designed with automotive safety in mind and have failure modes that cannot be used in an automotive-grade, safety-certified system.
- EGLStream forces producer-consumer semantics on an application, which are not flexible if you want to set up only control-dependency.
- EGL understands only two-dimensional image data. It cannot handle tensors or other non-image sensor data required for interference engines like DLA.
Introduction to NvSci
The NVIDIA Software Communication Interface (NvSci) libraries bundled with the NVIDIA SDK serve two primary purposes:
- They allow resources to be allocated up front, with access restrictions defined by the applications and with details of their overall requirements well understood.
- They allow resources to be exchanged between libraries that otherwise do not have knowledge of each other.
Multiple libraries are exposed by NvSci to cater to separate functionalities:
- NvSciBuf for buffer management
- NvSciSync for synchronization
- NvIPC for interprocess communication
- NvStream for streaming
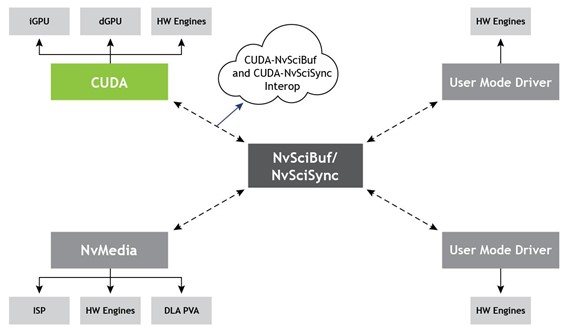
Of these, CUDA exposes interfaces to import NvSciBuf and NvSciSync as CUDA External Memory and Semaphore, respectively. For more information, see NvStreams.
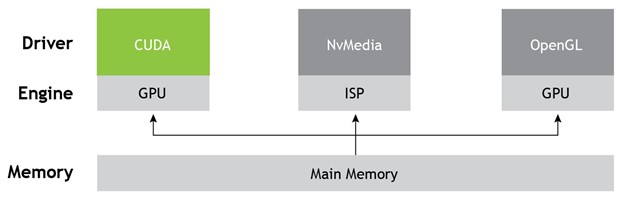
CUDA-NvSciBuf interop overview
With the current UMD-specific memory management APIs, improvements can be made to allow allocations from one UMD to be used by another, possibly acting on a different engine and especially considering compatibility across UMD-specific allocators and datatypes. Figure 7 shows how CUDA data types differ from others with some exposing higher-level constructs like image or texture as opposed to a CUDA pointer and array, making it harder to reconstruct one by using the other.
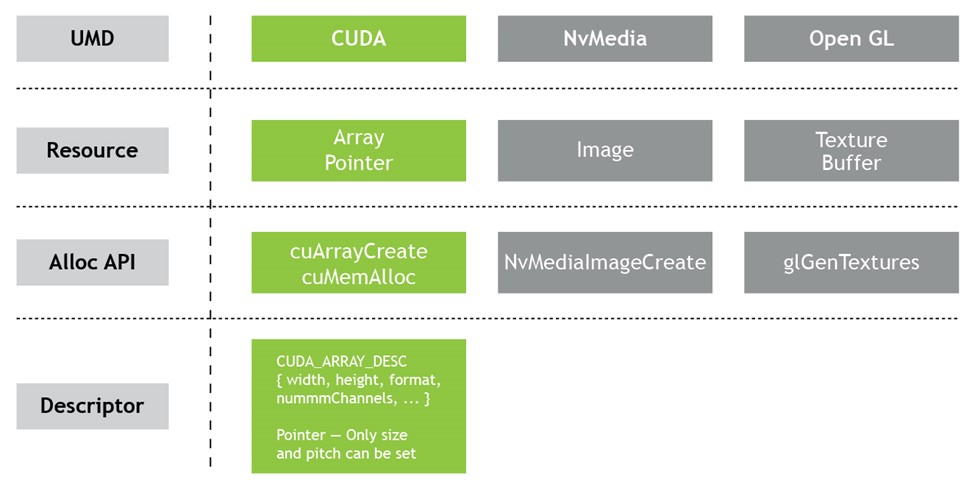
What is NvSciBuf
NvSciBuf is a buffer allocation module that enables applications to allocate a buffer shareable across hardware and software units. NvSciBuf serves a dual purpose:
- Act as a negotiator that understands the constraints of all engines.
- Allocate a memory that can be used by the respective UMDs and accessed as per their existing data types.

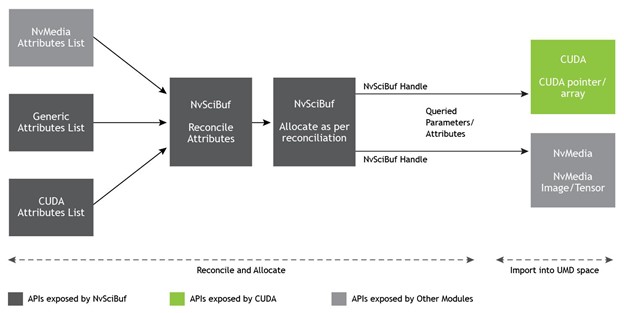
Figure 8 shows that the NvSciBuf object gets allocated as per application specifications, which can then be imported as UMD-specific data types.
NvSciBuf workflow
The buffer allocation model of NvSciBuf extends over multiple stages. For more information, see Buffer Allocation.
- Specify attribute: If two or more hardware engines must access the common buffer, applications specify attributes for each accessor in the form of a list.
- Reconcile: All the attributes from individual lists are reconciled and checked for a viable allocation.
- Allocate: If reconciliation passes, a buffer is allocated.
- Communicate: Share the buffer with all the accessors.
- Import: Each accessor UMD exposes interfaces to import the
NvSciBufobject as per their memory model. For instance, in the case of CUDA UMD, the CUDA external memory interfaces provide mechanisms to import theNvSciBufobject.
Using NvSciBuf with CUDA
CUDA supports the import of an NvSciBufObj object as the CUDA external memory of type NvSciBuf using the function cudaImportExternalMemory. After it’s imported, use cudaExternalMemoryGetMappedBuffer or cudaExternalMemoryGetMappedMipmappedArray to map the imported NvSciBuf object as a CUDA pointer or CUDA array. For more information, see the CUDA Runtime API or the Programming Guide.
As a precursor to import, applications should query allocated NvSciBufObj for the attributes required to fill CUDA descriptors cudaExternalMemoryHandleDesc or cudaExternalMemoryBufferDesc, which are passed as parameters to the import map.
If the NvSciBuf object imported into CUDA is also mapped by other drivers, then the application must use CUDA external semaphore APIs described next as appropriate barriers to maintain coherence between CUDA and the other drivers. After a CUDA pointer or array is created, it can be used with CUDA kernels and CUDA functions like memcpy or memset and freed using CUDA functions. For operations on NvSciBuf object, applications should refer to NvSciBuf functions.
Safety adaptation
To be used in safety-critical platforms, the NvSciBuf interop provides some additional features. The allocation, import, and mapping functions can all be completed in non-safety-critical or init phases, eliminating non-deterministic failures in the safety-critical mission mode phase. This also adheres to the ISO standards necessary for safety compliance.
Applications using NVIDIA DRIVE OS must adhere to the NVIDIA DRIVE OS Safety manuals to ensure that the API can be used in a safe context.
CUDA-NvSciSync interop overview
For applications on NVIDIA DRIVE AGX platforms, apart from the ability to share data, which is met with NvSciBuf, the execution dependencies between engines also must be satisfied.
An example of such an execution dependency is when CUDA should access a buffer to perform inference for example, only after the camera has finished initializing the buffer. One key characteristic for execution control is that each of the UMDs has its own programming model. For example, CUDA follows a control-flow model while other UMDs, such as NvMedia, follow a data-flow model.
Building an interop mechanism to share synchronization objects for coordination must ensure adherence to existing programming models at the same time.
What is NvSciSync
NvSciSync is a generic synchronization framework that allows a UMD to interpret the NvSciSync object the way that it deems fit and makes it simpler to describe complex application workflows.
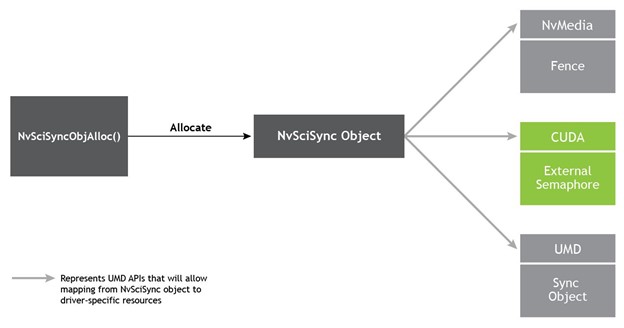
NvSciSync workflow
The synchronization model of NvSciSync extends multiple stages. The basic setup process is like the process used for allocating buffers.
- Specify attributes of the signaler: Restrictions imposed by the hardware components that signal the sync objects.
- Specify attributes of the waiters: Restrictions imposed by the hardware components that wait on the sync object.
- Reconcile: Reconcile and allocate the sync object.
- Share: Share the allocated sync objects with accessors.
- Map—Map the sync objects into UMD-specific interfaces.
For more information, see Synchronization.
Using NvSciSync with CUDA
CUDA supports the import of an NvSciSync object as a CUDA external semaphore of type NvSciSync. The interop enables traditional CUDA streams to wait for tasks that are outside of the CUDA domain and for other UMDs to natively wait for any tasks enqueued in a CUDA stream.
If the CUDA-NvSciSync interop is used to ensure mutually exclusive access to shared NvSciBuf objects imported into CUDA, then the application must set the correct flags. For more information, see NVIDIA Software Communication Interface Interoperability (NVSCI).
Safety adaptation
As with NvSciBuf, the NvSciSync interop provides features to comply with safety requirements. The allocation and import functions should be invoked in the init phase to complete all allocations and avoid non-deterministic failure during the runtime phase. Only wait and signal calls are allowed in runtime. In addition, this also adheres to the ISO standards necessary for safety compliance.
Applications must adhere to the NVIDIA DriveOS Safety manuals to ensure that the API can be used in safety contexts.
Sample application and performance
The sample application demonstrates the CUDA-NvMedia interop with and without NvSciBuf and NvSciSync APIs to evaluate performance gains.
It takes an RGBA image as input and converts it into YUV 420 with help of NvMedia2DblitEx. Then, the YUV output is converted to a grayscale image by the CUDA kernel. This is done twice, one time with NvSci allocators and syncs and another without NvSci, and the timings are noted. For more information about the sample workflow with and without NvSci, see cudaNvSciNvMedia Workflow (PDF) and the NVIDIA/cuda-samples/Samples/cudaNvSciNvMedia GitHub repo.
Figure 11 shows the performance measurements done with this sample app, with an NvSci code path and without, for three different image sizes:
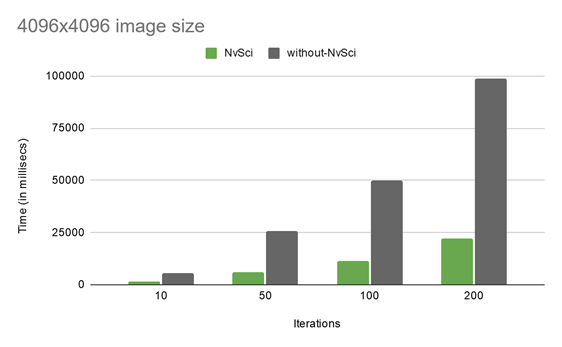

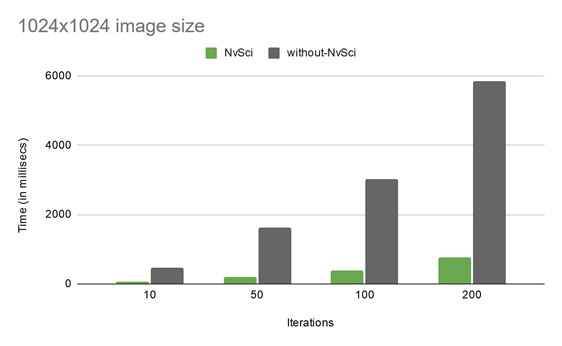
As is evident from these performance charts, with the increasing number of iterative operations and irrespective of image sizes, the performance advantage of using NvSci-based interop is tremendous. For instance, for the 4096×4096 image size with 200 iterations, the performance with NvSci improves by 4.45x compared to without NvSci.
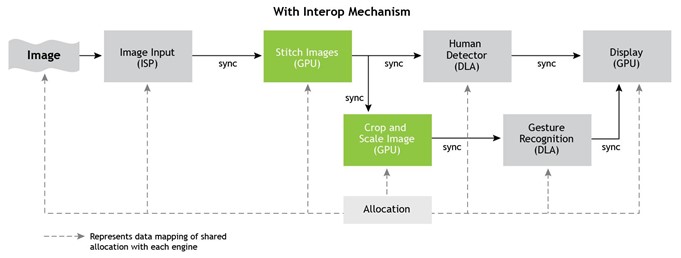
Figure 14 shows how the gesture recognition algorithm described earlier can make use of the NvSci interops to allow a single allocation to be used across all participating hardware units. It defines the control flow using NvSciSync to eliminate CPU-side synchronizations.
Benefits of NvSciBuf and NvSciSync
- Portability: AGX platforms, depending on the hardware and OS, natively support one or more synchronization primitives, such as SyncPoints, Semaphores, Sync FD, and so on. Users of the CUDA
NvSciSyncinterop are abstracted away from the internal platform-specific details. - Reusability: After allocation and reservation, the interop object is reusable, to reduce the resource footprint.
- Multi-casting: Multiple UMDs or entities can wait upon a single interop object. This feature helps avoid creating multiple objects that track the same task as the original interop object.
- High-level software abstraction:
NvSciBufandNvSciSyncfit well into higher-level software abstractions and frameworks likeNvStream, graph-based execution frameworks, user-space schedulers, profilers, and so on. - Safety and security:
NvSciBufandNvSciSyncwere designed to fit into the stringent requirements of a safety-critical system:- Resource-need predictions and reservations.
- Clear partitions between initialization and runtime APIs.
- Software and hardware protection mechanisms.
- Familiarity with x86 and desktop: Applications built on the x86 platform are portable to AGX platforms with minimum changes in the application.
Conclusion
The CUDA interop with NvSciBuf and NvSciSync provides a performant, safety-compliant, and scalable solution deployable in safety-critical domains such as autonomous vehicles. These interops allow applications to share resources and gain fine-grained control of efficiently describing dependencies that spans hardware boundaries, including an entire chip, such as the Tegra SoC A and Tegra SoC B on NVIDIA DRIVE AGX platforms, and software boundaries, such as a thread, process, or VM.
CUDA interops with NvSciBuf or NvSciSync are supported on any NVIDIA platform where CUDA External Resource interoperability is available, with CUDA 10.2 and later. Given that the current version of NvSciBuf and NvSciSync are designed for safety-critical automotive use cases, they are supported on limited platforms.
If you’re on any of the following platforms, you can try out this new interop now:
- x86/Desktop (supported on Ubuntu 18.04 in CUDA 10.2)
- Embedded Linux and QNX (VOLTA+ architectures)
With the upcoming NVIDIA DRIVE OS 5.2.0 release for DRIVE AGX, you can explore this new feature as it works right out-of-the-box and benefit directly from the performance improvement of using an NvSci-based interop. Download this software release in January 2021.
For more information, see the following resources:
