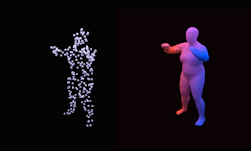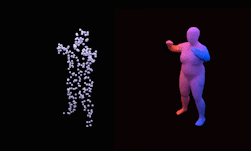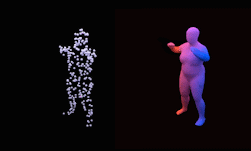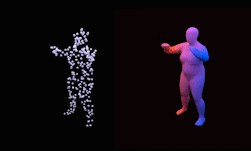
The story below is a guest post from researchers at the Max Planck Institute for Intelligent Systems. In this article, the researchers describe a new method for dense 4D reconstruction from images or sparse point clouds.
By Michael Niemeyer
An intelligent agent that interacts and navigates in our world has to be able to reason in 3D. Therefore, in recent years there has been a lot of interest in learning-based 3D reconstruction. Such techniques use neural networks to process some input information (for example an image or a sparse point cloud) and output the 3D geometry of a single object or scene.
One particular challenge in 3D reconstruction is the output representation, i.e. the representation of geometry, that we use. On the one hand, this representation should be expressive enough that we can represent all complex geometries that appear in the real world. On the other hand, the representation should work well with modern machine learning techniques, in particular deep learning.
Recently, our group proposed a new output representation for learning-based 3D reconstruction, called Occupancy Networks where geometry is represented through a deep neural network that distinguishes the inside from the outside of the object. We found that this representation is both powerful enough to represent complex geometries and also fits well the deep learning paradigm. It is also effectively parallelizable not only over the object instances but also the query points enabling us to make full use of the latest NVIDIA GPUs.
This allows us, for example, to train a neural network that can reconstruct a human from a sparse 3D point cloud.
Training was performed using NVIDIA RTX GPUs with the cuDNN-accelerated PyTorch deep learning framework.

The Challenge
While this works well, this scenario is not completely realistic: in the real world, objects are in motion, so that the human would not stand still, but move. Our input would hence rather look like this:

Of course, we could treat each time step individually and apply our network to it. However, this would be very slow (after all we cannot reuse information from previous time steps) and even worse, we would not have any correspondences between the individual time steps. Where does the finger tip end up 2 seconds later? We can’t know as we are not able to identify where a specific point on the body (e.g. the tip of a finger) is at a later time step. Can we do something more clever than this?
Our Approach
Our key insight in this project is that we can represent shape and motion of the 3D body separately (“disentangled”). Instead of just using an occupancy network, we use two networks: an occupancy network and a velocity network. While the occupancy network represents the shape of the 3D object, the velocity network defines a motion field in 3D space that changes over time. We can visualize this as follows:


During inference, we can extract a mesh at time 0 using our occupancy network (like in our previous paper) and then propagate the vertices forward in time using the velocity network by solving an ordinary differential equation.
During training, we sample random points in 3D and go backward in time to determine where these points would have been at time 0. We then evaluate the occupancy network at these hypothetical locations and compare to the ground truth occupancy at the sampled time. This way we do not even need correspondences between different time steps in our training data! However, if they are given, we can easily incorporate them by comparing where a point goes following our vector field against where it should go.
All in all, the key idea is that we disentangle the shape and the motion of 3D objects. As we use our continuous velocity network for the motion representation, we automatically have correspondences for every point in space between time steps. This also makes the inference step much faster!
Experiments
Let’s look at our example from the introduction again. How does Occupancy Flow perform on this example? Here are the results:


We see that Occupancy Flow reconstructs the 3D motion in a plausible way and also got the correspondences right (indicated by the colors).
In our paper, we conducted a variety of other experiments. For example, we used a generative model to transfer the motion from one shape to another:

Further Information
You can find more information (including the paper and supplementary) on our project page. We also provide animated slides for our project. If you are interested in experimenting with Occupancy Flow yourself, download the source code of our project and run the examples. We are happy to receive your feedback!
About the Author

I am Michael Niemeyer from Germany and I am a PhD student at the Max Planck Institute for Intelligent Systems (MPI-IS) and the University of Tübingen, Germany. Before starting my PhD in October 2018, I studied Mathematics at the University of Cologne, Germany and Advanced Computer Science at the University of St Andrews, Scotland. My research mainly focuses on 3D deep learning. I am interested in finding simple yet powerful 3D representations which fit well the deep learning paradigm.
