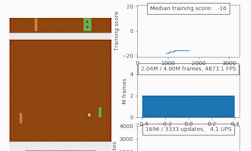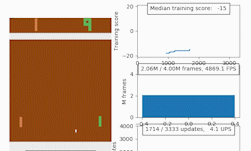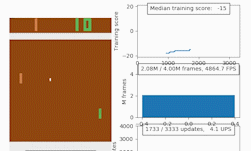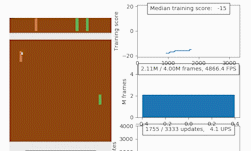
To help accelerate the development and testing of new deep reinforcement learning algorithms, NVIDIA researchers have just published a new research paper and corresponding code that introduces an open source CUDA-based Learning Environment (CuLE) for Atari 2600 games.
In the newly published paper, NVIDIA researchers Steven Dalton, Iuri Frosio, and Michael Garland identify computational bottlenecks that are common to several deep reinforcement learning implementations, prevent full utilization of the available computational resources, and make scaling of deep reinforcement learning on large distributed systems inefficient.

CuLE was designed to overcome these constraints: “Our CUDA Learning Environment overcomes many limitations of existing CPU-based Atari emulators by leveraging one or more NVIDIA GPUs to speed up both inference and training in deep reinforcement learning” the researchers stated.
“By rendering frames directly on the GPU, CuLE avoids the bottleneck arising from the limited CPU-GPU communication bandwidth. As a result, CuLE can generate between 40M and 190M frames per hour using a single GPU, a finding that could be previously achieved only through a cluster of CPUs,” the researchers explained
At the crux of the work, the researchers demonstrated effective acceleration of deep reinforcement learning algorithms on a single GPU as well as scaling on multiple GPUs for popular Atari games including Breakout, Pong, Ms-Pacman, and Space Invaders.
By analyzing the advantages and limitations of CuLE, the researchers also provided some general guidelines for the development of computationally effective simulators in the context of deep reinforcement learning, and for the effective utilization of the high training data throughput generated through GPU emulation: “Training a deep learning agent to reach an average score of 18 in the game of Pong takes 5 minutes when 120 environments are simulated on a CPU, which generates approximately 2,700 frames per second. CuLE on a single GPU generates as much as 11,300 frames per second using 1,200 parallel environments, and reaches the same score in 2:54 minutes; using 4 GPUs we can generate 44,900 frames per second and reach the same score in 1:54 minutes.
The speed up is far more impressive for more complex games like Ms-Pacman, where the traditional CPU-based emulation approach requires 35 minutes for an average score of 1,500; CuLE on one and four GPUs reaches the same score in 19 and 4:36 minutes respectively”.
To achieve such speed up “We had to implement an effective batching strategy to maximize at the same time the number of frames generated by CuLE, and the number training steps performed by the deep reinforcement learning algorithm,” the researchers said.
During testing the team evaluated their model using the cuDNN-accelerated PyTorch deep learning framework, with NVIDIA TITAN V, Tesla V100, and a DGX-1 system, comprised of 8 NVIDIA Tesla V100 GPUs, interconnected with NVLinks, and using the NVIDIA NCCL multi-GPU communications backend.
“CuLE runs successfully on the following NVIDIA GPUs, and it is expected to be efficient on any Maxwell-, Pascal-, Volta-, and Turing-architecture NVIDIA GPUs,” the researchers said.
| GPU |
| NVIDIA GeForce 1080 |
| NVIDIA TitanXP |
| NVIDIA Tesla P100 |
| NVIDIA Tesla V100 |
| NVIDIA TitanV |
| NVIDIA GeForce RTX 2080 TI, 2080, 2070 |
CuLE is being made available by NVIDIA as open source software under the 3-clause “New” BSD license.
