
CUDA Toolkit 12.4 introduced a new nvFatbin library for creating fatbins at runtime. Fatbins, otherwise known as NVIDIA device code fat binaries, are containers that store multiple versions of code to store different architectures. In particular, NVIDIA uses them to bundle code for different GPU architectures, such as sm_61 and sm_90.
Until now, to generate a fatbin, you had to rely on the command line tool fatbinary, which was ill-suited for dynamic code generation. This made dynamically generating fatbins difficult, as you’d put the generated code into a file, call fatbinary with exec or similar, and then handle the outputs. This significantly increased the difficulty of generating fatbins dynamically and led to several attempts to imitate fatbins through various containers.
CUDA Toolkit 12.4 greatly eases this task by introducing nvFatbin, a new library that enables the programmatic creation of a fatbin. No more writing to files, no more calling exec, no more parsing command line outputs and grabbing output files from directories.
New library offers runtime fatbin creation support
Using the nvFatbin library is similar to that of any of the other familiar libraries, such as NVRTC, nvPTXCompiler, and nvJitLink. There are static and dynamic versions of the nvFatbin library for all platforms that ship with nvrtc.
With proper considerations, fatbins created through the nvFatbin library comply with CUDA compatibility guarantees. This post primarily covers runtime fatbin creation as available through the nvFatbin library, highlighting differences with the existing command line fatbinary as and when appropriate. We dive into the details of the feature with code examples, compatibility guarantees, and benefits. As an added bonus, we include a sneak peek of how and why NVIDIA TensorRT plans to take advantage of the feature.
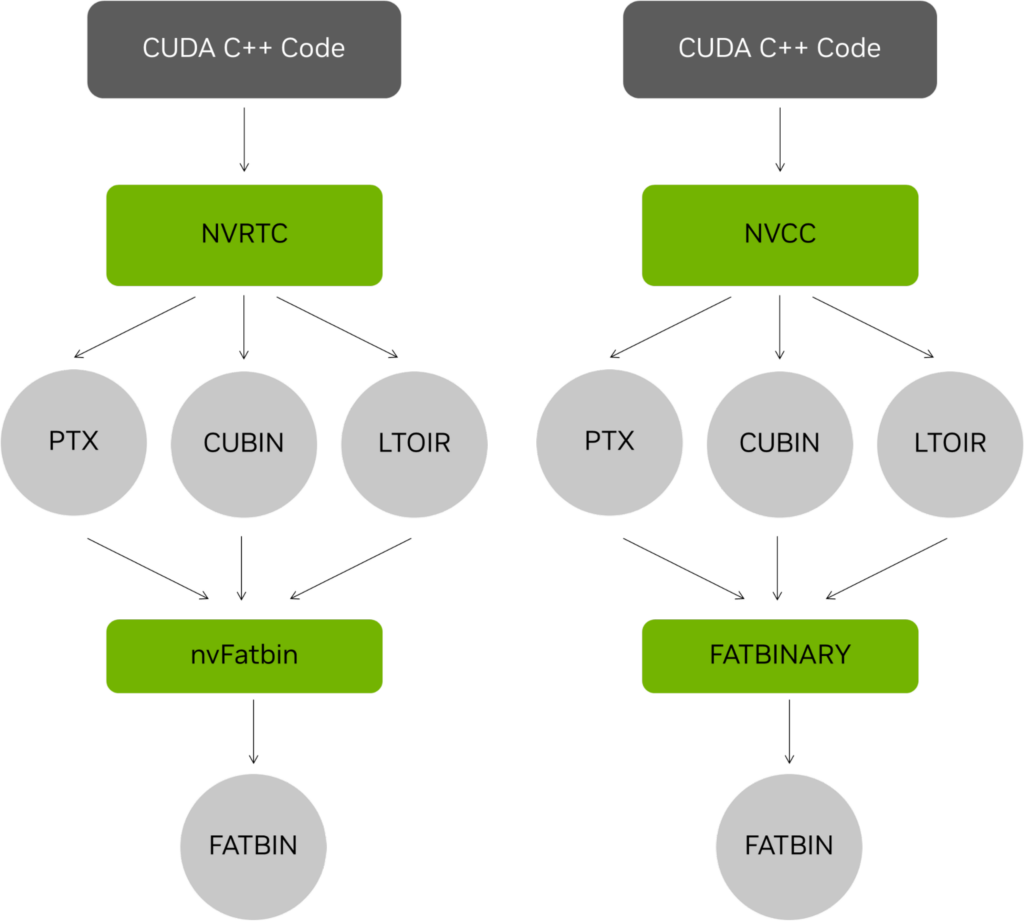
How to get runtime fatbin creation working
Create the handle to be referenced later to insert relevant pieces of device code into the fatbinary.
nvFatbinCreate(&handle, numOptions, options);
Add the device code to be put in the fatbin, using a function dependent on the kind of input.
nvFatbinAddCubin(handle, data, size, arch, name);
nvFatbinAddPTX(handle, data, size, arch, name, ptxOptions);
nvFatbinAddLTOIR(handle, data, size, arch, name, ltoirOptions);
For PTX and LTO-IR (a form of intermediate representation used for JIT LTO), specify additional options here for use during JIT compilation.
Retrieve the resultant fatbin. To do that, explicitly allocate a buffer. When doing so, be sure to query the size of the resulting fatbin to ensure that you allocate sufficient space.
nvFatbinSize(linker, &fatbinSize);
void* fatbin = malloc(fatbinSize);
nvFatbinGet(handle, fatbin);
Clean up the handle.
nvFatbinDestroy(&handle);
Generate fatbins offline with NVCC
To generate a fatbin offline with NVCC, add the option -fatbin. For example, the following command, given the file loader.cu, produces a fatbin containing one entry, for sm_90, that contains an LTO-IR version of the code, loader.fatbin:
nvcc -arch lto_90 -fatbin loader.cu
If you specify -arch=sm_90, nvcc creates a fatbin that contains both PTX and CUBIN (SASS). The object contains both specific SASS instructions for sm_90 and PTX, which can later be JIT to any architecture >= 90:
nvcc -arch sm_90 -fatbin loader.cu
To create a fatbin with multiple entries, specify multiple architectures with -gencode:
nvcc -gencode arch=compute_80,code=sm_80 -gencode arch=compute_90,code=sm_90 -gencode arch=compute_52,code=compute_52
This creates a fatbin that contains sm_80 ELF, sm_90 ELF, and compute_52 PTX. You can use cuobjdump to see the contents of the fatbin.
Generate fatbins at runtime
In addition to the offline compile and runtime fatbin creation model described earlier (Figure 1), fatbins can also be entirely constructed at runtime by using NVRTC to generate the object code. They are added to the fatbin at runtime using the nvFatbin API. The following code example has relevant modifications for using nvFatbin APIs.
#include <nvrtc.h>
#include <cuda.h>
#include <nvFatbin.h>
#include <nvrtc.h>
#include <iostream>
#define NUM_THREADS 128
#define NUM_BLOCKS 32
#define NVRTC_SAFE_CALL(x) \
do { \
nvrtcResult result = x; \
if (result != NVRTC_SUCCESS) { \
std::cerr << "\nerror: " #x " failed with error " \
<< nvrtcGetErrorString(result) << '\n'; \
exit(1); \
} \
} while(0)
#define CUDA_SAFE_CALL(x) \
do { \
CUresult result = x; \
if (result != CUDA_SUCCESS) { \
const char *msg; \
cuGetErrorName(result, &msg); \
std::cerr << "\nerror: " #x " failed with error " \
<< msg << '\n'; \
exit(1); \
} \
} while(0)
#define NVFATBIN_SAFE_CALL(x) \
do \
{ \
nvFatbinResult result = x; \
if (result != NVFATBIN_SUCCESS) \
{ \
std::cerr << "\nerror: " #x " failed with error " \
<< nvFatbinGetErrorString(result) << '\n';\
exit(1); \
} \
} while (0)
const char *fatbin_saxpy = " \n\
__device__ float compute(float a, float x, float y) { \n\
return a * x + y; \n\
} \n\
\n\
extern \"C\" __global__ \n\
void saxpy(float a, float *x, float *y, float *out, size_t n) \n\
{ \n\
size_t tid = blockIdx.x * blockDim.x + threadIdx.x; \n\
if (tid < n) { \n\
out[tid] = compute(a, x[tid], y[tid]); \n\
} \n\
} \n";
size_t process(const void* input, const char* input_name, void** output, const char* arch)
{
// Create an instance of nvrtcProgram with the code string.
nvrtcProgram prog;
NVRTC_SAFE_CALL(
nvrtcCreateProgram(&prog, // prog
(const char*) input, // buffer
input_name, // name
0, // numHeaders
NULL, // headers
NULL)); // includeNames
// specify that LTO IR should be generated for LTO operation
const char *opts[1];
opts[0] = arch;
nvrtcResult compileResult = nvrtcCompileProgram(prog, // prog
1, // numOptions
opts); // options
// Obtain compilation log from the program.
size_t logSize;
NVRTC_SAFE_CALL(nvrtcGetProgramLogSize(prog, &logSize));
char *log = new char[logSize];
NVRTC_SAFE_CALL(nvrtcGetProgramLog(prog, log));
std::cout << log << '\n';
delete[] log;
if (compileResult != NVRTC_SUCCESS) {
exit(1);
}
// Obtain generated CUBIN from the program.
size_t CUBINSize;
NVRTC_SAFE_CALL(nvrtcGetCUBINSize(prog, &CUBINSize));
char *CUBIN = new char[CUBINSize];
NVRTC_SAFE_CALL(nvrtcGetCUBIN(prog, CUBIN));
// Destroy the program.
NVRTC_SAFE_CALL(nvrtcDestroyProgram(&prog));
*output = (void*) CUBIN;
return CUBINSize;
}
int main(int argc, char *argv[])
{
void* known = NULL;
size_t known_size = process(fatbin_saxpy, "fatbin_saxpy.cu", &known, "-arch=sm_52");
CUdevice cuDevice;
CUcontext context;
CUmodule module;
CUfunction kernel;
CUDA_SAFE_CALL(cuInit(0));
CUDA_SAFE_CALL(cuDeviceGet(&cuDevice, 0));
CUDA_SAFE_CALL(cuCtxCreate(&context, 0, cuDevice));
// Dynamically determine the arch to make one of the entries of the fatbin with
int major = 0;
int minor = 0;
CUDA_SAFE_CALL(cuDeviceGetAttribute(&major,
CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MAJOR, cuDevice));
CUDA_SAFE_CALL(cuDeviceGetAttribute(&minor,
CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MINOR, cuDevice));
int arch = major*10 + minor;
char smbuf[16];
sprintf(smbuf, "-arch=sm_%d", arch);
void* dynamic = NULL;
size_t dynamic_size = process(fatbin_saxpy, "fatbin_saxpy.cu", &dynamic, smbuf);
sprintf(smbuf, "%d", arch);
// Load the dynamic CUBIN and the statically known arch CUBIN
// and put them in a fatbin together.
nvFatbinHandle handle;
const char* fatbin_options[] = {"-cuda"};
NVFATBIN_SAFE_CALL(nvFatbinCreate(&handle, fatbin_options, 1));
NVFATBIN_SAFE_CALL(nvFatbinAddCubin(handle,
(void *)dynamic, dynamic_size, smbuf, "dynamic"));
NVFATBIN_SAFE_CALL(nvFatbinAddCubin(handle,
(void *)known, known_size, "52", "known"));
size_t fatbinSize;
NVFATBIN_SAFE_CALL(nvFatbinSize(handle, &fatbinSize));
void *fatbin = malloc(fatbinSize);
NVFATBIN_SAFE_CALL(nvFatbinGet(handle, fatbin));
NVFATBIN_SAFE_CALL(nvFatbinDestroy(&handle));
CUDA_SAFE_CALL(cuModuleLoadData(&module, fatbin));
CUDA_SAFE_CALL(cuModuleGetFunction(&kernel, module, "saxpy"));
// Generate input for execution, and create output buffers.
#define NUM_THREADS 128
#define NUM_BLOCKS 32
size_t n = NUM_THREADS * NUM_BLOCKS;
size_t bufferSize = n * sizeof(float);
float a = 5.1f;
float *hX = new float[n], *hY = new float[n], *hOut = new float[n];
for (size_t i = 0; i < n; ++i) {
hX[i] = static_cast<float>(i);
hY[i] = static_cast<float>(i * 2);
}
CUdeviceptr dX, dY, dOut;
CUDA_SAFE_CALL(cuMemAlloc(&dX, bufferSize));
CUDA_SAFE_CALL(cuMemAlloc(&dY, bufferSize));
CUDA_SAFE_CALL(cuMemAlloc(&dOut, bufferSize));
CUDA_SAFE_CALL(cuMemcpyHtoD(dX, hX, bufferSize));
CUDA_SAFE_CALL(cuMemcpyHtoD(dY, hY, bufferSize));
// Execute SAXPY.
void *args[] = { &a, &dX, &dY, &dOut, &n };
CUDA_SAFE_CALL(
cuLaunchKernel(kernel,
NUM_BLOCKS, 1, 1, // grid dim
NUM_THREADS, 1, 1, // block dim
0, NULL, // shared mem and stream
args, 0)); // arguments
CUDA_SAFE_CALL(cuCtxSynchronize());
// Retrieve and print output.
CUDA_SAFE_CALL(cuMemcpyDtoH(hOut, dOut, bufferSize));
for (size_t i = 0; i < n; ++i) {
std::cout << a << " * " << hX[i] << " + " << hY[i]
<< " = " << hOut[i] << '\n';
}
// Release resources.
CUDA_SAFE_CALL(cuMemFree(dX));
CUDA_SAFE_CALL(cuMemFree(dY));
CUDA_SAFE_CALL(cuMemFree(dOut));
CUDA_SAFE_CALL(cuModuleUnload(module));
CUDA_SAFE_CALL(cuCtxDestroy(context));
delete[] hX;
delete[] hY;
delete[] hOut;
// Release resources.
free(fatbin);
delete[] ((char*)known);
delete[] ((char*)dynamic);
return 0;
}
To see the complete example, see nvFatbin.
Fatbin object compatibility
The nvFatbin library creates a fatbin directly from the input files. It does not do any linking or compilation itself and does not have any reliance on the CUDA driver. It can even be run on systems without a GPU.
It is the toolkit version of the nvFatbin library that processes the inputs and the toolkit version of the compiled inputs that matters.
The nvFatbin library retains support for older inputs, regardless of version. This does not, however, supersede any restraints placed by the driver on loading said versions, which are independent of using a fatbin as a container format. However, the output fatbin generated is only compatible for loading with a CUDA driver of the same major version or greater than that of the nvFatbin library.
In addition, nvFatbin can process the inputs from newer NVCC or NVRTC, as long as they are within the same major release. So the nvFatbin library version on the target system must always be at least the same or newer major release as the newest version of the toolkit used for generating any of the inputs.
For example, nvFatbin that shipped with 12.4 can support code generated by any CUDA Toolkit 12.X or earlier, but is not guaranteed to work with any code generated by CUDA Toolkit 13.0 or later.
Both fatbinary, the offline tool, and nvFatbin produce the same output file type and consume the same input types, so online and offline tools can be used interchangeably in certain circumstances. For example, an NVCC-compiled CUBIN could be put in a fatbin at runtime by nvFatbin, and an NVRTC-compiled CUBIN could be put in a fatbin offline by the offline tool fatbinary. The two fatbin creation tools also follow the same compatibility rules.
CUDA and nvFatbin compatibility
NVIDIA only guarantees that nvFatbin will be compatible with inputs created with code from CUDA Toolkit of the same major version or lower as the nvFatbin library. If you attempt to create a fatbin using nvFatbin from 12.4 with PTX created with a future CUDA Toolkit 13 release, you may see a failure. However, it should support compatibility with inputs from older CUDA Toolkits, such as 11.8.
CUDA minor version compatibility
As stated earlier, the nvFatbin library will be compatible with all inputs from the same CUDA toolkit major version, regardless of minor version. This means that nvFatbin for 12.4 will be compatible with inputs from 12.5.
Some newly introduced features will not be available for previous versions, such as the addition of new types of fatbin entries. However, any format that was already accepted in a version will continue to be accepted.
Backward compatibility
The nvFatbin library supports inputs from previous versions of the CUDA toolkit.
The Bigger Picture
Now that there are runtime equivalents of all the major compiler components, how do they all interact with each other?
nvPTXCompiler
The runtime PTX compiler, nvPTXCompiler, is available as a standalone tool, but also integrated into NVRTC and nvJitLink for convenience. It can be used with nvFatbin to create CUBINs for putting in a fatbin.
NVRTC
The runtime compiler, NVRTC, can be used to compile a CUDA program. It supports PTX and LTO-IR, as well as CUBIN by integrating nvPTXCompiler, though you can produce PTX and use nvPTXCompiler manually to produce CUBINs. All of these result formats can be put into a fatbin by nvFatbin.
nvJitLink
The runtime linker, nvJitLink, can be used with NVRTC to compile and link a CUDA program at runtime. The result can either be run directly through the driver APIs or put into a fatbin with nvFatbin.
Conclusion
With the introduction of nvFatbin, generating flexible libraries dynamically is easier than ever.
TensorRT wants to store both CUBINs for existing architectures, as well as PTX for future architectures. That way, optimized versions of the code are used when possible, while still remaining compatible. While perhaps not optimal for future architectures, it ensures optimal code for existing architectures and will still be compatible with future architectures.
Before the introduction of nvFatbin, you had to come up with an alternative way to handle this, leading to effort duplication to make an online format similar to fatbin to avoid reliance on writing the relevant data to files unnecessarily.
Now with nvFatbin, you and the team behind TensorRT can use the library to handle that operation, preventing unnecessary I/O operations and avoiding a custom format to store CUBINs with PTX.
