
The previous post How to Accelerate Quantitative Finance with ISO C++ Standard Parallelism demonstrated how to write a Black-Scholes simulation using ISO C++ standard parallelism with the code found in the /NVIDIA/accelerated-quant-finance GitHub repo. This approach enables you to productively write code that is both concise and portable.
Using solely standard C++, it’s possible to write an application that can be run in parallel on a modern, multicore CPU or on a GPU without modification. This post builds a more complex model, starting from the previously developed parallel Black-Scholes code, and optimizes it to use the benefits of the GPU, while remaining in standard C++.
Profit and loss modeling explained
A popular strategy to trade realized volatility involves delta-hedging an option position. Under Black-Scholes assumptions, if an investor succeeds in hedging away the underlying risk, then the main contributor of the profit and loss (P&L) from this strategy is proportional to the difference between the squares of the realized volatility and the volatility used to price and hedge the option.
The P&L is dependent on the path of the underlying. Estimating a full P&L distribution to a given horizon for a large portfolio of options can be rather compute-intensive and warrants an extension of the parallel Black-Scholes code.
Consider a grid of long European call options of various strikes and maturities on the same underlying \(S\). Assume that the options are held to a given time horizon (\(N\) timesteps) and that they are delta-hedged at each timestep \(dt\).
As time passes, the underlying \(S\) moves, the moneyness of each option changes accordingly, and the expiry draws nearer.
For a given option contract, the premium is a function of several parameters, including the underlying \(S\) and the option’s remaining time to expiry: \(T-t\). Theoretically, the shorter \(T-t\), the less opportunity for movement in \(S\).
Assuming all parameters remain unchanged as time passes, the option loses value with each tick of the clock. This negative change in the option’s value as time goes by is known as theta, or time decay.
As the underlying \(S\) moves over time, the value of the option also changes.
To the first order, the resulting change in the option value is given by the delta of the option. For example, if delta is 0.55 and \(S\) moves up by 1, then the option price also moves up by approximately 0.55.
To the second order, as \(S\) moves, so does the delta of the option, by an amount proportional to the second-order Greek gamma. Because a long call is a convex function of the underlying, gamma is positive and the gain in price due to gamma is also positive regardless of the direction of the underlying move.
In the case of a delta-hedged option, the aggregate delta P&L is zero, and the gamma gain has the potential to counteract, surpass, or succumb to losses due to theta (Figure 1).

In this example, the goal is to characterize the distribution of the gamma-theta P&L at a given horizon for each option in the grid by simulating paths of the underlying and accumulating the P&L along those paths.
In this simple Black-Scholes world, the underlying follows a lognormal dynamics under the risk-neutral measure with realized volatility \(\sigma_R\):
\(dS_t = rS_t dt + \sigma_R S_t dW_t^Q\)
The daily (or one time step) P&L can be obtained as:
\(\text{P\&L}_j = \Gamma_j dS_j^2 + \theta_j dt \equiv \Gamma_jS_j^2(\sigma_R^2 – \sigma_H^2)dt\)
In this equation, \(\Gamma\) and \(\theta\) are the gamma and theta greeks at the \(j^{th}\) time step computed using a hedging volatility \(\sigma_H\) (in practice, the implied volatility is often used as the hedging volatility).
The P&L over a single path of the underlying consisting of \(N\) time steps is the cumulation of the daily P&Ls:
\(\text{P\&L} = \Sigma_{j=1}^{N} \text{P\&L}_j\)
Parallel P&L simulations
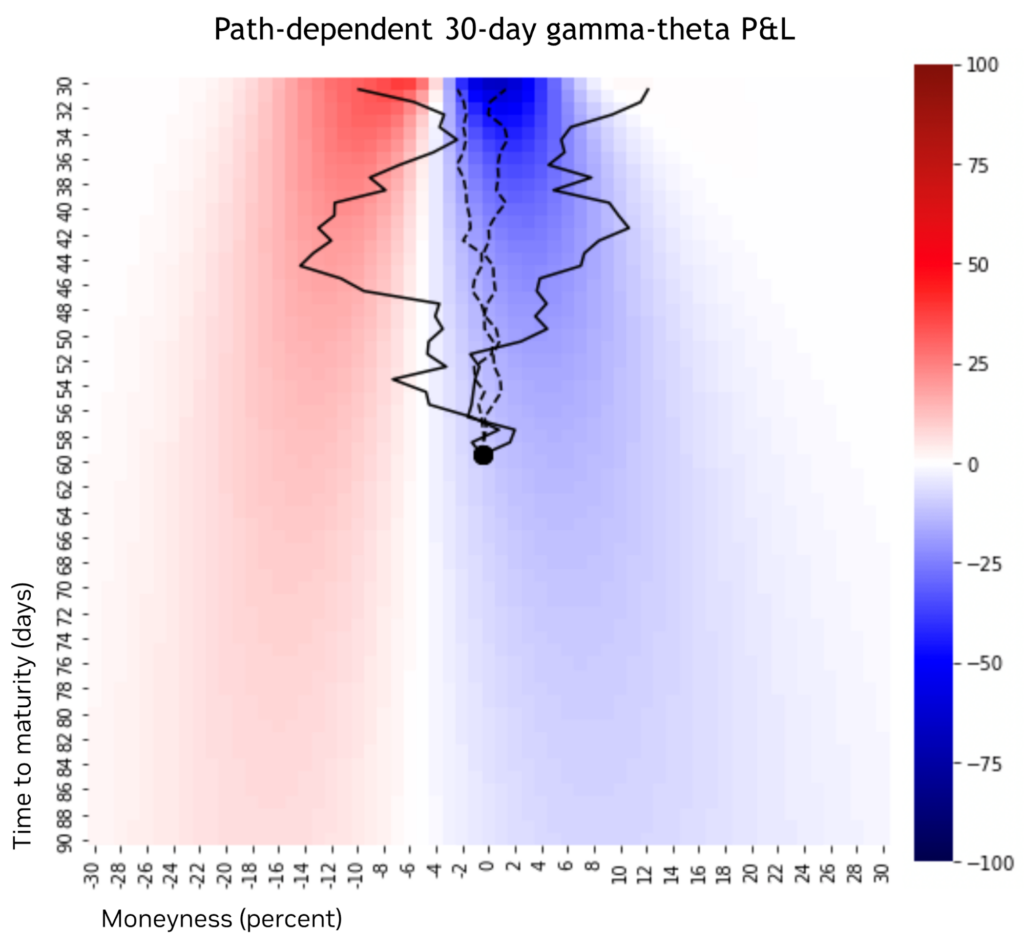
Figure 2 shows the options grid and four simulated paths. Each grid cell represents an option contract with its corresponding moneyness and time to maturity marked on the horizontal and vertical axes, respectively. The color in the heatmap is proportional to the average P&L across these paths. The average is just one statistic that can be computed from the simulated P&L for which the full distribution is available through simulation.
The parallel code from the previous post serves as the baseline. Each path is looped over and then walked, parallelizing the P&L calculation over options, as was done in the previous example.
This is a reasonable approach because there is the potential to have a significant number of options to parallelize. The code itself is straightforward and the only major difference is a transform added at the end to convert the sums to means.
However, there are still opportunities to further optimize the code and improve performance.
void calculate_pnl_paths_sequential(stdex::mdspan<const double, stdex::dextents<size_t,2>> paths,
std::span<const double>Strikes,
std::span<const double>Maturities,
std::span<const double>Volatilities,
const double RiskFreeRate,
std::span<double>pnl,
const double dt)
{
int num_paths = paths.extent(0);
int horizon = paths.extent(1);
auto steps = std::views::iota(1,horizon);
// Iterate from 0 to num_paths - 1
auto path_itr = std::views::iota(0,num_paths);
// Note - In this version path remains in CPU memory
// Note - Also that when built for the GPU this will result in
// num_paths * (horizon - 1) kernel launches
std::for_each(path_itr.begin(), path_itr.end(),
[=](int path) // Called for each path from 0 to num_paths - 1
{
// Iterate from 1 to horizon - 1
std::for_each(steps.begin(), steps.end(),
[=](int step) // Called for each step along the chosen path
{
// Query the number of options from the pnl array
int optN = pnl.size();
// Enumerate from 0 to (optN - 1)
auto opts = std::views::iota(0,optN);
double s = paths(path,step);
double s_prev = paths(path,step-1);
double ds2 = s - s_prev;
ds2 *= ds2;
// Calculate pnl for each option
std::transform(std::execution::par_unseq, opts.begin(), opts.end(),
pnl.begin(), [=](int opt)
{
double gamma = 0.0, theta = 0.0;
BlackScholesBody(gamma,
s_prev,
Strikes[opt],
Maturities[opt] - std::max(dt*(step-1),0.0),
RiskFreeRate,
Volatilities[opt],
CALL,
GAMMA);
BlackScholesBody(theta,
s_prev,
Strikes[opt],
Maturities[opt] - std::max(dt*(step-1),0.0),
RiskFreeRate,
Volatilities[opt],
CALL,
THETA);
// P&L = 0.5 * Gamma * (dS)^2 + Theta * dt
return pnl[opt] + 0.5 * gamma * ds2 + (theta*dt);
});
});
});
}
Increasing parallelism for increased performance
Whenever a parallel algorithm is offloaded to a GPU, two overheads are introduced:
- Launch latency: The cost of launching the GPU kernel.
- Synchronization: Parallel algorithms are synchronous with respect to the CPU, which means the program must wait for the kernel to complete before moving on and launching the next kernel.
Neither of these overheads is particularly large, a small fraction of a second each time, but they add up when done repeatedly. Even worse, the NVIDIA Nsight Systems profiler reveals that each kernel requires a device synchronization step that is longer than the kernel itself.
The paths are independent random walks that have no relation aside from the same initial value of the underlying \(S\). Therefore, you can parallelize across paths too, as long as no two paths attempt to update the same place in memory at the same time, which would be a race condition.
To address this potential race condition, use C++ atomic_ref to make sure that if two paths try to update the same location in the P&L array at the same time, they do so in a safe manner.
By moving the iteration over paths into the function, it is now possible to parallelize over both paths and options along each path. Though this example is more complicated, it’s essentially the same refactoring done for the initial example.
void calculate_pnl_paths_parallel(stdex::mdspan<const double,
stdex::dextents<size_t,2>> paths,
std::span<const double>Strikes,
std::span<const double>Maturities,
std::span<const double>Volatilities,
const double RiskFreeRate,
std::span<double>pnl,
const double dt)
{
int num_paths = paths.extent(0);
int horizon = paths.extent(1);
int optN = pnl.size();
// Create an iota to enumerate the flatted index space of
// options and paths
auto opts = std::views::iota(0,optN*num_paths);
std::for_each(std::execution::par_unseq, opts.begin(), opts.end(),
[=](int idx)
{
// Extract path and option number from flat index
// C++23 cartesian_product would remove the need for below
int path = idx/optN;
int opt = idx%optN;
// atomic_ref prevents race condition on elements of pnl array.
std::atomic_ref<double> elem(pnl[opt]);
// Walk the path from 1 to (horizon - 1) in steps of 1
auto path_itr = std::views::iota(1,horizon);
// Transform_Reduce will apply the lambda to every option and perform
// a plus reduction to sum the PNL value for each option.
double pnl_temp = std::transform_reduce(path_itr.begin(), path_itr.end(),
0.0, std::plus{},
[=](int step) {
double gamma = 0.0, theta = 0.0;
double s = paths(path,step);
double s_prev = paths(path,step-1);
double ds2 = s - s_prev;
ds2 *= ds2;
// Options in the grid age as the simulation progresses
// along the path
double time_to_maturity = Maturities[opt] –
std::max(dt*(step-1),0.0);
BlackScholesBody(gamma,
s_prev,
Strikes[opt],
time_to_maturity,
RiskFreeRate,
Volatilities[opt],
CALL,
GAMMA);
BlackScholesBody(theta,
s_prev,
Strikes[opt],
time_to_maturity,
RiskFreeRate,
Volatilities[opt],
CALL,
THETA);
// P&L = 0.5 * Gamma * (dS)^2 + Theta * dt
return 0.5 * gamma * ds2 + (theta*dt);
});
// accumulate on atomic_ref to pnl array
elem.fetch_add(pnl_temp, std::memory_order_relaxed);
});
}
A std::for_each algorithm is used to iterate across paths and options. Within each iteration, a std::transform_reduce algorithm is used to traverse each path for each option, adding up the profits and losses and returning that result. Each of these intermediate results is then automatically added to the P&L array.
The main benefit of this approach is that rather than repeatedly bouncing back and forth between the GPU and CPU, a single operation is launched on the GPU for the complete data set and the program only waits for the result one time (Figure 3).

This approach results in a significant performance improvement over the original, which itself was already accelerated on the GPU (Figure 4).

The lesson learned from this second example is to expose as much parallelism for the hardware as possible. Both the CPU and GPU versions improved with the first approach, but the GPU version really shines after reducing the launch and synchronization overheads by exposing more parallelism.
Explore the code
The acceleration realized in this quantitative finance example using the code in the /NVIDIA/accelerated-quant-finance GitHub repo can be easily applied to your C++ applications. Any C++ code written with serial loops can be easily modified using standard language parallelism to achieve significant GPU acceleration.
To easily produce your own portable and parallel-first code, download the NVIDIA HPC SDK, which contains all of the tools to make use of ISO C++ standard parallelism and profile the results.
