Researchers from University of California, Berkeley developed a deep learning-based method that creates a 3D reconstruction from a single 2d color image.
“Humans have the ability to effortlessly reason about the shapes of objects and scenes even if we only see a single image,” mentioned Christian Häne of the Berkeley Artificial Intelligence Research lab. “The question which immediately arises is how are humans able to reason about geometry from a single image? And in terms of artificial intelligence: how can we teach machines this ability?”
The researchers exploit the two dimensional nature of surfaces by hierarchically predicting fine resolution voxels with convolutional neural networks only where a surface is expected judging from the low resolution prediction. The difference in their method called hierarchical surface prediction (HSP) is in separating the voxels of an image into three categories: occupied space, free space, and boundaries — this allows them analyze the outputs at low resolution and only predict a higher resolution of the parts of the volume where there is evidence that it contains the surface.
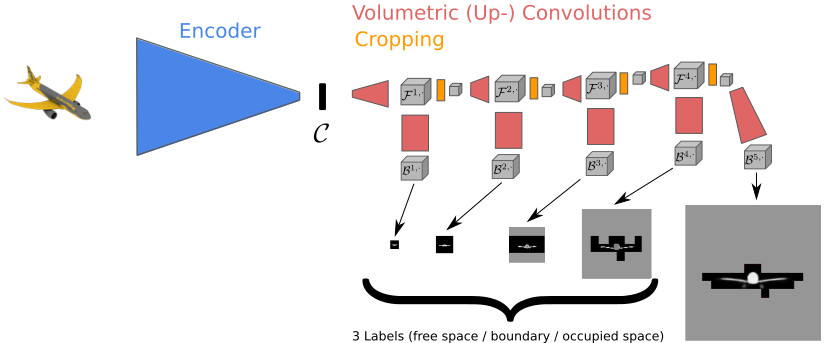
Using a Quadro M6000, Tesla K80 and TITAN X GPUs with the cuDNN-accelerated Torch deep learning framework, they trained their neural networks on the synthetic ShapeNet dataset which consists of Computer Aided Design (CAD) models of objects including airplanes, chairs and cars.

Transform Flat Images Into High-Resolution 3D Models

Aug 24, 2017
Discuss (0)
AI-Generated Summary
- Researchers from the University of California, Berkeley, have developed a deep learning-based method called hierarchical surface prediction (HSP) that creates a 3D reconstruction from a single 2D color image using convolutional neural networks.
- The HSP method separates voxels into three categories: occupied space, free space, and boundaries, allowing for the analysis of outputs at low resolution and prediction of higher resolution for parts of the volume where a surface is expected.
- The researchers trained their neural networks on the synthetic ShapeNet dataset using NVIDIA GPUs with the cuDNN-accelerated Torch deep learning framework, achieving a final resolution of 256^3.
AI-generated content may summarize information incompletely. Verify important information. Learn more
“The main shortcoming with predicting occupancy volumes using a CNN is that the output space is three dimensional and hence has cubic growth with respect to increased resolution,” Häine details. “In order to have sufficient information for the prediction of the higher resolution we predict at each level multiple feature channels which serve as input for the next level and at the same time allow us to generate the output of the current level. We start with a resolution of 163 and divide the voxel side length by two on each level reaching a final resolution of 2563.”
For more details about the research, read their paper on Arxiv >>