Exploding model sizes in deep learning and AI, complex simulations in high-performance computing (HPC), and massive datasets in data analytics all continue to demand faster and more advanced GPUs and platforms.

At SC20, we announced the NVIDIA A100 80GB GPU, the latest addition to the NVIDIA Ampere family, to help developers, researchers, and scientists tackle their toughest challenges. A100 80GB uses the new faster and higher capacity HBM2e GPU memory, which substantially increases the GPU memory size and bandwidth. Table 1 shows the key issues for how A100 80GB improves compared to the original A100 40GB.
| A100 40GB | A100 80GB | Comment | |
| GPU Memory Size | 40 GB HBM2 | 80 GB HBM2e | 2X capacity |
| GPU Memory Bandwidth | 1,555 GB/s | 2,039 GB/s | >1.3X higher bandwidth, industry’s 1st over 2 TB/s |
| GPU Peak Compute | – | Same as A100 40GB | Seamless portability |
| Multi-Instance GPU | Up to 7 GPU instances with 5 GB each | Up to 7 GPU instances with 10 GB each | More versatile GPU instances |
| Node Max GPU Memory (16 GPU Nodes) | 640 GB | 1,280 GB | For largest datasets |
| Form Factor | NVIDIA HGX 4 or 8 GPU board | NVIDIA HGX 4 or 8 GPU board | Form-factor compatible |
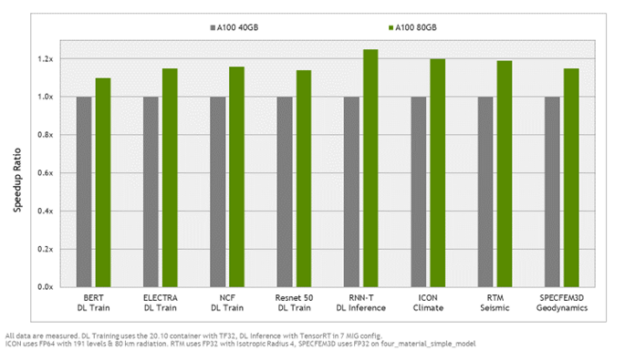
Higher GPU memory bandwidth is one of the key enablers for faster compute application performance. With over 30% higher memory bandwidth, many compute applications will see a meaningful application-level gain with A100 80GB. Figure 1 shows the top application speedups enabled by the higher memory bandwidth.
Putting the extra memory to work
Faster memory bandwidth is only the start. The extra memory can be used to train bigger AI models for better predictions, improve energy efficiency, and run jobs with much higher throughputs. Here are a few examples.
Train bigger models to produce a higher-quality result
It is well-known that bigger AI models enable higher-quality results. For example, OpenAI shows that the few-shot translation quality on language pairs improves as model capacity increases (Figure 2).
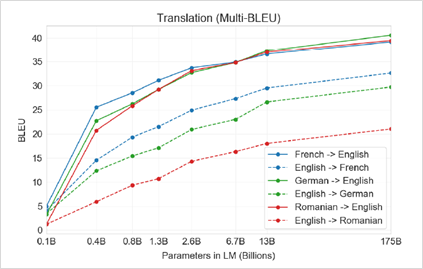
To train such a large model with billions of parameters, GPU memory size is critical. On a single NVIDIA HGX A100 40GB 8-GPU machine, you can train a ~10B-parameters model. With the new HGX A100 80GB 8-GPU machine, the capacity doubles so you can now train a ~20B-parameter model, which enables close to 10% improvement on translation quality (BLEU). Advanced users can train even larger models with model parallel using multiple machines.
Improved energy efficiency
Larger GPU memory enables solving memory size–intensive compute problems with fewer server nodes. In addition to the reduction in compute hardware, the associated networking and storage infrastructure overhead also goes down. As a result, the data center becomes more energy-efficient.
As an example, the NVIDIA DGX SuperPOD system, based on HGX A100 80GB, captured the top spot on the recent Green500 list of most efficient supercomputers, achieving a new world record in power efficiency of 26.2 gigaflops per watt. The additional GPU memory enables A100 to execute the Green500 workload much more efficiently.
Run the same jobs with fewer nodes to substantially improve data center throughput
With a larger GPU memory enabling fewer server nodes, the number of internode communications is also dramatically reduced. More communication happens within nodes using the high-speed NVLINK on the HGX platform. On a per-GPU basis, NVLINK is close to a 10X higher bandwidth than even the fastest internode networking at 400 Gb.
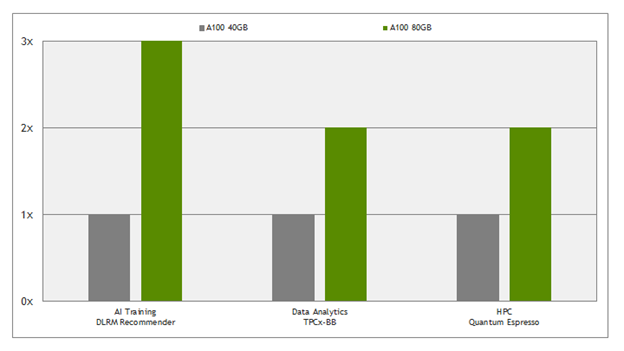
Today, many large dataset workloads are limited by internode network bandwidth. As a result, the same compute problems can be solved with less hardware and faster performance, substantially improving overall data center throughput. Table 2 shows a few examples on how using A100 80GB can save the number of nodes required to run the same jobs. Figure 3 shows the resulting data center throughput improvement for the same use cases.
| Use case | Application | # A100 40GB required to run | # A100 80GB required to run | Execution time comparison |
| Deep learning recommender training | DLRM, Criteo click log 1-TB dataset | 16 GPU | 8 GPU | 8 A100 80GB close to 1.5x faster than 16 A100 40GB |
| Data analytics | Retail benchmark, 10-TB dataset | 96 GPU | 48 GPU | Close to same execution time |
| HPC (Material Science) | Quantum Espresso (PRACE-large), 1.6TB dataset | 40 GPU | 20 GPU | Close to same execution time |
Summary
The A100 80GB GPU doubles the memory capacity and increases memory bandwidth by over 30% when compared to the original A100 40GB GPU.
For memory size–intensive compute problems—such as natural language processing that needs large model capacity, deep learning recommender systems with large embedding tables, data analytics and HPC applications that use large datasets—the benefit of the A100 80GB GPU is especially apparent. You get faster performance, better result quality, a more energy-efficient data center, and substantially increased throughput.
The HGX A100 80GB platform is another powerful tool for developers, researchers, and scientists to take advantage of. We look forward to helping to advance the most important HPC and AI applications.
