
In today’s data-driven landscape, maximizing performance and efficiency in data processing and analytics is critical. While many Databricks users are familiar with using GPU clusters for machine learning training, there’s a vast opportunity to leverage GPU acceleration for data processing and analytics tasks as well.
Databricks’ Data Intelligence Platform empowers users to manage both small and large-scale data needs efficiently. By integrating GPU clusters into existing workflows, users can unlock significant performance gains and enhance their analytics capabilities.
This guide explores how RAPIDS helps unlock GPU acceleration on Databricks to transform data processing and analytics with familiar APIs and plugins. RAPIDS provides Databricks users with multiple options to accelerate existing workflows, including single-node processing and integration with Apache Spark and Dask. The post highlights the following installation options and integration methods for single-node and multi-node users.
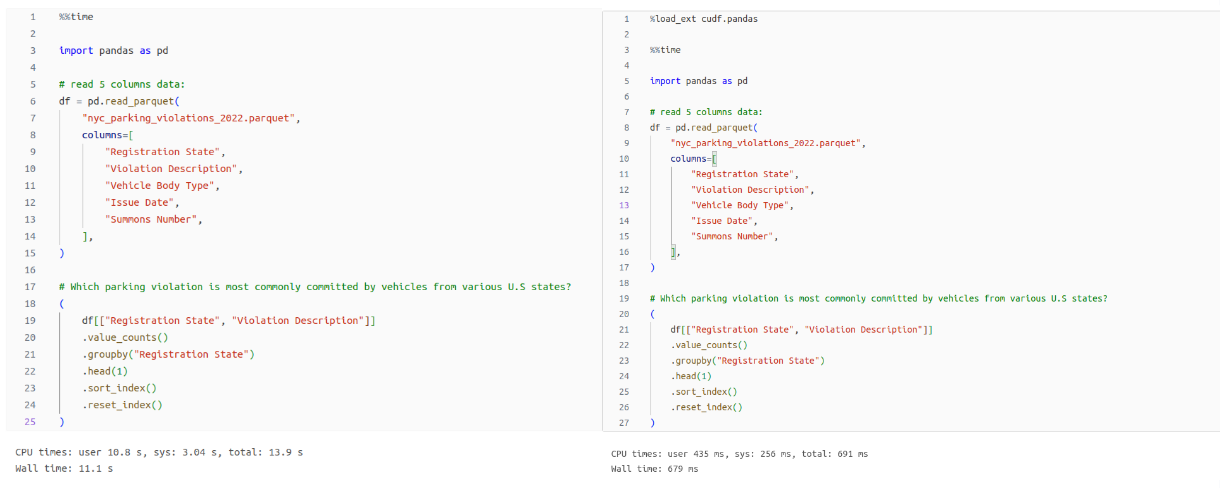
For single-node users, RAPIDS can accelerate existing pandas workflows with zero changes to code. With this new feature, single-node users can now easily switch between RAPIDS cuDF (cuDF) and pandas for large data manipulation tasks.
Multi-node users are able to accelerate their workloads with the RAPIDS accelerator for Apache Spark as well as with Dask on existing Spark clusters.
The RAPIDS accelerator for Apache Spark is available as a plugin into Apache Spark 3.0+. The plugin works by inserting a RAPIDS backend for SQL and DataFrame operations in Databricks, with no required code changes from the user. If an operation is not supported, it will fall back to using the Spark CPU version.
You can install Dask alongside Apache Spark and use libraries like dask-cudf to efficiently scale diverse workloads. The differences between Dask and Apache Spark are outlined later in the post to help you make the best tooling decisions for your data processing workflows.
Single-node users: Accelerating pandas on Databricks
pandas is a popular data manipulation library for structured data in a tabular format. Databricks Runtime includes pandas as one of the standard Python packages, enabling users to create and work with DataFrames within a single-node compute environment.
cuDF is a GPU-accelerated DataFrame library that is syntactically similar or identical to pandas in many scenarios. As of the RAPIDS v24.02 release, cuDF now directly accelerates pandas workflows with zero code changes.
Using cuDF to accelerate pandas
When cuDF accelerates pandas, a single flag written over pandas code will pull in cudf.pandas. This library will automatically optimize pandas to run on the GPU whenever possible, seamlessly falling back to the CPU with traditional pandas when necessary, with synchronization happening in the background.
This innovative approach delivers a cohesive CPU and GPU experience, ensuring optimal performance for your pandas workflows (Figure 1).
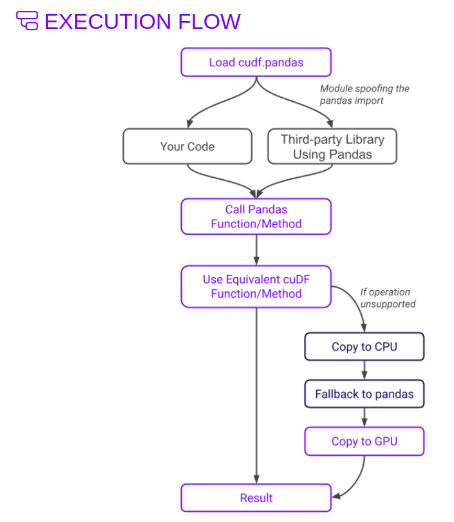
Using cudf.pandas in Databricks on a single GPU node can offer significant performance improvements over traditional pandas when dealing with large datasets. The following overview explains how cudf.pandas helps to accelerate pandas when it slows down.
1. Top performance in computation speed
- pandas operations are generally single-threaded and lack parallelism, not fully exploiting the computational capabilities of modern hardware, especially for large-scale data processing.
- Built on top of the CUDA framework, cudf.pandas harnesses the parallel processing power of GPUs, enabling faster computation of operations like filtering, aggregations, and joins. This is particularly beneficial when dealing with large datasets that can be distributed across the GPU cores.
2. Zero code change acceleration
- Users can accelerate pandas with cudf.pandas in their existing code with zero modifications. Load the cudf.pandas Jupyter Notebook extension using the magic command or use the Python module flag on the command line.
| # IPython or Jupyter Notebooks | # Python script |
%load_ext cudf.pandas | python -m cudf.pandas script.py |
3. Unified CPU and GPU workflows
- A vast majority of Python packages aren’t GPU-enabled. That means that for any analysis that uses other packages—PyData libraries or organization-specific tools—users move computation from GPU (cuDF) to CPU (pandas) and back again.
- With cuDF pandas accelerator mode, you can now develop, test, and run in production with a single code path, regardless of hardware.
- Third-party library compatibility: cudf.pandas offers flexibility and is compatible with most third-party libraries that operate on pandas objects, consequently accelerating pandas operations within these libraries.
cuDF pandas quick start example
To accelerate pandas with cuDF in a notebook environment, follow the instructions to launch a single-node GPU-enabled Databricks cluster. Then upload the 10 Minutes to RAPIDS cuDF pandas notebook.
In addition, any pandas code running inside the third-party library’s functions will also benefit from GPU acceleration where possible. For example, you can see an image illustrating how cudf.pandas can accelerate the pandas backend in Ibis, a library that provides a unified DataFrame API to various backends. This example ran on a system with an NVIDIA H100 GPU and an Intel Xeon Platinum 8480CL CPU.
By loading the cudf.pandas extension, pandas operations within Ibis can use the GPU with zero code change. It just works.

To learn more, see the GTC 2024 session, Accelerating pandas with Zero Code Change Using RAPIDS cuDF and the cuDF documentation. Also, check out the related posts, RAPIDS cuDF Accelerates pandas Nearly 150x with Zero Code Changes and NVIDIA Announces cuDF pandas Accelerator Mode.
Distributed data processing with Apache Spark and Dask
Apache Spark and Dask are distribution frameworks that help users process workloads across multiple processors for larger datasets. Leveraging Apache Spark and Dask in multi-node Databricks clusters ensures the effective utilization of GPU resources, translating into better results and overall performance for RAPIDS workflows.
In Databricks, Spark clusters excel in large-scale data processing, with a driver node managing execution and multiple worker nodes for computing parallel tasks. Apache Spark focuses strongly on traditional business intelligence workloads like ETL and SQL queries, as well as lightweight machine learning.
Dask clusters share a similar architecture as Spark clusters but offer a flexible parallel computing framework suited for diverse workloads, particularly those less centered on traditional SQL-style computations. For instance, Dask excels in handling multi-dimensional arrays, GIS, advanced machine learning.
Multi-node Databricks: Accelerating Rapids with Apache Spark
In Databricks, a Spark cluster handles large-scale data processing with Apache Spark, distributing workloads across multiple nodes to achieve parallelism.
When you launch a multi-node cluster on Databricks, a Spark driver node and many Spark worker nodes are provisioned. The driver node is responsible for managing the overall Spark application, while the worker nodes execute the submitted tasks.
RAPIDS Accelerator For Apache Spark provides a set of plugins for Apache Spark that leverage GPUs to accelerate Dataframe and SQL processing using the RAPIDS libraries.
The accelerator is built on the RAPIDS cuDF project and UCX, and requires each worker node in the cluster to have CUDA installed.
To use Spark RAPIDS with a Databricks cluster, the user must provide an init script that downloads the rapids-4-spark-xxxx.jar plugin and then configure Spark to load this plugin. Spark queries will then leverage libcudf under the hood and benefit from GPU acceleration.
To set up the RAPIDS Accelerator for Apache Spark 3.x on Databricks, follow the Databricks User Guide. The end of the guide presents an opportunity to run a sample Apache Spark application that runs on NVIDIA GPUs on Databricks.
Multi-node Databricks: Accelerating Rapids with Dask
Dask is used throughout the PyData ecosystem and is included in many libraries like Xarray, Prefect, RAPIDS, and XGBoost.
As datasets and computations scale faster than CPUs and RAM, it’s necessary to find ways to scale computations across multiple machines. Dask helps to partition large computations and allocate efficiently onto distributed hardware.
Why Dask on Databricks?
Dask now has a dask-databricks CLI tool (through conda and pip) to simplify the Dask cluster startup process within Databricks.
The Spark cluster architecture of a driver and workers is the same as a Dask cluster, which has a scheduler and workers on different nodes. As shown in the Spark RAPIDS example, Databricks provides a mechanism to run a script on every node at startup to install plugins.
Dask on Databricks takes advantage of this paradigm to bootstrap a Dask cluster in the background as part of the initialization script process. This init script runs on each node at startup, enabling necessary configurations and installations.
Dask on Databricks with RAPIDS quick start example
To get started, first configure an init script with the following contents to install Dask, Dask on Databricks, RAPIDS libraries, and all other dependencies.
#!/bin/bash
set -e
# Install RAPIDS (cudf & dask-cudf) and dask-databricks
/databricks/python/bin/pip install --extra-index-url=https://pypi.nvidia.com \
cudf-cu11 \
dask[complete] \
dask-cudf-cu11 \
dask-cuda==24.04 \
Dask-databricks
# Start Dask cluster with CUDA workers
dask databricks run –-cuda
Next, from your Databricks notebook you can quickly connect a Dask Client to the scheduler running on the Spark Driver Node.
import dask_databricks
client = dask_databricks.get_client()
Now submit tasks to the cluster:
def inc(x):
return x + 1
x = client.submit(inc, 10)
x.result()
You can access the Dask dashboard using the Databricks driver-node proxy. The link can be found in Client or using client.dashboard_link.
>>> print(client.dashboard_link)
https://dbc-dp-xxxx.cloud.databricks.com/driver-proxy/o/xxxx/xx-xxx-xxxx/8087/status
For a more comprehensive example, see Training XGBoost with Dask RAPIDS in Databricks.
Summary
RAPIDS is an open-source suite of GPU-accelerated Python libraries with APIs that look and feel like the most popular open-source data science tools. This post walked through a few approaches to help accelerate your analytics workloads using the RAPIDS on Databricks unified, and easy-to-use analytics platform:
- If you work in a single-node GPU notebook environment, installing RAPIDS cuDF can speed up your pandas workloads by up to 150x with zero code changes.
- If you’re an Apache Spark user, you can simply add RAPIDS Accelerator for Apache Spark 3.x to your Databricks setup for multiple nodes distributed processing for up to 5x speed-ups, with the NVIDIA Decision Support benchmark.
- We’re thrilled to share another option for multi-node data processing with Dask and RAPIDS on Databricks that excels at scaling non-SQL workloads. Dask support is now integrated on existing Spark clusters in Databricks.
- The different installation options (cudf.pandas, Spark, or Dask) make it easy to adapt RAPIDS to your specific needs on the Databricks platform.
As data scientists shift from using traditional analytics to leveraging AI applications, traditional CPU-based processing can no longer keep up without compromising either speed or cost. The growing demand for big data analytics has created the need for a new framework to process data quickly with GPUs.
As a result, Databricks is a favorable option that makes it easy to seamlessly integrate GPU acceleration into your everyday work with pandas and other libraries.
Whether you leverage the power of cudf.pandas for efficient data manipulation, Spark or Dask for parallelized computing, Databricks provides a user-friendly environment that empowers you to supercharge your existing RAPIDS workflows with GPU capabilities, unlocking new levels of performance and efficiency.
