
Large language models (LLMs) have seen dramatic growth over the last year, and the challenge of delivering great user experiences depends on both high-compute throughput as well as large amounts of high-bandwidth memory. NVIDIA TensorRT-LLM provides optimizations for both peak throughput and memory optimization, delivering massive improvements in LLM inference performance.
The latest TensorRT-LLM enhancements on NVIDIA H200 GPUs deliver a 6.7x speedup on the Llama 2 70B LLM, and enable huge models, like Falcon-180B, to run on a single GPU. Llama 2 70B acceleration stems from optimizing a technique called Grouped Query Attention (GQA)—an extension of multi-head attention techniques—which is the key layer in Llama 2 70B.
Falcon-180B is one of the largest and most accurate open-source large language models available, and previously required a minimum of eight NVIDIA A100 Tensor Core GPUs to run it.
TensorRT-LLM advancements in a custom INT4 AWQ make it possible to run entirely on a single H200 Tensor Core GPU, featuring 141 GB of the latest HBM3e memory with nearly 5 TB/s of memory bandwidth.
In this post, we share the latest TensorRT-LLM innovations and the performance they’re bringing to two popular LLMs, Llama 2 70B and Falcon-180B.
Llama 2 70B on H200 delivers a 6.7x performance boost
The latest version of TensorRT-LLM features improved group query attention (GQA) kernels in the generation phase, providing up to a 6.7x performance boost with H200 compared to the same network running on an NVIDIA A100 GPU.
Used in Llama 2 70B, GQA is a variant of multi-head attention (MHA) that groups key-value (KV) heads together, resulting in fewer KV heads than query (Q) heads. TensorRT-LLM has a custom implementation of MHA that supports GQA, multi-query attention (MQA), and standard MHA.
It leverages NVIDIA Tensor Cores, in the generation and context phases, and delivers great performance on NVIDIA GPUs.
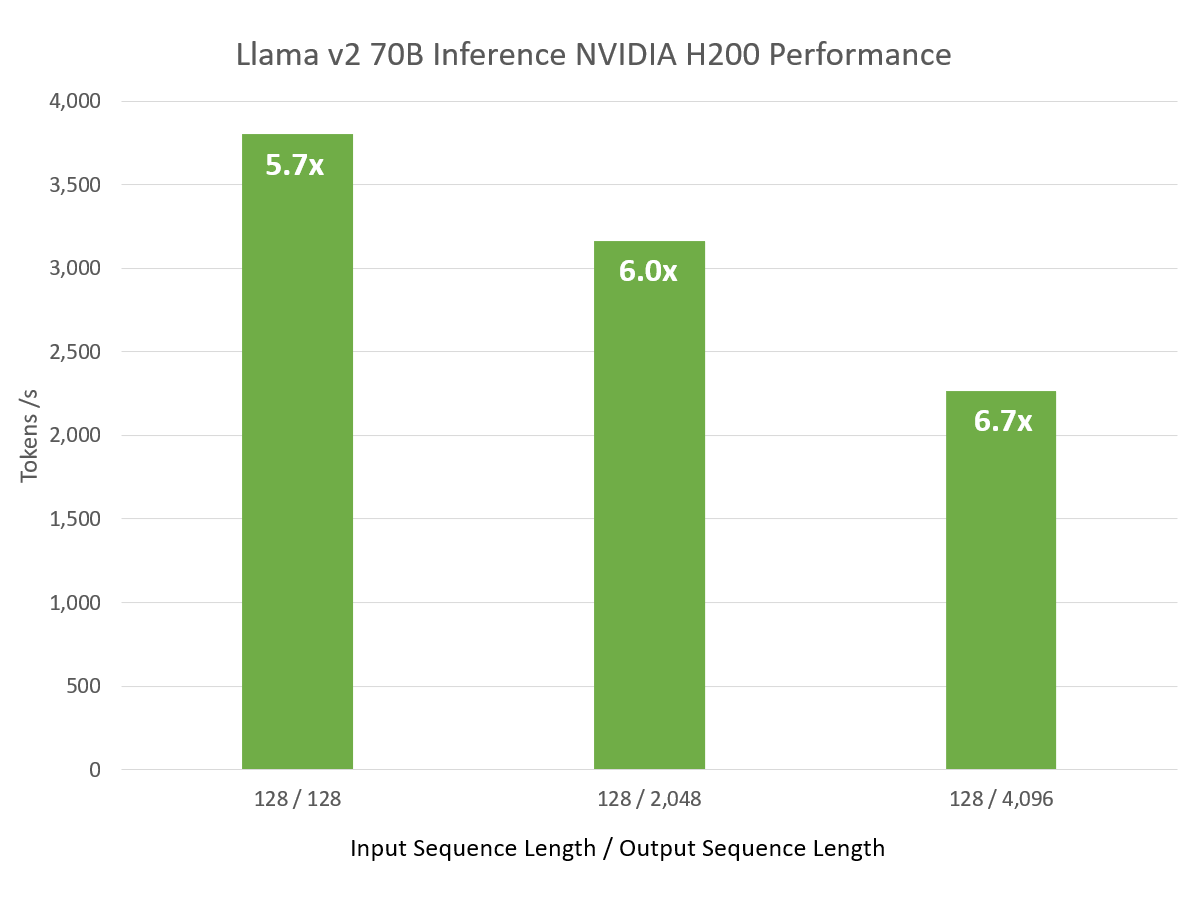
| H200 Llama 2 70B Inference Performance | ||
| Input Sequence Length | Output Sequence Length | Throughput (Tokens/s per GPU) |
| 128 | 128 | 3,803 |
| 128 | 2048 | 3,163 |
| 128 | 4096 | 2,263 |
When evaluating LLM performance, it’s important to consider different input and output sequence lengths, which vary depending on the specific application where the LLM is being deployed. As we increase the output sequence length, raw throughput decreases as expected, however, the performance speedup compared to A100 increases significantly.
Improvements in TensorRT-LLM software alone are bringing a 2.4x improvement compared to the previous version running on H200.
Falcon-180B performance examined
LLMs place both significant compute and memory demands on data center systems, and with the ongoing growth of these models, this problem will persist for some time to come. There are many techniques that developers are evolving to help address this challenge.
One of these is INT4 Activation-aware Weight Quantization (AWQ) (Lin et al., 2023). This quantization technique compresses the weights of an LLM down to just four bits based on their relative importance and then performs the computation in FP16.
This approach enables AWQ to maintain higher accuracy than other 4-bit methods while also reducing memory usage. To achieve this, special kernels capable of handling the change in precision at high performance are required.
The latest release of TensorRT-LLM implements custom kernels for AWQ. It takes the technique a step further, performing the computations in FP8 precision on NVIDIA Hopper GPUs instead of FP16, using the latest Hopper Tensor Core technology.
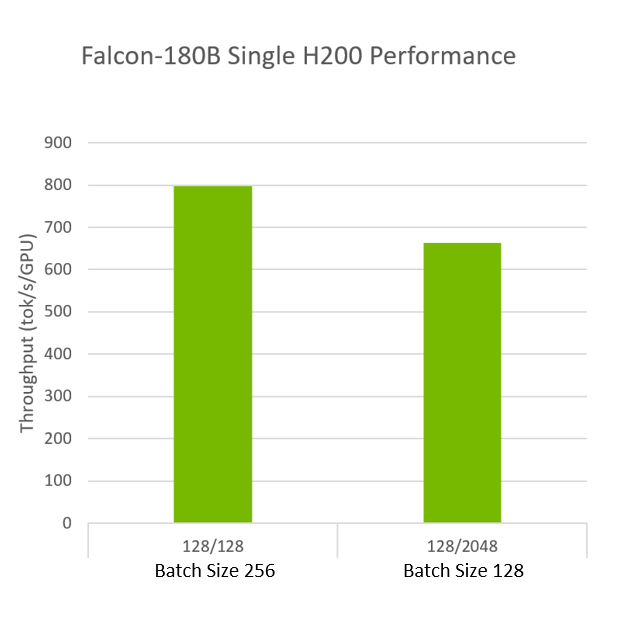
These are the results seen running INT4 AWQ with FP8 on a single H200. In addition to being able to fit the entire Falcon-180B model, H200 also runs the model with excellent inference throughput of up to 800 tokens/second.
Stay on target
Quantization can often hurt model accuracy. However, TensorRT-LLM AWQ achieves a nearly 4x reduction in memory footprint and excellent inference throughput all while maintaining exceptional accuracy.
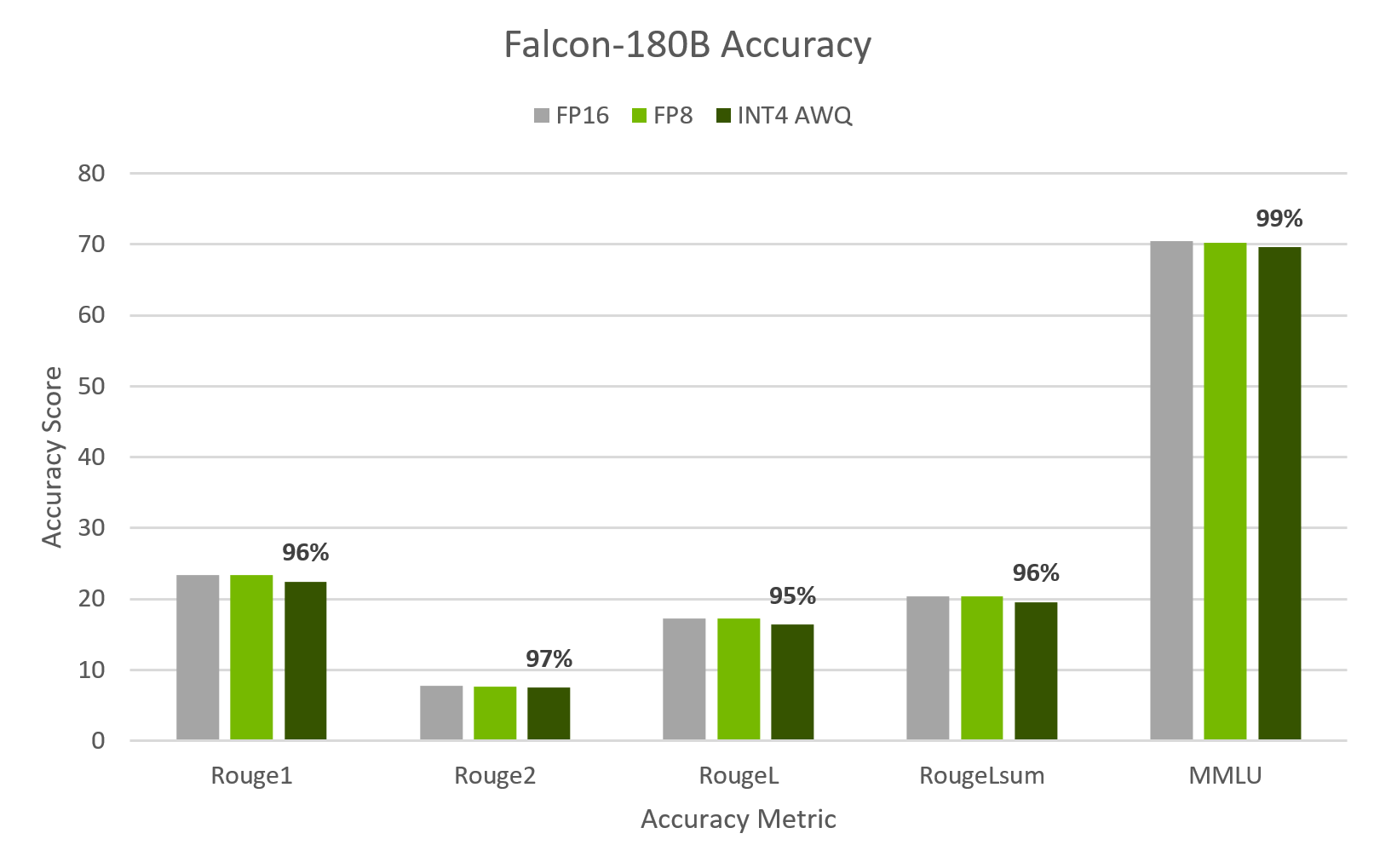
TensorRT-LLM v0.7a | Falcon-180B | 1xH200 TP1 | INT4 AWQ
Accuracy stays at or above 95% compared to running at higher precision, while delivering higher performance, and making the best use of GPU compute resources by fitting the entire model onto a single GPU. Making efficient use of the GPUs on deployed applications makes optimal use of compute resources, and helps reduce operational costs as well.
Ongoing work
These improvements will be available soon in TensorRT-LLM, and will be included in the v0.7 and v0.8 releases. Similar examples running Llama 2 70B in TensorRT-LLM are available on the TensorRT-LLM GitHub page.
For more information, visit the NVIDIA H200 Tensor Core GPU product page.
This blog post has been adapted from a technical post on the TensorRT-LLM GitHub: Falcon-180B on a single H200 GPU with INT4 AWQ, and 6.7x faster Llama-70B over A100
