
Most objects in home and industrial settings consist of multiple parts that must be assembled. While human workers typically perform assembly, in certain industries, such as automotive, robotic assembly is prevalent.
Most of these robots are designed to perform highly repetitive tasks, dealing with specific parts in a carefully engineered setup. In high-mix, low-volume manufacturing (that is, the process of producing a wide variety of products in small quantities), robots must also adapt to diverse parts, poses, and environments. Achieving such adaptivity while maintaining high precision and accuracy is a major open challenge in robotics.
Simulation of robotic assembly tasks (such as insertion) is now possible, thanks to recent developments from NVIDIA on faster-than-realtime simulation of contact-rich interactions, as detailed in Advancing Robotic Assembly with a Novel Simulation Approach Using NVIDIA Isaac. This enables the use of data-hungry learning algorithms to train simulated robot agents.
The follow-up work on sim-to-real transfer for robotic assembly proposes algorithms that can solve a small number of assembly tasks in simulation using reinforcement learning (RL), as well as methods to successfully deploy the learned skills in the real world. For details, see Transferring Industrial Robot Assembly Tasks from Simulation to Reality.
This post introduces AutoMate, a novel framework to train specialist and generalist policies for assembling geometrically diverse parts with a robotic arm. It demonstrates zero-shot sim-to-real transfer of the trained policies, meaning the assembly skills learned in simulation can be directly applied in real-world settings without additional tuning.
What is AutoMate?
AutoMate is the first simulation-based framework for learning specialist (part-specific) and generalist (unified) assembly skills over a wide range of assemblies, as well as the first system demonstrating zero-shot sim-to-real transfer over such a range. This work is a close collaboration between the University of Southern California and the NVIDIA Seattle Robotics Lab.
Specifically, AutoMate’s primary contributions are:
- A dataset of 100 assemblies and ready-to-use simulation environments.
- A novel combination of algorithms that effectively trains simulated robots to solve a wide range of assembly tasks in simulation.
- An effective synthesis of learning approaches that distills knowledge from multiple specialized assembly skills to one general assembly skill, and further improves the performance of the general assembly skill with RL.
- A real-world system that can deploy the simulation-trained assembly skills in a perception-initialized workflow.


Dataset and simulation environments
AutoMate provides a dataset of 100 assemblies that are compatible with simulation and 3D-printable in the real world, as well as parallelized simulation environments for all 100 assemblies. The 100 assemblies are based on a large assembly dataset from Autodesk. In this work, the term plug refers to the part that must be inserted (Figure 3, illustrated in white), and socket refers to the part that mates with the plugs (Figure 3, illustrated in green).


Learning specialists over diverse geometries
Although the previous NVIDIA work IndustReal has shown that an RL-only approach can solve contact-rich assembly tasks, it only solves a small variety of assemblies. The RL-only approach is unable to solve most of the 100 assemblies in AutoMate dataset. However, imitation learning enables robots to acquire complex skills by observing and mimicking demonstrations. AutoMate introduces a novel combination of three distinct algorithms that combine RL with imitation learning, enabling effective skill acquisition for a wide range of assemblies.
To augment RL with imitation learning involves three challenges:
- Generating demonstrations for assembly
- Integrating an imitation learning objective into RL
- Selecting demonstrations to use during learning
The following sections explore how to solve each of these challenges.
Generating demonstrations with assembly-by-disassembly
The kinematics of assembly is a narrow-passage problem where a robot must manipulate parts to pass through a confined or tight space without colliding with obstacles. It’s extremely difficult to collect assembly demonstrations automatically using motion planners. To collect human demonstrations also requires highly-skilled human operators and advanced teleoperation interfaces, which can be costly.
Inspired by the concept of assembly-by-disassembly, where the process of assembling an object is approached by first understanding how to disassemble it, demonstrations for disassembly are collected and then reversed for assembly. In simulation, the robot is commanded to disassemble the plug from the socket and record 100 successful disassembly demonstrations for each assembly.

RL with an imitation objective
In RL, a reward is a signal given to an agent that indicates how well it is performing at any given step. The reward serves as feedback, guiding the agent to learn and adapt its actions to maximize the cumulative reward over time (leading to task success). Inspired by work in character animation such as DeepMimic, an imitation term is incorporated into the reward function to augment RL with an imitation objective, encouraging the robot to mimic demonstrations during the learning process. The per-timestep imitation reward is defined as the maximum reward over all demonstrations for the given assembly.
Besides the imitation term, the reward formulation also includes terms that:
- Penalize distance-to-goal
- Penalize simulation error
- Reward task difficulty
This aligns with the previous IndustReal work.
Selecting demonstrations with dynamic time warping
To determine which demonstration to imitate (that is, which demonstration provides the maximum reward at the current timestep), the first step is to compute the distance between each demonstration and the current robot end-effector path, and then imitate the path with the minimum distance. The demonstration paths might have an uneven distribution of waypoints and a different number of waypoints compared to the robot end-effector path, making it difficult to determine the correspondence between waypoints in the demonstration paths and the robot end-effector path.
Dynamic time warping (DTW) is an algorithm used to measure the similarity between two temporal sequences that may vary in speed. In this work, DTW is used to find a mapping between the robot end-effector path and each demonstration path that minimizes the sum of distances between each waypoint in the end-effector path and the matching waypoint on the demonstration path (Figure 6). Given the distance returned by DTW, the imitation reward is calculated for each demonstration path, and select the demonstration path that gives the highest imitation reward.

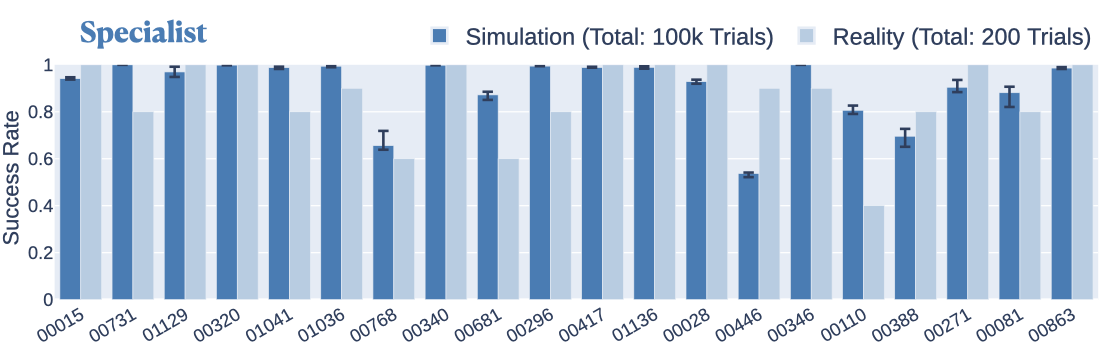
The proposed combination of assembly-by-disassembly, RL with an imitation objective, and trajectory matching using DTW shows consistent performance over a wide spectrum of assemblies. In simulation, the specialist policies achieve ≈80% success rates or higher on 80 distinct assemblies and ≈90% success rates or higher on 55 distinct assemblies. In the real world, the specialist policies achieve a mean success rate of 86.5% on 20 assemblies, which is a drop of only 4.2% compared to deployments on these assemblies in simulation (Figure 7).
Learning a general assembly skill
To train a generalist skill that can solve multiple assembly tasks, the goal is to reuse knowledge from already trained specialist skills and then use curriculum-based RL to further improve performance. The proposed method includes three stages:
- First, standard behavior cloning (BC) is applied, which involves collecting demonstrations from already-trained specialist skills and using these demonstrations to supervise the training of a generalist skill.
- Second, DAgger (dataset aggregation) is used to refine the generalist by executing the generalist skill and actively querying the specialist skills (that is, getting the actions predicted by the specialists) at the states visited by the generalist to provide supervision.
- Finally, an RL fine-tuning phase on the generalist is executed. During the fine-tuning phase, the sampling-based curriculum from the IndustReal work is applied, where the initial engagement of parts is gradually reduced as the generalist reaches a higher task-success rate.

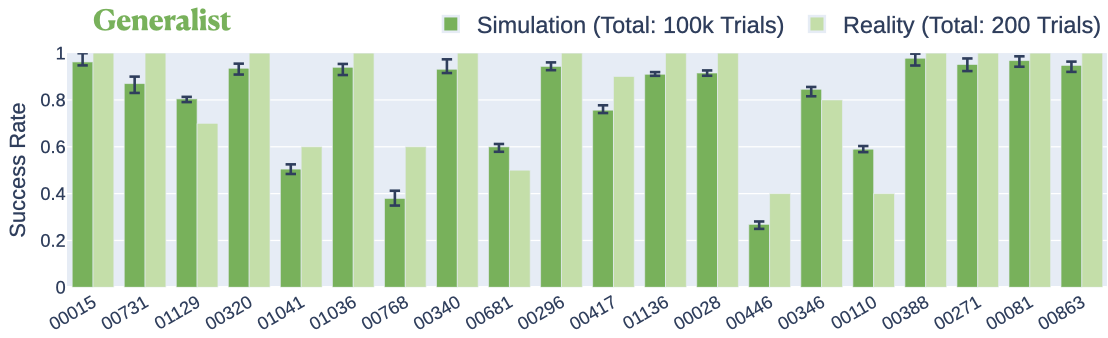
A generalist is trained using the proposed three-stage approach on 20 assemblies. In simulation, the generalist policy can jointly solve 20 assemblies with an 80.4% success rate. In the real world, the generalist policy achieves a mean success rate of 84.5% on the same set of assemblies, which is an improvement of 4.1% compared to deployments in simulation (Figure 9).
Real-world setup and perception-initialized workflow
The real-world setup includes a Franka Panda robot arm, a wrist-mounted Intel RealSense D435 camera, a 3D-printed plug and socket, and a Schunk EGK40 gripper used to hold the socket. In the perception-initialized workflow:
- The plug is placed haphazardly on a foam block and the socket is placed haphazardly within the Schunk gripper.
- An RGB-D image is captured through the wrist-mounted camera, followed by 6D pose estimation (FoundationPose) of the parts.
- The robot grasps the plug, transports it to the socket, and deploys a simulation-trained assembly skill.

The specialists and the generalists are evaluated in the perception-initialized workflow. For specialists, the mean success rate is 90.0%. For generalists, the success rate is 86.0%. These results indicate that 6-DOF pose estimation, grasp optimization, and the proposed methods for learning specialist and generalist policies can be effectively combined to achieve reliable assembly under realistic conditions using research-grade hardware.
Summary
AutoMate is the first attempt to leverage learning methods and simulation to solve a wide range of assembly problems. Through this work, researchers at NVIDIA have gradually built towards the large-model paradigm for industrial robotics, while staying grounded in real-world deployment.
Future steps focus on solving multipart assemblies that require efficient sequence planning (that is, deciding which part to assemble next) and further improving skills to meet industry-competitive performance specifications.
To get up to speed on the preceding NVIDIA work, read the papers for Factory and IndustReal. Visit the AutoMate project page to read the paper and view summary videos. Stay tuned for the upcoming integration of AutoMate into the newly released NVIDIA Isaac Lab.
Join authors Bingjie Tang, Iretiayo Akinola, Jie Xu, Bowen Wen, Ankur Handa, Karl Van Wyk, Dieter Fox, Gaurav S. Sukhatme, Fabio Ramos, and Yashraj Narang at the Robotics: Science and Systems (RSS) conference in July 2024 for their presentation of the paper, AutoMate: Specialist and Generalist Assembly Policies over Diverse Geometries.
