
Creating interactive simulated humanoids that move naturally and respond intelligently to diverse control inputs remains one of the most challenging problems in computer animation and robotics. High-performance GPU-accelerated simulators such as NVIDIA Isaac Sim and robot policy training using NVIDIA Isaac Lab enable significant progress in training interactive humanoids.
Adversarial Motion Priors and Human2Humanoid are recent examples that both present a significant leap forward for simulated and real robots. However, they also share the common pitfall that any change in how the humanoid is controlled requires retraining a new specialized controller.
This post introduces MaskedMimic, a framework that unifies whole-body humanoid control through the lens of motion inpainting. MaskedMimic is part of NVIDIA Project GR00T for enabling development of generalized humanoid robots. This research work contributes to GR00T-Control, a suite of advanced motion planning and control libraries, models, policies and reference workflows for whole-body control.
Overcoming task-specific control
Traditional approaches to humanoid control are inherently limited by their task-specific nature. A controller specialized in path following cannot handle teleoperation tasks requiring head and hand coordinate tracking. Similarly, a controller trained for tracking a demonstrator’s full-body motion, is incapable of adapting to scenarios that require tracking a subset of keypoints.
This specialization creates significant challenges, including:
- Modifying the control scheme requires designing new training environments with specific rewards and observations, and training a new controller from scratch.
- Switching between control modes becomes impractical.
- Working on development and deployment cycles is lengthy and resource-intensive.
Motion inpainting provides a unified solution
Recent advances in generative AI have demonstrated remarkable success using inpainting across multiple domains, such as text, image, and even animation. These methods share a common and powerful concept in that they learn by training to reconstruct complete data from masked (incomplete) or partial views. MaskedMimic adapts this powerful paradigm to the task of full-body humanoid control.
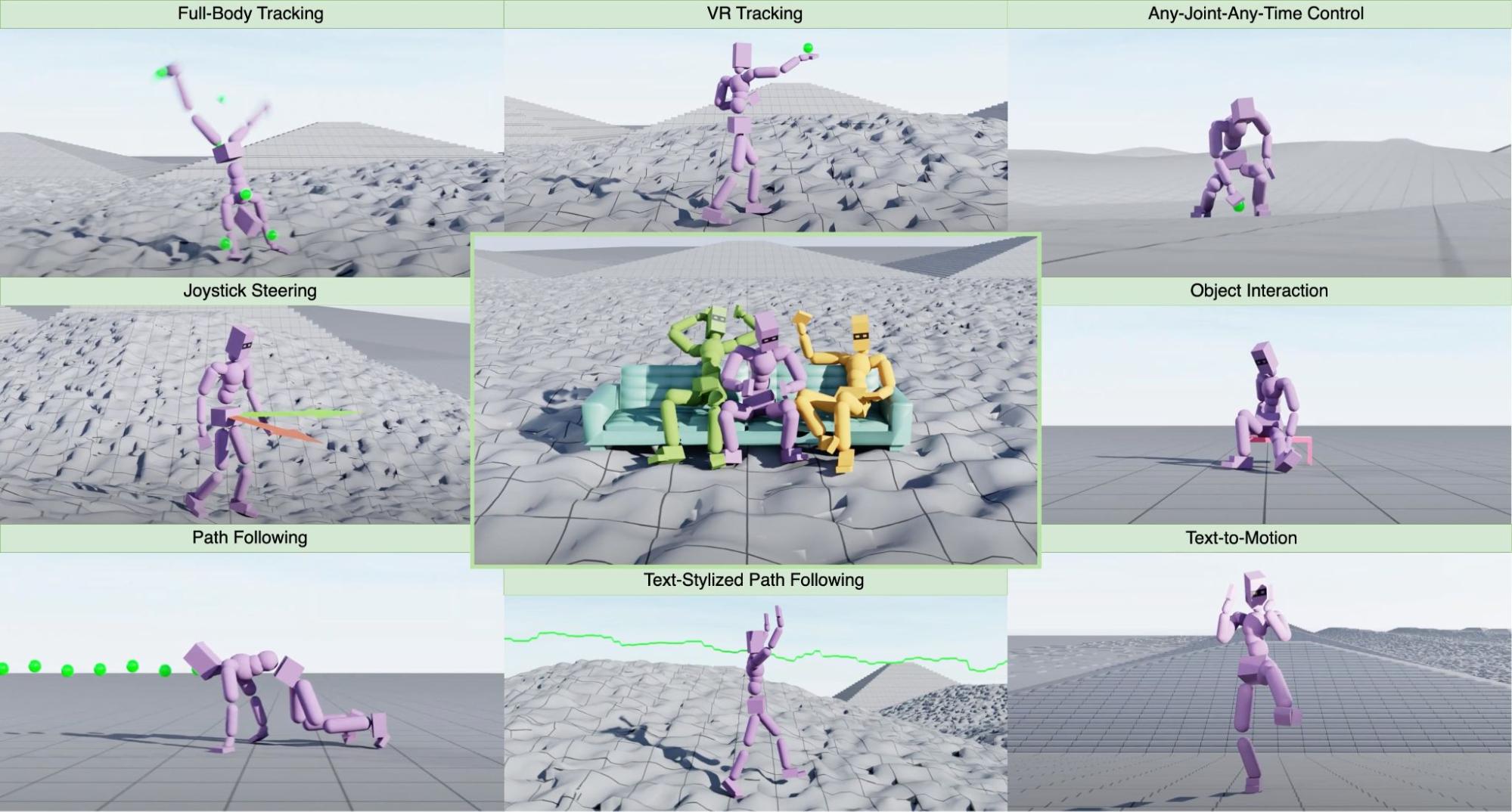
MaskedMimic accepts various types of partial motion descriptions:
- Masked keyframes: Position data for select body parts at specific timeframes (VR teleoperation data with head/hand positions, for example).
- Scene interaction: Natural object interaction specifications (“sit on this chair,” for example).
- Text descriptions: Natural language motion descriptions (“wave with right hand,” for example).
- Hybrid inputs: Combinations of the above (path following with stylistic text constraints, for example).
How MaskedMimic works
Training MaskedMimic is achieved in a two-stage pipeline that leverages a large dataset of human motions, their textual descriptions, and scene information.
This data demonstrates how humans move, but it lacks the motor actuations required by the simulated robot to reproduce these motions.
The first stage in the pipeline involves training a reinforcement learning agent on the task of full-body motion tracking. This model observes the robot’s proprioception, surrounding terrain, and what motion it should perform in the near future. It then predicts the motor actuations required to reconstruct the demonstrated motion. This can be seen as an inverse model that adapts to the terrain around it.
The second stage of training is an online teacher-student distillation process. The model from the first stage is used as the expert and is no longer trained.
During training, the humanoid is initialized to a random frame from a random motion. While the expert observes the untouched future demonstration, the student is provided a randomly masked version of it.
A mask may be very dense, providing the student model with all the information—every joint in every frame, the text, and also scene information. It could also be very sparse—for example, only the text, or the position of the head in a few seconds.
The objective of the student (MaskedMimic) is motion inpainting. Provided a partial (masked) motion description, MaskedMimic is tasked with successfully predicting the expert’s actions, which in turn will reproduce the original unmasked motion demonstration.
Motion reconstruction
Viewing control and motion generation as an inpainting problem opens a wide range of capabilities. For example, MaskedMimic can reconstruct a user’s demonstration within a simulated virtual world.
When inferred from a camera, the motion may include all of the body key-points.
On the other hand, virtual reality systems often include only a subset of tracking sensors. Common systems such as the Oculus and Apple Vision Pro provide both head and hand coordinates.
The success rate and tracking error are also measured for VR tracking. Empirical results show large performance improvements when compared to specialized controllers that were optimized specifically for this task. Without any task-specific training or fine-tuning, the unified MaskedMimic controller outperforms prior specialized methods.
| Method | Success rate | Average tracking error (mm) |
| MaskedMimic | 98.1% | 58.1 |
| PULSE | 93.4% | 88.6 |
| ASE | 37.6% | 120.5 |
| CALM | 10.1% | 122.4 |
Interactive control
This same control scheme can be reused to generate novel motions from user inputs. A single unified MaskedMimic policy is able to solve a wide range of tasks, a problem that prior works tackled by training multiple distinct specialized controllers.
By specifying the future position and orientation of the root, MaskedMimic is steered with a joystick controller.
Similarly, conditioning on both the head location and height, MaskedMimic is instructed to follow a path.
Another important capability is scene interaction. Conditioning MaskedMimic on an object is like instructing it to “naturally interact with that object.”
Benefits of the MaskedMimic unified system
MaskedMimic offers two significant advantages:
- Superior performance: MaskedMimic outperforms task-specific controllers across a range of control inputs.
- Zero-shot generalization: MaskedMimic shows an ability to combine knowledge gained through separate training regimes. This is similar to how generative text and image models learn to combine knowledge. For example, it learns to interact with unseen objects placed on irregular surfaces, although it was only trained on object interaction in a flat and undisturbed environment.
Summary and future work
MaskedMimic represents a significant advance in versatile humanoid control, unifying different control modalities through motion inpainting while maintaining physical realism. This research can be extended in several exciting directions, as detailed below.
- Robotics applications: It is natural to extend this work to real robotics. Training on a simulated robot, such as the Unitree H1, enables more intuitive control in real robotic systems.
- Enhanced interaction capabilities: This work showcases nontrivial terrains and static scenes. A next major milestone could be more complex and dynamic environments, such as object manipulation and parkour.
- Technical improvements: Finally, this work has focused on animation. Optimizing inference speed may enable deployment in real-time games and robotic systems. Moreover, improving the ability to recover from failure will enable deployment in more diverse and unpredictable environments.
For more information, including source code and pretrained models, check out MaskedMimic: Unified Physics-Based Character Control Through Masked Motion Inpainting.
Get started
NVIDIA Project GR00T is an active research initiative to accelerate humanoid robot development. If you’re a humanoid robot maker, or a robot software or hardware vendor, request to join the NVIDIA Humanoid Robot Developer Program.
Get started with Isaac Lab, or migrate from Isaac Gym to Isaac Lab with new developer onboarding guides and tutorials. Check out the Isaac Lab reference architecture to understand the end-to-end robot learning process with Isaac Lab and Isaac Sim.
Learn more about how leading robotics companies are using NVIDIA platforms, including 1X, Agility Robotics, The AI Institute, Berkeley Humanoid, Boston Dynamics, Field AI, Fourier, Galbot, Mentee Robotics, Skild AI, Swiss-Mile, Unitree Robotics, and XPENG Robotics.
