
XGBoost is a machine learning algorithm widely used for tabular data modeling. To expand the XGBoost model from single-site learning to multisite collaborative training, NVIDIA has developed Federated XGBoost, an XGBoost plugin for federation learning. It covers vertical collaboration settings to jointly train XGBoost models across decentralized data sources, as well as horizontal histogram-based and tree-based federated learning.
Under the vertical setting, each party holds part of the features for the entire population, and only one party holds the label. The label-owner is referred to as the active party, while all other parties are passive parties. Under the horizontal setting, each party holds all features and label information, but only for part of the whole population.
Further, NVIDIA FLARE, a domain-agnostic, open-source, and extensible SDK for federated learning, has enhanced the real-world federated learning experience by introducing capabilities to handle communication challenges. This includes multiple concurrent training jobs, and potential job disruptions due to network conditions.
Currently, Federated XGBoost is built with the assumption of full mutual trust, indicating that no party has the intention to learn more information beyond model training. In practice, though, honest-but-curious is a more realistic setting for federated collaborations. For instance, in vertical federated XGBoost, passive parties may be interested in recovering the label information from the gradients sent by the active party. In horizontal federated learning, the server or other clients can access each client’s gradient histograms and learn their data characteristics.
NVIDIA Flare 2.5.2 and XGBoost federated-secure expand the scope of Federated XGBoost by securing these potential information concerns. Specifically:
- The secure federated algorithms, both horizontal and vertical, are implemented and added to the federated schemes supported by XGBoost library, addressing data security patterns under different assumptions.
- Homomorphic encryption (HE) features are added to the secure federated XGBoost pipelines using a plugin and processor interface system designed to robustly and effectively bridge the computation by XGBoost, and communication by NVIDIA Flare with proper encryption and decryption in between.
- HE plugins are developed, both CPU-based and CUDA-accelerated, providing versatile adaptation depending on hardware and efficiency requirements. The CUDA plugin is shown to be much faster than current third-party solutions.
With the help of HE, key federated computation steps are performed over ciphertexts, and the relevant assets (gradients and partial histograms) are encrypted and will not be learned by other parties during computation. This gives users assurance of their data security, which is one of the fundamental benefits of federated learning.
As explained in this post, CUDA-accelerated Homomorphic Encryption with Federated XGBoost adds security protection for data privacy and delivers up to 30x speedups for vertical XGBoost compared to third-party solutions.
Collaboration modes and secure patterns
For vertical XGBoost, the active party holds the label, which can be considered “the most valuable asset” for the whole process, and should not be accessed by passive parties. Therefore, the active party in this case is the “major contributor” from a model training perspective, with a concern of leaking this information to passive clients. In this case, the security protection is mainly against passive clients over the label information.
To protect label information for vertical collaboration, at every round of XGBoost after the active party computes the gradients for each sample, the gradients will be encrypted before sending to passive parties (Figure 1). Upon receiving the encrypted gradients (ciphertext), they will be accumulated according to the specific feature distribution at each passive party. The resulting cumulative histograms will be returned to the active party, decrypted, and further used for tree building by the active party.
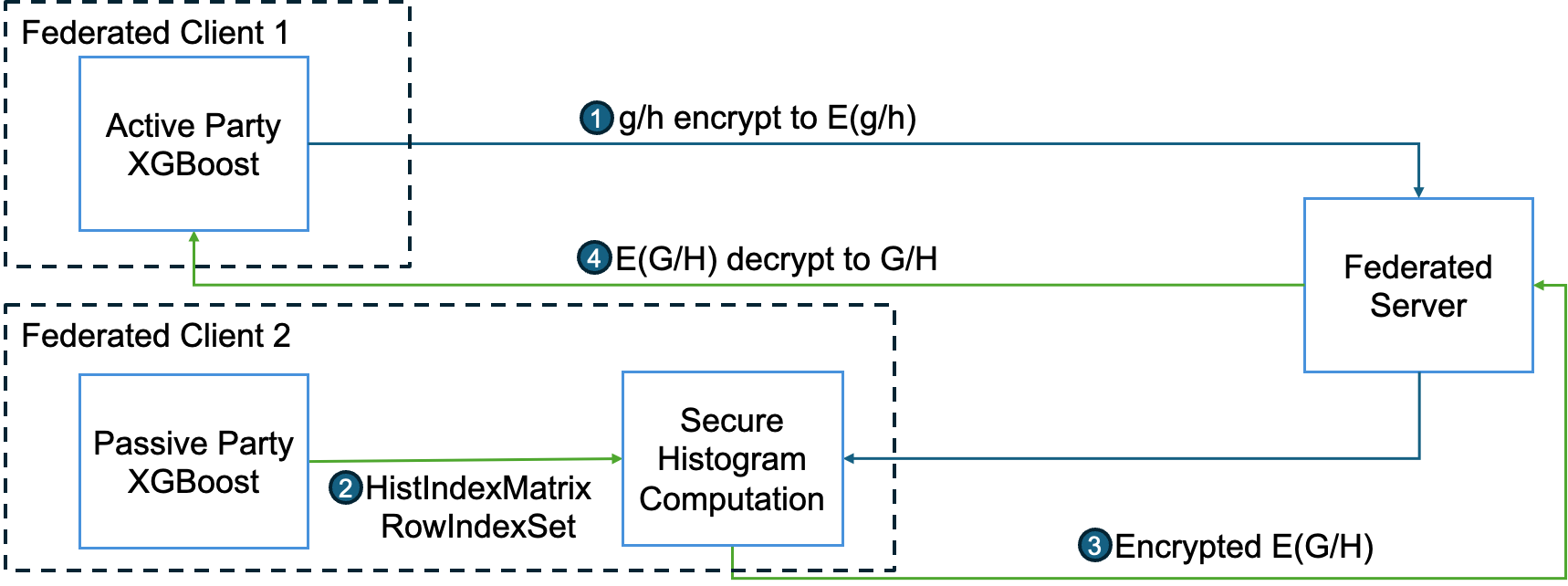
For horizontal XGBoost, each party holds “equal status” (whole feature and label for partial population), while the federated server performs aggregation, without owning any data. Hence in this case, clients have a concern of leaking information to the server, and to each other. Hence, the information to be protected is each clients’ local histograms.

To protect the local histograms for horizontal collaboration, the histograms will be encrypted before sending to the federated server for aggregation. The aggregation will then be performed over ciphertexts and the encrypted global histograms will be returned to clients, where they will be decrypted and used for tree building. In this way, the server will have no access to the plaintext histograms, while each client will only learn the global histogram after aggregation, rather than individual local histograms.
Encryption with proper HE schemes
With multiple libraries covering various HE schemes both with and without GPU support, it is important to properly choose the most efficient scheme for the specific needs of a particular federated XGBoost setting. Let’s look at one example, assume N=5 number of participants, M=200K total number of data samples, J=30 total number of features, and each feature histogram has K=256 slots. Depending on the type of federated learning applications: (Vertical or Horizontal application, we will need different algorithms.
For vertical application, the encryption target is the individual g/h numbers, and the computation is to add the encrypted numbers according to which histogram slots they fall into. As the number of g/h is the same as the sample number, for each boosting round in theory:
- The total encryption needed will be M * 2 = 400k (g and h), and each time encrypts a single number
- The total encrypted addition needed will be (M – K) * 2 * J ≈ 12m
In this case, an optimal scheme choice would be Paillier because the encryption needs to be performed over a single number. Using schemes targeting vectors like CKKS would be a significant waste of space.
For horizontal application, on the other hand, the encryption target is the local histograms G/H, and the computation is to add local histograms together to form the global histogram. For each boosting round:
- The total encryption needed will be N * 2 = 10 (G and H), and each time encrypts a vector of length J * K = 7680
- The total encrypted addition needed will be (N – 1) * 2 = 18
In this case, an optimal scheme choice would be CKKS because it is able to handle a histogram vector (with length 7680, for example) in one shot.
We provide encryption solutions both with CPU-only, and with efficient GPU acceleration.
Example results
With implementation of the pipeline previously described on both XGBoost and NVIDIA Flare, we tested our secure federated pipelines with a credit card fraud detection dataset. The results are as follows:
The AUC of vertical learning (both secure and non-secure):
[0] eval-auc:0.90515 train-auc:0.92747
[1] eval-auc:0.90516 train-auc:0.92748
[2] eval-auc:0.90518 train-auc:0.92749
The AUC of horizontal learning (both secure and non-secure):
[0] eval-auc:0.89789 train-auc:0.92732
[1] eval-auc:0.89791 train-auc:0.92733
[2] eval-auc:0.89791 train-auc:0.92733
Comparing the tree models with a centralized baseline, we reached the following observations:
Vertical federated learning (non-secure) has exactly the same tree model as the centralized baseline.
Vertical federated learning (secure) has the same tree structures as the centralized baseline. Furthermore, it produces different tree records at different parties because each party holds different feature subsets, and it should not learn the cut information for features owned by others.
Horizontal federated learning (both secure and non-secure) have different tree models from the centralized baseline. This is due to the initial feature quantile computation, over either global data (centralized) or local data (horizontal).
For more details, refer to the NVIDIA Flare Secure XGBoost example.
Efficiency of encryption methods
To benchmark our solutions, we conducted experiments using a diverse range of datasets with varying characteristics, including differences in size (from small to large) and feature dimensions (from few to many). These benchmarks aim to demonstrate the robustness of our algorithms and highlight significant performance improvements in terms of speed and efficiency.
Dataset and data splits
We used three datasets, covering different data sizes and feature sizes, to illustrate their impact on the efficiency of encryption methods. The data characteristics are summarized in Table 1. The credit card fraud detection dataset is labeled as CreditCard, the Epsilon dataset as Epsilon, and a subset of the HIGGS dataset as HIGGS.
| CreditCard | HIGGS | Epsilon | |
| Data records size | 284,807 | 6,200,000 | 400,000 |
| Feature size | 28 | 28 | 2000 |
| Training set size | 227,845 | 4,000,000 | 320,000 |
| Validation set size | 56,962 | 2,200,000 | 80,000 |
For vertical federated learning, we split the training dataset into two clients, with each client holding different features of the same data records (Table 2).
| Feature | CreditCard | HIGGS | Epsilon |
| Label client | 10 | 10 | 799 |
| Non-label client | 18 | 18 | 1201 |
For horizontal federated learning, we split the training set into three clients evenly (Table 3).
| Data records | CreditCard | HIGGS | Epsilon |
| Client 1 | 75,948 | 1,333,333 | 106,666 |
| Client 2 | 75,948 | 1,333,333 | 106,666 |
| Client 3 | 75,949 | 1,333,334 | 106,668 |
Experiment results
End-to-end XGBoost training was performed with the following parameters: num_trees = 10, max_depth = 5, max_bin = 256. Testing was performed using the NVIDIA Tesla V100 GPU and the Intel E5-2698 v4 CPU. Figures 3 and 4 show the time comparisons. Note that the simulation was run on the same machine, so federated communication cost is negligible.
Secure vertical Federated XGBoost
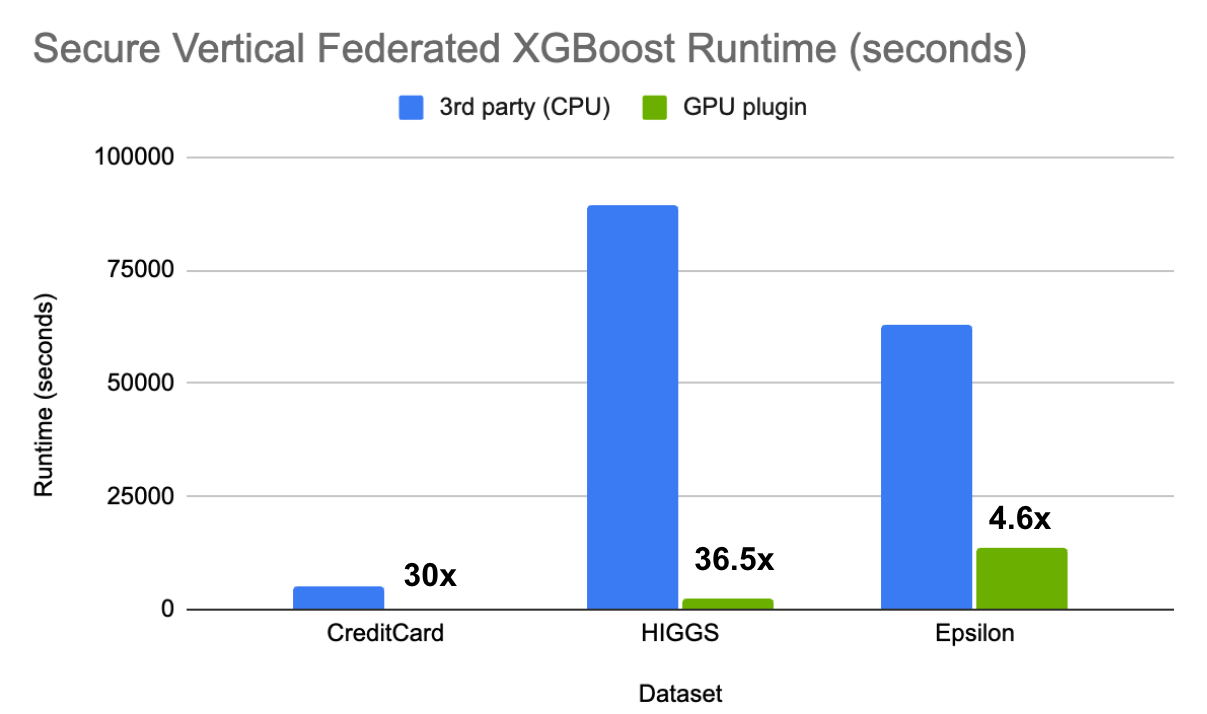
We compare the time cost of the NVIDIA Flare pipeline CUDA-accelerated Paillier plugin (noted as GPU plugin) with the existing third-party open-source solution for secure vertical federated XGBoost. Both are HE-encrypted. Figure 3 shows that our solution is 4.6x to 36x faster depending on the combination of data and feature sizes. Note that the third-party solution only supports CPU.
Secure horizontal Federated XGBoost
For secure horizontal Federated XGBoost, third-party offerings do not have a secure solution with HE. Therefore, we compare the time cost of the NVIDIA Flare pipeline without encryption and with the encryption plugin of CKKS using CPU (noted as the CPU plugin) to get an idea of the overhead of the encryption for data protection.
As shown in Figure 4, in this case the computation is notably faster than in the vertical scenario (orders of magnitude lower), and thus GPU acceleration may not be required with such reasonable overhead. Only for datasets with very wide histograms (Epsilon, for example), the encryption overhead will be more significant (but still only ~5% of the vertical setting).

Summary
In this post, we demonstrated how GPU-accelerated Homomorphic Encryption enhances the security of Federated XGBoost, enabling privacy-preserving horizontal and vertical federated learning through NVIDIA FLARE. As compared with existing works of federated XGBoost, the new functionality provides 1) a secure federated XGBoost pipeline ensuring data safety from the algorithm level, and 2) an efficient CUDA-accelerated solution that is much faster than current alternatives on the market enabled by GPU computation. This will encourage adaptations in the fields that have high requirements over both data security and learning efficiency where XGBoost is commonly used, such as fraud detection model training in the financial industry.
For more information and an end-to-end example, visit NVIDIA/NVFlare on GitHub. Reach out to us at federatedlearning@nvidia.com with questions or comments.
