
The past decade has seen a remarkable surge in the adoption of deep learning techniques for computer vision (CV) tasks. Convolutional neural networks (CNNs) have been the cornerstone of this revolution, exhibiting exceptional performance and enabling significant advancements in visual perception.
By employing localized filters and hierarchical architectures, CNNs have proven adept at capturing spatial hierarchies, detecting patterns, and extracting informative features from images, as explained in Deep Residual Learning for Image Recognition. Convolutional layers exhibit translation equivariance, enabling them to generalize to translations and spatial transformations. However, despite their success, CNNs exhibit limitations in capturing long-range dependencies and global contextual understanding, which become increasingly crucial in complex scenes or tasks requiring fine-grained understanding.
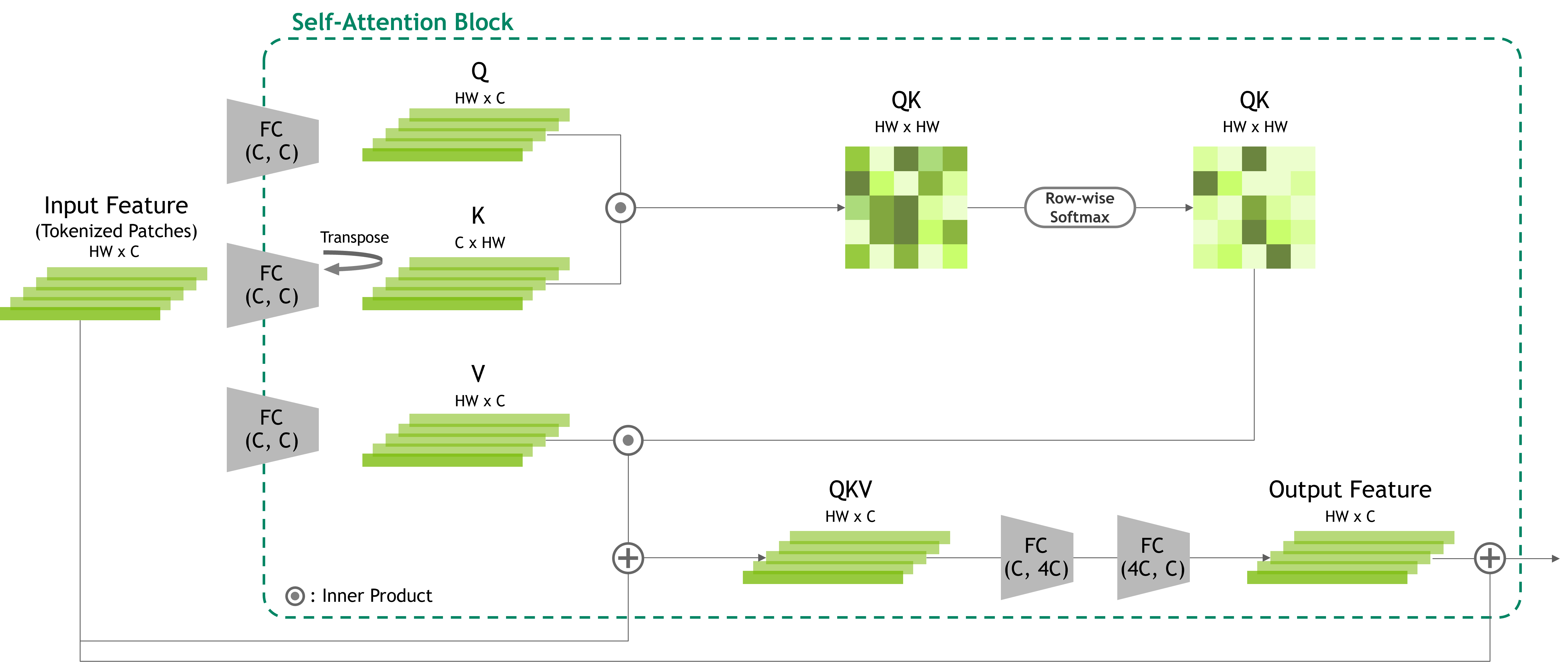
In contrast, transformers have emerged as a compelling alternative architecture in computer vision, driven by their success in natural language processing (NLP), as explained in Attention Is All You Need. By eschewing local convolutions, transformers offer a self-attention mechanism that supports global relationships among visual features. The attention mechanism enables transformers to capture long-range interactions between image elements, facilitating a more holistic understanding of the visual scene that leads to better accuracy. Figure 1 shows an example of self-attention for vision applications. For more details, see An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale and Swin Transformer: Hierarchical Vision Transformer using Shifted Windows.
Self-attention, nonetheless, encounters challenges in effectively capturing local contextual information within images, accentuating the significance of broader global receptive fields. Additionally, the computational complexity associated with self-attention, characterized by quadratic interactions between visual feature elements, poses significant challenges for handling large images in computer vision.
At the frontier of innovation, the automotive industry is increasingly recognizing the need for the widespread incorporation of transformer-like networks. However, the integration of these networks presents unique challenges. Specifically, within the NVIDIA TensorRT framework for certain operating systems on NVIDIA DRIVE products, limited specialized functionality is supported as compared to standard use cases.
These specialized APIs still include highly optimized convolution operations, among others, reflecting the industry’s long-standing commitment to refining convolutional networks. We aim to harness these optimized convolution operations strategically to drive more efficient and effective implementation of transformer networks. Our goal is to empower the automotive industry to meet the dynamic demands of modern applications while working harmoniously within the confines of existing software frameworks and hardware platforms.
While recognizing the value of self-attention, it is imperative to place greater emphasis on the impact of convolutions, especially in CV tasks for. This is true for the following reasons:
- The inherent characteristic differences between images and texts, as previously mentioned, highlight the challenges of applying self-attention directly to CV tasks, calling for hybrid approaches or alternative architectures that combine the strengths of self-attention and convolutional layers.
- In autonomous vehicle (AV) applications, high-resolution images are often used in real-time applications. The optimization of self-attention computation on hardware platforms has fallen behind the rapid emergence of new transformers by AV industry and chip makers, failing to meet user demands. Current implementations of transformer-based models inadequately leverage the computational capabilities of GPUs.
- In many cases of production in autonomous driving, inference performed in the restricted mode of deep learning runtime libraries may not yet have full support of state-of-the-art transformer networks. For example, current operations in transformers are not fully covered in TensorRT restricted mode.
This post presents our recent work on emulating the attention mechanism in transformer models using a fully convolutional network. Our method combines the strengths of conventional convolution kernels optimized for current GPU hardware platforms with self-attention modules, resulting in superior performance compared to contemporary transformer-like models. Our work addresses the increasing user demand for transformer usability in various industries with computer vision problems. Our method not only provides the fastest latency performance with comparable accuracy when running on TensorRT, but is also fully compatible in TensorRT restricted mode.
Fusing convolutions and self-attention
Recent research shows a growing interest in merging the strengths of CNNs and transformers. By combining convolution operations for local feature information with self-attention modules for global feature relations, researchers aim to enhance the capabilities of both architectures.
Swin Transformer is one notable example. This recent vision-transformer introduces the concept of shifted windows to enable transformers to effectively learn local features. By incorporating local self-attention within smaller regions, Swin captures local relationships and dependencies, thereby improving performance in tasks requiring fine-grained information. However, a challenge arises with the quadratic increase in computational complexity of self-attention as input sizes grow, which can quickly impose latency burdens.
To address this issue, researchers have explored merging convolution operations and self-attentions. Convolution-based approaches mimic transformer training configurations or selectively use convolutions and self-attentions in various parts of networks.
For example, Convolutional Vision Transformer (CvT) intuitively incorporated convolutional features into self-attention modules. Conv-Next, on the other hand, resembles vision transformers with conventional CNNs. Nonetheless, the approach fails to explicitly address the limited receptive fields commonly encountered in traditional convolutional network models. Unlike self-attention, convolutional operations possess a fixed receptive field size and a shared set of parameters. This characteristic enables convolutions to process input data in a locally focused and parameter-efficient manner.
Convolutional Self-Attention
We present Convolutional Self-Attention (CSA), which completely replaces conventional attention mechanisms with convolution operations for vision tasks, enabling the modeling of both local and global feature relations. By relying solely on convolutions, our overall model achieves remarkable efficiency on highly optimized GPUs and deep learning accelerators. Experimental results convincingly demonstrate its competitive accuracy in comparison to contemporary transformer networks, while displaying improved hardware utilization and significantly reduced deployment latency.
The overall proposed model consists of repetitive uses of down-sampling convolution layers and our proposed CSA blocks along its feed-forwarding flow, as depicted in Figure 2. Each CSA block emulates a transformer block employing convolution operations.

Figure 3 shows the structure and flow of the CSA module. The CSA blocks can differ in implementation but are designed to emulate the relational encoding process of self-attention. To achieve relational encoding, we rotate the tensor along the channel-axis, converting channel features into spatial format (height and width).
This rotated feature tensor is elementwise multiplied with the original tensor before rotation, followed by convolutions. This replicates the first inner product of self-attention, but with a difference in concept, as our method allows for one-to-many relational embedding through elementwise multiplication and convolution. The resulting relational feature tensor is then normalized, activated, and multiplied with another visual feature from the input tensor, value (V).
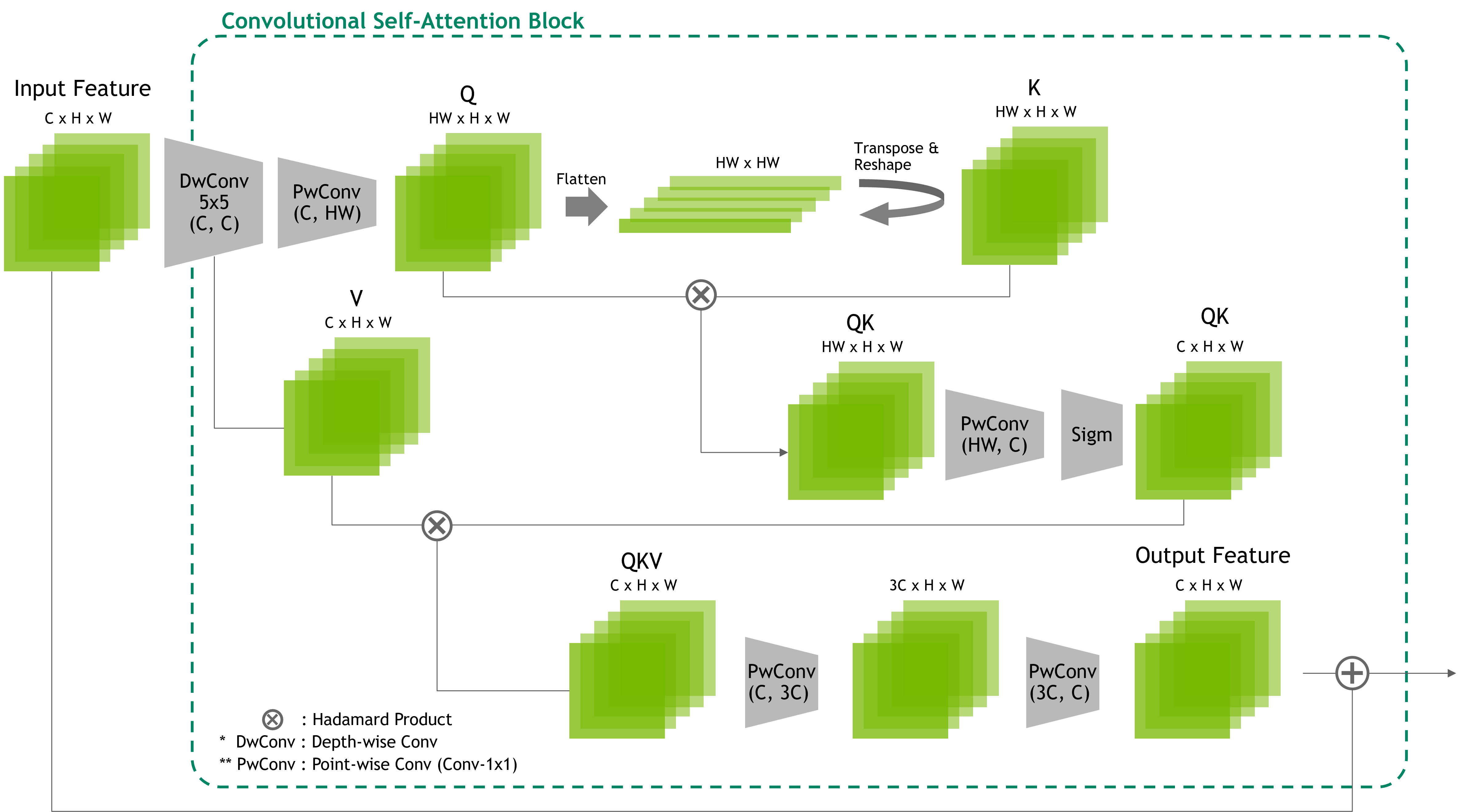
Our method achieves a global receptive field by strategically rearranging feature tensors and utilizing local convolution kernel windows. This explicit relational encoding enables each feature pixel to be projected to all others, resulting in comprehensive inter-pixel interactions. This is because the structural rearrangements of tensors in our approach enable convolution windows to capture global relationships among visual features, leveraging the strengths of convolutional operations for one-to-many visual feature relational reasoning.
In comparison, CSA modules encode relations among all feature pixels through inner-product operations, which can impose significant computational burdens on hardware. By achieving one-to-all relational encoding, our approach reduces the computational load while preserving the ability to capture long-range dependencies and structural information across the entire feature map.
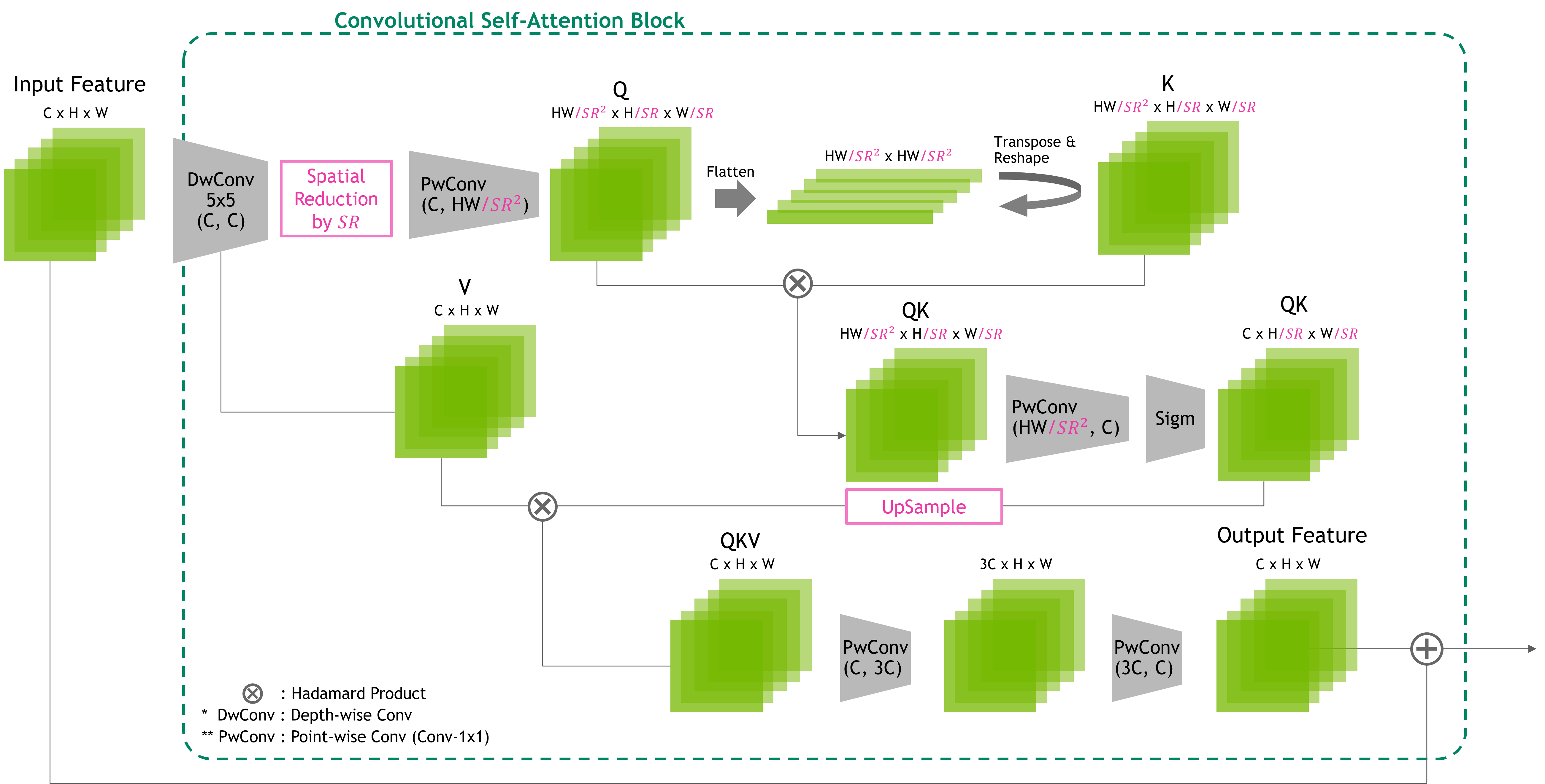
To manage the quadratic computational increments resulting from increasing input sizes, our design can incorporate spatial reduction layers to reduce the tensor size, as illustrated in Figure 4. This not only helps decrease computational overhead but also enables the network to focus on regional relationships among visual features, which carries more semantics, rather than pixel-level relationships.
Performance in accuracy and latency
The CSA module is compared against relevant contemporary CV classification models with the ImageNet-1K dataset in terms of accuracy against the validation data and latency measured with TensorRT-8.6.11.4. We target for AV application of CSA with restricted mode in mind, so the models are compared on the NVIDIA DRIVE Orin platform. NVIDIA DRIVE Orin is a high-performance and energy-efficient system-on-a-chip (SoC) and is part of the NVIDIA DRIVE platform for use in autonomous vehicles.
Benchmark entries
- The Swin Transformer network is an innovative deep learning architecture that combines self-attention mechanisms, originally popularized by models like the vision transformer (ViT), with a hierarchical and parallelizable design.
- The ConvNext model is developed through a progressive transformation of a standard ResNet to resemble a vision Transformer, competing favorably with Swin Transformers in specific tasks while maintaining the simplicity and efficiency of conventional convolutional networks.
- The Convolutional Vision Transformer (CvT) enhances performance and efficiency by incorporating convolutions into ViT. CvT performs very competitively on ImageNet-1k with fewer parameters and lower GMACs.
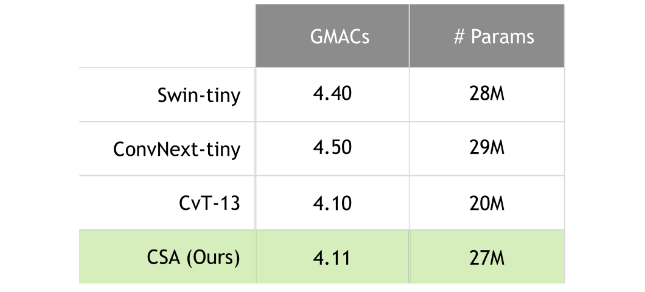
The rationale for the benchmark entries lies in their relevance to CSA and contemporary significance. In our experiments, we specifically compared CSA with the benchmarks of Swin-tiny, ConvNext-tiny, and CvT-13 that share similar model sizes, which is succinctly shown in Table 1.
We are presenting our results using two kinds of precision modes, FP16 and mixed precision (that is, with FP32, FP16, and INT8 all enabled) in TensorRT. This approach allows us to provide a balanced assessment of our models’ performance. The model quantization for all methods was achieved using Post-Training Quantization (PTQ) and 500 images were used during the calibration process.
We measure accuracy using the Top-1 accuracy on the ImageNet dataset and report inference latency in milliseconds with various batch sizes of 1, 4, 8, and 16. This ensures that our comparison is conducted in a fair and unbiased manner. One can further optimize the TensorRT inference of CSA to strike a balance between accuracy and latency, with the aim of exploiting latency within acceptable accuracy constraints.
In the pursuit of optimizing precision modes to enhance latency at the potential expense of accuracy, quantization strategies emerge as a compelling solution. TensorRT offers a diverse array of quantization methods, including percentile, mean squared error (MSE), and entropy quantization, all of which demonstrate effectiveness in mitigating precision loss. In our study, which centers on mixed-precision inferences across a range of benchmark methods, we selected the entropy quantization methodology. This approach, grounded in information theory, allocates codes to minimize the average code word length, resulting in minimal accuracy degradation, with the noteworthy exception of the CvT benchmark.
While all benchmarks, including CSA, maintain an indistinguishable level of accuracy even after precision reduction, ConvNext outperforms the other benchmarks to a slight extent despite the reduced precisions. Conversely, CSA exhibits the smallest drop in accuracy.
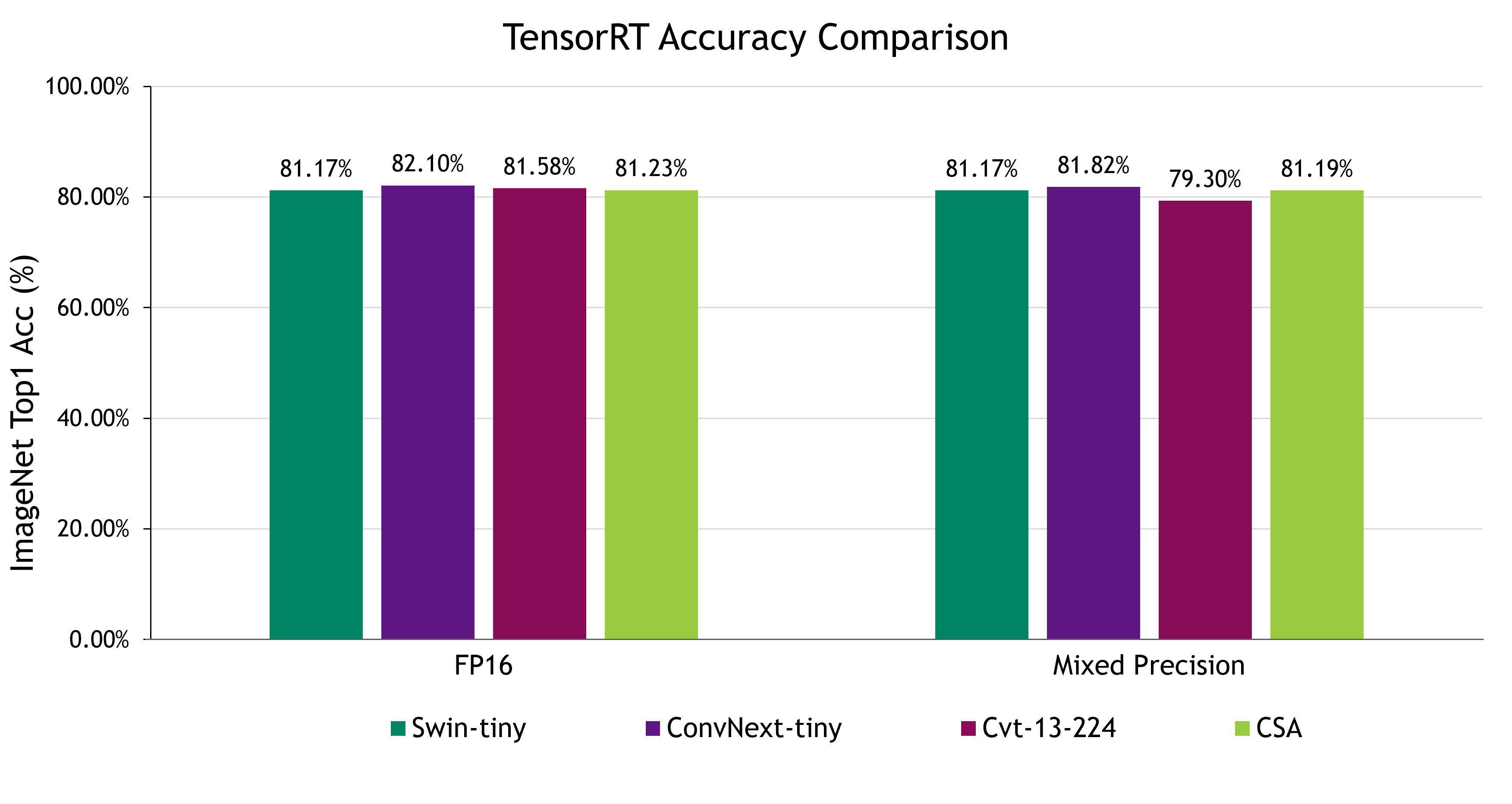
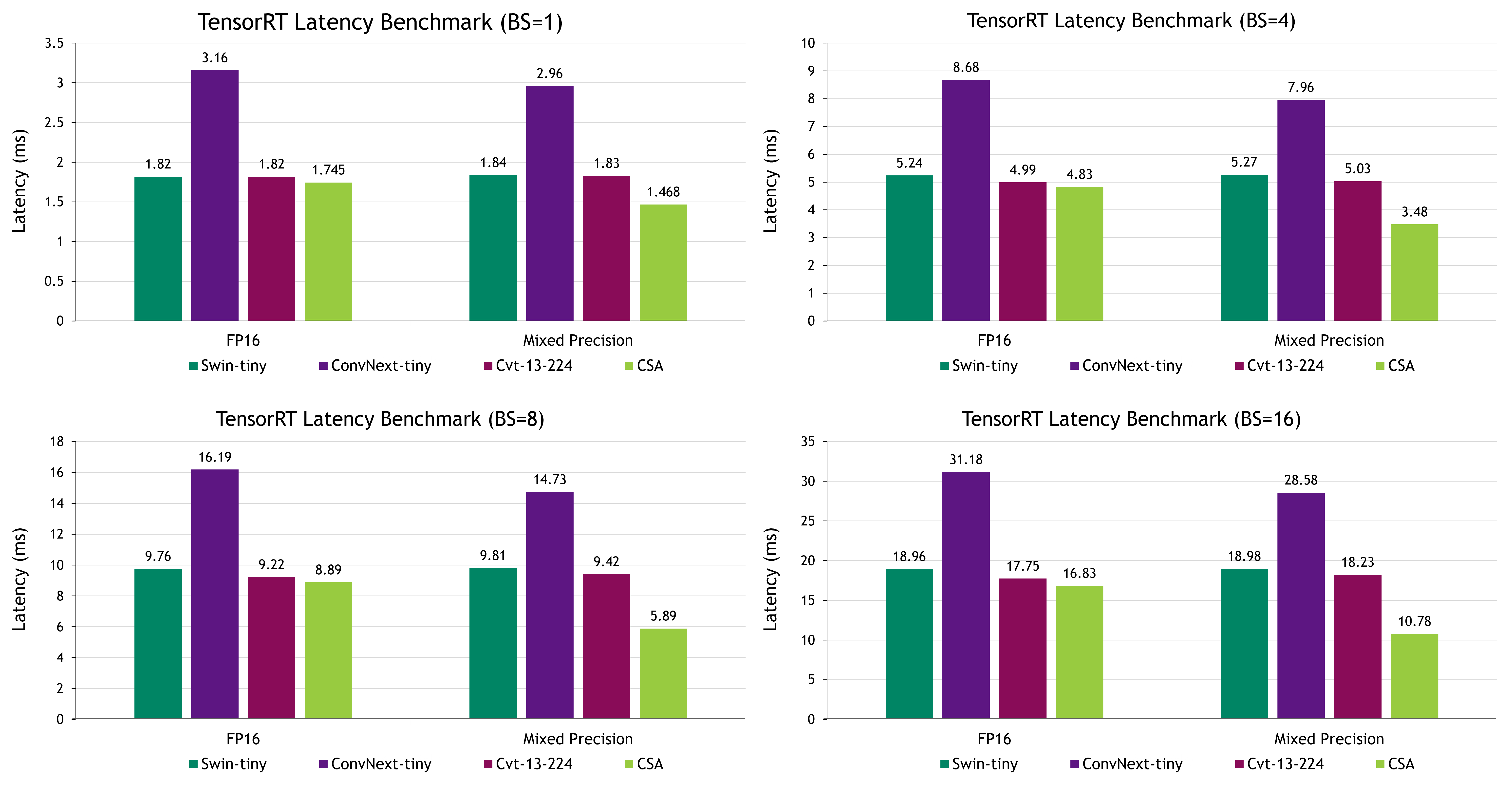
ConvNext stands out for its accuracy in both FP16 and mixed-precision modes but comes with the trade-off of comparably slow latency. In this context, CSA emerges as a highly competitive option, offering commendable accuracy, while achieving the fastest latency.
Compared to ConvNext-tiny, CSA delivers a remarkable 49% improvement in latency for the case of batch size of one while maintaining its strong accuracy performance. This underscores CSA’s impressive capabilities and positions it as a strong choice within this context.
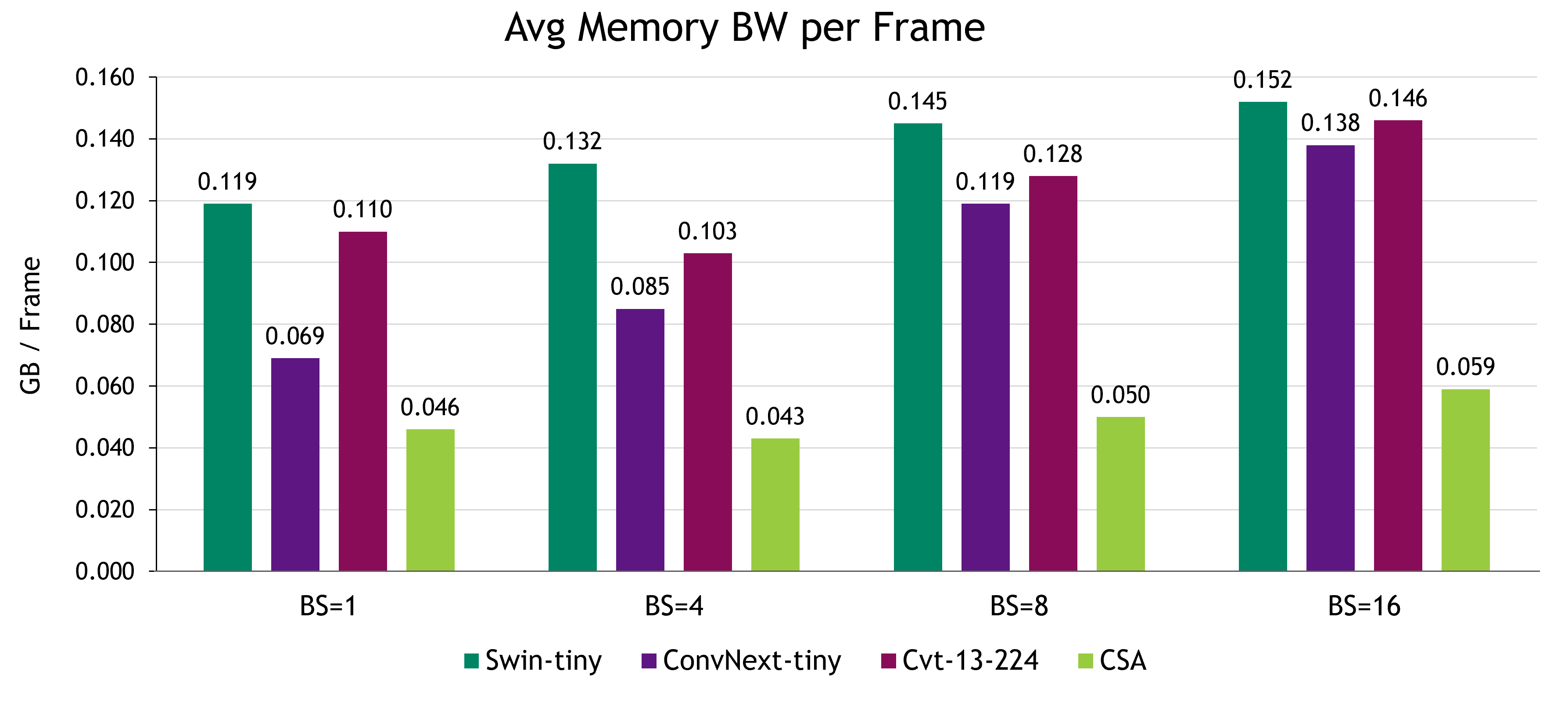
CSA outperforms the benchmarks for efficient memory traffic during inference, resulting in the least bandwidth of average memory per frame. It should be noted that CSA’s memory traffic is persistent even as the batch size grows, while the other methods in the benchmark are growing gradually.
Thanks to the strategic design of CSA, our model can leverage efficient convolution kernel implementation in TensorRT, resulting in highly efficient computations that strike a harmonious balance between accuracy and latency, while being fully compatible with TensorRT restricted mode. Other methods, either with higher accuracy or lower latency, are not compatible. In practice, this makes it currently difficult to deploy those models in production where the TensorRT restricted model is required.
Conclusion
Unlike other convolutional models that try to ingest the attention module from a transformer model, Convolutional Self-Attention (CSA) explicitly finds relationships among features one-to-many with only convolutions in conjunction with simple tensor shape manipulations. The differences between our method and relevant methods listed below:
- By strategically rearranging feature tensors, explicit relational encoding ensures that each feature pixel is projected to all others, achieving a global receptive field while utilizing local convolution kernel windows.
- In contrast to conventional self-attention modules that encode relations among all input features with increase computational cost with respect to the input size, our method succinctly achieves all-to-all relational encoding with convolution operations in a hierarchical manner at each stage with reduced input size, which lower the computational load on hardware.
- These advantages enable faster inference speed for models of comparable size and match or exceed the performance of other methods.
More importantly, CSA operates without bells and hassles in TensorRT restricted model, making it suitable for AV production for safety-critical applications. We expect CSA to serve as a reference model design for our customers who are using the NVIDIA DRIVE platform and beyond. For more information, visit the NVIDIA Developer AV Forum and TensorRT Forum.
