
This post discusses tensor methods, how they are used in NVIDIA, and how they are central to the next generation of AI algorithms.
Tensors in modern machine learning
Tensors, which generalize matrices to more than two dimensions, are everywhere in modern machine learning. From deep neural networks features to videos or fMRI data, the structure in these higher-order tensors is often crucial.
Deep neural networks typically map between higher-order tensors. In fact, it is the ability of deep convolutional neural networks to preserve and leverage local structure that made the current levels of performance possible, along with large datasets and efficient hardware. Tensor methods enable you to preserve and leverage that structure further, for individual layers or whole networks.
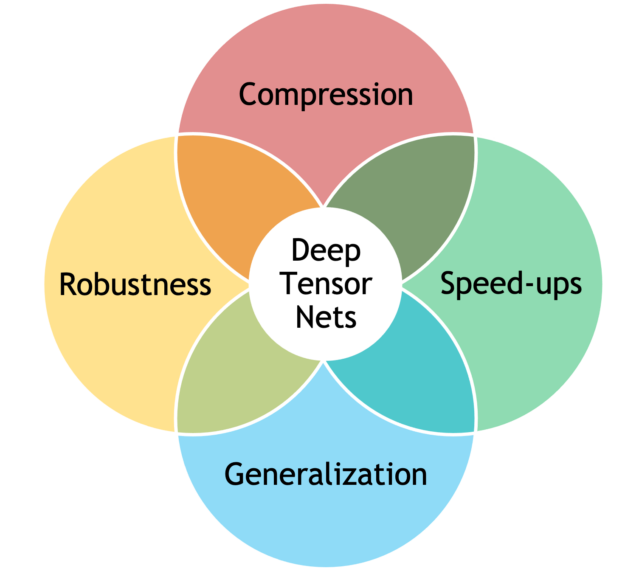
Combining tensor methods and deep learning can lead to better models, including:
- Better performance and generalization, through better inductive biases
- Improved robustness, from implicit (low-rank structure) or explicit (tensor dropout) regularization
- Parsimonious models, with a large reduction in the number of parameters
- Computational speed-ups by operating directly and efficiently on factorized tensors
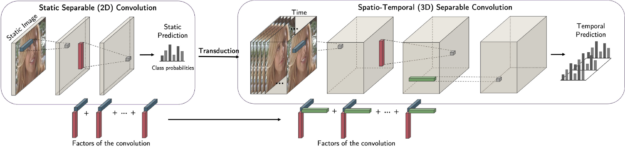
One example is factorized convolution. With a CP structure, it is possible to decompose the kernel of a convolution and express it efficiently as a separable one. This decouples the dimensions and enables you to transduct, such as training on 2D and generalizing to 3D while leveraging the information learned in 2D.
The proper implementation of tensor-based deep neural networks can be tricky. Major neural networks libraries such as PyTorch or TensorFlow do not provide layers based on tensor algebraic methods and have limited support for sparse tensors. In NVIDIA, we lead the development of a series of tools to make the use of tensor methods in deep learning seamless, through the TensorLy project and Minkowski Engine.
TensorLy ecosystem
TensorLy offers a high-level API for tensor methods, including decomposition and algebra.
It enables you to use tensor methods easily without requiring a lot of background knowledge. You can choose and seamlessly integrate with your computational backend of choice (NumPy, PyTorch, MXNet, TensorFlow, CuPy, or JAX), without having to change the code.
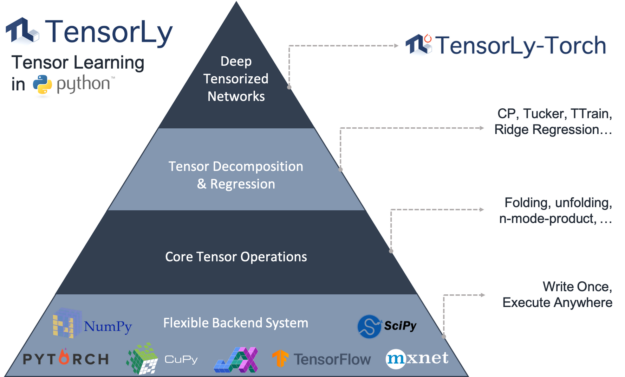
TensorLy-Torch is a new library that builds on top of TensorLy (GitHub repo) and provides PyTorch layers implementing these tensor operations. They can be used out-of-the-box and readily integrated in any deep neural network. At the core of it is the concept of factorized tensors: tensors are represented, stored, and manipulated directly in decomposed form. Whenever possible, operations then directly operate on these decomposed tensors.
These factorized tensors can then be used to parametrize deep neural network layers efficiently, such as factorized convolutions and linear layers. Finally, tensor hooks enable you to apply techniques such as generalized lasso and tensor dropout seamlessly for improved generalization and robustness.
Spatially sparse tensors and Minkowski Engine
In many high-dimensional problems, data become sparse as the volume of the space increases faster. The sparsity is mostly embedded in the spatial dimension where you can compute distance. The most well-known example of such sparsity is 3D data, such as meshes and scans.

Here’s an example 3D reconstruction of a room with two beds. The 3D bounding volume that it occupies can be quite large, but the data, or the 3D surface reconstruction, occupies only a fraction of the space. In this example, 95.5% of the space is empty and less than 5% contains a valid surface. Using a dense tensor to represent such data results in wasting not just large amounts of memory but also computation if you were to process such data.
For such cases, you could use a sparse representation that does not waste memory and computation on the empty space for building a neural network or a learning algorithm. Specifically, you use sparse tensors to represent such data, which is one of the most widely used representations for sparse data. Sparse tensors represent data using a pair of positions and values of nonzero values.
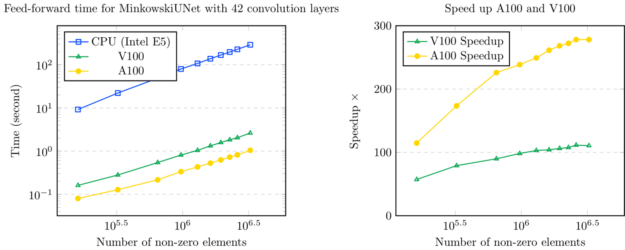
Minkowski Engine is a PyTorch extension that provides an extensive set of neural network layers for sparse tensors. All functions in Minkowski Engine support CPU and CUDA operations where CUDA operations accelerate over 100x over the top-of-the-line CPUs.
For other interesting projects, see all NVIDIA Research posts.
