
The NVIDIA H100 Tensor Core GPU, based on the NVIDIA Hopper architecture with the fourth generation of NVIDIA Tensor Cores, recently debuted delivering unprecedented performance and sweeping AI benchmarks such as MLPerf training.
A significant fraction of operations in AI and machine learning benchmarks are general matrix multiplications (GEMMS), which are also referred to as matmul functions. GEMMs are also present in forward and backward passes of deep learning training, as well as in inference.
The prominence of GEMMs makes it critical for deep learning software to maximally leverage hardware used for matrix multiplications and, at the same time, support several key AI components. These components include fusions with bias and popular activation functions and their derivatives.
This post explores the latest capabilities of the NVIDIA cuBLAS library in CUDA 12.0 with a focus on the recently introduced FP8 format, GEMM performance on NVIDIA Hopper GPUs, and improvements to the user experience such as the new 64-bit integer application programming interface (API) and new fusions.
Before diving into these capabilities, a brief summary details the currently available cuBLAS APIs, how each can be more effectively applied, and how cuBLAS relates to other available NVIDIA tools for matrix multiplications.
Determining which cuBLAS API to use
The cuBLAS library is an implementation of Basic Linear Algebra Subprograms (BLAS) on top of the NVIDIA CUDA runtime, and is designed to leverage NVIDIA GPUs for various matrix multiplication operations. This post mainly discusses the new capabilities of the cuBLAS and cuBLASLt APIs. However, the cuBLAS library also offers cuBLASXt API targeting single-node multiGPU GEMMs. The cuBLASDx API is set to be available in Early Access in 2023 and targets GEMMs and their fusion inside device functions.
Table 1 provides an overview of what each API is designed for and where users can expect the best performance.
| API | API complexity | Called from | Fusion support | Matrix sizes for maximum performance |
| cuBLAS (since CUDA 6.0) | Low | Host | None | Large (global memory) |
| cuBLASXt (since CUDA 6.0) | Low | Host | None | Very Large (multi-GPU, global memory) |
| cuBLASLt (since CUDA 10.1) | Medium | Host | Fixed set | Medium (global memory) |
| cuBLASDx (targeting 2023 EA) | Medium/High | Device | User ops | Small (shared memory) |
cuBLAS API
The cuBLAS API implements the NETLIB BLAS specification in all three levels, with up to four versions per routine: real single, real double, complex single, and complex double precisions, with S, D, C, and Z prefixes, respectively.
In the case of BLAS L3 GEMMs, \(D=\alpha * op(A) * op(B) + \beta * C\), there are more options available for \(\alpha\) and \(\beta\) variables such as host and device references. This API also provides several extensions like the batched and reduced/mixed-precision versions of the traditional functions.
cuBLASLt API
The cuBLASLt API is a more flexible solution than cuBLAS specifically designed for GEMM operations in AI and machine learning. It provides flexibility through parameter programmability for the following options:
- matrix data layouts
- input types
- compute types
- epilogues
- algorithmic implementation choice
- heuristics
Once a set of options for the intended GEMM operation is identified by the user, these options can be used repeatedly for different inputs. Briefly, compared to the cuBLAS API, cuBLASLt can support complex cases such as:
\(D, Aux= Epilogue(\alpha * scale_{A} * scale_{B} * op(A) * op(B) + \beta * scale_{C} * C)\)
This case has multiple outputs and is a prominent GEMM encountered in transformer-based models.
To provide a recent example, A and B can be in either of the two new FP8 formats with multiplication and accumulation done in FP32. Epilogues can include both GELU and bias, with bias in BF16 or FP16. Many common epilogues are now fused with matmuls. Moreover, \(Aux\) is an optional additional epilogue output meant to be used when computing gradients. The above operation and many similar ones are described using a cuBLASLt operation handle type.
NVIDIA CUTLASS and GEMMs
One of the most prominent open-source NVIDIA libraries, NVIDIA CUTLASS also provides CUDA C++ and Python abstractions for GEMMs (and convolutions) on NVIDIA GPUs with primitives at device, block, warp, and thread levels. One advantage of CUTLASS is that users can compile GEMMs for their required scope exclusively rather than needing to load a much larger binary, as would be the case with the cuBLAS library.
This of course comes with a performance tradeoff in that a substantial effort is required to find and instantiate the best kernel for every individual use case. The cuBLAS library provides maximal performance across a broad range of problems through extensively trained heuristics.
In fact, for a number of use cases and data types, cuBLAS may include several kernels that are instantiated from CUTLASS. In general, cuBLAS employs various sources of kernels to guarantee maximum performance more uniformly across applications.
FP8 support on NVIDIA Hopper
First introduced in CUDA 11.8, FP8 is a natural progression from 16-bit floating point types, reducing the memory and computational requirements of neural network training. Furthermore, due to its nonlinear sampling of the real numbers, FP8 can also have advantages for inference when compared to int8.
FP8 consists of two encodings, E4M3 and E5M2, where the name explicitly states the number of exponent (E) and mantissa (M) bits with the sign bit being implied. In CUDA C++, these encodings are exposed as __nv_fp8_e4m3 and __nv_fp8_e5m2 types, respectively. NVIDIA Hopper Tensor Cores support FP8 matrix products with FP16 and FP32 accumulation.
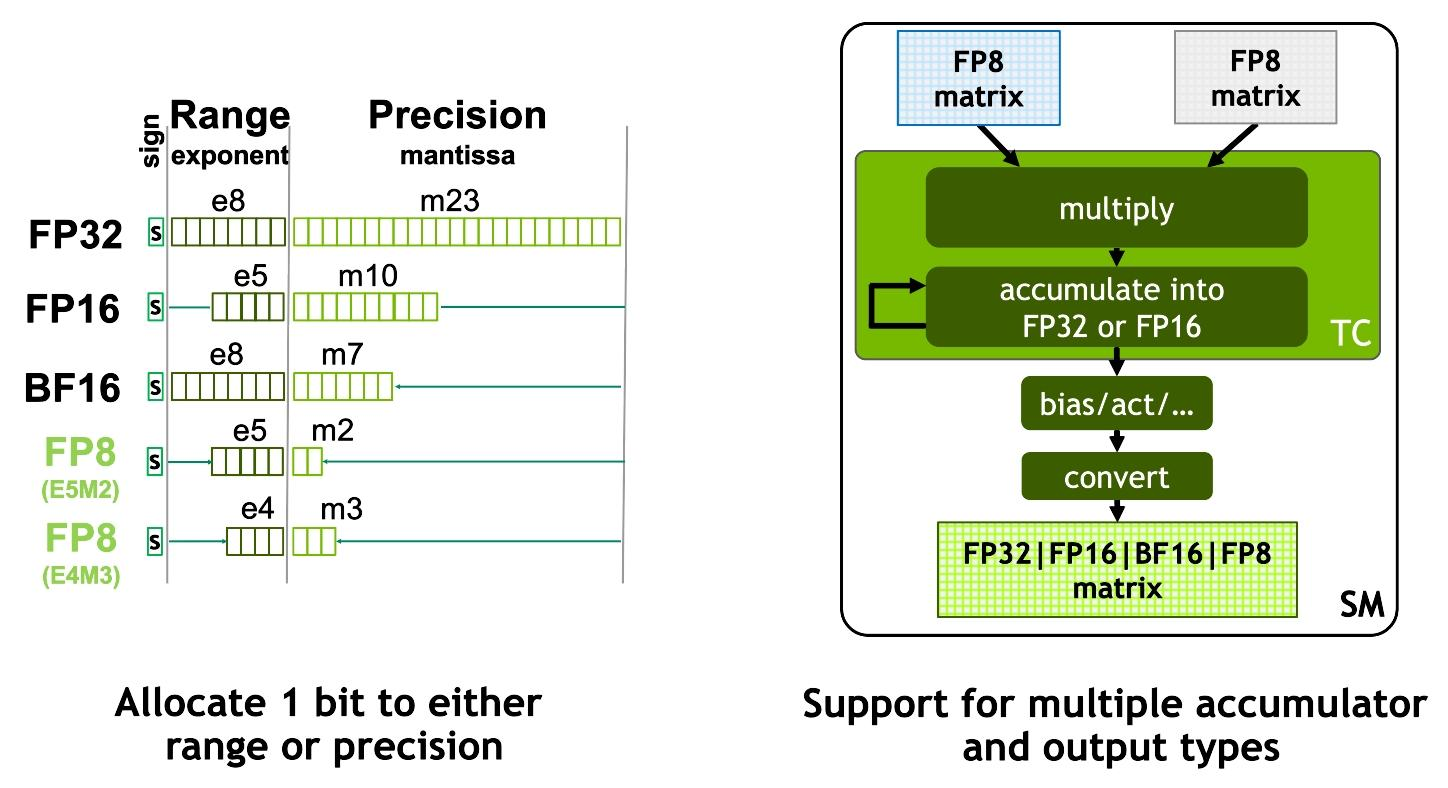
In CUDA 12.0 (and since CUDA 11.8), cuBLAS provides a wide variety of matmul operations that support both encodings with FP32 accumulation. (For the full list, see the cuBLAS documentation.) FP8 matmul operations also support additional fused operations that are important to implement training and inference with FP8, including:
- per-matrix scaling factors for A, B, C, and D matrices in addition to the traditional alpha and beta
- absolute maximum computations for output matrices
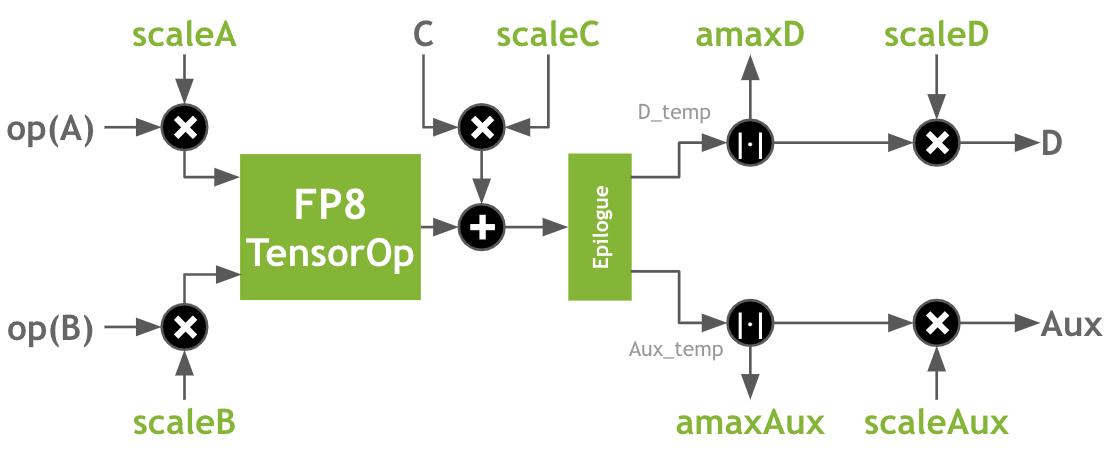
\(D_{temp}, Aux_{temp} = Epilogue(\alpha * scale_{A} * scale_{B} * op(A) * op(B) + \beta * scale_{C} * C)\)
\(amax_{D} = max(\vert D_{temp} \vert)\)
\(amax_{Aux} = max(\vert Aux_{temp} \vert)\)
\(D = scale_{D} * D_{temp}\)
\(Aux = scale_{Aux} * Aux_{temp}\)
The \(scale_{A}\), \(scale_{B}\), and \(scale_{C}\) scaling factors are used for de-quantizing \(A\), \(B\), and \(C\) input matrices, respectively. The \(scale_{D}\) and \(scale_{Aux}\) are used for quantizing \(D_{temp}\) and \(Aux_{temp}\) output matrices, which contain operation results in the accumulation data type (FP16 or FP32). The scaling factors are available regardless of the types used for the \(C\) and \(D\).
Note that all scaling factors are applied multiplicatively. This means that sometimes it is necessary to use a scaling factor or its reciprocal depending on the context in which it is applied. The particular order of multiplications between scaling factors and matrices is not guaranteed.
cuBLAS 12.0 performance on NVIDIA H100 GPUs
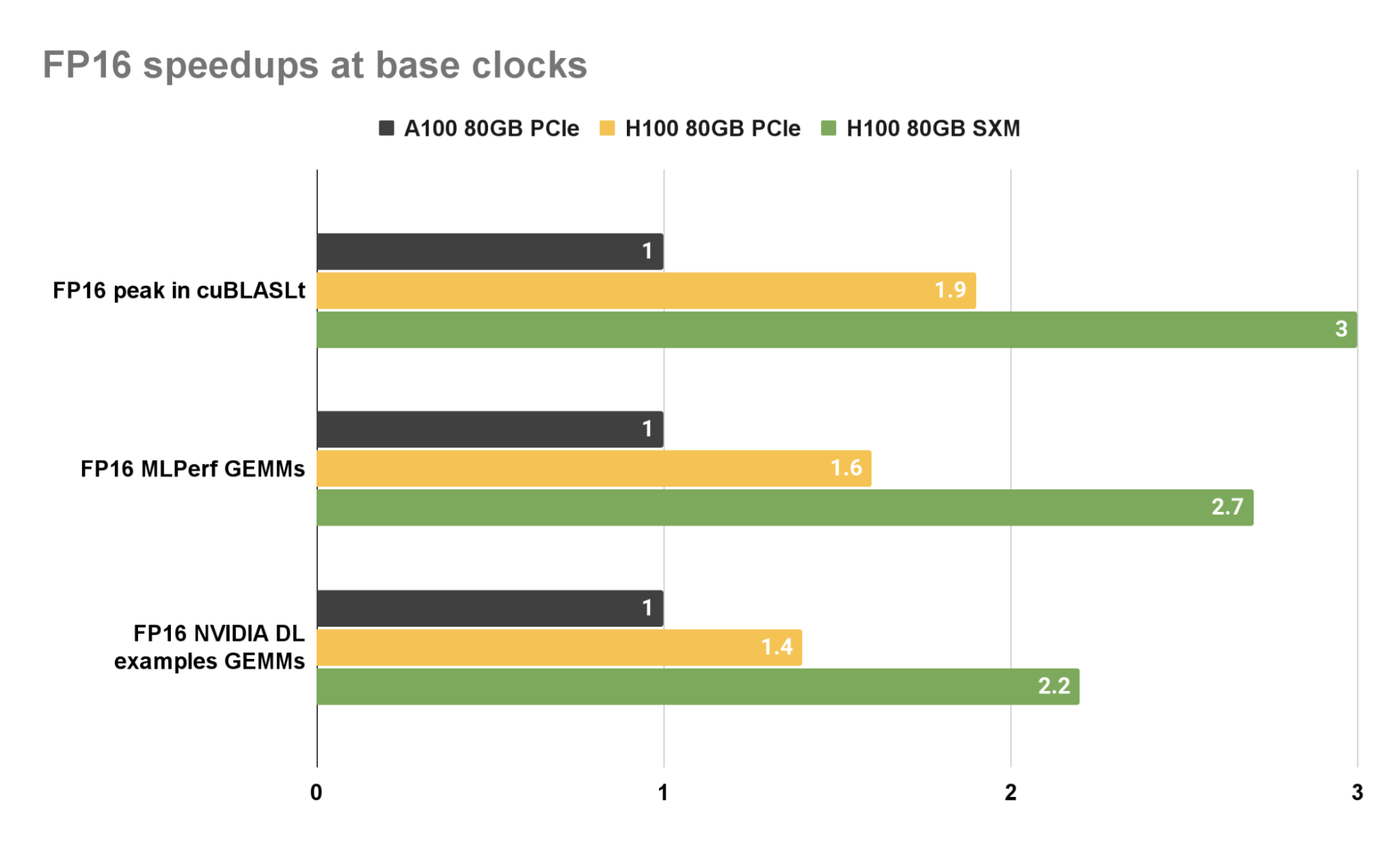
We compare the performance of FP16, BF16, and FP8 GEMMs on H100 PCIe and SXM (preview) with A100 (PCIe) at their base clocks for three scenarios: peak performance of the cuBLAS library for large matrix sizes, and for the GEMMs present in the MLPerf and NVIDIA deep learning examples.
Large GEMMs exhibit large arithmetic intensities, and are therefore compute-bound. Speedup factors, when normalized to A100, are close to the ratio of the peak performance for the underlying data type between pairs of GPUs. The cuBLAS library achieves a three-fold speedup on H100 SXM with respect to A100 for compute-bound FP16 GEMMs.
MLPerf and NVIDIA DL examples, on the other hand, consist of GEMMs that span a range of arithmetic intensities. Some are far from compute-bound and therefore exhibit smaller speedups than large GEMMs. The cuBLAS library achieves 2.7x and 2.2x speedups on H100 SXM with respect to A100 for GEMMs in MLPerf and NVIDIA DL examples, respectively.
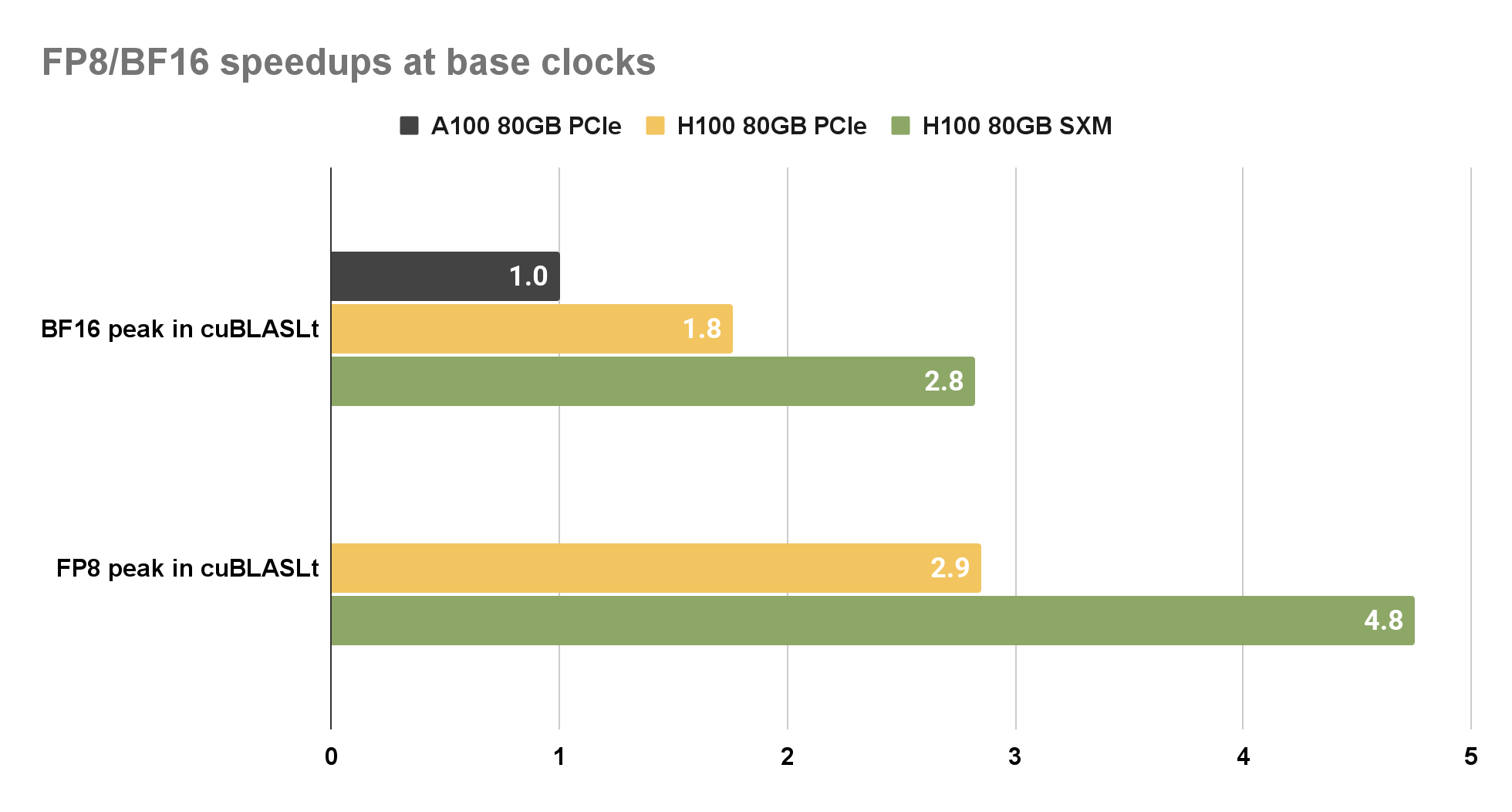
In order to compare FP8 and BF16 performance on H100, we choose BF16 on A100 as the baseline. This choice is due to FP8 support being only available on NVIDIA Hopper architecture. The cuBLAS library provides a speedup of nearly 2.8x for BF16 and 4.8x for FP8 on H100 SXM over BF16 on A100 PCIe.
NVIDIA Hopper architecture workspace requirements
H100 native kernels have increased the need for workspace size. It is therefore highly recommended to provide at least 32 MiB (33554432 B) of workspace for cuBLASLt calls or when using cublasSetWorkspace.
Improvements to the cuBLAS user experience
- cuBLAS 12.0 enables new FP8 and FP16/BF16 fused epilogues. On NVIDIA Hopper, FP8 fusions are now available with bias (BF16 and FP16), ReLU and GELU, with and without auxiliary output buffers. New FP16 fusions are also available with bias, ReLU and GELU, dBias and dReLU for NVIDIA Hopper. For NVIDIA Ampere architecture, single-kernel, faster BF16 fusions with bias and GELU, and dBias and dGELU are exposed now.
- Heuristics cache allows for storing the mapping of matmul problems to kernels previously selected by heuristics. This helps reduce the host-side overhead for repeating matmul problems.
- cuBLAS 12.0 extends the cuBLAS API to support 64-bit integer problem sizes, leading dimensions, and vector increments. These new functions have the same API as their 32-bit integer counterparts except that they have a
_64suffix in the name and declare the corresponding parameters asint64_t.
For example, for the classic 32-bit integer function:
cublasStatus_t cublasIsamax(
cublasHandle_t handle,
int n, const float *x,
int incx, int *result);the 64-bit integer counterpart is:
cublasStatus_t cublasIsamax_64(
cublasHandle_t handle,
int64_t n, const float *x,
int64_t incx, int64_t *result);Performance is the main focus for cuBLAS, so when the arguments passed to 64-bit integer API fit into the 32-bit range, the library uses the same kernels as if the user calls 32-bit integer API. To try the new API, the migration should be as simple as just adding a _64 suffix to cuBLAS functions, thanks to C/C++ autoconversion from int32_t values to int64_t.
cuBLAS 12.0 and NVIDIA Hopper GPUs
This post presented the properties of cuBLAS APIs and new features available from the cuBLAS library in CUDA 12.0. In particular, it discussed FP8 features and fused epilogues and highlighted the performance improvements of the library on NVIDIA Hopper GPUs, with examples relevant to AI frameworks. Finally, it detailed improvements to the user experience such as the support for int64 dimensions in the cuBLAS API, future hardware fallbacks, and more reduction in host-side overheads.
To learn more about cuBLAS updates, refer to the cuBLAS documentation.
